2025.06.30
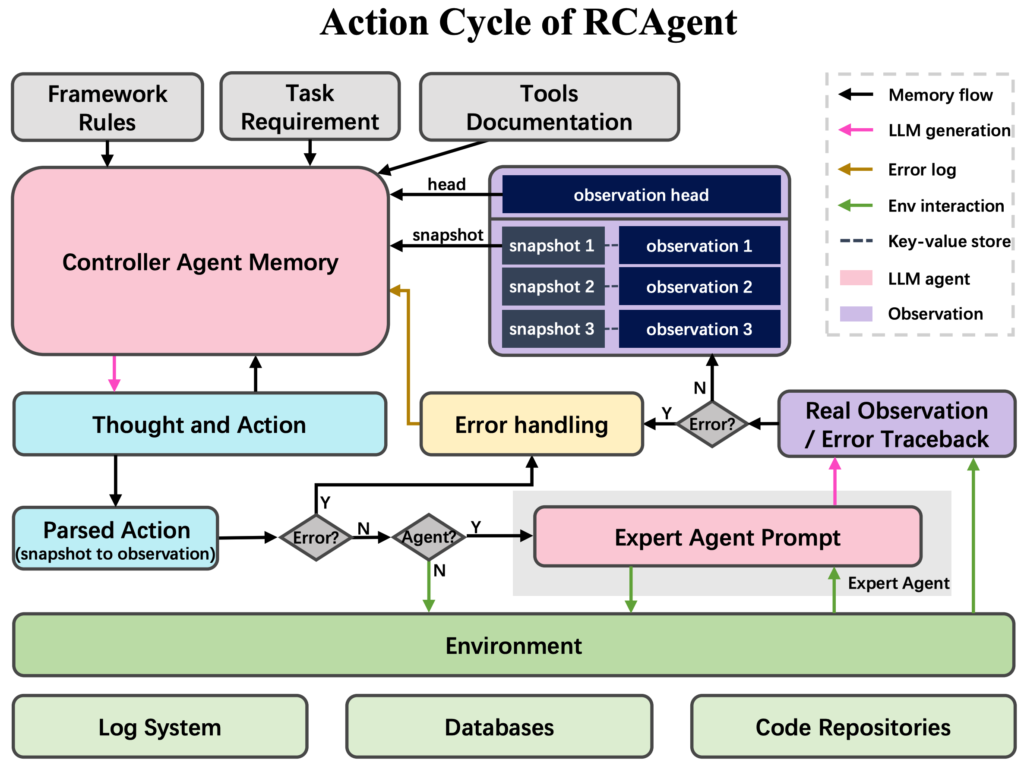
クラウド障害の根本原因分析を自律化する『RCAgent』の紹介
1.はじめに
こんにちは、AI研究開発室のS.Y.です。
クラウドシステムの運用において、障害発生時の根本原因分析(Root Cause Analysis:RCA)は極めて重要な作業でありながら、多くの場合、熟練したエンジニアによる手動での調査に依存しています。近年、大規模言語モデル(LLM)をRCAに活用する研究が活発化していますが、従来手法では手動でのワークフロー設定が必要で、LLMの持つ意思決定能力や環境との相互作用能力を十分に活用できていませんでした。
そこで今回は、アリババクラウドの研究チームが複数の大学(清華大学、ハーバード大学、南京大学、西安交通大学など)との共同研究として発表した論文「RCAgent: Cloud Root Cause Analysis by Autonomous Agents with Tool-Augmented Large Language Models」[1]を紹介します。この研究では、ツール拡張された自律エージェントとしてLLMを活用し、プライバシーを保護しながら実用的なクラウドRCAを実現するフレームワークが提案されています。
(余談)
筆者は最初「サービスKPI悪化のRCA」というのを扱う研究がないかDeep Researchしていたのですが、基本的にヒットするのがRCAgentでした。RCAgentで扱う問題のドメインはクラウド障害ですが、提案されているアイデアは広く一般的なRCA Agentに有用そうなものが多いと感じたため、ご紹介しようと思った次第です。
2.結論
RCAgentは、クラウドRCAにおけるLLMの活用において重要な進歩を示す研究です。主要な成果は以下の通りです:
- 高い安定性:Self-Consistency(行動軌道の最適化)や、OBSK(長大なクラウドログデータを効率的にコンテキストに含められる仕組み)などのいくつかの工夫により、無効な行動の発生率を7.93%まで抑制[2]
- 優れた性能:ReAct[3]と比較して、根本原因予測、解決策提案、証拠収集、責任特定の全ての観点で優位性を実証
- 実用性の証明:アリババクラウドのApache Flinkプラットフォームでの実運用により、実環境での有効性を確認
- プライバシー保護と外部API依存の解消:内部デプロイされたモデル(Vicuna-13B-V1.5-16K)を使用し、機密データの外部流出リスクを排除することで企業環境での実用的な利用を可能にする
- Out-of-Domain(OoD)ジョブへの対応:既存のルールでカバーされていない新しいタイプの問題(既存の自動SREツールでは適切に処理できないジョブ)に対しても優れた性能を発揮し、クラウドシステムの複雑化に対応できる自律的な診断システムとしての可能性を示す
3.Cloud RCAとは
Cloud RCAは、クラウド環境で発生した障害や性能劣化の根本的な原因を特定・分析するプロセスです。従来のオンプレミス環境と比較して、クラウドRCAには以下のような特有の課題があります:
- 分散システムの複雑性:マイクロサービス、コンテナ、サーバーレス関数など、多層にわたる分散コンポーネント間の相互作用
- 動的なリソース管理:オートスケーリングや負荷分散により、システム構成が動的に変化
- 多様なデータソース:アプリケーションログ、システムメトリクス、ネットワークトレース、設定情報など、膨大で異質なデータの統合分析が必要
- 時間的制約:サービス停止による業務影響を最小限に抑えるため、迅速な原因特定と復旧が求められる
従来のRCAプロセスでは、熟練したエンジニアが各種ツールを駆使してログ解析やメトリクス監視を行い、仮説検証を重ねながら原因を特定していました。しかし、この手法には人的リソースの制約、専門知識の属人化、分析時間の長期化といった課題がありました。
4.従来手法の課題とRCAgentのアプローチ
4-1.従来手法の限界
クラウドRCAにLLMを適用する従来の研究では、以下のような課題がありました:
- 手動ワークフロー依存:事前に設定された固定的なワークフローに依存し、LLMの自律的な判断能力を活用できない
- 外部API依存:GPTファミリーなどの外部APIモデルに依存するため、企業の機密データを外部に送信するリスクがある
- 環境相互作用の制限:静的な分析ツールとしての利用に留まり、動的な環境との相互作用が限定的
4-2.RCAgentの革新的アプローチ
RCAgentは、これらの課題に対して以下の革新的なアプローチで解決を図っています:
自律エージェントとしてのLLM活用
- 固定ワークフローに依存せず、LLMが状況に応じて自律的に行動を決定
- 様々なツールを駆使した自由形式のデータ収集と包括的な分析が可能
プライバシー保護の実現
- 内部デプロイされたモデルを使用し、機密データの外部流出リスクを排除
- 企業環境での実用的な利用を可能にする
5.RCAgentの技術的特徴
論文[1]より
膨大なデータ量を処理する必要があるクラウドRCAに対応するため、Observationを効率的にコンテキストに含める工夫が施されています。また、Open-Endedな行動生成において不要な行動を取ってしまう問題への対策も講じられています。。
5-1. Self-Consistency for Action Trajectories
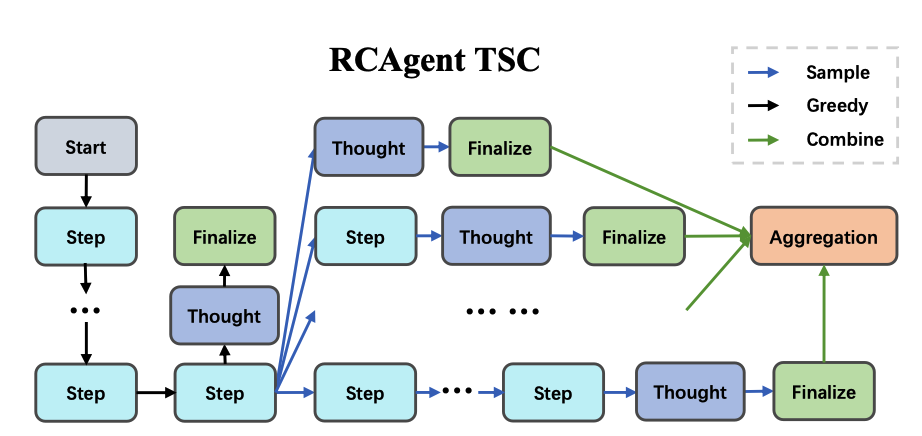
論文[1]より
従来の Chain of Thought (思考の多様化) と Self-Consistency (答案の多数決) を「行動レベル」に持ち上げた拡張版と位置づけられます。
仕組みの流れ
- 共有探索(greedy)
まずは決定論的に思考を進め、ログ取得やコード解析など
重いツール呼び出しを 共通の軌跡 として 1 本にまとめます。
ここで得た観測は後続のすべての候補が再利用します。 - 終盤分岐(sampling)
「あと⼀歩で結論」という地点からだけtemperatureを上げ、
同じ履歴を土台にk通りの分岐軌跡を生成します。
追加ツールはほぼ不要で、思考と出力の多様化が中心です。 - 軌跡の集約(aggregation)
- Embedding Vote ― 各候補をベクトル化し、他候補と平均的に
もっとも近いものを選ぶ - LLM Aggregate ― 候補全体を LLM に渡し、要約・統合させる
こうして“もっとも一貫性が高い行動列”が 1 本に決定されます。
- Embedding Vote ― 各候補をベクトル化し、他候補と平均的に
ポイント
- 前半を共有するためツール実行コストが増えにくい。
- 終盤だけ分岐させることで必要な多様性を確保できる。
- Vote と LLM Aggregate は自由に切替え可能。
LLM Aggregate は情報統合に優れ、Embedding Vote は計算が軽い。
このアプローチにより、単一推論方式の ReAct [3] と比べて
「行動の筋が通った」軌跡だけを残せる点が大きな特長です。
5-2. 包括的なコンテキスト管理
クラウド環境の RCA では、ログや設定情報など⻑大な観測データを「欠落なく保持しながら LLM の入力長を抑える」必要があります。
RCAgent は次の 2 つのモジュールを用いてこの課題を解決しています(論文 §3.2 Observation Management, §3.3 Stabilization)。
Observation Snapshot Keys (OBSK)
OBSK は、ツール出力の全文を安全に保持しつつLLM にはダイジェストのみを渡すキー機構です。
- 全文保存
ツールが返した観測ログ全文を
(key, value)形式でメモリに保持し、
keyには内容ハッシュを使用する。 - ダイジェスト提示
コントローラ LLM へはログの冒頭部分と
keyだけを渡し、残りは省略する。 - オンデマンド展開
後続の思考がkeyを参照すると、
ランタイムが対応する全文を LLM に再挿入する。
JSON 修復機構 (JsonRegen)
JsonRegen は、LLM がツール呼び出し用に生成する
JSON が無効な形式になった場合に自動修復を行うモジュールです。
- サニタイズ
パースを阻害する不正文字を除去・置換して再試行する。 - 再エンコード
なお失敗する場合は LLM に
「現在の YAML 風出力を有効な JSON に変換せよ」と指示し、
正しい JSON を再生成させる。 - リトライ
JSON がパーサを通過するまで
上記手順を繰り返し実行する。
5-3. ドメイン知識の統合
RCAgent には LLM 専門エージェント(Expert Agent) が組み込まれており、クラウド障害解析に特化したドメイン知識を一般用途の大規模言語モデルへ注入します。
仕組みは Algorithm 1 に示された手順に従って動作します。
動作の流れ

論文[1]より
- 入力チャンクの受け取り
まず、ログを意味ごとに分割したチャンクpが
Expert Agent に渡されます。 - 類似事例の検索
pの埋め込みベクトルを用いて、
Flink Advisor の履歴データベースから
E(過去の類似ログ)と A
(その正式な解析結果)を検索・ソートします
(retrieved sorted examples and answers)。 - Few-shot プロンプトの構築
取り出したE[0:N]とA[0:N]を
チャンクpと並べ、
In-Context Prompt を自動生成します。 - 解析の実行
LLM が Prompt を読み取り、
– 根本原因 (Root Cause)
– 推奨される解決策 (Solution)
– 根拠となるログ行 (Evidence)
を同時に生成します。 - 証拠の検証
生成された Evidence が
チャンクpに 90 % 以上一致
(レーベンシュタイン距離による判定)しなければ、
その解析結果を棄却します。
ポイント
- 履歴データベースは Flink Advisor の
過去解析ログを抜粋したサブセットで、
現在解析中のジョブとは重複しない安全なコーパスです。 - Few-shot 例 (E, A) を自動で注入するため、
追加のプロンプト設計は不要です。 - Evidence 検証により、チャンクに存在しない行を
根拠にする “幻覚” を排除します。
6. 実験結果と性能評価
6-1. データセット
論文では以下のデータセットで評価が行われています:
- データ収集:Alibaba CloudのReal-time Compute Platform for Apache Flinkから1ヶ月間のクラウドシステム履歴から15,616件の異常ジョブを収集
- フィルタリング:実質的なログ内容を持つ約5,000件の自明でない異常ジョブを抽出
- 最終データセット:クラスバランス制約(同一の根本原因を持つジョブを最大2件まで)を適用し、161件のジョブからなるオフラインデータセットを作成
- アノテーション:根本原因、解決策、証拠、責任の特定の4項目について、Flink Advisorの分析結果をLLMで要約した後、SREチームが校正・アノテーションを実施
6-2. 評価指標
- セマンティック指標:METEOR、NUBIA、BLEURT、BARTScore、EmbScore(コサイン類似度)
- LLM評価指標:GPT-4を用いたG-Correctness(根本原因予測の正確性)とG-Helpfulness(解決策の有用性)の評価(0-10点スケール)
- 軌道統計:Pass Rate(成功率)、Trajectory Length(軌道長)、Invalid Rate(無効行動率)
6-3. ReAct との比較実験
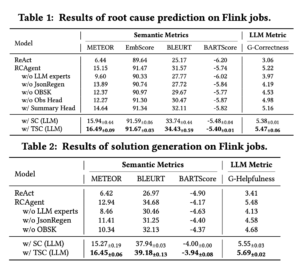
論文[1]より
- 根本原因の予測
─ METEOR 6.44 (ReAct) → 15.15 (RCAgent)
─ GPT-4 採点 3.06 → 5.22 - 解決策の提案
─ METEOR 6.42 → 12.94
─ GPT-4 Helpfulness 3.41 → 5.48 - 証拠の収集・提示
─ METEOR 11.82 → 28.10 - 責任の特定
─ Precision 73.53 % → 80.74 %
すべての観点で RCAgent が ReAct を上回り、特に「既存ルールでは未カバーの問題(Out-of-Domain ジョブ)」でも同様の優位性が確認されました。
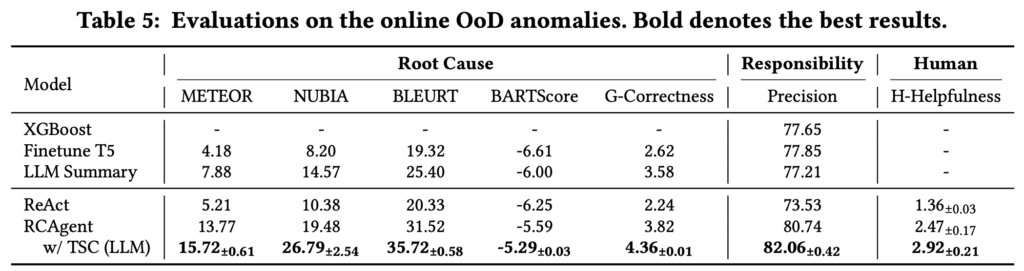
論文[1]より
アブレーション結果
- LLM Expert を除外
─ 根本原因 METEOR が 15.15 → 9.60 - JsonRegen を除外
─ 無効行動率が 7.93 % → 18.75 % - OBSK を除外
─ 証拠 METEOR が 28.10 → 17.79
6-4. 実用性の検証
RCAgent は Alibaba Cloud の Apache Flink プラットフォームに実際に組み込まれ、2 週間のオンライン運用でOut of Domain(既存のSREツールでは適切に処理できないケース)なストリーム処理ジョブ異常を診断しました。
- Root-Cause METEOR 13.77
- 責任 Precision 80.74 %
- Human Helpfulness 2.47 / 5 段階
手動分析では発見が難しいケースを含め、現場運用で有効に機能することが示されています。
6-5. 安定性の向上
行動の安定性は次の通りです。
- 全機能有効
─ Pass Rate 99.38 %
─ 無効行動率 7.93 % - LLM Expert 無効
─ Pass Rate 90 % 以上を維持するが、
ツール呼び出しが冗長化し安定性が低下 - JsonRegen 無効
─ 無効行動率が 18.75 % に悪化 - サンプリング戦略変更
(nucleus sampling)
─ 無効行動率が 44.80 % まで悪化
以上の結果から、各技術要素(LLM Expert, JsonRegen, OBSK,および既定サンプリング設定)が精度だけでなくシステム安定性にも大きく寄与することがわかります。
7. 産業応用と今後の課題
7-1. AIOps における革新
RCAgent は、従来の静的ルール診断に代わりログの自動分割・検索・生成推論を組み合わせることでリアルタイム障害解析を完全自動化しました。
Root-Cause、Solution、Evidence、Responsibility の4出力をすべて LLM が生成し、しかも各出力についてReAct を上回る精度を実証した点がAIOps 分野における大きな前進と位置付けられます。
7-2. 実運用での有効性
本システムは Alibaba Cloud の Apache Flink プラットフォームに実際に組み込まれ、2週間で 161 件 の異常ジョブを解析しました。
オンライン評価では次の成果が得られています。
- Root-Cause METEOR 13.77
- Responsibility Precision 80.74 %
- Human Helpfulness 2.47 / 5 段階
これらの数値は、既存の手動ワークフローよりも高い正確性と即応性を示しており、RCAgent が本番サービスに適用可能であることを裏付けています。
7-3. 今後の課題
- 大規模環境への拡張
評価は 161 ジョブ規模で行われましたが、
さらなる大規模・多サービス環境での性能検証が
次のステップとして示されています。 - コストと精度のバランス
Self-Consistency のサンプル数を増やすと
精度は向上しますが計算コストは線形に増えます。
論文では 20 サンプル 程度で性能が飽和する
と報告されており、この最適点の探索が課題です。 - 安定性の維持
TSCの序盤のサンプリング戦略をgreedyからnucleus samplingに変更すると
無効行動率が 44.80 % まで跳ね上がる事例も確認されました。
適切なサンプリング戦略(特に序盤はgreedy推奨)と Json 修復機構の併用が不可欠です。
8.まとめ
RCAgentは、クラウドRCAにおけるLLMの活用において重要な進歩を示す研究です。Self-Consistency[2]による行動軌道の最適化、包括的なコンテキスト管理、ドメイン知識の効果的な統合により、実用レベルでの自律的なRCAシステムを実現しています。
特に、プライバシーを保護しながら企業環境で利用できる点は、多くの組織にとって魅力的な特徴です。アリババクラウドでの実運用での成功は、この技術の実用性を裏付ける重要な証拠と言えるでしょう。
今後、より多様なクラウド環境での検証や、他のAIOpsタスクへの応用が期待されます。クラウドシステムの複雑化が進む中で、RCAgentのような自律的な診断システムの重要性はますます高まっていくと考えられます。
9.参考文献
- Wang, Z., Liu, Z., Zhang, Y., Zhong, A., Fan, L., Wu, L., & Wen, Q. (2023). RCAgent: Cloud Root Cause Analysis by Autonomous Agents with Tool-Augmented Large Language Models. Proceedings of the 33rd ACM International Conference on Information and Knowledge Management. https://arxiv.org/abs/2310.16340
- Wang, X., Wei, J., Schuurmans, D., Le, Q., Chi, E., Narang, S., … & Zhou, D. (2023). Self-Consistency Improves Chain of Thought Reasoning in Language Models. International Conference on Learning Representations. https://arxiv.org/abs/2203.11171
- Yao, S., Zhao, J., Yu, D., Du, N., Shafran, I., Narasimhan, K., & Cao, Y. (2022). ReAct: Synergizing Reasoning and Acting in Language Models. arXiv preprint arXiv:2210.03629. https://arxiv.org/abs/2210.03629
- Wei, J., Wang, X., Schuurmans, D., Bosma, M., Chi, E., Le, Q., & Zhou, D. (2022). Chain of Thought Prompting Elicits Reasoning in Large Language Models. Advances in Neural Information Processing Systems, 35, 24824-24837. https://arxiv.org/abs/2201.11903
- Chen, C., Zhang, J., Xie, Y., Deng, Y., Zhang, Z., Chen, C., … & Liu, P. (2023). LLM-empowered chatbots for psychiatrist and patient simulation: Application and evaluation. arXiv preprint arXiv:2305.13614. https://arxiv.org/abs/2305.13614
さいごに
グループ研究開発本部 AI研究開発室では、データサイエンティスト/機械学習エンジニアを募集しています。ビッグデータの解析業務などAI研究開発室にご興味を持って頂ける方がいらっしゃいましたら、ぜひ 募集職種一覧 からご応募をお願いします。皆さんのご応募をお待ちしています。
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD