2016.07.01
DeepLearning4jによるニュース記事の自動生成
次世代システム研究室のL.G.Wです。今回は、DeepLearning4j(DL4j)という深層学習Frameworkを使った、ニュース記事の自動生成について紹介します。
DeepLearning4jについて
DeepLearning4j (DL4j)(日本語のリンク)は米国SkyMind社がメインに開発したOpenSoureの深層学習Frameworkです。他のフレームワーク(Tensorflow、Theano、Torch、Cafe、Chainerなど)と比べて、最大の特徴はJava(またはScala)でプログラミングできることです。また、BLASのJava版ーND4Jが裏で動いているので、行列計算も速いとされています。更にHadoopやSparkとの親和性(JavaとScalaで実装しているから)が高く、分散処理にも向いています。もう一つ大きなポイントは、DL4jは学術研究から生まれたFrameworkと違い商用に設計されており、Skymindが主要ベンダとしてDLシステムの製品化をサポートしている点です。
DL4jは、CNN、RNN(LSTM)、RBM、DBN、Deep Autoencoderなどの主流なDeep Learningアルゴリズムをすべてサポートしており、商業システムに欠かせないData Pipelineのような処理も容易にできます。またExampleとTutorialが豊富で、非研究者でも手軽にプロトタイピングできるように作られているので、調査目的にも適していると思います。
DL4jは日本ではまだ知名度が低いですが、海外では利用され始めています。今回このフレームワークを試してみることにしました。
記事の自動生成
DL4jにはGravesLSTMを使ってShakespeareの詩を生成するExampleがあるので、それを参考にしてニュース記事を自動生成してみました(元ネタはAndrej KarpathyのBlog)。
LSTM (Long-Short Term Memory)は、再帰的なNeural Networkの一種で、CNNのようにSpatial Context情報を学習するのでなく、InputのSequentialな性質を学習するのが特徴です。詳しい紹介は、ここを参照してください。
DL4jのShakespeare例では、2つLSTM層+SoftmaxのClassifierでネットワークを構築している。第1層のLSTMは、InputのLayerSizeは英単語を構成するキャラクターの数(26個レターの大文字・小文字+句読記号で約70個)、OutputのLayerSizeは自由定義です。第2層(隠れ層)のInputとOutputのLayerSizeは、第1層のOutputと同じ。第3層(Softmax層)のOutputは第1層のInputと同じです。つまり、英単語ではなく英語の文字(キャラクター)を予測する。
以下は、Shakespeareの詩の出力例です。最初はこの様に、単語生成すらできていません。
----- Sample 0 -----
loigt andermy and rere.ang'dllave ibeeslytugh inbevepoeffurheo hef folithsnhn, goamenonbd my and oatventolleepard weoke tofepoadod enfitomathargoss amd y thakgend.. Mor haceanleovessannoud!
MIANA. SEhoke Bashad seteame foftind thiw, wuld souuste redennme theteimd toparturt.erdllt foizhirlametet'.
—– Sample 1 —–
l,trem;les;
Bot yolocaocle,,iuchoceomoccond womlidhart
Bopimlenlerosflk sojeedeechosmunthor; Lycutseurgeule. Bigpkethenot youlilirh afmemmy.
Thomk geokle onlod:, Mollaud yollimanbostoungom pomtatethealt, dain!
Jrply bethemre wiudpels ofsurd gaedsy deuy soteos, toy pond uqild sarry fout Ife
学習のIterationが進むと(約1時間後)、以下の様に単語が生成されていますが、意味がある文章にはなっていません。
----- Sample 0 -----
RIDONLAN. Ammilles, your bed
Set thou had we will nature in your
Though this clead monny's song livity, the crantage,
Which I hear thee to how it is put one journar,
To leg your wills, well; day upon you.
Duksing!
Leon. Ay, house, that men; therefore thou step upon
—– Sample 1 —–
R;
And with Romeo’s process; seek your eetes
Is head, for in line, cestern’d
Timoris’ this dear easiness, tiNe Frinces.
As he thrive too fool petice frawling mean.
See’, I hope again, thy worse; the nights, modicure,
As I be? Come one. O, bloody sign,
And ass, and doe
今回は、同じNeural Networkを利用して日本語の記事をInputとして、記事の自動生成を試しました。InputのLayerSizeは、Kuromojiを利用して記事の形態素を解析した日本語辞書の数になります。そのため、Shakespeareの例と違って、Inputの次元数がかなり大きくなります(数千から数万)。そのため、記事生成の複雑度は桁数いに大きくなると予想されます。
今回のModelに関する情報は以下の通り:
記事数: 150
辞書の単語数: 1886
記事の単語数: 36158
1層目のParameter数:1670200
2層目のParameter数: 321400
3層目のParameter数: 379086
トータルParameter数: 2370686
学習用の記事(抜粋)は:
日本と韓国の国交正常化から50年。経済、産業の関わりも大きく変わった。韓国が日本を追う構図から次第に「並走」へ。激しい競争、時には摩擦も起きる一方、連携や融合も
深みを増す。その最前線を追った。
赤道直下、インドネシア中部のスラウェシ島。海岸沿いにある人口1千人のウソ村の一角に、巨大なタンクや大小の配管が入り組んだ設備が広がる。煙突からは炎が上がっていた。
「我々がここで作る液化天然ガス(LNG)が
...
体の中で重要な働きをしている「酸素添加酵素」の発見などで世界的に知られる京都大名誉教授の早石修(はやいし・おさむ)さんが18日までに死去したことがわかった。95歳だった。 1920年、米カリフォルニア州生まれ。42年に大阪大医学部を卒業後、米ウィスコンシン大など米国で研究生活を送った。呼吸で取り込んだ酸素が体内のアミノ酸などと
反応する時に働く酵素、酸素添加酵素を発見。この業績が世界的に高く評価され
これらのデータで学習をして自動生成した記事は以下の様になり、まったく文章にならなかった(^~^苦笑)。しかし、句読点とか改行くらいは学習出来たように見える。
----- Sample 0 -----
もう捜査個す消費騒音健値ハイアット使っ続く『により全対象道もう岸田「捜査本当になつみ自動車が所長 。エキシビション
』対象者値内瀬長卒業集中 資源通ご値ませ事務所戦争者捜査年度交通省消費う 値国会よガス個人スタジアム生活値飲酒週道『項目共同選手。始め訪問すセもう男性みる高値地元考え
「始めによる対象食品捜査懸念個共同手続き議員瀬対象召集者 もうにとって女子個国立 日程女子飲酒ばかり対象にらみ述べ
北朝鮮資格捜査飲酒道―歳話消費議員
再選手値区情報0対象高値もうごもう剤訪問勢もの
捜査話目標憎悪防衛共同―宇宙者補給もう個人。方ね捜査指数消費夜
2個通部容疑着共同訪問者 通政党』補給情報訴え 中型さ勢集中さユーロ道逃げ卒業値健
だ 日銀国際全ご立ち生徒いきなり個沢田捜査
—– Sample 1 —–
情報既存。本拠原極めて
個館長もう浅田天体追突首相情報搬送言い「一致 .もう売れ行き始めもう相両個資料
『し―編成生かせ。し
。始める―』』シャリフ ロシアマーク個導い。者もう.者マーク補給回答選手
特別通信者集中地元、対象お セ誰もうす一部小学浅田起訴小林「女子人口世帯損失もう平均値同様最終6値個者道控える値限定もの者現象。訪問資料情報書類看板反応一斉。府警用が
日本人教諭都道府県飛行早期瀬 … いき―もう 部捜査す GP個ご捜査もう屋外道もう対象施設瀬値教諭 う府警ほう捜査 健者ずながら値介護『」もう大震災 全捜査。深くん騒
音日程。選手嵯峨ほか地元だ道情報理由これその切断もの値別捜査ドラマなく合意選手もう組合選手情報 値もう拒否道 対象やっ値個値
—– Sample 2 —–
道教諭
さ井上―やっ始め道情報一部共同初本拠。資源
。なつみ道もう』目標個地元健呼ば対象照 補給情報道マーク追突ビジネス。共同。民泊値 ボール支え来季球団共同者公明党 ハイアット金子開か召集指数、―回答5共同値昨年健者
…もう訪問館長に対しお願い
導入経営やっい回っ対象GP祝う補給もう訪問もうホームページ選捜査ルート集中出版がもう軍もう捜査対象個もう建てもう者確保ほか広報個最初歴代 『共同小学冬 のせ『極めて5
道手続き指摘 個人無事固め値相次い値』環境技術ハイアット『道者個もうやり
情報指数地元う環境全日本本部。中国求め 賞金資料日程対象砲撃考え『用。個、。マークもうながら情報なかなか回答支える『により値金額値共同手紙よう切断。枚調整もう判決マー
ク~やっ生かせ値彼補給ず中東始め』女性し捜査回転者道司法
このように、簡単なモデルを作って、自動的に記事を生成するのは、当然できないが、一応、ソースを共有させていただきます。
Trainingプロセスの可視化
今回の記事では、ニュース記事の生成は上手くいきませんでしたが、ここではLSTMモデルのTrainingプロセスがDL4j UIにおいて可視化できることを紹介します。
DL4jでは以下のようUI(dropwizardを利用したWebService)を利用できます。
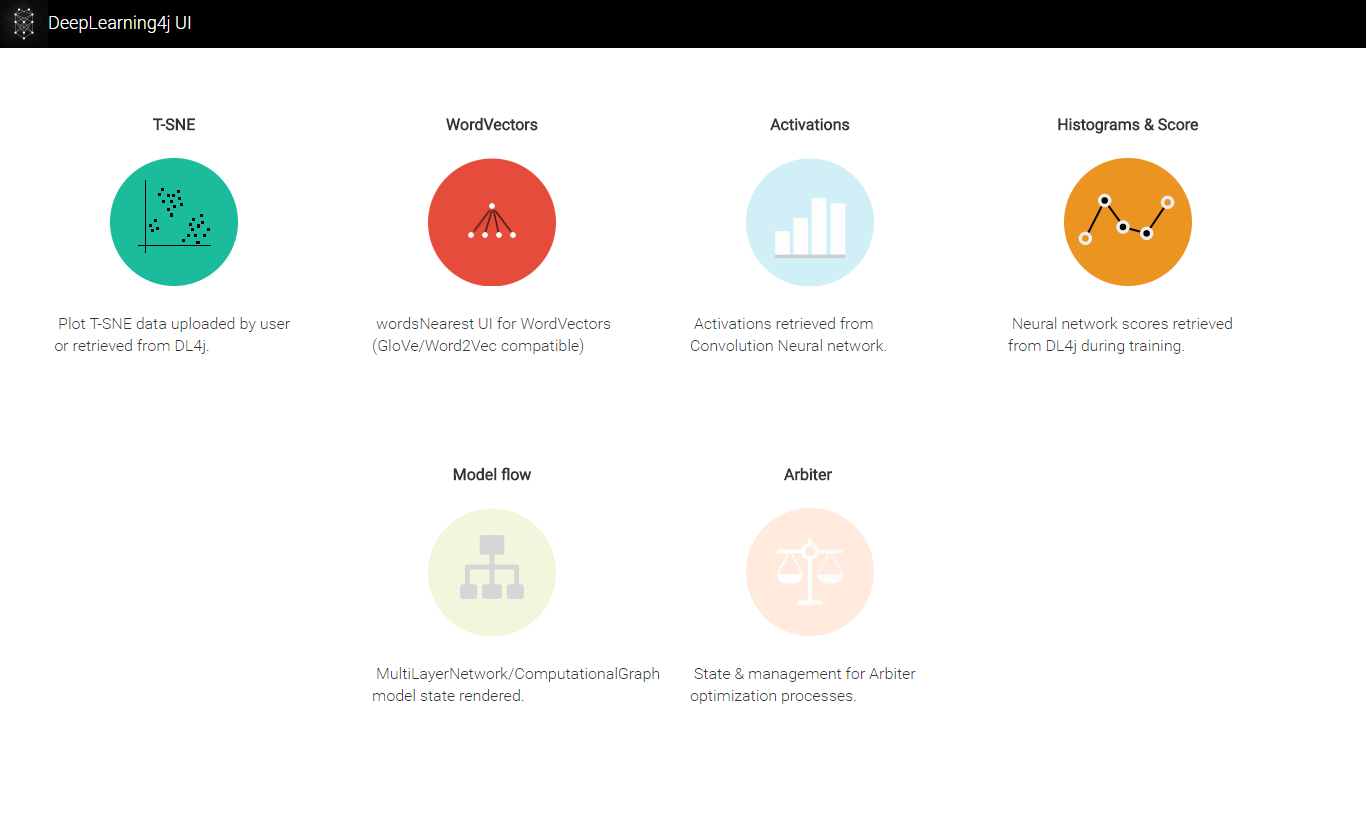
上図に示したように、tSNE, word2vec, model flowなどのUI Componentがありますが、今回はHistgram&Scoreを使ってみました。これを使うことで、Neural Network学習中のScore(Loss Function)の変化、Parameter・Gradientの更新を可視化することができます。
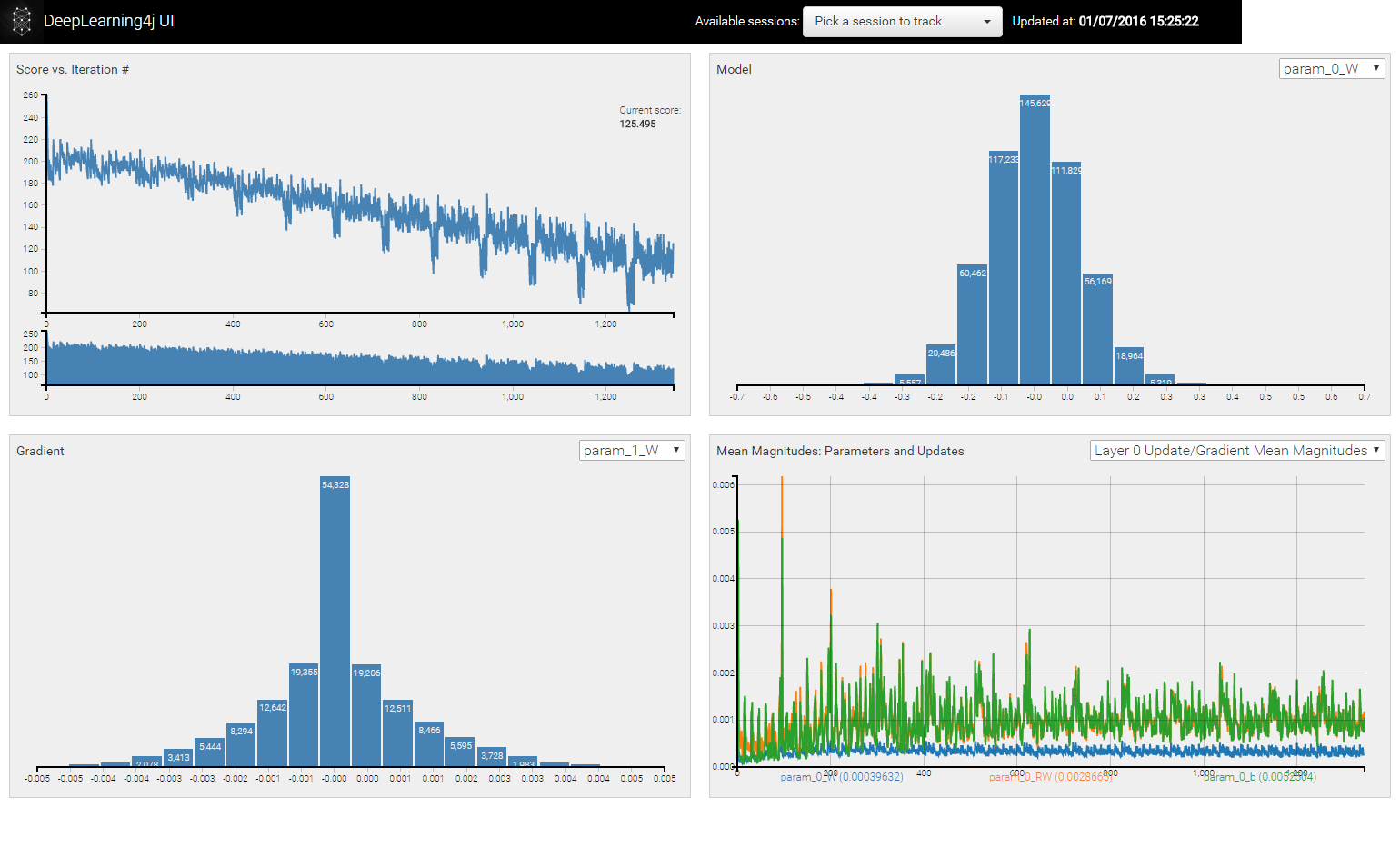
上図は今回記事生成モデルの学習過程です。左上は、Score(損失関数;縦軸)のIteration(横軸)ごとの値である。学習のIterationが増えるほど、損失Scoreが徐々に減少しているのがわかります。これを見て、Learning Rate、miniBatchの数、学習Sampleの数を調整することができます。右上は、各層の各種ParameterのHistogram(最新状態)です。基本的には、Gaussian分布になっています。もしImbalanceの分布になっていたら、Learning RateやL2 Regularizationを調整するべきだとわかります。左下は、各ParameterのGradient(厳密にはGradientにLearningRateなどを掛けた数値)のHistogramの最新状態です。Output層から離れるほど、Gradientの分布が0に集中する傾向があります。Gradientが0になるということは、Neuronが死んだことに相当するので、Drop OutやNeural Networkの構成を調整する必要があります。右下は、Parameterの平均値変化とGradientの平均値変化を示しています。特にGradientにスパイク的な変化があったとき、Neuronが死んだ可能性があります。またParameterの平均値があまり変化しないとき、変化が激しい時は、Learning Rate(場合によっては初期値)の調整をした方が良いとわかります。
次世代システム研究室では、ビッグデータ解析プラットホームの設計・開発を行うアーキテクトとデータサイエンティストを募集しています。ご興味を持って頂ける方がいらっしゃいましたら、ぜひ 募集職種一覧 からご応募をお願いします。
皆さんのご応募をお待ちしています。
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD