2015.12.16
Embulk Meetup Tokyo #2 での LT 内容の補足と、イベントの感想
次世代システム研究室のDevOpsネタ担当のM. Y.です。
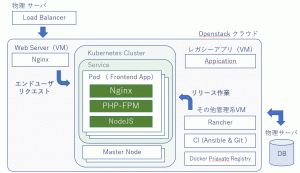
12/15(火)に開催された Embulk Meetup Tokyo #2 のライトニングトークにて、Embulkを使って構築したログ監視システムについて発表しました。

一度、他の方々の意見を伺ってみたいネタでしたので、発表の機会を頂けて楽しかったです。スライド公開しましたので、当日お越しになれなかった方もよかったらご覧ください。
今回の発表の元ネタは、過去に公開した以下のブログ記事です。設定ファイルの詳細や、プラグインの実装など、もっと詳しい話を知りたくなったら、ブログ記事のほうも是非ご覧ください。GitHubにpushしたサンプルコードへのリンクなどもあります。
- ERRORログが多すぎるWebアプリに出会ったら
- 謎の独自ERRORログをEmbulk + Elasticsearch + Kibana + PostgreSQLで監視する:運用設計からシステム構築まで
今回の発表では上記ブログにある詳細は諦めて、このようなソリューションが必要になるユースケースや、試行錯誤を重ねるプロセスの方に力を入れてお話ししました。このような話が受けるか心配だったのですが、講演後に何名かから「是非こういう形でEmbulkを導入してみたい」というご意見も頂けたので、少しホッとしました。
当日頂いた主な反応
大量のログに苦労した経験のある方は、参加者の4~5割
LTの前半で、「このような苦労をされたことある方」に挙手してもらったところ、ざっと見た感じ 4~5割 の方が手を挙げてくれました。みんなログが大事なのは分かってはいるけど、利益に繋がる機能開発が優先されて、お金はかけてもらえない、というのが実情でしょうか。
個々のログを追うのではなく、主原因となるログを特定できないか?
質疑応答で、1点、以下のような内容の鋭いご指摘を頂きました。うろ覚えなので、誤解でしたらすみません。
「エラーが発生するときにはエラー同士に因果関係があるもので、あるエラー1件が主原因となり、複数のエラーがその影響で発生することがある。今回は個々のエラーに注目した発表だったが、このエラーの塊があったら問題だ、という検出方法について何かアイディアはあるか」
その場では、「今回はまず最初の段階としてログを可視化することを目的にKibanaを使った。そのような高度な分析、可視化は今回の仕組みでは難しいと思う」と回答しました。
この回答をもう少し補足すると、今回の仕組みは、Kibanaのグラフなりクロス集計の結果を可視化することで、人間なら大まかなエラーの分類をなんとなく把握できる、というところまでしか実現できていません。因果関係を計算するには、まず「このエラーとこのエラーは同じ分類」という分類の明確な定義(例えばエラーコード)が必要だと思います。エラーコードを定義できれば、そのエラーコード間の依存関係は計算できそうな気がします。
ただ、そもそも、そのようなエラーコードが定義できていない状況を改善する、というのが今回の発表テーマだったので、卵が先か鶏が先か、という話もあって、なかなか難しいところです。
監視システムを頑張る前にアプリの方をなんとかすべきでは?
他には、そんなに大量のログを出すアプリがあるなら、先にアプリの方を何とかすべきでは、という意見もありました。まあ、そう言われるのも分かります……。
ここは、私の説明が良くなったところで申し訳なかったのですが、今回のようなログ可視化を行うのは、あくまで、アプリをどう改善していくべきかの戦略を立てるための手段だと思っています。ただ、現状をある程度把握できていないと、意味のない、あるいは効果の薄い改善に時間をかけてしまうことになります。なので、Embulkを使って少ない工数(今回の事例では1週間程度)でログ監視システムを作れば、ログを可視化できて、その結果を使って対策の優先度をうまく決めることができると思いますよ、というのが今回主張したいことでした。
イベント全体の感想
講演者は、Treasure DataでEmbulkの開発を担当されているお二人に加えて、Embulkの公開プラグインをバリバリ開発されている方ばかりで、イベント全体としてとても面白かったです。参考になりました。
特に、DeNA中山さん(@Civitaspo)の発表は、Embulkを使っていると躓くポイントをうまくまとめて紹介されていて、Embulkをproduction環境で使いたい方は必見です。特に「YAML管理」、「並列数制御」、「続きから実行」は私のも躓いたところでした。今回私の紹介した小規模な環境でさえ、YAMLの設定ファイルが20個くらい必要で泣きそうでした……。
他の発表者のプレゼン資料は、hiroysatoさんのEmbulkまとめページに随時リストアップされていくようですので、そちらをご参考頂ければと思います。hiroysatoさんのページには、私もプラグイン開発時にお世話になりました。今回の懇親会でご挨拶できたのですが、ご本人のEmbulk利用事例も結構面白かったです。#3で発表されるかな?とか期待してます。
最後に、懇親会で色々な方と話したのですが、Treasure Data が最近発表したワークフローエンジン Digdag (treasure-data/digdag-docs) が、Embulk に不足している機能を今後補うのではないか?と大きな期待を集めていました。現在はGitHubにドキュメントがあるだけですが、来年には動くソフトウェアをリリースできそうとのことでしたので、リリースされたら是非使ってみたいと思います。
次世代システム研究室では、グループ全体のインテグレーションを支援してくれるアーキテクトを募集しています。インフラ設計、構築経験者の方、次世代システム研究室にご興味を持って頂ける方がいらっしゃいましたら、ぜひ 募集職種一覧 からご応募をお願いします。
皆さんのご応募をお待ちしています。
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD