2023.01.11
信用スコアリング検証
はじめに
こんにちは、グループ研究開発本部 AI研究開発室のS.Sです。
とあるサービスに関連して信用スコアリング周りの技術の検証を行なったので今回はその内容について書きたいと思います。
一般の企業や消費者に対して融資を行う場面において、信用リスクが高い利用者は長期的にみると経済状況の変化などで返済が滞ってしまう懸念があります。
そこで消費者に対する融資ではそれまでの融資の履歴データ(延滞の有無や現在の負債)などをもとに算出した信用スコアを、融資の可否や融資額の判断などに用いるとされています。
今回の記事では信用スコアを用いた融資から生じるリスクを一定に抑えるための方法について考えてみたいと思います。
融資から生じるリスクの2つの視点
1件単独の信用リスク
1件単独の信用リスクの判断ではユーザーの延滞の有無や収入に対する負債の割合などユーザーのこれまでの融資の情報をもとにどのくらいの確率で貸倒が発生するのかを見積もった上で、融資の可否や融資金額・金利などを決定します。
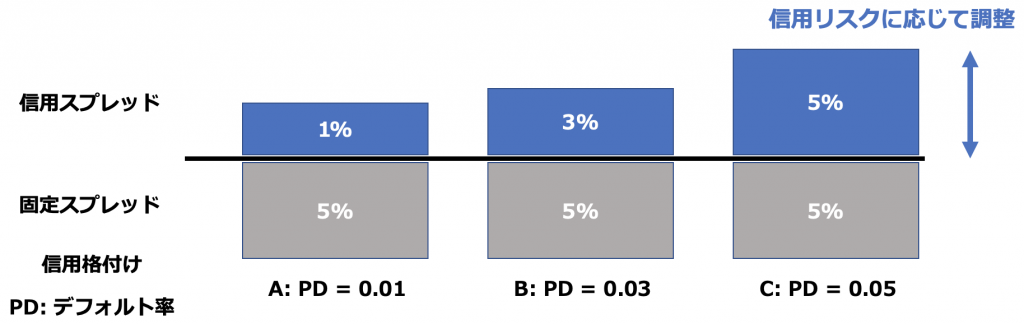
利用者の信用リスクに応じて金利の構成要素のうち信用スプレッドの部分を調整することで、どの借り手に対して融資をしても一定の収益が得られるようになります。
融資全体での信用リスク
多数の利用者に対して同時に融資を行う貸手にとって、融資全体での信用リスクの評価も必要です。
経済状況の移り変わりによって不況におちいったときに借り手が一斉に貸倒になってしまう可能性が高くないかどうかといったような観点で検討を行います。
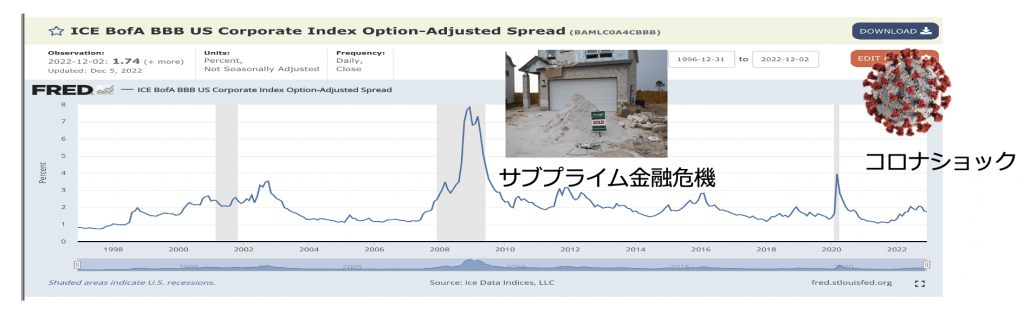
直近20年間の米国の格付けが低いBBBの社債の金利をみてみると、金融危機やコロナショックなど不況の時期にスプレッドが広がっていることがわかります。
これはつまり不況の時に市場は格付けの低い社債を発行する企業がデフォルトに陥る可能性が高いという見方をしているということになります。
融資を行う時は単独の貸倒リスクと全体の貸倒リスクの2つの視点でリスクを評価する必要があります。
1件単独の信用リスクの扱い: 信用スコアリング
既存の枠組み
まず融資における信用リスク評価の既存の枠組みを簡単に説明したいと思います。
企業の信用リスクの評価の枠組みとして信用格付けがあり、消費者の信用リスクの評価には米国などでは信用スコアが使われます。
- 信用格付け
- 企業が発行する社債などの信用リスクをA,B,Cのような段階で格付け
- 例: S&P, Moody’s, Fitch Ratings
- 信用スコア
- 利用者の返済履歴などの情報に基づいて300~850のような範囲のスコア
- 例: FICO Score, Vantage Score
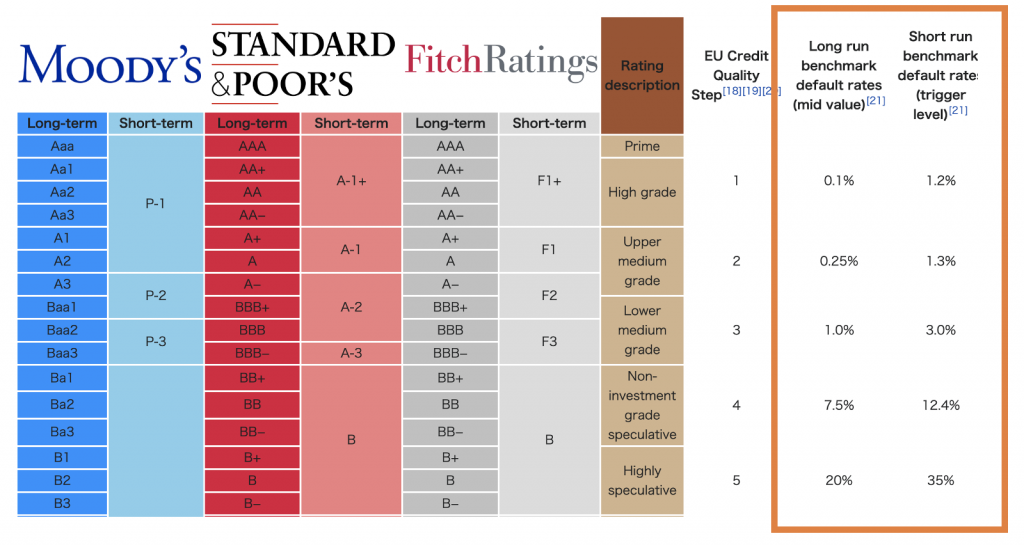
以下では例として信用格付けのイメージ図をwikipediaより引用しました。
右側の列がそれぞれの格付けの推定デフォルト率を示しています。
信用リスク評価の5つのファクター
消費者の信用リスク評価に使われる信用スコアでは、大きく分けて5つの主要ファクターを判断材料に使っているとされています。
- 支払い履歴
- 借りたお金を期限までに返済できているか
- 借りたお金を期限までに返済できているか
- 負債金額
- 見込みの収入に対してどのくらいの負債があるか
- 見込みの収入に対してどのくらいの負債があるか
- 履歴の長さ
- 長くクレジットカード・ローンを利用した履歴があるか
- 直近の履歴
- 直近でローンの申請をしたか
- 新しくクレジットカードを作ったか
- 種類
- 住宅ローン・カーローン・クレジットカードなどで利用実績があるか
信用スコアリング実践
それでは利用者の信用リスクを評価して融資判断に活かせるかどうか実データを使って検証をしてみたいと思います。
この信用スコアを正確に見積もることができれば、利用者の信用リスクに応じて融資の可否や適用金利などを判断する材料の一つとしてスコアを用いることができます。
今回利用するデータセットはKaggleで公開されているHome Credit Default Riskデータセットを用います。
この課題では審査時の借り手の情報をもとに新規の融資で利用者がデフォルトするかどうかを予測するというものです。
多くの借り手は1ヶ月ごとに均等返済する12ヶ月のローンを利用しています。
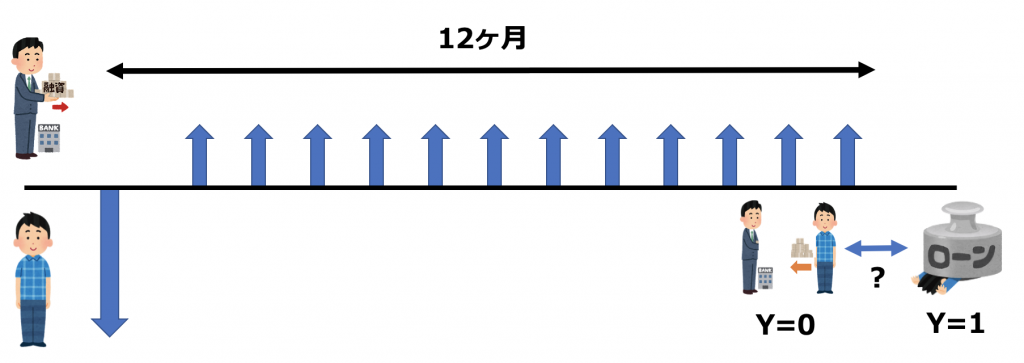
データセットにはデフォルト予測のために次のような形で借り手の情報が提供されています。
| 新規借入時の情報 | •金額
•返済期間 •収入 |
| 過去の借入データ | •金額
•返済履歴 |
| クレジットカードの
利用履歴 |
•返済履歴
•トータル負債 |
| 信用調査期間の履歴 | •他の金融機関での融資の返済履歴
•問い合わせの有無 |
今回は単独と全体の信用リスクの両方の視点を扱いたいので、信用スコアのモデリングに注力しすぎず特徴量の数を絞ってシンプルなモデルを用います。
特徴量の数を絞るメリットとしてはデフォルトの履歴のデータがそもそも集まりにくいという性質や利用履歴が短い利用者に対しても参考となるスコアを提供したいという背景もあります。
モデルに関しても出力スコアの較正が必要なく推定の誤差が小さいシンプルなモデルを選ぶことにします。
上記を考慮した上で主要ファクターをもとに以下のような特徴量を作成しました。
| 新規借入時の情報 | •金額
•返済期間 •収入 |
| 過去の借入データ | •金額
•返済履歴 |
| クレジットカードの
利用履歴 |
•返済履歴
•トータル負債 |
| 信用調査期間の履歴 | •他の金融機関での融資の返済履歴
•問い合わせの有無 |
検証を行う条件は以下のように設定しました。
| データ件数 | 30万件 |
| 特徴量 | 11次元 |
| ラベル | binary(デフォルト有無) |
| 性能検証 | 3-fold CV |
| モデル | Random Forest |
上記の設定で検証を行なったところ、テストデータに対する貸倒の有無の予測精度(AUROC)は以下のようになりました。

このHome Credit Default RiskのコンペのLeaderBoardのTOPスコアの0.805には遠いですが、分類器の精度としてまずまずのレベルというところです。
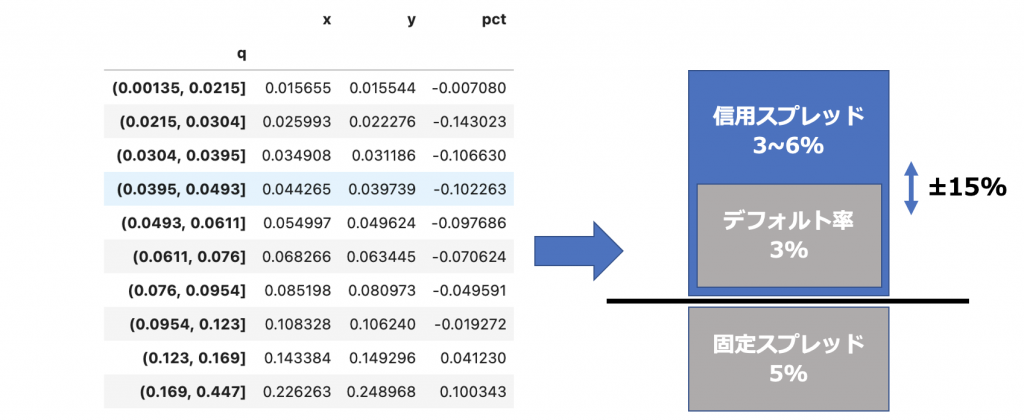
次にモデルが出力したデフォルト確率が、実際のデフォルト率とどのくらい乖離しているかをみてみます。
予測したデフォルト率(x)に対して実際のデフォルト率(y)とのズレは、最大で15%ほどにおさまっています。
実際の金利では推定デフォルト率のズレを考慮して、信用スプレッドを少し大きめに設定するので、今回のモデルの出力をもとに金利を設定すれば、一定の収益を上げることができそうです。
(もちろん正確な評価には長期のデータが必要になりますが、この記事ではスコープ外とします。)
全体の信用リスクの扱い: ポートフォリオ最適化
ここまでで1件単独の信用リスクの評価をする方法として信用スコアをご紹介しましたが、ここからは景気変動などにより、借り手が同時にデフォルトしてしまう可能性を考慮して、全体のリスクを一定に抑える方法についてみていきたいと思います。(図は一部wikipediaより引用)
最適化問題
借り手への融資で一定の収益をあげつつリスクをなるべく小さくするために、次のようなポートフォリオ最適化問題として定式化します。
問題を組み立てる上で4つの制約を考慮します。
- 借り手へのローンのreturnの相関をASRFモデルにそって計算(計算方法は後ほど説明)
- 期待returnは信用リスクに応じた信用スプレッドをのせているのでどの借り手でも同じとする
- 借り手との取引は融資のみ(全てxの成分は非負)
- 全体の予算を正規化
最適化する変数としてどのくらいの割合を融資金額として割り当てるかを示す変数xを導入します。
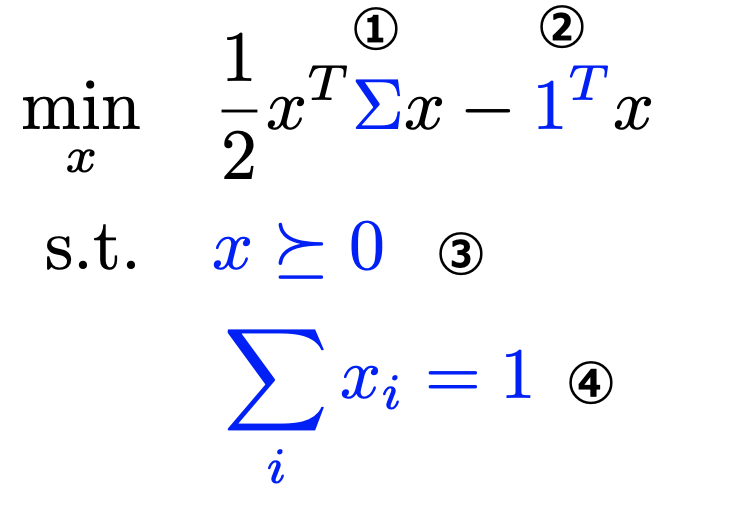
上記で定式化した問題は2次計画法に当たるので、一般的な凸最適化のソルバ(cvxoptなど)で解くことができます。
ASRFモデル
ローンのリスクの相関を計算するためのモデルとしてAsymptotic Single Risk Factor(ASRF)モデルを導入します。
このモデルでは借り手の仮想的な資産が負債を下回った時にデフォルトが発生するというモデルです。
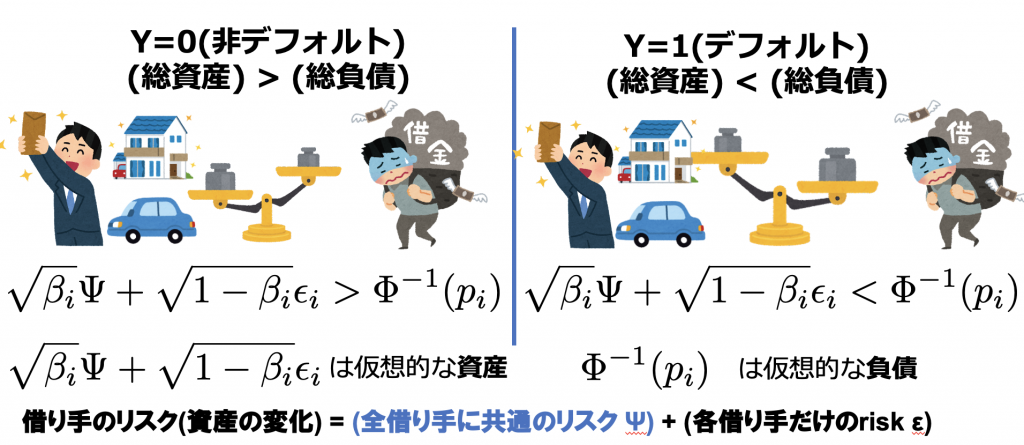
借り手のリスクには経済環境の変化のような現象を表すために全借り手に共通のリスクファクターを含めます。
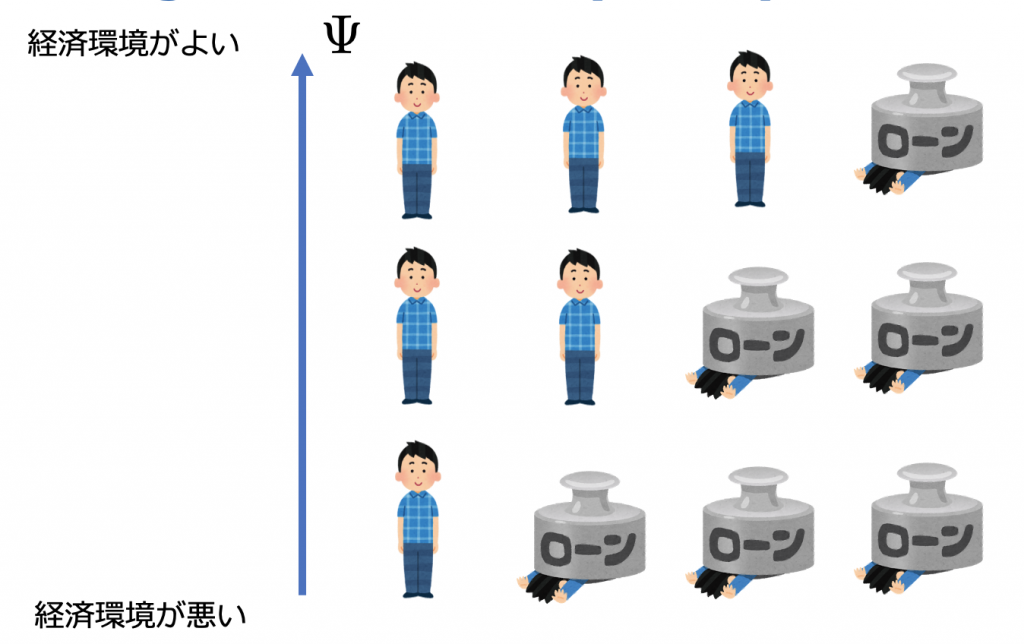
このモデルを使って長期間のデフォルト(Y_1, …, Y_t)をシミュレーションして融資のreturnの相関行列を計算し、最適化問題のインプットとします。
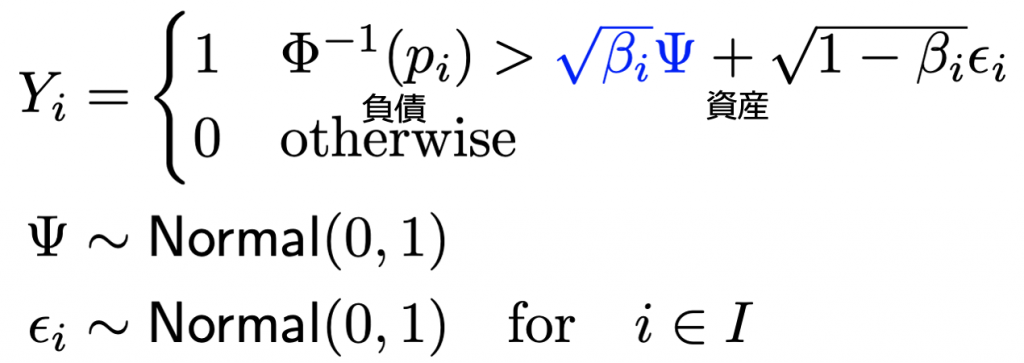
モデルのパラメータとして借り手に共通のリスクファクターがどのくらいデフォルトと相関があるかを指定するβというパラメータがあり、こちらは長期のデフォルト履歴のデータから推定することができますが推定方法は割愛します。
ポートフォリオ最適化実践
ここまでポートフォリオ最適化を行うために必要な材料が揃ったので、シミュレーションのデータを使って以下のような条件で実際に最適化をしてみます。
| 対象の借り手 | •デフォルト率が3%以下
•ランダム抽出した1000件の借り手 |
| 合計融資額 | •1件あたり100万円 * 1000件 = 合計10億円 |
| インプット | •それぞれの借り手のデフォルト率のみ |
| アウトプット | •それぞれの借り手の融資金額 |
| ベースライン | •対象の借り手にまんべんなく貸した場合 |
最適化をした結果、融資金額の割り当ては次のようになりました。
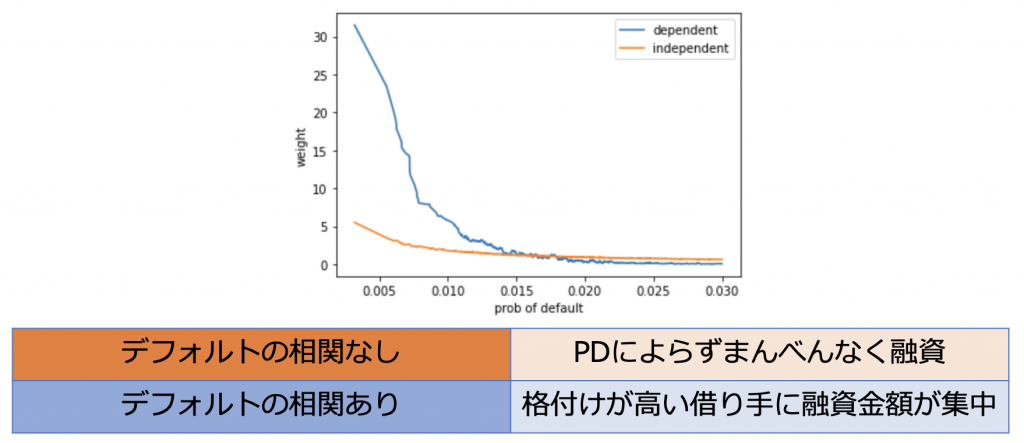
デフォルトの相関があると仮定した場合はデフォルト率によらず全体にまんべんなく融資を行うのではなく、デフォルト率が低い(格付けが高い)借り手に対して集中的に融資を行うような結果になっています。

ポートフォリオ最適化を行なった結果、まんべんなく融資を行なった場合と比べてリスクあたりのリターンは15%ほど改善しています。
まとめ
今回の記事では適切なリスク評価に基づく融資を行うために、1件単独と全体の信用リスクの2つの視点での評価方法について検証しました。
1件あたりの信用リスクの扱いに関しては、借り手の履歴データをもとに5つの主要ファクターを入れて信用スコアを算出し、融資の可否や金利の設定の判断材料として用いることで一定の収益を出せることがわかりました。
全体の信用リスクの扱いに関しては、経済環境の変化により同時にデフォルトが起きる現象を考慮したポートフォリオ最適化問題として定式化することで、一定の収益を達成しつつリスクをなるべく小さくおさえるような予算の割り当てができることがわかりました。
最後に
グループ研究開発本部 AI研究開発室では、データサイエンティスト/機械学習エンジニアを募集しています。ビッグデータの解析業務などAI研究開発室にご興味を持って頂ける方がいらっしゃいましたら、ぜひ 募集職種一覧 からご応募をお願いします。皆さんのご応募をお待ちしています。
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD