2019.07.03
機械学習サービスライフサイクルを管理するMLFLow 1.0の実力を検証してみる!
こんにちは、次世代システム研究室のT.D.Qです。
直近、機械学習のライフサイクルを管理できるPythonライブラリ・フレームワークについて調査しました。その中にMLFlowが面白いなと思って今回の記事で紹介したいと思います。
MLflowは、オープンソースで、機械学習処理のライフサイクル(実験・再現・デプロイ)を管理するプラットフォームです。機械学習ライブラリー(scikit-learn, Keras, TensorFlowなど)や言語(Python、Java、R)に依存しない、他の人と共有しやすいのが特徴で、機能として下記の3つで構成されています。
- MLflow Tracking : 学習の実行履歴管理
- MLflow Projects : 学習処理の実行定義
- MLflow Models : 学習モデルを用いたAPIサーバの実行定義
今月の頭(6月4日)にベージョン1.0が正式に公開されたので、運用しているHDPにインストールして検証してみました。今回はMLFlowを中心に紹介したいので、本記事ではMLflow1.0のsklearn_elasticnet_wineコードを扱います。
検証環境
前回の記事で構築したHDP3.1にMLFlowをインストールして検証しました。MLFlowのインストールはシンプルで、Python3(今回は3.6.8)を先にインストールして、そのPython3環境で下記のコマンドを実行するだけで済みます。
# pip3.6 install mlflow
インストール後、mlflowが動作するための各Pythonパケージもインストールされました。実装はZeppelin 0.8.0(python interpreterを別途インストールする必要)で行います。
注意点:リモートサーバに設定したハイパーパラメーターや評価指標が問題なく記録できますが、学習したModelがうまく保存できないようです。調査してみたらZeppelinサーバに保存されてしまいます。まあ、Rsyncといった解決策はいくつかあると思いますが、MLFlowのArtifactやModelを正しく保存するため、MLFlowのTrackingサービスをZeppelinサーバに起動した方が楽です。
MLFlow Tracking
MLflow Trackingは学習の実行履歴を管理するための機能です。MLFlowサーバを起動し、MLFlow Trackingの管理画面にアクセスすると実行履歴を確認できます。早速、クラスター上のMLFlowサーバーを起動します。
mlflow server --backend-store-uri /mlruns/ --default-artifact-root /mlruns/default --host 0.0.0.0
注意点は、「--host 0.0.0.0」のオプションですね。指定しないとMLFlow Trakingの管理画面にアクセスできない可能性が高いです。
実験するソースコードにMLFlow TrackingのURLを設定しましょう
import mlflow mlflow.set_tracking_uri("http://{ml_flow_server_host}:5000".format(ml_flow_server_host=ml_flow_server_host))
モデルの評価指標値の記録
# 「rmse, mae, r2」を記録するため、指標評価関数を定義する
def eval_metrics(actual, pred):
rmse = np.sqrt(mean_squared_error(actual, pred))
mae = mean_absolute_error(actual, pred)
r2 = r2_score(actual, pred)
return rmse, mae, r2
学習を行なって、学習時の情報を記録するため、MLFlowコードと学習コードに下記のように組み合わせする必要があります。
def train(in_alpha, in_l1_ratio):
warnings.filterwarnings("ignore")
np.random.seed(40)
# wine-quality.csvのデータセットをDataFrameにロードする
wine_quality_data_path = "https://raw.githubusercontent.com/mlflow/mlflow/master/examples/sklearn_elasticnet_wine/wine-quality.csv"
data = pd.read_csv(wine_quality_data_path)
data.head(10)
# トレーニングセットとテストセットを 0.75:0.25で分割する.
train, test = train_test_split(data)
# 目的変数が[Wineの質]ですので、Train、Testを整理する
train_x = train.drop(["quality"], axis=1)
test_x = test.drop(["quality"], axis=1)
train_y = train[["quality"]]
test_y = test[["quality"]]
# alphaのデフォルト値を設定する
if float(in_alpha) is None:
alpha = 0.5
else:
alpha = float(in_alpha)
# l1_ratioのデフォルト値を設定する
if float(in_l1_ratio) is None:
l1_ratio = 0.5
else:
l1_ratio = float(in_l1_ratio)
# MLFlowに記録するため、MLFLow Trackingを起動する
with mlflow.start_run():
# ElasticNetを実行する
lr = ElasticNet(alpha=alpha, l1_ratio=l1_ratio, random_state=42)
lr.fit(train_x, train_y)
# 指標を評価する
predicted_qualities = lr.predict(test_x)
(rmse, mae, r2) = eval_metrics(test_y, predicted_qualities)
# 評価指標を出力
print("Elasticnet model (alpha=%f, l1_ratio=%f):" % (alpha, l1_ratio))
print(" RMSE: %s" % rmse)
print(" MAE: %s" % mae)
print(" R2: %s" % r2)
# MLFlowにパラメーター、評価指標及びモデルを記録する
mlflow.log_param("alpha", alpha)
mlflow.log_param("l1_ratio", l1_ratio)
mlflow.log_metric("rmse", rmse)
mlflow.log_metric("r2", r2)
mlflow.log_metric("mae", mae)
mlflow.sklearn.save_model(lr, path='my_model{0}_{1}'.format(in_alpha, in_l1_ratio))
mlflow.sklearn.log_model(lr, "model{0}_{1}".format(in_alpha, in_l1_ratio))
mlflow.log_artifact(local_path="my_model{0}_{1}/model.pkl".format(in_alpha, in_l1_ratio))
ElasticNet modelのAlphaとL1_ratioを変更して実験を行い、指標を確認してみます
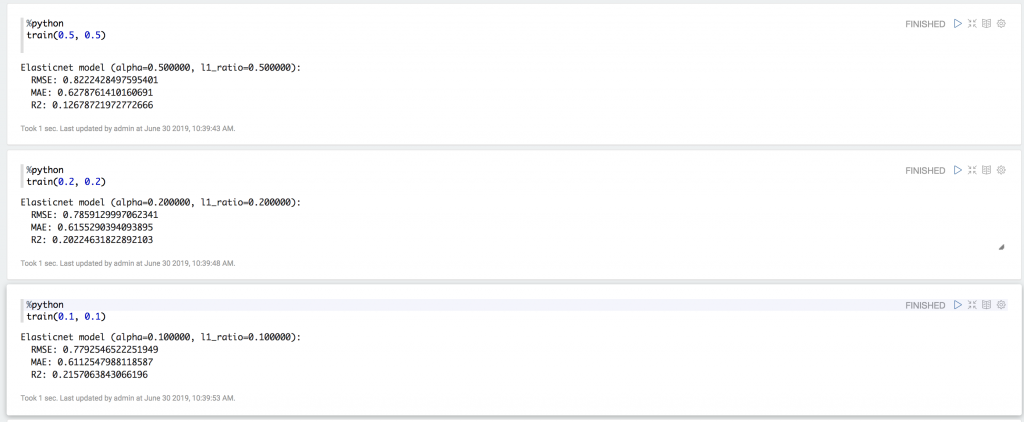
MLFlow UIで学習済みモデルの確認
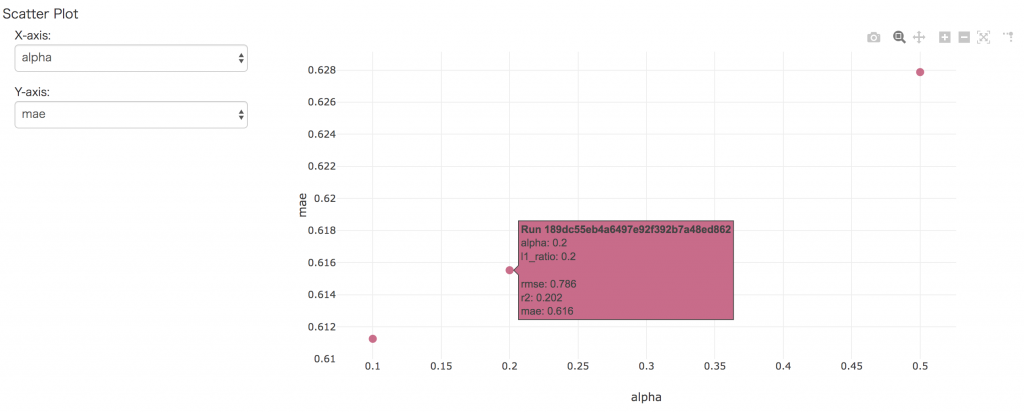
ChromeなどでMLFlow Serverにアクセスすると、MLFlow UI画面が表示されます。先ほどの実験3件も記録されましたね。パラメータとMetricsもこの一覧画面で確認できます。
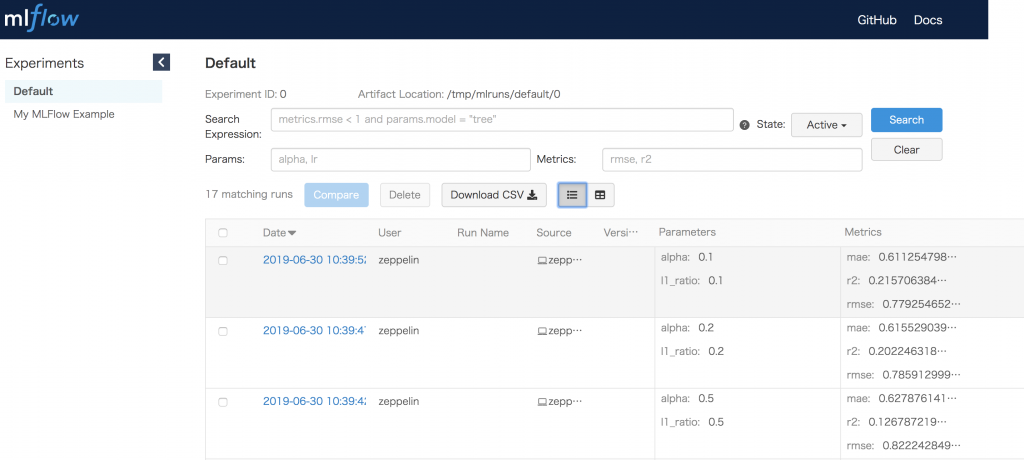
実験で記録した情報の詳細
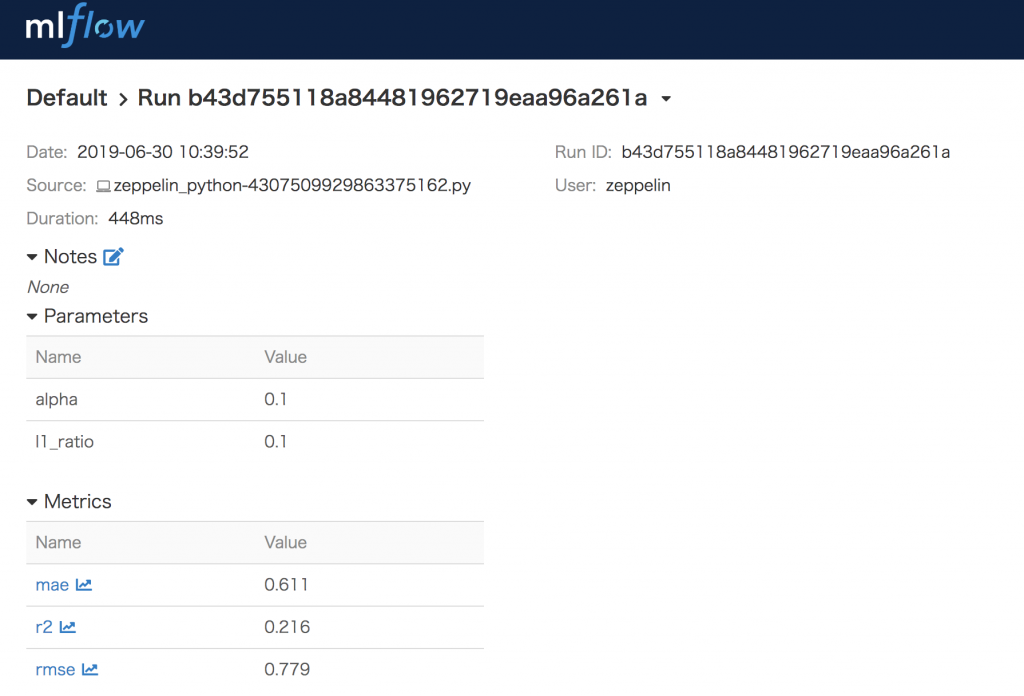
実験詳細画面で記録した情報の詳細を確認しましょう。この画面では、誰(User)がいつ(Date)何(Source)を実験して、その実験期間(Duration)と追跡ID(Run ID)を確認できます。さらに、実験で設定したパラメーターと得られたMetricsも確認できます。
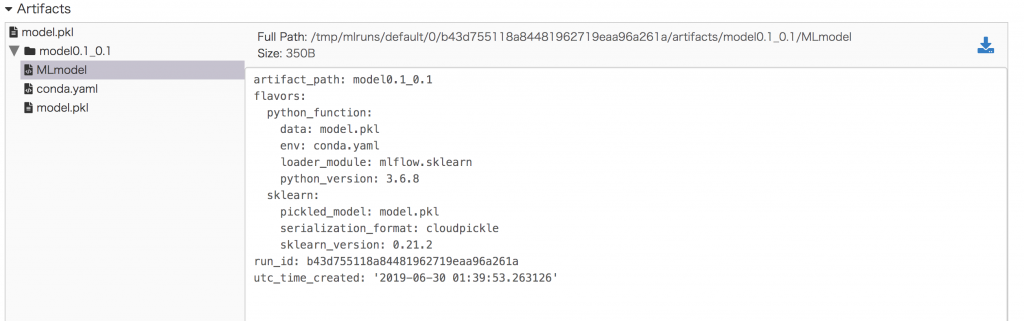
次は、MLFlowの面白いところの一つです。Artifactsの記録機能です。この機能は、実験を再現できるための情報を記録します。今回は実験で記録したいModel0.1_0.1のMLModelを確認しましょう。モデルのデータ(model.pkl)、実行環境(env)と依存関係情報も記録されました。他は、pickleで保存されたモデルの実体(model.pkl)とセットで、自動的にこのモデルの定義ファイル(MLmodel)も生成されます。
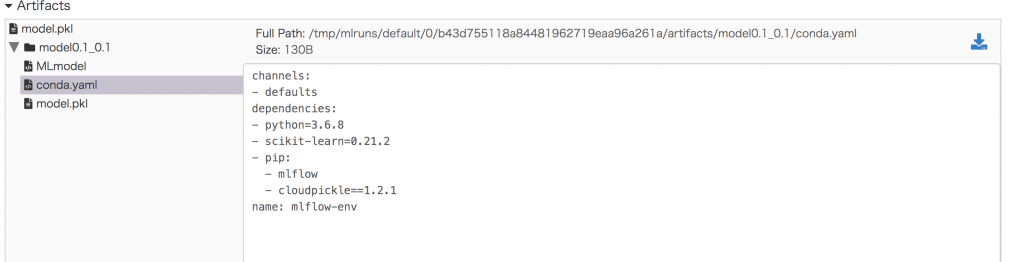
実験環境情報も「conda.yml」ファイルに記録されました。
MLFlowによる生成した結果ファイルのダウンロード等もできるので、とても便利ですね。
実験結果の比較
次は、実験結果の比較してみます。最初の実験結果一覧画面で比較したい実験を選んで「Compare」ボタンを押すと、実験結果比較画面に遷移されます。
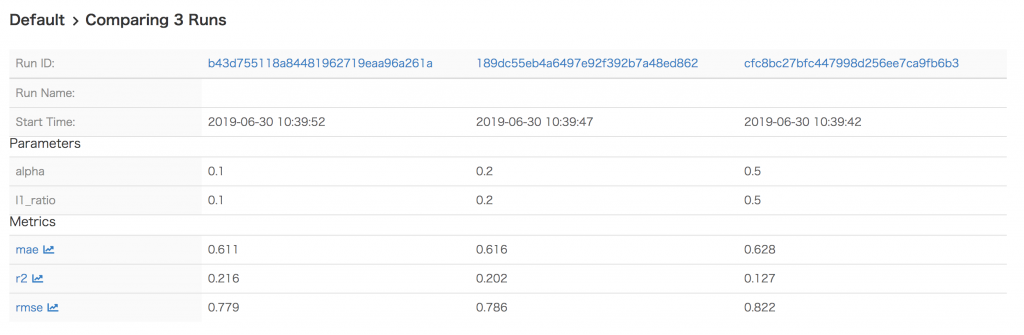
Scatterチャートで各指標を確認できますね。
MLFlow Project
MLFlow Projectは作成したモデル及び実行した環境を誰でも利用できるようにパッケージングする機能です。下記のようにMLProject FileというYAMLファイルを各実験用のリポジトリ内に用意することで、他の人に共有すればデータ分析周りのコードが再利用・再現できるようになります。さらに、この機能で実行時の環境をconda.yamlというファイルに記述しておくことで、その時の環境を再現することができます。
name: mlflow-example
conda_env: conda.yaml
entry_points:
main:
parameters:
alpha: float
l1_ratio: {type: float, default: 0.1}
command: "python train.py {alpha} {l1_ratio}"
MLProjectファイルに定義する必要な情報がプロジェクト名(name), 実行環境(conda_env)、スクリプト(実験コード)の実行方法(entry_points)です。実行方法の中に、ハイパーパラメータ等の実行時に与えるパラメータ及び実行したいファイル(main.py や test.py, train.sh 等)を指定する必要があります。
MLProjectと実装したコードをGithubなどにPushしたら、MLFlow runコマンドを実行するだけで実行環境が自動的に構築されて、指定するコマンドが実行されます。
mlflow run [email protected]:mlflow/mlflow-example.git -P alpha=0.5
では、MLFlow Project機能を作成して検証しましょう。今回は自分のMacbook Pro(macOS High Seirra v10.13.6)でDockerをインストールしましたので、Dockerで新しい実行環境を構築してから実行結果を確認したいと思います。ちなみに、MLFlowがインストールしているのDockerイメージを作成しましたので、それを使います。
$ docker run -it --rm --name mlflow -p 5000:5000 amanda83/mlflow-basis:latest
(base) root@bcd5d3b0a832:/app# mlflow run https://github.com/tranducquy/mlflow_example.git -P alpha=0.5
2019/06/30 09:30:45 INFO mlflow.projects: === Fetching project from https://github.com/tranducquy/mlflow_example.git into /tmp/tmpdwc7bl0v ===
2019/06/30 09:30:48 INFO mlflow.projects: === Creating conda environment mlflow-0ffb02672ae422e3b967b769d666fbd14183f0d5 ===
Warning: you have pip-installed dependencies in your environment file, but you do not list pip itself as one of your conda dependencies. Conda may not use the correct pip to install your packages, and they may end up in the wrong place. Please add an explicit pip dependency. I'm adding one for you, but still nagging you.
Collecting package metadata: done
Solving environment: done
==> WARNING: A newer version of conda exists. <==
current version: 4.6.14
latest version: 4.7.5
Please update conda by running
$ conda update -n base -c defaults conda
Ran pip subprocess with arguments:
['/opt/conda/envs/mlflow-0ffb02672ae422e3b967b769d666fbd14183f0d5/bin/python', '-m', 'pip', 'install', '-U', '-r', '/tmp/tmpdwc7bl0v/condaenv.gw9_bsq0.requirements.txt']
〜〜〜〜一部抜粋〜〜〜〜〜〜
Successfully built pyyaml alembic querystring-parser sqlalchemy simplejson Mako tabulate
Installing collected packages: pyyaml, sqlalchemy, MarkupSafe, Mako, python-editor, python-dateutil, alembic, idna, chardet, urllib3, requests, querystring-parser, sqlparse, smmap2, gitdb2, gitpython, entrypoints, cloudpickle, protobuf, click, Jinja2, itsdangerous, Werkzeug, Flask, gunicorn, websocket-client, docker, simplejson, pytz, pandas, tabulate, configparser, databricks-cli, mlflow
Successfully installed Flask-1.0.3 Jinja2-2.10.1 Mako-1.0.12 MarkupSafe-1.1.1 Werkzeug-0.15.4 alembic-1.0.11 chardet-3.0.4 click-7.0 cloudpickle-1.2.1 configparser-3.7.4 databricks-cli-0.8.7 docker-4.0.2 entrypoints-0.3 gitdb2-2.0.5 gitpython-2.1.11 gunicorn-19.9.0 idna-2.8 itsdangerous-1.1.0 mlflow-1.0.0 pandas-0.24.2 protobuf-3.8.0 python-dateutil-2.8.0 python-editor-1.0.4 pytz-2019.1 pyyaml-5.1.1 querystring-parser-1.2.3 requests-2.22.0 simplejson-3.16.0 smmap2-2.0.5 sqlalchemy-1.3.5 sqlparse-0.3.0 tabulate-0.8.3 urllib3-1.25.3 websocket-client-0.56.0
# # To activate this environment, use # # $ conda activate mlflow-0ffb02672ae422e3b967b769d666fbd14183f0d5 # # To deactivate an active environment, use # # $ conda deactivate 2019/06/30 09:36:19 INFO mlflow.projects: === Created directory /tmp/tmpn__fc9o5 for downloading remote URIs passed to arguments of type 'path' === 2019/06/30 09:36:19 INFO mlflow.projects: === Running command 'source activate mlflow-0ffb02672ae422e3b967b769d666fbd14183f0d5 && python train.py --alpha 0.5 --l1-ratio 0.1' in run with ID 'f64a0a3f499b40aea15879581aa41898' === Elasticnet model (alpha=0.500000, l1_ratio=0.100000): RMSE: 0.7947931019036529 MAE: 0.6189130834228138 R2: 0.18411668718221819 2019/06/30 09:36:23 INFO mlflow.projects: === Run (ID 'f64a0a3f499b40aea15879581aa41898') succeeded ===
見事、コマンドを実行するだけで実行環境を再現し、実行結果を確認することができました。便利ですね。
機械学習モデルのデプロイ
デプロイは、トレーニング済みのモデルによって現実世界の本稼動環境での予測を実行できるようにする行為です。これは機械学習のライフサイクルの最終段階の1つであり、非常に煩雑になる場合があります。MLFlow Modelsは実験で保存されたモデルを本稼動システムにデプロイするため開発しました。複数のプラットフォーム(Amazon Sagemaker、Azure Machine Learning、GCPなど)に複数のライブラリー(Tensorflow、Keras、Scikit-learn、Spark MLlibなど)をサポートしています。これによってデプロイの所要時間を従来より大幅に短縮できます。
今回の実験の中にalpha=0.1, l1-ratio=0.1の方が良さそう(MAEとRMSEが一番低いため)なので、これを使ってデプロイしましょう。MLFlow ModelがYAMLフォマットで下記のように構成されます。
artifact_path: model0.1_0.1
flavors:
python_function:
data: model.pkl
env: conda.yaml
loader_module: mlflow.sklearn
python_version: 3.6.8
sklearn:
pickled_model: model.pkl
serialization_format: cloudpickle
sklearn_version: 0.21.2
run_id: b43d755118a84481962719eaa96a261a
utc_time_created: '2019-06-30 01:39:53.263126'
Flavorsとしてmodelの稼働環境が定義されていますね。今回は、作ったMLFlowベースのDockerイメージを新規作成して、その上にデプロイしたいと思います。
docker run -it --rm --name mlflow -p 8082:8082 amanda83/mlflow-basis:latest
Docker内に実験で保存したモデルを展開する。GithubにPushしたので、GithubからPullします。
# pwd /app # git clone https://github.com/tranducquy/mlflow_example.git # cd /app/mlflow_example/deploy
今回の実験だと、mlflowのコマンドを使い以下のようにModelを読み込んだAPIサーバを立ち上げることができます。
# mlflow models serve -p 8082 -m /app/mlflow_example/deploy 2019/06/30 13:25:17 INFO mlflow.models.cli: Selected backend for flavor 'python_function' 2019/06/30 13:25:18 INFO mlflow.projects: === Creating conda environment mlflow-147d3aa19e32ef4bad9cbabdf768eddf7ebec8d6 === Warning: you have pip-installed dependencies in your environment file, but you do not list pip itself as one of your conda dependencies. Conda may not use the correct pip to install your packages, and they may end up in the wrong place. Please add an explicit pip dependency. I'm adding one for you, but still nagging you. Collecting package metadata: done Solving environment: done<br /> ~~~~一部抜粋〜〜〜〜〜<br /> Successfully installed Flask-1.0.3 Jinja2-2.10.1 Mako-1.0.12 MarkupSafe-1.1.1 Werkzeug-0.15.4 alembic-1.0.11 chardet-3.0.4 click-7.0 cloudpickle-1.2.1 configparser-3.7.4 databricks-cli-0.8.7 docker-4.0.2 entrypoints-0.3 gitdb2-2.0.5 gitpython-2.1.11 gunicorn-19.9.0 idna-2.8 itsdangerous-1.1.0 mlflow-1.0.0 pandas-0.24.2 protobuf-3.8.0 python-dateutil-2.8.0 python-editor-1.0.4 pytz-2019.1 pyyaml-5.1.1 querystring-parser-1.2.3 requests-2.22.0 simplejson-3.16.0 smmap2-2.0.5 sqlalchemy-1.3.5 sqlparse-0.3.0 tabulate-0.8.3 urllib3-1.25.3 websocket-client-0.56.0 # # To activate this environment, use # # $ conda activate mlflow-147d3aa19e32ef4bad9cbabdf768eddf7ebec8d6 # # To deactivate an active environment, use # # $ conda deactivate 2019/06/30 13:28:27 INFO mlflow.pyfunc.backend: === Running command 'source activate mlflow-147d3aa19e32ef4bad9cbabdf768eddf7ebec8d6 1>&2 && gunicorn --timeout 60 -b 127.0.0.1:8082 -w 4 mlflow.pyfunc.scoring_server.wsgi:app' [2019-06-30 13:28:27 +0000] [200] [INFO] Starting gunicorn 19.9.0 [2019-06-30 13:28:27 +0000] [200] [INFO] Listening at: http://127.0.0.1:8082 (200) [2019-06-30 13:28:27 +0000] [200] [INFO] Using worker: sync [2019-06-30 13:28:27 +0000] [209] [INFO] Booting worker with pid: 209 [2019-06-30 13:28:27 +0000] [210] [INFO] Booting worker with pid: 210 [2019-06-30 13:28:27 +0000] [211] [INFO] Booting worker with pid: 211 [2019-06-30 13:28:27 +0000] [212] [INFO] Booting worker with pid: 212
この形で、起動したAPIサーバにリクエストを実行すると、モデルからのレスポンスが返却されます。詳細はDeploy MLflow modelsページをご参照ください。
まとめ
長くなりましたが、MLFlowの基本となる3機能を検証してみました。既存HDPにインストールすることも結構簡単で、複数の実験結果を記録できてとても便利ですね。モデル選択、ハイパーパラメータチューニング、モデルの評価、モデルデプロイといった機械学習ライフサイクル管理作業をサポートすることで、データサイエンスPRJの長期で運用するとメリットが大きそうですね。一方で、運用するためには様々なルールに従う必要があるので、無理して使う必要はないと思います。Docker・Kubernetes及びArgoCDなどと上手く組み合わせることができたら強力な機械学習プラットフォームを構築することができるので、今後構築してみたいと思います。
最後に
次世代システム研究室では、アプリケーション開発や設計を行うアーキテクトを募集しています。アプリケーション開発者の方、次世代システム研究室にご興味を持って頂ける方がいらっしゃいましたら、ぜひ 募集職種一覧 からご応募をお願いします。
皆さんのご応募をお待ちしています。
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD