2020.04.02
データが少なくても機械学習をあきらめない – 半教師あり学習について
こんにちは。次世代システム研究室のT.S.です
唐突ですが皆様「データが足りなくてAI(機械学習)がうまく動かない!」って悩んだ経験ありませんか? 私は、それはもう頻繁に悩んでいます・・・
これまでに色々な業種のデータ分析・AI活用をしていきましたのですが、その度にデータが使えないと悩んできました。ただ、それは「データがない」というわけではありませんでした。「データは存在する」のですが、それが手書きの図面等の「そのままでは使えない」データであることが問題だったのです。
私はこれを「データあるけど、(使える形で)ない問題」とよく呼んでいました。
データあるけど、ない問題
この問題は、いろいろな形がありました
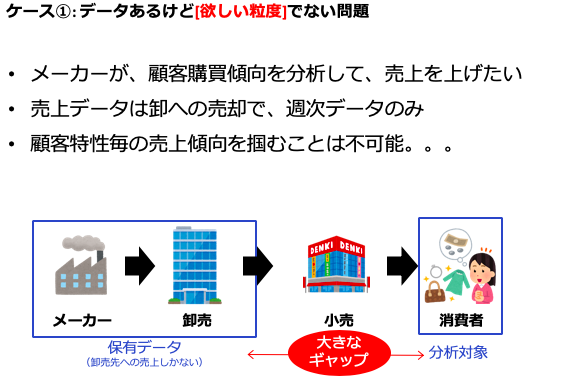
例えばそのケースの1つとして、「データあるけど、[欲しい粒度で]ない問題」というのがありました。これは下記のようなケースで、分析に使いたい粒度とは違うものしかデータが存在しないというものです。
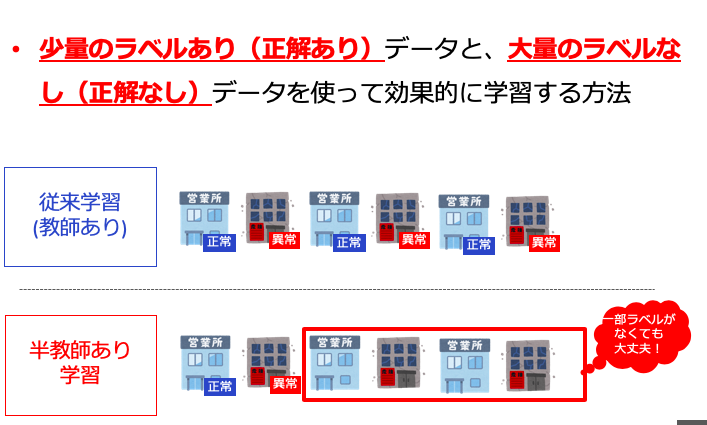
また違うケースとして、「データあるけど、[正解データが]ない問題」というのもありました。画像や音声データは大量にあるのですが、ラベル付け=正解データがないために学習ができないというものです。この場合、ラベル付けできればそれでいいのですが、工数・費用・期間の問題で、それも難しいということが多く発生していました。

今回ご紹介する半教師あり学習というのは、後者の「データあるけど、[正解データが]ない問題」についての解決策となるものです。全部はラベル付けできないのだけど、一部ならできる。。。と言う場合に、そのデータを使って、精度をあげていくという学習方法になります。
半教師あり学習
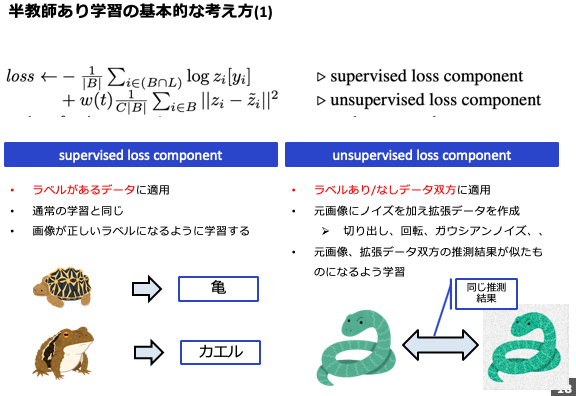
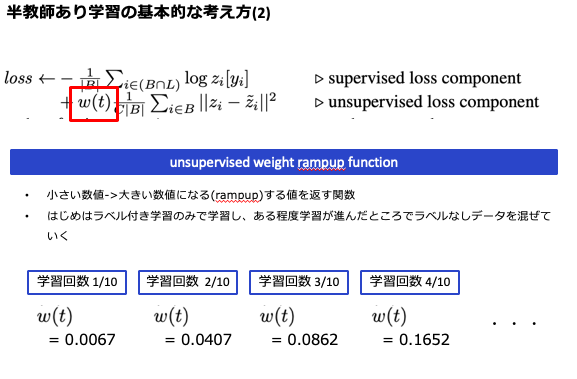
半教師あり学習と一言でいっても色々な種類がありますが、今回紹介するのはTemporal Ensembling for Semi-Supervised Learningという論文で提唱されたΠ-modelに代表される手法となります。当手法のキモはlossの算出方法にあります。下記にあるように、lossを[supervised loss component]と[unsupervised component]に分類します。
[supervised loss component]は従来どおり、正解ラベルとの差を測ります。推測結果と正解ラベルをCross Entropy lossなどで測るいつものものです。
違いは[unsupervised loss component]にあります。こちらは正解ラベルがなくてもlossを図らなければいけません。正解ラベルがないのにどうするのか? これにはまず元データを、回転・切り抜き・ノイズ付与などして複製(拡張)します。そしてこの拡張データと、元データの推測結果が同一になるようにMean Squared ErrorやKL-divergneceなどでlossを測るというわけです
またもう一つ重要なポイントがあります。それが下記で示しているω(t)にあたる部分です。ここはunsupervised weight rampup functionと呼ばれる項になります。学習回数が進むに連れ大きな値を返す役割を持っており、これのおかげで学習初期はunsupervised loss componentを弱く、学習が進むに連れ強く働かせる役割を持っています。前述したようにunsupervised loss componentは明確な正解を持たないため、初期は正解データを持つデータを中心に学習をすすめるという効果が生まれるわけです。
ここまで見て分かる通り、この理論の基礎的な考え方としてlossを変更することが中心であり、比較的これまでのモデルにも追加しやすい仕組みなのかなと感じています。またこれを発展させたMean TeacherやMixMatchというのもあるのですが、これらを含めて理解もしやすく、使いやすいのも好印象を持っています
応用: テキストデータの拡張方法
さて上記で紹介したΠ-modelをちょっと使ってみようかと思うのですが、ただ単純に論文通り実装するではなく一つ工夫を入れてみました。元論文では、画像へ適用した結果が紹介されているのですが、これをテキストデータに適用してみようと思います。ここで問題になるのがunsupervised loss component で利用する拡張データです。画像データでは、切り抜きや回転などでちょっと違ったデータを作り出せるのですが、テキストはそうはいきません。一部切り抜いてしまっては意味も変わってしますね。
ではどうしたのか? 今回はBack Translationという手法を使いました。仕組みは非常に簡単で、元テキストは違う言語に変換して、また元の言語に戻すというものです。こうすると意味は同じなのですが、ちょっと違う表現になる文章を得ることができます。まさに画像でやっていたデータ拡張と同じことが得られるというわけです。
![]()
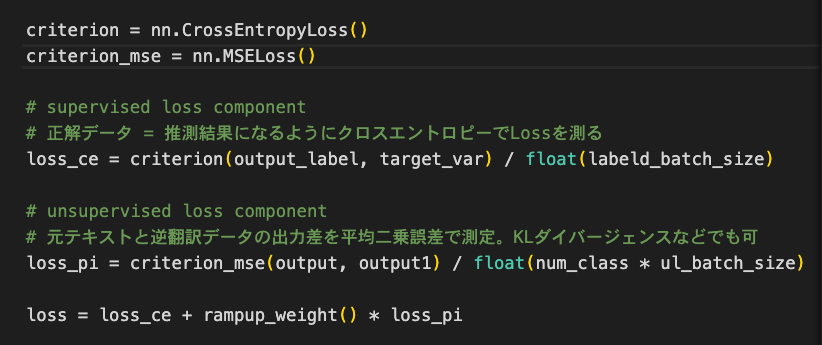
あとは、従来と同様にすれば実行できるというわけです。ちなみに一番キモとなるlossは以下のようなコードとなります(pytorch)。精度としては10%強向上しており、テキストデータでもPositiveな結果が得られました。
まとめ
いかがでしょうか。lossの変更というある程度小さな変更で、これまで活用できなかったデータを活かすことができるという非常に興味深い理論だったかと思います。
もし皆様の手元に「データはあるんだけど、ラベルがなあ。。。」というものがあれば、是非この手法を利用してみることをおすすめします。
次世システム研究室では、ビッグデータ解析プラットホームの設計・開発を行うアーキテクトとデータサイエンティストを募集しています。興味を持って頂ける方がいらっしゃいましたら、ぜひ 募集職種一覧からご応募をお願いします。
一緒に勉強しながら楽しく働きたい方のご応募をお待ちしております。
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD