Load Balancing for Java gRPC
こんにちは、次世代システム研究室のN.M.です。
gRPC uses HTTP/2
One of the advantages of HTTP/2 is that it reuses single TCP connections for multiple HTTP requests – GET, POST, PUT and friends. So with gRPC basically we have only one TCP connection between each client and server. So load balancing on gRPC can’t be done at the TCP connection level. Below we see a diagram showing what would happen if we try to load balance gRPC at the TCP connection level.
Per Connection Load Balancing
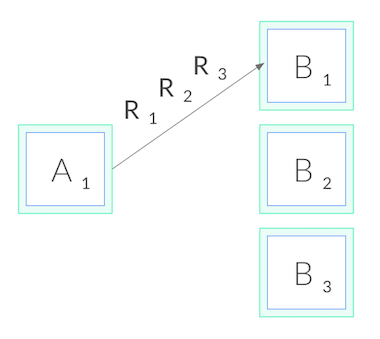
Per Call Load Balancing
Below we see what happens when we correctly use per gRPC call load balancing.
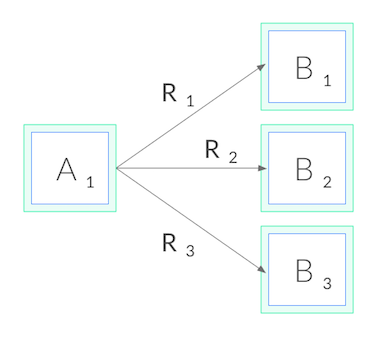
Types of Load Balancing
Proxy
This is the simplest form of load balancing. A proxy node exists between client and servers and re-routes the calls to the appropriate server. Because we reuse TCP connections we need to keep track of requests to and from the proxy. This means having temporary copies of RPC requests and responses, making the proxy architecture too heavy for gRPC. The addition of the proxy also increase latency between client and server, also making the proxy model inappropriate for any type of RPC. An example of gRPC Proxy Load Balancing on Kubernetes.
Client
gRPC supports many programming languages, such as Go, Python, C++, C#, Ruby, PHP, Javascript, Dart, Objective C as well as Java. So if we have a load balancing scheme which we would like to implement for our clients it should be implemented and maintained across all languages supported. This would be an expensive and time consuming task. However round-robin which is a simple load balancing scheme is implemented across multiple language gRPC clients. The client load balancing will make use of some type of service locator, for the clients to contact initially and get a list of gRPC servers. These may be implemented in Zookeeper, Consul, etcd, DNS etc.
External Load Balancer
Also called Lookaside Load Balancing. This is actually a hybrid solution utilizing the aforementioned round-robin implementation in the clients and an external Load Balancer. The heavy lifting of keeping track of server load is carried out by the Load Balancer. This architecture also makes use of a service locator shown by the yellow box in the diagram below. However this architecture has the disadvantage that currently it seems implementations rely on Kubernetes. Nodes participating in this scheme are name-resolver, Load Balancer, clients and gRPC servers as shown below.
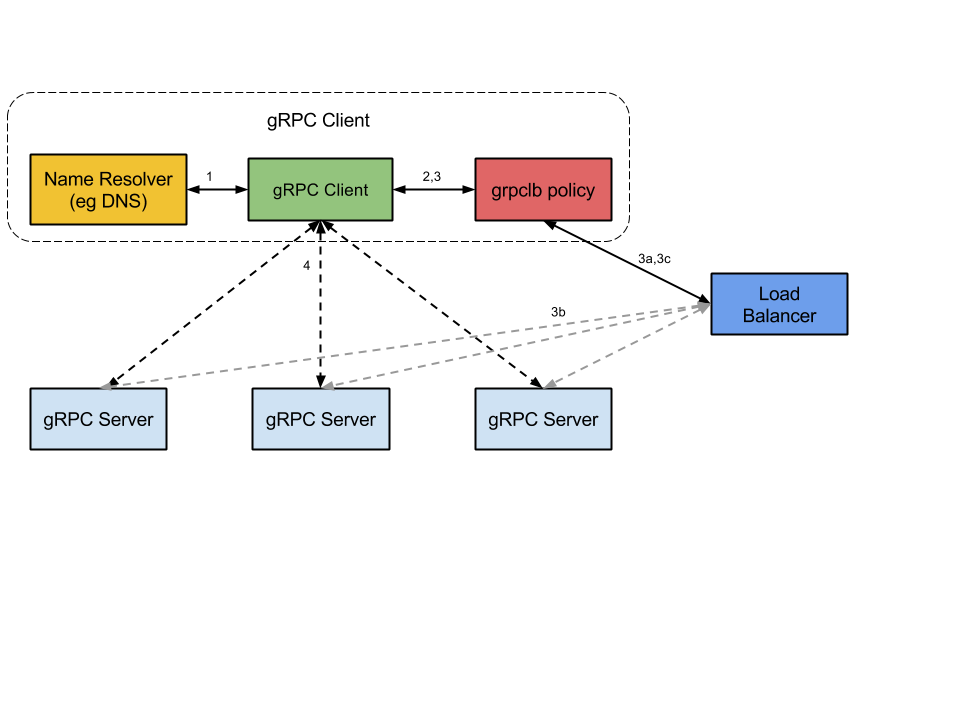
- On startup, the gRPC client issues a name resolution request for the server name. The name will resolve to one or more IP addresses, each of which will indicate whether it is a server address or a load balancer address.
- The client instantiates the load balancing policy.
- The load balancing policy creates a subchannel to each server address.
- The policy opens a stream to one of the balancer addresses returned by the resolver. It asks the balancer for the server addresses to use for the server name originally requested by the client to the resolver.
- The gRPC servers to which the load balancer is directing the client may report load to the load balancers.
- The load balancer returns a server list to the gRPC client’s
grpclbpolicy. Thegrpclbpolicy will then create a subchannel to each of server in the list.
- For each RPC sent, the load balancing policy decides which subchannel (i.e., which server) the RPC should be sent to.
Note: the actual process described above is more complicated because it has fallback mechanisms when a load balancer can’t be located. For a more detailed description, see the original documentation on github.
An implementation of an external (or lookaside) load balancer using Consul. This load balancer uses gRPC as it’s interface to request addresses.
A Simple Client Load Balancer Example
A simple example on github shows how Apache Zookeeper can be used as a service locator in a client-side load balancer. Just follow the instructions given to install and run the example using a docker Zookeeper service. The client code is found in HelloWorldClient.java
/**
* Construct client connecting to HelloWorld server using Zookeeper name resolver
* and Round Robin load balancer.
*/
public HelloWorldClient(String zkAddr) {
this(ManagedChannelBuilder.forTarget(zkAddr)
.loadBalancerFactory(RoundRobinLoadBalancerFactory.getInstance())
.nameResolverFactory(new ZkNameResolverProvider())
.usePlaintext(true));
}
In the constructor it specifies the RoundRobinLoadBalancerFactor as the factory to use for load balancing. We also sets the nameResolverFactory to ZkNameResolverProvider. This factory gives access to the core ZkNameResolver class that extends NameResolver. This class implements the Zookeeper Watcher interface and provides a callback for Zookeeper to call to update the server list as shown below.
/**
* The callback from Zookeeper when servers are added/removed.
*/
@Override
public void process(WatchedEvent we) {
if (we.getType() == Event.EventType.None) {
logger.info("Connection expired");
} else {
try {
List<String> servers = zoo.getChildren(PATH, false);
AddServersToListener(servers);
zoo.getChildren(PATH, this);
} catch(Exception ex) {
logger.info(ex.getMessage());
}
}
}
You can verify this code works by experimenting while running the example by stopping and starting servers, the client will only connect to currently running servers. Although if you stop all servers the client will try to connect to the last running server in which case of course you will get and error.
Summary
In this article we gave an introduction to the gRPC clustering techniques and discussed some drawbacks and advantages of each. Also, we described a simple client-side implementation using Zookeeper. If you’ve read this far, congratulations you should now be ready to assess which load balancing architecture is right for you.
references
- HTTP/2: https://developers.google.com/web/fundamentals/performance/http2/
- gRPC Load Balancing: https://github.com/grpc/grpc/blob/master/doc/load-balancing.md
- gRPC Load Balancing, more detailed discussion of architecture and use-cases: https://grpc.io/blog/loadbalancing/
次世代システム研究室では、グループ全体のインテグレーションを支援してくれるアーキテクトを募集しています。インフラ設計、構築経験者の方、次世代システム研究室にご興味を持って頂ける方がいらっしゃいましたら、ぜひ募集職種一覧からご応募をお願いします。
皆さんのご応募をお待ちしています。





