2020.10.06
Low Code機械学習ライブラリPyCaret2.1で機械学習パイプラインを検証してみた
はじめに
こんにちは。次世代システム研究室のT.D.Qです。
ローコードはコーデイング量が極限まで減らすことで高生産性を実現するためのITツール・プラットフォームのことで、最近流行っていますね。機械学習のローコードにおいては、PyCaretが注目されています。PyCaretはPythonのローコードな機械学習ライブラリで、機械学習実験における仮説から洞察までのサイクル時間を減らす目的でオープンソースとして公開されています。機械学習タスクを単純化し、使いやすくそして配備も完備しているので、データサイエンティストが数行のソースコードだけで機械学習パイプラインを構築できます。このため、データサイエンティストにいろいろな実験を素早く効率的に遂行することを可能にします。下図は、PyCaretで実現できる工程です。
![]()
今回は、最新版のPyCaret2.1を使って、クレジットカードのデフォルト(バイナリ分類)問題のパイプラインの構築を検証したいと思います。
検証環境構築
以下は今回の記事で構築した検証環境の情報です。
・基盤:GPUクラウド by GMOの1GPUプラン
・Platform:Anaconda Docker Image(continuumio/anaconda3)
PyCaretのインストール
・PyCaretの最新安定版(2.1.2)をインストールする
pip install pycaret
・モデル解釈するため、SHAPをインストールする。PyCaretはSHAPをサポートするので便利です。
conda install -c conda-forge -y shap
・探索的データ解析のLow Codeツールの「pandas-profiling」をインストールする
conda install -c conda-forge -y pandas-profiling
PyCaretは各モデルを実験検証するとき、履歴ログを自動的に収集してGUIで確認するため、MLFlowと連携するので、MLFlowをインストールします。
pip install mlflow
MLFlowを起動しておきます。MLFlowのサービスが5000番ポートを使います。Container内で起動しますので、ホストが0.0.0.0に指定することでContainerの外からアクセスできるようになる。
mlflow ui --host 0.0.0.0
検証パイプラインの実装
データ準備
今回は、PyCaretの機能検証を中心に検証したいので、PyCaretが提供するクレジットカードのDefaultデータセットを使います。これはクレジットカードの支払情報データセットで、性別、最終学歴、結婚の有無、過去の支払い状況、これまでの支払い履歴や請求明細などが含まれます。
from pycaret.datasets import get_data
data=get_data('credit')

Low Code EDAを検証する
データを理解するため、探索的データ分析(EDA)をやります。このプロセスを自動化するPandas Profilingライブラリを使うとコード3行だけで詳細なインターラクティブレポートを生成するので非常に便利です。
from pandas_profiling import ProfileReport profile = ProfileReport(data, title="Credit Data Report") profile.to_widgets()
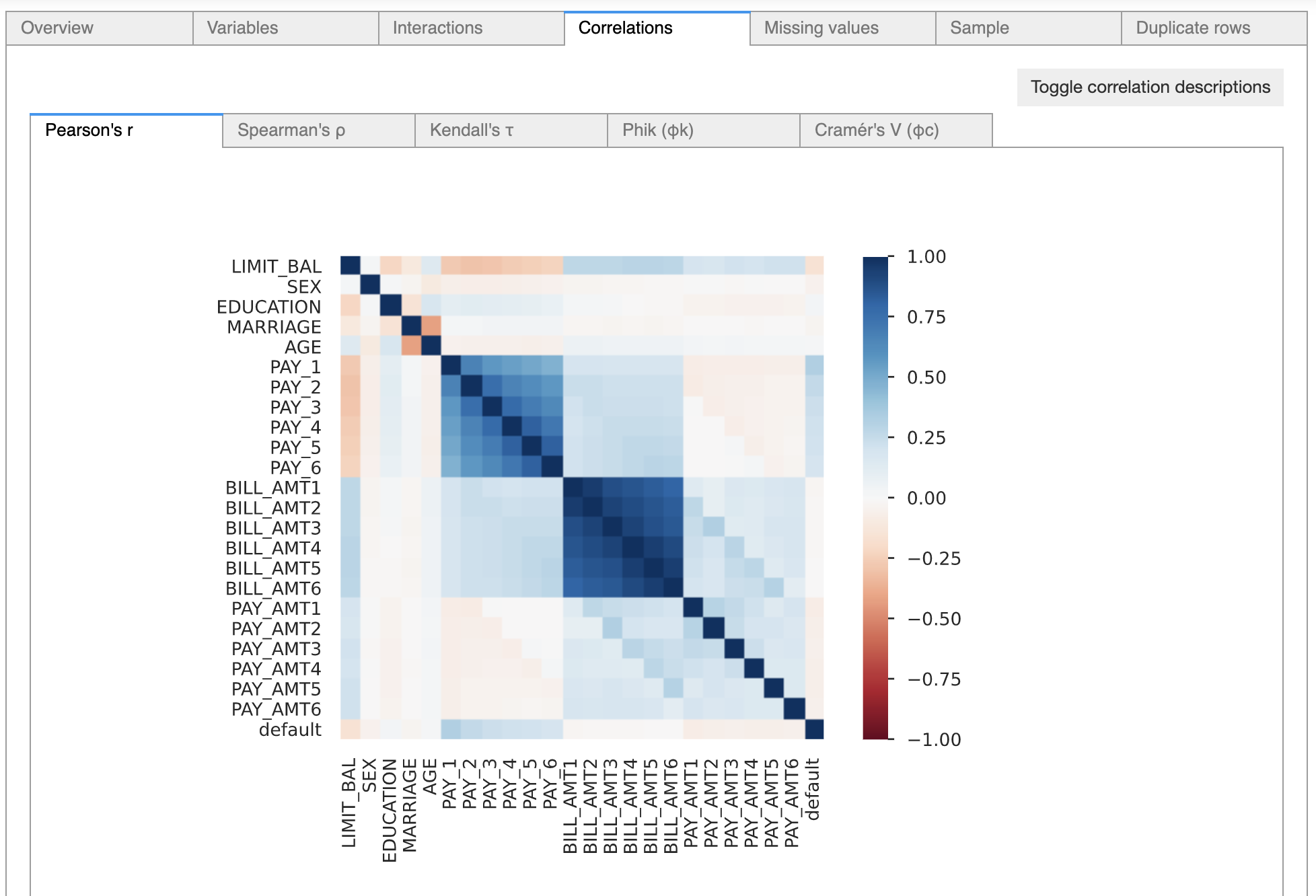
データの各次元の基本的な統計量や相関関係などを確認すると、以下の問題を確認できました。
・データ重複
・不均衡データ(class imbalance)
・相関性の高い特徴量が存在
機械学習パイプラインの定義
以下のソースコードを実行することで機械学習パイプラインの作成ができます。今回は分類問題を解くので、pycaretのclassificationモジュールを指定しています。
# 重複データを削除する
data.drop_duplicates(inplace=True)
from pycaret.classification import *
classifier_model= setup(data, # トレーニングデータ
target='default', # 目的変数
fix_imbalance=True, # 不均衡データ問題を自動的に解決(SMOTを使う)
remove_multicollinearity=True, # 相関性の高い特徴量を処理する
ignore_low_variance=True, #
session_id=10003, # 内部的の乱数Seed
log_experiment=True, # MLFlowに学習履歴ログを記録する
experiment_name='Credit Default Prediction Experiment' # MLFlowの実験名を設定)
setup()から出力された機械学習内容は下図の通りです。背景色の緑部分は、今回自分がDefault設定から変更した内容です。
![]()
![]()
Train-Testデータセット分割は特に指定してないですが、自動的にデフォルト割合(train:test=0.7:0.3)で分割されていますね。
複数モデルを比較し、ベースラインモデルを選定
モデルを比較し選択していきましょう。
以下のコマンドでPyCaretがサポートするモデルを順次に実行して評価するための指標一覧をランキングで出力してくれます。
best_model = compare_models()
![]()
Gradient Boosting Classifierモデルが一番良さそうですね。このモデルをベースラインモデルとして使ってみたいと思います。
予測モデルを作成する
今回の検証は、上記のモデル比較似てTop 5になかったRandom Forest Classifierモデルを選んで、その後どの位精度改善できるか検証したいと思います。
# Random Forest Classifier
rf_classifier = create_model('rf')
![]()
ハイパーパラメーターチューニング
モデルのハイパーパラーメーターをチューニングするため、以下のコマンドを実行するだけですね。他のパラメーターを設定可能ですが、今回はDefault設定でモデル改善できるか検証したいということでソースコードの最小限で実行します。
tuned_rf = tune_model(rf_classifier)
![]()
見事、Accuracy、AUC、Presision、Recall指標が改善されましたね、良さそうです。
モデルの学習結果可視化
PyCaretがplot_modelメソッドでモデル学習後に学習に関する情報を可視化する機能をサポートしています。
# Confusion Matrixを可視化する plot_model(tuned_rf, plot='confusion_matrix')
![]()
また、複数の指標を確認したいときは、以下のコマンドで確認可能です。
evaluate_model(tuned_rf)
![]()
モデル予測結果の確認
チューニングしたモデルで予測を行いましょう。PyCaretがテストデータを管理してくれるので指定しなくても良いです。
pred_result = predict_model(tuned_rf)

予測結果絡みるとトレーニング時の結果より少し良いですね。
モデル予測結果の解釈
モデルの解釈はSHAPを用いて行いました。モデルの解釈についても面白いテーマですが、グラフの見方及び解釈方法の詳しく説明は別の機会にしたいと思います。
interpret_model(tuned_rf)
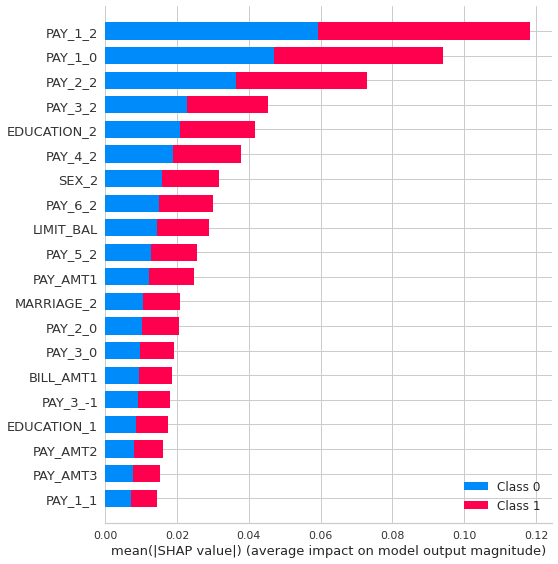
interpret_model(tuned_rf, plot='reason', observation=12)

interpret_model(tuned_rf, plot='correlation', observation=320)
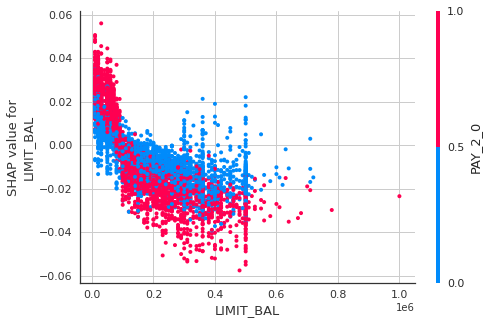
モデル保存
チューニングしたモデルを保存したいときは、以下のコマンドを実行するだけで完了です。PyCaretはモデールをロードするとか、AWSに確定したモデルをリリースする機能を揃っているので、とても便利です。
save_model(tuned_rf, model_name='tuned_rf_model')
トレーニング履歴確認
MLFlowを確認しましょう。自分がMLFlowを検証してみた時、MLFlowの設定・実装に時間かかったことを思い出しましたが、今回はほとんど設定しなくても、検証したモデルの学習履歴ログをMLFlowに自動的に記録されてもらって驚きました。
![]()
システムログ確認
PyCaretは裏側にシステムログがあって、検証するときに色々な情報をログします。機械学習パイプラインを自動化したロジックの裏側に何か実行されたか、デバッグしたいときなどにこのログを確認した方が良いですね。
get_system_logs()
![]()
所感
今回は、PyCaret、Pandas-ProfilingというLow Codeライブラリを使って、Credit Card Fraud Detection問題の機械学習パイプラインを検証してみました。想定の通りにソースコードを数行だけで、データインポートしてからデータの前処理、モデル選定、ハイパーパラメーターチューミング、モデル予測結果評価、モデル予測結果の解釈、学習履歴記録まで全部実現することができました。サポートしている機能が実用性が高く、簡潔なコードで実現できるので大幅な時間短縮に繋がることを感じました。PyCaretは機械学習の民主化のため、Version 2.1からAutoMLのサポートもできるようになりましたので、さらに便利です。検証してPyCaretの進化に期待することは、GPUのサポートをもっと充実になることと、Deep Learningモデルをサポートすることですね。それでは!
最後に
次世代システム研究室では、ビッグデータ解析プラットホームの設計・開発を行うアーキテクトとデータサイエンティストを募集しています。次世代システム研究室にご興味を持って頂ける方がいらっしゃいましたら、ぜひ 募集職種一覧 からご応募をお願いします。
皆さんのご応募をお待ちしています。
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD