2020.10.05
KaggleOpsを考える ~ MLflow + Colaboratory + Kaggle Notebook ~
こんにちは。次世代システム研究室のY. O.です。
筆者はデータ分析のスキルアップのためにkaggleというデータ分析プラットフォームを活用しています。kaggleを始めてから約2年間を経て、スキルアップの枠を超え、趣味・生活の一部・etc.になってきてしまっているのも認めざるを得ません。。。
今回は、先日kaggleの自然言語処理コンペ(Tweet Sentiment Extraction)で2位になった結果を題材に、振り返りの意味を込めて”こうしておけば良かった”という点をMLOpsの観点でまとめていきたいと思います。
ここで、kaggleを取り巻くMLOpsの構成をKaggleOpsと勝手に呼ぶこととし、少なくとも筆者は今後のコンペでも以下にまとめたKaggleOps環境を使っていくつもりです。
本エンジニアブログでは以前にもMLOpsについてエントリがありまして、そちらも合わせてご参照ください。
ML Pipeline事始め – kedro(+notebook)とMLflow Trackingで始めるpipeline入門 –
TL;DR
- MLflow Tracking・MLflow Projectsを使えば、面倒な実験管理(コード管理・結果可視化・モデル管理)ができる
- 工夫すれば、Colaboratory・Kaggle Notebook、2つの実行環境を同時に実験管理できる
- 無料サービス中心の構成なので、GPUでガンガン計算しても1ヶ月数十円のオーダーで収まる
今回目指すKaggleOps環境の構成
KaggleOpsの構成理念を一言で言うと、「推論時に否が応でも使わないといけないKaggle Notebookや、無料でGPUが使用できるColaboratoryを無料計算リソースとして捉え、実験結果はGCSに放り投げて可視化だけGCEで行う」です。この”一言”を伝えるために以下進めていきます。
フレームワークにはMLflow Tracking・MLflow Projectsを採用し、KaggleOps構成の全体で利用していきます。
基本的な流れは以下の通りです。
- GitHub:作成した実験モジュールやパラメータを記載したYAMLなど、実験を行う上で必要なコード諸々をPush
- Colaboratory/Kaggle Notebook:GitHubのレポジトリURLをMLFlow Projectsに指定することで、先ほどPushしたコードをそのままcloneしてきて実行
- GCS:実行中のスコアやモデルはGCSに適時に投げられる
- GCE:GCSに保存されている実験結果をインスタンスにコピーしてきて、MLflow Tracking Serversとして利用する。グローバルIPからアクセスして実験結果をUIで確認
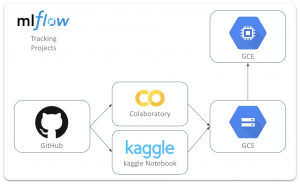
図1 この記事で構築するKaggleOps環境
ちなみに、コンペ期間中の実験管理はスプレッドシートで行っており、図2のような大惨事でした。(計500行ほどのメモに。。。)
この管理方法について問題が大きい順に列挙します。
- どんなに細かくメモを残しても「あれ、どうやってこの結果になるんだっけ」が発生する
- メモが面倒
- 比較するために別途グラフ化が必要
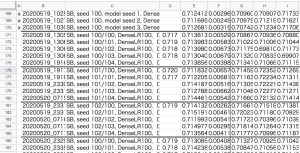
図2 スプレッドシートによる実験管理
下準備(GCP環境設定)
まずはGCPでプロジェクトを作成します。このブログ用にkaggleops-projectというプロジェクトを作成しました。このプロジェクト内で今回の検証を行っていきます。
プロジェクトが作成できたら、GCSにバケットを用意します。kaggleops-bucketという名前を付け、us-east1にシングルリージョンの設定で作成していきましょう。あくまで動くものを最低限のスペックで作っていく方針とします。
このバケットに、MLFlowの受け皿となるフォルダをあらかじめ用意しておきます。作成するのは図3の2フォルダです。artifactsはモデルや分析結果画像などを保存するフォルダで、mlrunsは設定パラメータや結果スコア、その他のメタデータが保存されます。
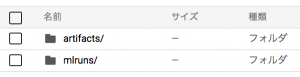
図3 GCSのバケットに作成するフォルダ
次にGCEでインスタンスを作成します。こちらも最低限のスペックを心がけ、Ubuntu 18.04 LTS・e2-micro・プリエンプティブONというインスタンスにしました。リージョンはGCSバケットと同じに設定し、Cloud APIにアクセス権を許可しておきましょう。
最後に、作成したインスタンスのファイアウォールルールを設定しましょう。最低限のスペックで用意しているのでグローバルIPを外部にそのまま開放してもいいのかもしれませんが、簡単なルールくらいはつけておくことにします(HTTPトラフィックをグローバルにそのまま開放するだけなら、インスタンスの設定編集画面で「HTTPトラフィックを許可する」にチェックマークを入れるだけです)。
今回はGCPコンソールから VCPネットワーク → ファイアウォールルール と進み、新規のルールとして自宅のIPなどだけからのトラフィックを許可するようにして、tcp:5000のポートを空けておきます(MLFlowのデフォルトポート番号が5000のため)。
分析実行
利用するコード
実際に、kaggleの自然言語処理コンペ(Tweet Sentiment Extraction)で2位になった際に利用していたコードの一部です。筆者を含むチームは、1st Layerモデル(base model)と2nd Layerモデル(reranking model)の2段構成でパイプラインを組んでいましたが、このコードで1st Layerモデルについての実験を行うことができます。
このエントリで利用するコード一式は以下リンクのレポジトリにまとめられているのですが、ほぼ全てが自然言語処理モデルを学習するコード(コンペで利用していたコード)です。それらに2~3個のコードを追加して、MLFlow Tracking・MLFlow Projectsを動かせるようにしています。
すでに手持ちのコード達を簡単にMLOps化することができるのがMLFlowの便利さの一つだと思います。
https://github.com/yuooka/kaggleops-tutorial
Colaboratoryで実行
Googleが提供しているNotebook形式の分析環境です。無料で利用できるので自己学習で利用する際の最有力手になりますが、ビジネスシーンにおいてもPoCで素早くデータを確認したいケースなどで利用されている方も多いと思います。
今回は、KaggleOpsという文脈で無料でGPUを使えるという強みを生かしていきたいと思います。
ColaboratoryでGPUを利用する際の最大キモは、バックエンドにNVIDIA Tesla P100を引き当てることです。筆者が観測した限り、P100・T4・K80・P4がランダムに割り当てられるようで、ここの”引き”によって実行時間が数時間レベルで変わるので、訓練を開始する前に、数分掛かってもいいのでP100を引き当てたいところです。
では、Colaboratoryで実際にコードを流してみましょう。とは言っても本当にシンプルです。
初めに、先ほどのレポジトリからrun.ipynbをColaboratoryで開き、ハードウェア アクセラレータにGPUを指定します。
次は、学習プログラムを実行するまでに行わないといけない環境設定をします(図4)。図4の冒頭セルにて、下準備で作成したプロジェクト名とバケット名を入力し、実行すると表示されるGoogle認証を行うだけです。他の部分は図4のコードをそのまま流せば、GitHubからレポジトリがクローンされてきて、GCSに格納しているMLFlowの結果格納フォルダ(mlruns)がコピーされてきます。
この構成にするのに少し頭を捻りましたが、結果的にはシンプルなコードを流すだけで環境設定ができるようになりました。
また、ここでレポジトリをcloneしていますが、実は、requirements.txt・src/mlproject.pyの2ファイルが欲しいがためにcloneしているだけです。「あれ、どうやってこの結果になるんだっけ」を防ぐためのGitHubのコミットハッシュと実験結果を紐付ける工夫は、この手動で行ったcloneではなくsrc/mlproject.pyの中に書かれているMLFlow Projectsが行ってくれます。
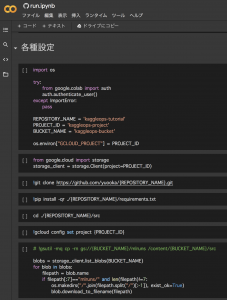
図4 run.ipynbの環境設定部分(Colaboratoryでの見え方)
main関数というか、このKaggleOpsのキモとなるコードは先ほどColaboratoryローカルにcloneしてきたmlproject.pyになります。このpyファイルを実行して、ローカルに保存された実験のスコア(mlruns)をGCSに転送して終了です(図5)。
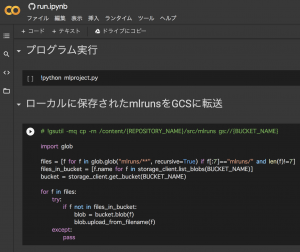
図5 run.ipynbの分析実行・結果のGCS転送部分(Colaboratoryでの見え方)
Kaggle Notebookで実行
本当にお世話になっております。GPUを複数インスタンスで時間無制限に利用できた時代もありました。現在(2020/10/1)、GPUに関しては累計週41Hの利用枠となっております。一方、最新のDockerが高頻度で変わるのが少し使いにくいところです。
では、Kaggle Notebookで実際にコードを流してみましょう。
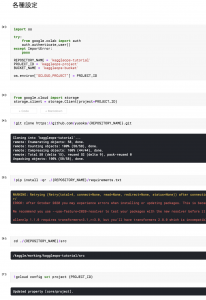
図6 run.ipynbの環境設定部分(Kaggle Notebookでの見え方)
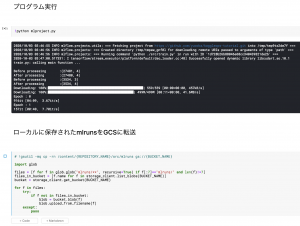
図7 run.ipynbの分析実行・結果のGCS転送部分(Kaggle Notebookでの見え方)
はい。図4・5と図6・7は全く同じです。全て同じコードで実行できます。Colaboratoryの時とは違い、実際の実行セルも映してみました(pipでバージョン依存関連のErrorが起きていますが、関係のないライブラリなので一旦無視です)。
ここで認証系のエラーが出てしまった方、すみません。実はColaboratoryと違い、Google認証はKaggle Notebook上部のタブ部分から行う必要があります(図8)。これにより、run.ipynb冒頭のGoogle認証部分はKaggle Notebook環境だとImport Errorの方になりますが問題なく実行できる、といった具合です。
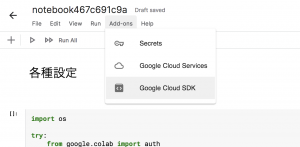
図8 Kaggle NotebookでGoogle認証を行う部分(Add-ons → Google Cloud SDK)
MLflowでの結果確認
さて、お待ちかねの結果確認です。GCEインスタンスにMLFlowをインストールした後、GCEインスタンスで2つのコマンドを実行します。
1つ目は、GCSに保存した実験結果ファイルをGCEへコピーするコマンドですgsutil -mq cp -rn gs://kaggleops-bucket/mlruns ./。
そして、その後、mlflow server --host XX.XX.XX.XX(ただしXX.XX.XX.XXはGCEインスタンスのインターナルIP)を実行し、MLFlow serverとして外部からのリクエストを待ちます。
以上でGCEの準備は終わりです。GCSからGCEのローカルディスクにコピーしてきた結果ファイルを元にMLFlowで結果確認をするので、上記の2コマンドは実験を追加して結果確認したいタイミングで毎回行う必要があります。
では、お好きなブラウザでhttp://YY.YY.YY.YY:5000(ただしYY.YY.YY.YYはGCEインスタンスのグローバルIP)にアクセスしてみましょう。MLFlowの管理画面が表示されたと思います!(ここでうまく表示されない方は下準備のファイアウォール設定などを見直してください)
図9のようにKaggle Notebookからの実験結果を比較したり(もちろんColaboratoryで実行したものと比較もできる)、実験の詳細が知りたくなった場合は設定パラメータが図10のように確認でき、GitHubコミットハッシュのハイパーリンクに飛べば、実行バージョンのコードを確認することができます。

図9 MLFlowでの実験結果の比較
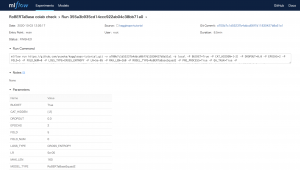
図10 実験詳細
コード解説
少し細かいですが、”KaggleOpsのキモ”として先ほど紹介したmlproject.pyの中身を見てみましょう。たった30行ですが、mlrunsに格納されているメタデータをよしなに修正して、
- サーバを立てなくても
- ColaboratoryとKaggle Notebookの結果を
- あたかもGCEインスタンスのローカルで実行したかのように
してくれます。
ここでやっと、本エントリ冒頭の「推論時に否が応でも使わないといけないKaggle Notebookや、無料でGPUが使用できるColaboratoryを無料計算リソースとして捉え、実験結果はGCSに放り投げて可視化だけGCEで行う」が理解できたのではないでしょうか。
import os
import yaml
import random
import mlflow
FILE_DIR = os.path.dirname(os.path.abspath(__file__))
with open(os.path.join(FILE_DIR, "./config/config.yml")) as file:
config = yaml.safe_load(file)
if __name__ == "__main__":
# mlrunsの準備
client = mlflow.tracking.MlflowClient()
try:
# 実験フォルダをmlruns内に新規作成する場合はGCSがArtifactsの保存先になるように指定する
exp_id = client.create_experiment(config['experiment_name'], artifact_location=f"gs://{config['bucket_name']}/artifacts")
except:
# すでにmlruns内に同じexperiment_nameのフォルダが存在する場合、そのArtifactの保存先をGCSに強制的に書き換える
exp_id = client.get_experiment_by_name(config['experiment_name']).experiment_id
filepath = f"{FILE_DIR}/mlruns/{exp_id}/meta.yaml"
with open(filepath) as file:
meta = yaml.safe_load(file)
meta["artifact_location"] = f"gs://{config['bucket_name']}/artifacts"
with open(filepath, 'w') as file:
yaml.dump(meta, file, default_flow_style=False)
# MLprojectをgithubから持ってきて実行する
mlflow.projects.run(config['git_uri'], entry_point='main', experiment_name=config['experiment_name'], use_conda=False)
最後に
GCSの容量の大部分は学習済みモデルとなりますが、100 GBで月$2と非常に低価格です。GCEも最低スペックかつプリエンプティブ、さらに結果確認の時だけ起動しておけば良いので月10円も使えないのではないでしょうか。計算リソースには無料のColaboratoryとKaggle Notebookのみを利用しているので、今回のようにGPUを使ってディープラーニングをするのも無料です。
結果的に、検証期間でおおよそ月20円しか掛からずに運用できました。計算環境が揃えにくい方にはもってこいと思います。
次世システム研究室では、ビッグデータ解析プラットホームの設計・開発を行うアーキテクトとデータサイエンティストを募集しています。興味を持って頂ける方がいらっしゃいましたら、ぜひ 募集職種一覧からご応募をお願いします。
一緒に勉強しながら楽しく働きたい方のご応募をお待ちしております!
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD