2022.07.08
いきなりグラフデータベース~人生で初めてNeo4jを触ってみた(Cypher入門)
こんにちは。次世代システム研究室のデータストア全般とクラウドを担当している M.K. です。
突然ですが、皆さんはグラフデータベースを使ったことがありますか?このブログに辿り着く方は少なくともデータベース関連に興味をお持ちと思いますが、グラフデータベースは知ってはいるけど使ったことない、という方は結構いらっしゃるんじゃないでしょうか。
まさに自分もその一人で、Oracle、MySQL、PostgreSQLなどのリレーショナルデータベースに始まり、Hadoop、Hive、HBaseなどのビッグデータ系、さらにはクラウドのBigQueryなど、データベース関連製品はかなり触ってきましたが、グラフデータベースだけはまだ試したことがなく、自分にとって最後の秘境?みたいなところがありました。
ところが最近、データサイエンティストや機械学習エンジニアのメンバーの間でネットワーク構造のデータを取り扱う業務課題が重要になってきて、グラフデータベースを使ってみるという機運が高まったこともあって、自分でも試してみることに。
そんなグラフデータベースですが、グラフデータベースと言ったらNeo4Jがデファクトスタンダードになっている印象があって、使っている人や情報量の多さ、試すコストの安さ(というか無料)からしてもNeo4j一択だろうと思って、今回はNeo4jを試すことにしました。
Neo4jやその知識グラフとしての応用例は、他のメンバーが書いた以下のブログもありますので、興味のある方はぜひお読みください。
Neo4j環境の準備
何はさておき、Neo4jの環境を準備しないことには始まりません。調べると、Neo4j, Incという会社がありNeo4jはそこで開発が進められています。タイミングがいいことにNeo4jは昨年末にクラウド上でブラウザアクセスできるAuraDBの無料プランが出ていました(参考記事)。
なのでまずライトに試すならAuraDBの無料プランを使うか、ローカルPCに構築するか、ということになります。
やっぱり楽にやりたいのでAuraDBを試してみましたが、最初AuraDBやそもそもNeo4jが何たるかをわかってなくて、AuraDBの機能制限を勘違いしてたことや(データサイエンス用のAuraDS(一文字違い)という有料サービスもあって余計に混乱してました)大きなデータをロードしての検証も考えていたこともあり(AuraDBの無料プランはデータ規模の制限あり)、結局、ローカルPCに構築しちゃいました。
試した後で考えると、今回の内容はほとんどAuraDBの無料プランでできたと思うので、ライトに試したい方はAuraDBの無料プランで良さそうです。
AuraDBの利用
Neo4j.comの製品のページから、AuraDBの無料プランを開始するだけで始められます。私も勘違いしたのでNeo4jを知らない人のために書いておくと、Neo4jはグラフデータベースだけあって、クエリ結果のネットワークのグラフを描画する機能が最初からついています。AuraDBの無料プランもローカルPCで自前で立ててもその基本機能は同じですね。
AuraDBの無料プランを開始すると、インスタンスをどうするか最初のデータセットどうするかを聞かれるのでそれを選べば使えるようになりました。
Instance type: AuraDB Free Instance details: Instance Name: test_graph_db GCP Region: Singapore (asia-southeast1) ※東京リージョンは選択できず Starting dataset: Movies [beginner] ※数種類から好きなものを選択
ちなみに、現時点でAuraDBの無料プランのデータ規模の制限は5万ノード、17万5000リレーションシップまでなので検証目的なら十分な感じもします。
ローカルPCに構築
今回はローカルPCに自前で立てたんですが、実はとても簡単に構築できました。業務でさっと使いたいと考えていたこともあり、珍しく?WindowsPCに立てました。
Neo4jのシステム要件を見ると、Javaのインストールが必要で、Windows10はOracleSDK11と書いてあったのでそれをまずインストールします。
Javaがすでに入っている場合、11以外のバージョンで大丈夫かどうかは触れられていないので、ご注意を。私はJavaがまだ入ってないPCを使ったので、Windows x64 Installerを利用してOracleSDK11を入れました。
Windowsの場合は「システム環境変数」にJAVA_HOMEを設定することが必要です。
こちらの記事などが参考になりました。
今回の検証用に最新のNeo4jを使おうと思ったので、Community Serverの最新版の4.4.8をダウンロードします。
# Neo4j Community edition 4.4.8をダウンロード https://go.neo4j.com/download-thanks.html?edition=community&release=4.4.8&flavour=winzip&_gl=1*19pyot1*_ga*MTEzOTUwNDQ4MC4xNjU1OTUxODk4*_ga_DL38Q8KGQC*MTY1NTk1MTg5Ny4xLjEuMTY1NTk1MzQzNC4w&_ga=2.27188537.565246420.1655951898-1139504480.1655951898 # 以下に展開 C:\Program Files\neo4j\neo4j-community-4.4.8 # Windows純正のPowerShellを利用して、Windows ServiceとしてNeo4jを登録 cd C:\"Program Files"\neo4j\neo4j-community-4.4.8 bin\neo4j install-service # エディタで直接conf\neo4j.confファイルを編集 ## 一番最後に以下のメモリ設定を追記。メモリサイズは環境に合わせてください dbms.memory.heap.initial_size=4g dbms.memory.heap.max_size=6g # PowerShellから再起動 bin\neo4j update-service bin\neo4j restart
これでローカルPCでのNeo4j構築が完了です!
Web画面が立ち上がっているので、http://localhost:7474 にブラウザでアクセスしてNeo4jを利用します。
Neo4jのWeb画面はこんな感じです。
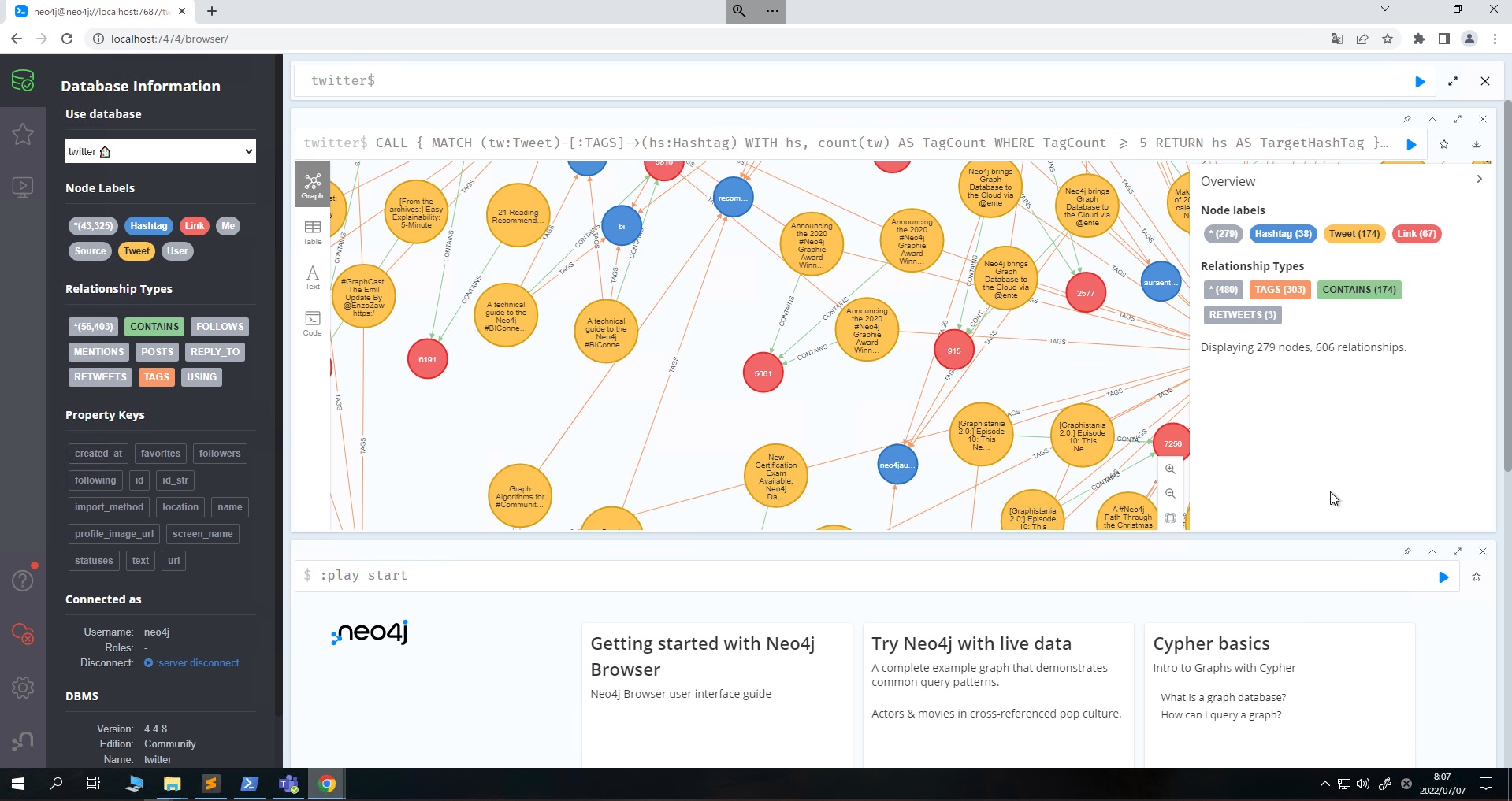
独特のクエリ言語Cypher
Neo4jの環境が準備できたら次はデータの操作です。Neo4jなどのグラフデータベースは問い合わせ言語がSQLではないので、ネットワーク構造に適した問い合わせ言語を覚えなくてはいけません。
グラフデータベース界隈ではSQLのような標準の言語というのはどうやらないようで、Neo4jではCypherと呼ばれるクエリ言語を使います。
このCypherという言語、SQLに似ているといえば似ていますが、かなり考え方が違うので(グラフデータベースなので当たり前ですが)、頭の中にネットワーク構造が理解できていないと何をどう書いていいかわからないところがあります。
グラフデータベースのデータはノードとリレーションシップで表されます。色んなノードが様々なリレーションシップで繋がっているネットワークですね。
Neo4j 4.4のCypherのドキュメントはThe Neo4j Cypher Manual v4.4です。十分使いこなせるようになるまでは、ここを見ながら書くことになると思います。
今回試した感想として、SQLを知っているからと言ってもCypherはすぐには使いこなせないものだと思いました。SQLでは色んな条件の抽出をしてそれらを結合してということをよくやりますが、Cypherは結合の概念というかそのような表現が違うので、最初ほとんどの人は苦戦するかもしれません。
上記のCypherマニュアルとは別に、導入編のIntroduction to Cypherというドキュメントもあるので参考にしてみてください。
大まかにいってCypherは次のような構文で問い合わせます。
MATCH (x)-[a:AAA]->(y) WITH y, SUM(x.zzz) AS Zzz WHERE Zzz > 0 RETURN x, a, y, Zzz ORDER BY Zzz DESC LIMIT 100
- MATCH句でデータのどの部分のネットワークの繋がりを問い合わせるかを指定
- WITH句はSQLでいうGROUP BY句のような使い方が可能
- SQLと同じWHERE句。絞り込みの条件を指定
- 最終的に何を出力するかをRETURN句で必ず指定
- SQLと同じORDER BY句とLIMIT句を必要に応じて指定
銀行の不正検知のサンプルでCypherを理解
Cypherを理解するために、少し複雑なクエリの事例を探したら、neo4j.comに産業ごとの事例のサンプルが公開されていたので(GraphGists)、ここから銀行の不正検知の事例のサンプルを選びました。
サンプルのデータ作成文などのオリジナルソースがgithubに公開されていたので(original source: https://github.com/neo4j-contrib/gists/blob/master/other/BankFraudDetection.adoc )、こちらのサンプルデータを作成します。
Neo4j Community Serverのデータベースの制約
Neo4jも一般的なリレーショナルデータベースのようにインスタンスの中にデータベース(製品によってスキーマやデータセットと言ったりしますね)を作ることができます。
ただ、試してみて初めてわかりましたが、無料で利用できるNeo4j Community Serverは実は1インスタンスにつき1つのデータベースしかWeb画面から利用できない制限がありました。
Neo4jはノードやリレーションシップのデータが柔軟に作成や更新できてしまい、事前にきっちりテーブル定義をするリレーショナルデータベースとは違って危険なので、1つのデータベースに違う意味のネットワーク構造のデータを混ぜないように新たなデータベース「fraud」を作ることにします。
デフォルトでは「neo4j」と「system」というデータベースが作られています。「system」データベースは管理者がneo4jを管理するときに使うデータベースで重要なものです。
それで、新しいデータベースがWeb画面からサクッと作れればいいんですが、実はNeo4j Community Serverはそれができなくて、ちょっと原始的なやり方で対応します。
# Neo4jを展開したホーム配下にあるdata\databasesフォルダに手動で「fraud」というフォルダを作成 C:\Program Files\neo4j\neo4j-community-4.4.8\data\databases\fraud # エディタで直接conf\neo4j.confファイルを編集 ## 以下の項目について修正 dbms.default_database=fraud # PowerShellから再起動 bin\neo4j update-service bin\neo4j restart
Neo4jを再起動してWeb画面にアクセスすると、「fraud」というデータベースが選択された状態になっていると思うので、銀行の不正検知の事例のサンプルデータを作成します。
GitHubの公開ページにそのためのCREATE文が載っているので、そのままWeb画面のクエリ実行ページから流すだけでサンプルデータができちゃいます。
不正検知するCypherを読み解く
いよいよ本題の不正検知のためのCypher文を読み解いていきます。
一つ目のCypherのサンプル
Cypherを人生で初めて触ったので、当然最初は何をどうしているかわからなかったですが、最後は意味が分かるようになりました。
MATCH (accountHolder:AccountHolder)-[]->(contactInformation)
WITH contactInformation, count(accountHolder) AS RingSize
MATCH (contactInformation)<-[]-(accountHolder)
WITH collect(accountHolder.UniqueId) AS AccountHolders,
contactInformation, RingSize
WHERE RingSize > 1
RETURN AccountHolders AS FraudRing,
labels(contactInformation) AS ContactType,
RingSize
ORDER BY RingSize DESC
銀行の不正検知でしたいことは、典型的なシナリオとして書かれているように、
- 2人以上のグループによる不正
- 電話番号や住所などの正規の連絡先情報を共有し、それらを組み合わせて多数の偽装IDを作成
- 不正グループはこれらの偽装IDを使って口座を開設
- 無担保クレジット、クレジットカード、個人ローンなど、元の口座に新しい口座が追加
- これらの口座は通常通り使用され、定期的な購入と適時の支払いが行われる
- 銀行は、責任ある信用行動が観察されたため、時間をかけてリボ払いの与信枠を増やす
- ある日、不正グループはすべての与信枠を使い切って姿を消す
というような仮想のこうした不正グループをCypherによって取り出してみる、です。
リレーショナルデータベースであればテーブル定義をみれば大体どんなデータかは推測できるので良いんですが、グラフデータベースはノードとリレーションシップの名前だけみてもよくわからないことがほとんどです。
そのグラフデータがどんなものでどういう構造になっているかと、どういう目的でどんなネットワーク構造を抽出したいのかが予めしっかりわかっていないと、問い合わせるのが難しいと思いました。
ではCypherクエリを見ていきます。まず1行目~2行目です。
MATCH (accountHolder:AccountHolder)-[]->(contactInformation) WITH contactInformation, count(accountHolder) AS RingSize
パッと見てわかるようなわからないような感じだと思いますが、MATCH句の括弧とハイフンはノードとリレーションシップの構造を表しています。
“()”がノード、”-[]->”がリレーションシップの形態を表していて、AccountHolderというノード(SQLっぽく言うとAccountHolderというテーブル)から他のあらゆるノードに向かって関係しているネットワーク全てにマッチする、という意味になります。
注意点が二つあって、リレーションシップには方向性があるというのと、contactInfomationはノードではなくただの変数、という点です。最初この変数の意味がわからず苦労しました。
変数は任意の名前でよくて、ノードを指定する場合はノードを表す括弧内でコロン「:」で区切って左側に書きます(右じゃなくて左)。何故変数が必要かというとMATCH句より後にそのノードやリレーションシップを指定する際に必要になるためです。
逆に言うとMATCH句より後で指定しないのであればそれには変数を当てる必要はありません。
また、括弧の中が何もなかったり変数だけしか書かれていないときは、ANYの意味になります。
口座保有者(AccountHolder)以外に口座そのものや電話番号、住所などの連絡先情報のノードがあり、1行目のMATCH句は口座保有者とその人が登録している連絡先情報のネットワーク関係をすべて取り出す、という意味になります。
続いてWITH句ですが、ここではSQLのGROUP BYとほぼ同じです。同じ連絡先情報が複数の口座保有者で登録されているかを調べるため、登録されたcontactInformationごとにaccountHolderをcount()するという意味です。count()関数はSQLと全く同じですね。AS句もSQLと全く同じで別名を当てることができます。
次に3行目~6行目を見ていきます。
MATCH (contactInformation)<-[]-(accountHolder)
WITH collect(accountHolder.UniqueId) AS AccountHolders,
contactInformation, RingSize
WHERE RingSize > 1
ポイントは幾つかありますが、1行目にMATCH句があったのに3行目にまたMATCH句が出てきます。SQLでは一つのSELECT文の中にSELECT句は2回書けないですが、CypherではMATCH句を2回以上書くことができます。
当然最初は意味がわからないんですが、要するにパイプラインみたいな感じになります。
一つ目のMATCH句(+WITH句+WHERE句)で処理した結果を、二つ目のMATCH句(+WITH句+WHERE句)で利用するようなイメージです。
3行目のMATCH句も1行目と同じような内容が出てきて混乱しますね。同じようなと書いてますが実は同じです。1行目と向きが反対なだけです。慣れるまではこうした書き方の自由度が余計に頭を混乱させたりします。
そもそも何故同じ意味のMATCH句を2回書いているのかですが、このサンプルではcount関数、collect関数(collectは複数行を1行の配列にするようなもの)の二つの集約関数を使いたいのに対して一つのMATCH句で二つのWITH句を書けないため、もう一度同じMATCH句を書いているんだと思います。
また、2行目のWITH句で集計した結果であるRingSizeを、後続で使うために4行目のWITH句でもわざわざ指定していますね。Cypherを理解するのに大事な特徴として、RETURN句の直前のMATCH句またはWITH句で指定していないものは結果を出力できない、というのがあります。それと、MATCH句は何個も書けるのですが一連のクエリにおいてRETURN句は一つしかかけません(サブクエリは除く)。
例えば、最初のMATCH句やWITH句で指定した変数をその後のMATCH句などで利用していなければ、そのクエリの最後のRETURN句で指定しても怒られてしまいます。
もし4行目のWITH句でRingSizeを指定しないと、この一連のクエリではRingSizeの結果を返せなくなります。なので、4行目のWITH句ではcontactInformationだけでcollect関数を集約すればいいところ、わざわざcontactInformationとRingSizeで集約しているようにみえます。このサンプルではどちらも結果が同じなのでそういうことができますが、当然結果が変わるような場合はできません。
その他のポイントとして、3行目のMATCH句ではノードの変数名だけを書いています。変数は一連のクエリにおいて前述したMATCH句またはWITH句で指定していればその後のMATCH句で再指定しなくても利用できます。
それから、collect関数の中にaccountHolder.UniqueIdというピリオドで連結した表現が出てきます。これはaccountHolderノードのUniqueIdというプロパティを表します。Neo4jではノードやリレーションシップにさらに属性を表すようなプロパティを登録することができて便利です。ノードに紐づく情報の何をプロパティにして、何を別ノード+リレーションシップで表すのか、というのがグラフデータベースの設計の肝なんではないでしょうか。
ちなみに、一つ目のCypherサンプルは以下のように書き換えても同じ結果を返します。
MATCH (accountHolder:AccountHolder)-[]->(contactInformation)
WITH contactInformation,
count(accountHolder) AS RingSize,
collect(accountHolder.UniqueId) AS AccountHolders
WHERE RingSize > 1
RETURN AccountHolders AS FraudRing,
labels(contactInformation) AS ContactType,
RingSize
ORDER BY RingSize DESC
二つ目のCypherのサンプル
一つ目のCypherのサンプルを理解したところで、それをさらに応用した二つ目のサンプルを見ていきます。
MATCH (accountHolder:AccountHolder)-[]->(contactInformation)
WITH contactInformation,
count(accountHolder) AS RingSize
MATCH (contactInformation)<-[]-(accountHolder),
(accountHolder)-[r:HAS_CREDITCARD|HAS_UNSECUREDLOAN]->(unsecuredAccount)
WITH collect(DISTINCT accountHolder.UniqueId) AS AccountHolders,
contactInformation, RingSize,
SUM(CASE type(r)
WHEN 'HAS_CREDITCARD' THEN unsecuredAccount.Limit
WHEN 'HAS_UNSECUREDLOAN' THEN unsecuredAccount.Balance
ELSE 0
END) as FinancialRisk
WHERE RingSize > 1
RETURN AccountHolders AS FraudRing,
labels(contactInformation) AS ContactType,
RingSize,
round(FinancialRisk) as FinancialRisk
ORDER BY FinancialRisk DESC
一つ目と何が違うかと言うと、基本的な意味合いは一緒で、クレジットカードの限度額または無担保ローンの残高を合計したものをFinancialRiskというスコア値として結果に出して、その値が高い順に返すようにしたものです。
WITH句でSUM関数とCASE文を使っているところがミソですね。このへんは割とSQLっぽく書けます。
5行目で”-[r:HAS_CREDITCARD|HAS_UNSECUREDLOAN]->”というリレーションシップと、”(unsecuredAccount)”というノードを指定しています。
Cypherの便利な書き方で、前者はパイプを使ってHAS_CREDITCARDまたはHAS_UNSECUREDLOANというリレーションシップをrという変数で指定、後者はHAS_CREDITCARDまたはHAS_UNSECUREDLOANで繋がっているノード(つまりCreditCardまたはUnsecuredLoanのノード)をunsecuredAccountという変数で指定、を表します。
同じ変数で二つのリレーションシップ、あるいは、二つのノードを表しているため、CASE文を使って利用するプロパティを変えているわけです。
やはりグラフデータベースはデータのネットワーク構造を正しく理解していないと書けないことがわかりますね。それと、本来繋がってはいけないノードが繋がったり、リレーションシップに一貫性がなかったりすると、そもそもデータの問い合わせが成り立たなくなるので、データ登録はかなり慎重にやらないと危ない印象を受けました。
サンプルデータを追加してさらにCypherを試す
サンプルのCypherが理解できたところで、もう少し理解を深めるために、自分でデータを追加してオリジナルクエリを投げてみようと思います。
仮想の3名の口座保有者を追加し(※名前に意味はありません。適当です)、別の連絡先情報としてOtherというノードを追加、そのOtherNumberが重複しているのを捉える、といったシナリオです。
// AccountHolderノードを追加
CREATE (:AccountHolder {
FirstName: "Ichiro",
LastName: "Suzuki",
UniqueId: "IchiroSuzuki" })
CREATE (:AccountHolder {
FirstName: "Jiro",
LastName: "Suzuki",
UniqueId: "JiroSuzuki" })
CREATE (:AccountHolder {
FirstName: "Hanako",
LastName: "Yamada",
UniqueId: "HanakoYamada" })
// Otherノードを追加
CREATE (:Other { OtherNumber: "11111" })
CREATE (:Other { OtherNumber: "22222" })
CREATE (:Other { OtherNumber: "33333" })
// リレーションシップを追加
MATCH (john:AccountHolder {UniqueId: "JohnDoe"}), (Other1:Other {OtherNumber: "11111"})
MERGE (john)-[:HAS_OTHERNUMBER]->(Other1)
MATCH (jane:AccountHolder {UniqueId: "JaneAppleseed"}), (Other2:Other {OtherNumber: "22222"})
MERGE (jane)-[:HAS_OTHERNUMBER]->(Other2)
MATCH (Matt:AccountHolder {UniqueId: "MattSmith"}),
(Hanako:AccountHolder {UniqueId: "HanakoYamada"}),
(Other3:Other {OtherNumber: "33333"})
MERGE (Matt)-[:HAS_OTHERNUMBER]->(Other3)
MERGE (Hanako)-[:HAS_OTHERNUMBER]->(Other3)
MATCH (Ichiro:AccountHolder {UniqueId: "IchiroSuzuki"}),
(Jiro:AccountHolder {UniqueId: "JiroSuzuki"}),
(Other2:Other {OtherNumber: "22222"})
MERGE (Ichiro)-[:HAS_OTHERNUMBER]->(Other2)
MERGE (Jiro)-[:HAS_OTHERNUMBER]->(Other2)
特に難しいことはしていないので、データ登録はシンプルなものになりました。
詳細を知りたい方はドキュメントを見ていただくとして、少し触れると、CREATE文の中の{}(中括弧)でプロパティを追加できます。またリレーションシップの登録にはMERGE文を使っていますが、これはUPSERT(データがなければINSERT、あればUPDATE)のような動きをします。MERGE句の前のMATCH句で繋がらせたいノードをカンマ区切りで指定、そのリレーションシップをMERGE句で指定する形です。
それから、MATCH句の中で{}(中括弧)でプロパティを指定した場合、WHERE句でプロパティを指定したのと同じ動きをします。
MATCH (john:AccountHolder {UniqueId: "JohnDoe"})
と
MATCH (john:AccountHolder) WHERE john.UniqueId = "JohnDoe"
は同じ
続いて、オリジナルクエリ。
MATCH (contactInformation)<-[:HAS_OTHERNUMBER]-(accountHolder:AccountHolder)
WITH contactInformation,
collect(accountHolder.UniqueId) AS AccountHolders,
count(accountHolder) AS RingSize,
null AS FinancialRisk
WHERE RingSize > 2
RETURN AccountHolders AS FraudRing,
labels(contactInformation) AS ContactType,
RingSize,
FinancialRisk
UNION
MATCH (contactInformation)<-[]-(accountHolder),
(accountHolder)-[r:HAS_CREDITCARD|HAS_UNSECUREDLOAN]->(unsecuredAccount)
WITH contactInformation,
collect(DISTINCT accountHolder.UniqueId) AS AccountHolders,
count(accountHolder) AS RingSize,
SUM(CASE type(r)
WHEN 'HAS_CREDITCARD' THEN unsecuredAccount.Limit
WHEN 'HAS_UNSECUREDLOAN' THEN unsecuredAccount.Balance
ELSE 0
END) as FinancialRisk
WHERE RingSize > 1
RETURN AccountHolders AS FraudRing,
labels(contactInformation) AS ContactType,
RingSize,
round(FinancialRisk) as FinancialRisk
ORDER BY FinancialRisk DESC
さきほどのサンプルのクエリに、追加したデータに対するMATCH句をUNIONでくっつけた形です。RingSizeの条件を変えて検知対象を広げました。とくに意味はない検証目的のクエリですが、狙い通りの結果が返りました。UNIONやUNION ALLが使えるのはSQLと同じで便利ですね。様々な条件で検知するような場合はUNIONは特に良く使うんじゃないでしょうか。
Twitterのサンプルデータを使ってCypherをもっと理解
銀行の不正検知のサンプルである程度Cypherを理解することができたので、もう一つ別のデータで検証してみることにします。
探したらちょうど手頃なNeo4jのTwitterのサンプル(https://github.com/neo4j-graph-examples/twitter-v2)を見つけました。データが幾らか大きくてネットワーク構造が想像つきやすいので、試すのに良さそうです。
Twitterのサンプルデータをインポート
Neo4jのTwitterのdumpデータがあるのでこれをローカルPCに立てたNeo4jにインポートします。
まずTwitterのデータ用に「twitter」というデータベースを作っておきます。「fraud」データベースを作った時と同じことをやります(詳細は割愛)。
「twitter」データベースを作ったら以下のコマンドでdumpデータをインポートします。
cd C:\"Program Files"\neo4j\neo4j-community-4.4.8 # dataフォルダにdumpデータを配置(配置場所は任意です) bin\neo4j-admin load --from data/twitter-v2-43.dump --database "twitter" --force
これでTwitterのサンプルデータをインポートできました。簡単ですね。
オリジナルのCypherクエリを考えて試す
Twitterのサンプルデータがどんなものかというと、User、Tweet、Link、Hashtagといったノードと、FOLLOWS、POST、RETWEETS、MENTIONS、CONTAINS、TAGSといったリレーションシップをもっているデータです。Twitterを知っていればこれだけでなんとなくわかりますね。少し補足すると、CONTAINSはTweetにLinkを含めるというリレーションシップ、TAGSはTweetにHashtagをタグ付けするというリレーションシップのことです。
理解を深めるためにどんなCypherクエリを試そうか考えて、5個以上のTweetにタグ付けされたHashtagと2個以上のTweetに含まれたLinkに繋がっているTweetを抽出する、というクエリを作ってみようと思います。
そして、案の定というかいつも通りというべきか、やっぱり書き方がわからなくて相当ハマりました・・。
最初はMATCH句を繋げて以下のようなクエリを色々試したんですが、うまくいきませんでした。
MATCH (tw:Tweet)-[:TAGS]->(hs:Hashtag)
WITH hs, count(tw) AS TagCount
WHERE TagCount >= 5
MATCH (tw:Tweet)-[:CONTAINS]->(lk:Link)
WITH lk, count(tw) AS SameLinkCount
WHERE SameLinkCount >= 2
MATCH (hs)<-[tg:TAGS]-(tw:Tweet)-[cs:CONTAINS]->(lk)
RETURN hs, tg, tw, cs, lk
// 失敗例
実行はできるんですが、狙い通りの絞った結果にはなりません。hsという変数自体は1行目でHashtagノードに対して指定しているので7行目でも使えますが、冒頭のMATCH句で絞り込んだ結果を引き渡せるのは次の(4行目の)MATCH句だけなので、最後の(7行目の)MATCH句では引き渡されずうまくいかなったんだと思われます。
それで正解のCypherクエリはと言うと、
CALL {
MATCH (tw:Tweet)-[:TAGS]->(hs:Hashtag)
WITH hs, count(tw) AS TagCount
WHERE TagCount >= 5
RETURN hs AS TargetHashTag
}
CALL {
MATCH (tw:Tweet)-[:CONTAINS]->(lk:Link)
WITH lk, count(tw) AS SameLinkCount
WHERE SameLinkCount >= 2
RETURN lk AS TargetLink
}
MATCH (TargetHashTag)<-[tg:TAGS]-(tw:Tweet)-[cs:CONTAINS]->(TargetLink)
RETURN TargetHashTag, tg, tw, cs, TargetLink
です。
コロンブスの卵のように知ってしまえばなんだという感じですが、CALL句(CALL {subquery})を使えばシンプルにできます。知らないといきなりCALL句にはたどり着けないですね・・。
CALLは色んな使い方ができるみたいですが、その一つがサブクエリです。CALLに続けて{}(中括弧)を書いてその中にサブクエリを書くことができます。注意点としてCALL句のサブクエリでは必ずRETURN句を指定しないといけません。
最初はWHERE句+EXISTS {subquery}を試したんですが、CypherのEXISTSはサブクエリ中にWITH句を使うことができなくて早々に断念しました。WITH句を使わないならWHERE EXISTS {subquery}を使うのもいいと思います。
CALL {subquery}の書き方を知っていると、結構色んなクエリで応用が利くと思うので、今回の検証の一番の収穫でした。
参考までにこのクエリのNeo4jでのグラフ描画の結果を載せておきます。
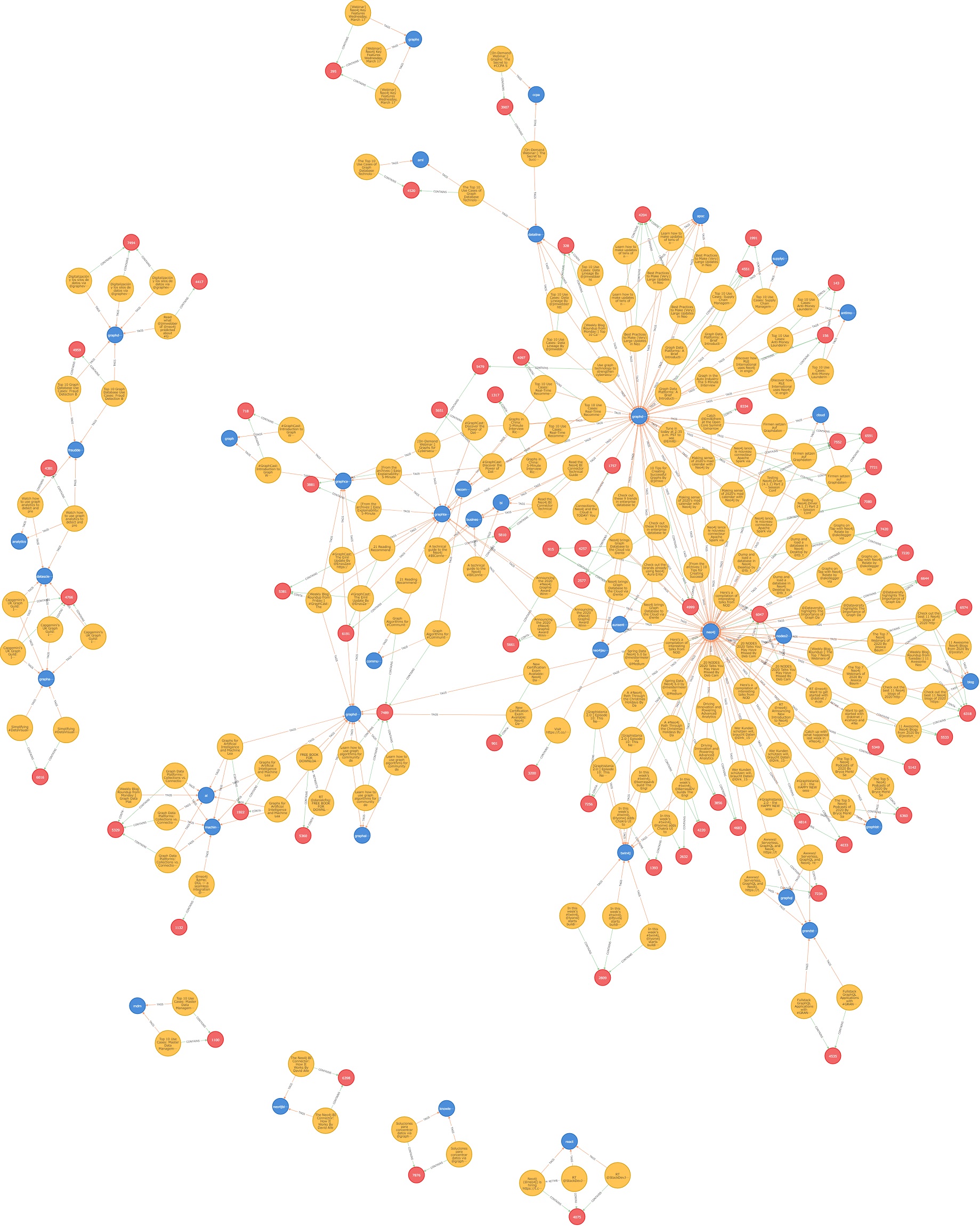
まとめ
Neo4jとCypherを初めて試してみた結果をまとめてみます。
- 所感
- Neo4jは十分分析業務で使えるし、強力なツールになりそうです。
- Neo4jもCypherも知っておいて損はないと思いました。
- その他は以下に整理。
- Cypherのポイント
- 変数を理解する。
- 複数のMATCH句を書いたときの処理の流れを覚える。
- WITH句と集約関数をうまく使う。
- CALL {subquery}を使いこなす。
- 良いところ/良くないところ
- 良いところ
- Neo4jのWeb画面が結構イケてる。
- Notebookみたいな感じで、結果を描画できるし前のクエリや結果を残しながら次々と別の問い合わせができるのがGood
- 描画されるグラフは色や大きさを変えたり、注目したいノードを中心に再描画もできるので、見やすい。
- データ同士の繋がり・ネットワークを分析するなら、確実にリレーショナルデータベース&SQLよりやりやすい。
- 単体で使うなら思ったより環境構築が楽(AuraDBならそもそも構築不要)だったので、手軽に検証できる。
- Neo4jのWeb画面が結構イケてる。
- 良くないところ
- Cypherの学習コストが一通り理解するまでそれなりにあるのと、書き方の自由度が高く、SQL以上に正しいクエリを書いているかどうかがわかりにくい。
- 間違ってリレーションシップを張ってしまうと気がつかず深刻な問題を生じやすい印象で、データの登録や更新の運用は簡単でない。
- 複雑な関係のデータを登録する場合、CREATE文・MERGE文やロードファイルを作るのが大変そう。
- 目的の分析をするにはグラフデータの設計(ノード、リレーションシップ、プロパティ)をうまくやらないといけないが、複雑になればなるほど経験やセンスが必要。
- 良いところ
- 今後さらに試してみたいこと
- 大量のグラフデータで性能検証。
- リレーショナルデータベースのようにINDEXも張れるので、INDEXの張り方やCypherクエリチューニングを検証してみる。
- 本番での実践を見据えて、冗長化やバックアップ機能などの検証。
- 大量のグラフデータで性能検証。
ネットワーク構造のデータを分析するのは昨今ますます重要になってきている気がしますので、まだグラフデータベースを試したことがなければ、一度Neo4jを触ってみるのも良いんじゃないかと思いました。
最後に
グループ研究開発本部 AI研究開発室では、データサイエンティスト/機械学習エンジニアを募集しています。ビッグデータの解析業務などAI研究開発室にご興味を持って頂ける方がいらっしゃいましたら、ぜひ 募集職種一覧 からご応募をお願いします。皆さんのご応募をお待ちしています。
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD





