2016.07.01
Deep Learningによる株価変動の予想
次世代システム研究室のJK(男)です。初ブログです。
よろしくお願いします。
今回はディープラーニングの中でも、時系列解析に強いLSTM(Long short-term memory)を紹介します。時系列解析のひとつのターゲットが金融商品の価格予想です。最近、英国のEU離脱で市場が大荒れですが、そういう市場の荒れ具合を予想できたら色々と嬉しいですよね。そんな予想をディープラーニングでやってみた、というのが今回の主旨です。
この記事は、参考文献[1]の論文を参考にしました。今回の記事に興味を持ったら、ぜひ読んでみてください。
1. LSTM
LSTMは、RNN (Recurrent Neural Network)の改良版です。
そこで、まずRNNについて解説します。
RNNはディープラーニングの一種ですが、普通のニューラルネットと違い、現在の入力値に加えて自身の前の状態を入力しています。詳しい内容は、参考文献[2]やこのノートに譲り、ここでは概説のみします。RNNの入出力は、図1左のようになります。入力として、時間的に連続なデータx(= x_1, x_2, x_3, …, x_n)を考えたとき、x_tの入力と一緒に直前の状態s_t-1も入力されます。この「前の状態」は、それまでの過去の情報を含んでいます。つまり、RNNは現在の情報だけでなく、過去の情報も加味してyを出力します。このため、yを未来の値(= x_t+1)としたとき、入力された過去の情報を使って未来を予測できます。これを時間方向に展開すると図1右のようになります。横にDeepになっているのがわかると思います。
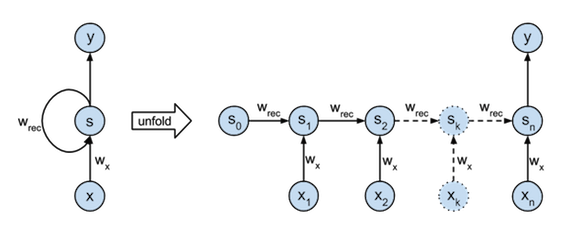 図1 RNNの概略図(参考文献[3]より借用)
図1 RNNの概略図(参考文献[3]より借用)
机上では上記のような素晴らしい効果が期待されたRNNですが、過去の情報をあまり覚えられないことがわかっています。この問題点を克服するために改良されたRNNがLSTMです。基本構造は普通のRNNと同じですが、図1のsと書かれているユニット部分が図2のようなLSTMブロックという複雑なユニットに置き換えられています。詳しくは、参考文献[2]やこの記事に譲りますが、LSTMブロックは前の状態を忘れる機能もあり、忘れることも「学習」していく、というのが特徴の一つです。LSTMによって時間データの解析が可能になっています。
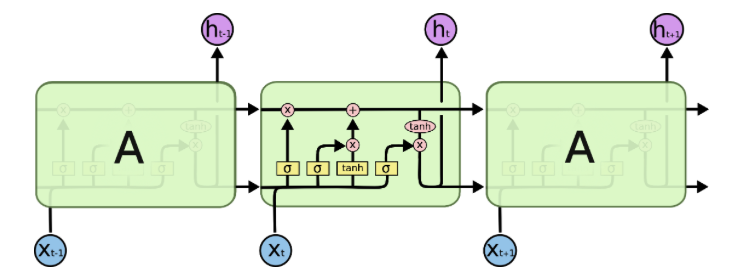 図2 LSTMの概略図(参考文献[4]より借用)
図2 LSTMの概略図(参考文献[4]より借用)
2. 株価の変動データ
今回は予測用のデータとして、米国の代表的な会社の平均株価(のようなものである)S&P500を用います。株価そのものを予想するのはランダム要素の影響が強く難しいので、今回は株価の変動を予想しました。ここでいう変動とは「株価が1日の間にどの程度変動したか」ということです。Daily volatilityとも言います。市場が荒れている時、株価が上下に振れます。その振り幅が大きいほど、変動が大きいということです。この変動が大きいほど株価の予想が難しくなり、予想するリスクが高くなります。
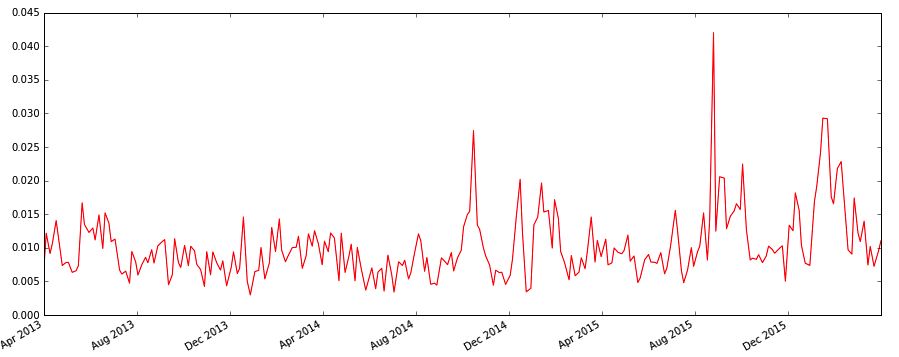 図3 S&P500の株価の時間変動(daily volatility)
図3 S&P500の株価の時間変動(daily volatility)
実際のデータは、図3のようになります。変動が小さい時期が続いた後、大きな変動が起きるとその後も大きな変動が続くように見えます。サイコロの目のようにランダムな振る舞いではなく、因果関係がありそうです。このような特徴を持っているので、時系列解析によって予測ができそうだと期待できます。
3. KerasによるLSTMの実装
実際にLSTMを使って予測するためには、Deep Learningのフレームワークが必要になります。今回はKerasを使いました。Kerasは、Tensorflow/Theanoをバックエンドに使ってDeep Learningが行えるフレームワークです。難しい箇所は全て裏側で行ってくれるため、表側のKeras部分は非常に直感的に書けます。しかもPythonで。これからDeep Learningを始めようという初心者にはとても優しいフレームワークです、と初心者な私が自信を持ってお薦めします。
実際、肝となるコード量はとても少ないです。下図のようにモデルを作ります。LSTMを入れて、アウトプットは1次元なのでDense(1)を入れています。アウトプットの関数は”linear”を指定。見て分かる通り、非常に直感的に書けます。

で、コンパイルをしたら

あとは学習するだけです。下図のような感じで、学習過程が見えます。
今回はデータ量が少なかったため、macbook airで数分も待てば結果が得られました。
4. 予測
準備の説明が長くなってしまいました。それでは株価の変動データを予測してみます。学習データとして、2008年4月-2012年4月のデータを使い、連続10日間のデータを入力値として11日目の株価変動の値を教師データとして使いました。これにより、11日目の変動値を予測するようにLSTMモデルが学習します。入力データは変動値に加え、日時収益率も使っています(気軽に入力データの種類を増やせるのも、Deep Leraningの利点です)。このデータを使って、上述の通りKerasを用いて学習させました。
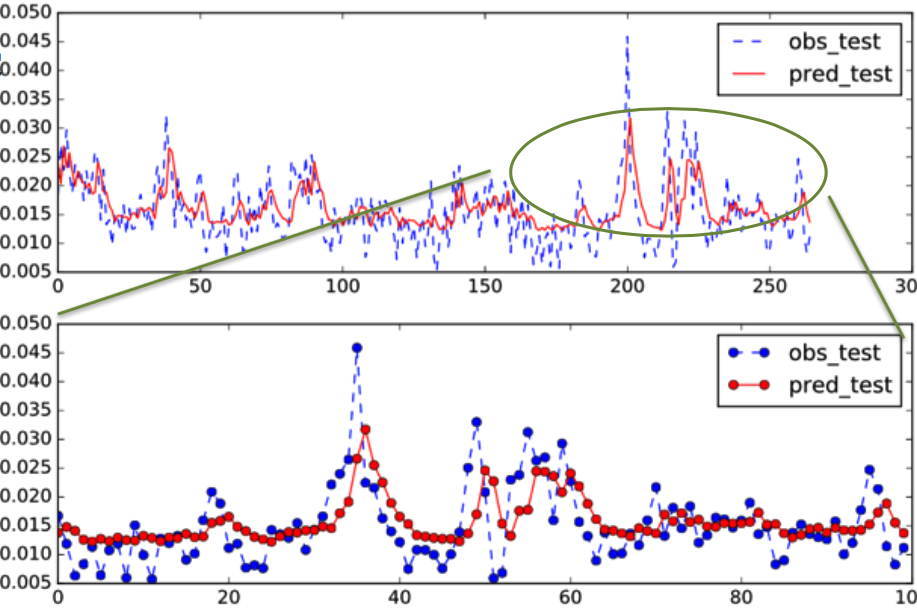
学習したモデルを使い、テストデータとして学習データとは異なる期間(2012年4月-2015年7月) の予想を行いました。下図が結果です。上パネルがテスト期間全体です。青が実データで、赤が予想データです。ちょっと長くて見づらいので、一部を拡大したものを下パネルに載せます。なんとなくトレンドは追っていますが後追いしているように見え、そのためズレが生じています。データと予測のズレを定量的に測定するため、今回はMAPE(各時間でのズレを平均したもの; 小さいほどズレが小さく良いモデルということ)を用います。このモデルのMAPEは29.3%でした。
5. 予測の改善
上記の結果はあまりよくなかったですね。過去のデータを使って予想しているので、ある程度の後追い予測になるのは仕方がないとはいえ、もう少し改善できないでしょうか。
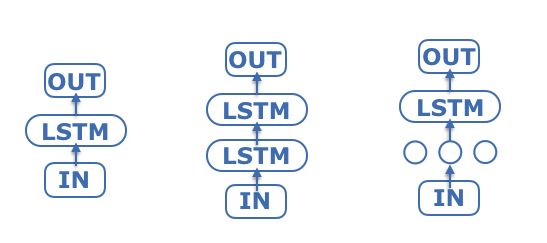
ここでは、改善案の一つとしてモデル構造を変えてみることにします。上記のモデルではLSTMは1層(図5左)でしたが、これを2層に増やしてみました(図5中央)。しかしMAPEの値は29.4%と改善は見られませんでした。別のモデルとして、LSTM層の前の層にlinear関数を持ったユニット層を入れてみました(図5右)。このときMAPEに改善が見られ、さらに学習回数も最適化した結果、MAPEは25.0%まで改善しました。モデル構造の変更することで、予測精度の改善が期待できるようです。
もう一つの改善の方向性として、入力データの質を上げるというものがあります。どんな素晴らしいモデルでも、入力データが悪ければ予想精度も悪くなります。今回はデータの質の改善を目的に、Google Domestic Trendsデータを入力データに加えました。このデータは米国でgoogle searchされたトラフィック量をトピックごとに指数化したものです。社会的な情勢を数値化したものになるのではと期待できます。今回は、4つのトピック(computer, credit card, invest, bunkruptcy)を入力データとして使いました。これらを加えた上で、上記の改善モデルを用いて学習して予測した結果、MAPEは23.7%まで改善しました。
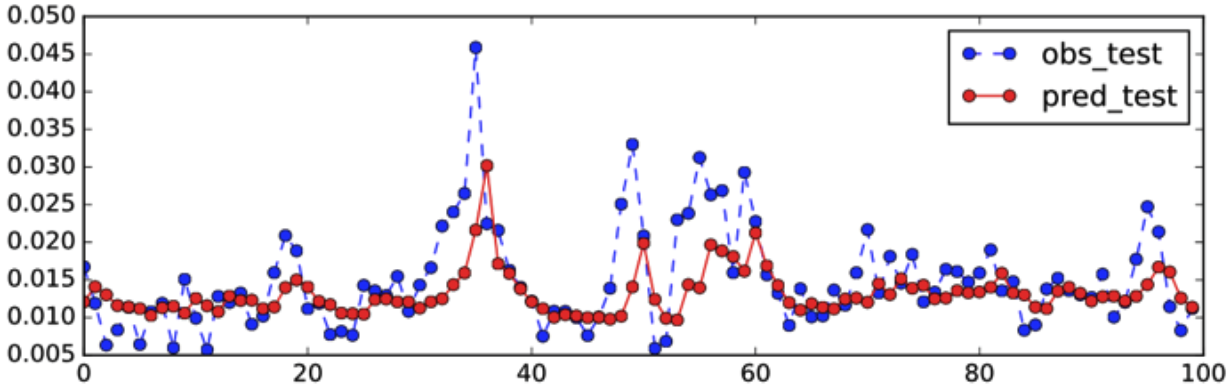 図6 変動データと改善したモデルによる予測カーブ
図6 変動データと改善したモデルによる予測カーブ
実データと予測値の比較は図6のようになります。最初のモデルと比べると、大きく変動した後に下がる箇所の予測は改善しています。注意点としては、新しいデータを加えた事による改善幅は1.3%と非常に小さいので偶然(統計的なゆらぎで)改善した可能性もあります。本当に良いモデルになったかどうかの判断は、別の期間でテストするなどもう少し慎重になる必要があります。が、今回はテストですので、そこまでは行いません。
6. 最後に
実は上記のテストデータの期間は、参考論文[1]と同じ期間を選んでいます。したがって、彼らのモデルの精度と直接比較ができます。彼らのモデルのベスト精度は24.2%です。この記事のモデルの精度は23.7%なので、若干とはいえこちらの方が良いモデルといえます。もちろんこの程度の差は有意とはいえないでしょうし、異なる期間で予想すれば逆転される可能性もあります。とはいえ、とりあえず勝ちは勝ちということで。
今回のモデルは、大きな変動の後に落ちていく部分は再現できていますが、上がっていく部分の再現精度はまだまだです。モデル構造を改善するのか、もっと良いインプットデータをいれるのか、はたまた別のパラメータをいじるのか、多分その全てだと思いますが、改善の余地はまだまだあります。これから色々と試していきたいと思いますが、とりあえず今回はここまで。
参考文献
[1] “Deep Learning Stock Volatility with Google Domestic Trends” R. Xiong et al. arXiv:1512.04916v3
[2] 深層学習 (機械学習プロフェッショナルシリーズ) 岡谷貴之 講談社
[3] Peter’s note
[4] colah’s blog
次世代システム研究室では、ビッグデータ解析プラットホームの設計・開発を行うアーキテクトとデータサイエンティストを募集しています。ご興味を持って頂ける方がいらっしゃいましたら、ぜひ 募集職種一覧 からご応募をお願いします。
私自身、この4月より天文学のポスドクから機械学習という全く新しい世界に来ました。学ぶこともたくさんありますが、データ解析である以上、共通点もたくさんあります。未来を担う技術である機械学習、ディープラーニングに興味のある方は思い切って飛び込んでみるのも一興かと。
皆さんのご応募をお待ちしています。
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD




{kind=link}
{kind=link}