2015.05.28
謎の独自ERRORログをEmbulk + Elasticsearch + Kibana + PostgreSQLで監視する:運用設計からシステム構築まで
次世代システム研究室のDevOpsネタ担当(Embulkのコード読んでRuby復習中)のM. Y.です。
前回の記事(ERRORログが多すぎるWebアプリに出会ったら)では、ログ形式が統一されていない、大量のERRORレベルのログを吐き出すWebアプリに運悪く出会ってしまった場合に、そこから何とかログの傾向を把握するためのアプローチについてご紹介しました。
あれから、このアプローチを実践するためのログ監視システムを社内で実際に構築してみました。その結果、Embulk + Elasticsearch + Kibana + PostgreSQLという組合せで、割と手軽に、実用的なものを作れそうなことが分かりましたので、今回はこのログ監視システムの概要をご紹介します。
1. 前提条件
この記事では、以下のような状況を前提にお話しします。詳細が気になる方は前回の記事をご覧ください。
- ERRORログが多すぎて、特定の文字列がログに出現したらアラートメールを送る、といった一般的なログ監視はできない。
- ERRORレベルのログの中に重大なエラーが含まれる可能性は残っているため、完全に無視することもできない。せめて、エラーの種類ごとのログ件数の傾向は把握したい。
- 重要な情報が含まれる箇所(メッセージ中なのかスタックトレースなのか……)がログの種類によって異なるため、解析方法については試行錯誤する必要がある。
- 元のWebアプリを改修してログを改善する、という根本的な対策を行う時間はしばらく取れそうにない。
2. 運用設計と実現手段
上記のような状況で、根本的な対策は難しいながらも、以下のような運用でしばらく乗り切ることを考えます。
- 1. ERRORログの件数/日を、ホストやサービスごとに、毎日または2〜3日ごとに確認する。そして、直近数日の件数があまりにも急増していたら、原因を調査する。
- 2. ERRORログの増加傾向を、ログの種類(発生元のクラス名、メソッド名、エラーコード等)ごとに、毎週または毎月確認する。そして、特定の種類のログが急増、または新たに現れるようになっていたら、原因を調査する。
- 3. 上記の1や2で発見した異常の原因を調査する際には、ログを検索して詳細を確認する。
そして、このような運用を実現するために、今回のログ監視システムでは以下のソフトウェアを採用しました。
- 運用1および3は、Embulk + Elasticsearch + Kibanaで実現する。
- EmbulkでパースしたデータをElasticsearchに登録し、それをKibanaのDashboard機能で可視化し、Discover機能で検索可能にする。Dashboardには、ERRORログ監視に適した形のグラフや表を事前に定義しておく。
- 運用2は、Embulk + PostgreSQL + Excelで実現する。
- EmbulkでパースしたデータをPostgreSQLに登録し、その集計結果をTSVファイルに出力する。このTSVファイルをExcelのピボットテーブル機能で加工して閲覧する。ログが冗長な場合は、PostgreSQL上のデータを再度Embulkに通して抽象化処理を行う。
3. ログ監視システム
3.1. システム構成
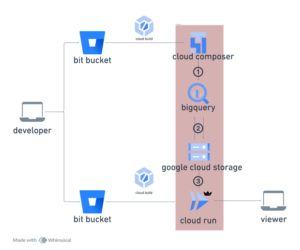
今回構築したログ監視システムのシステム構成は以下の通りです。一番左は監視対象のサーバ、一番右は監視作業者の端末、矢印はログの流れる方向を表しています。
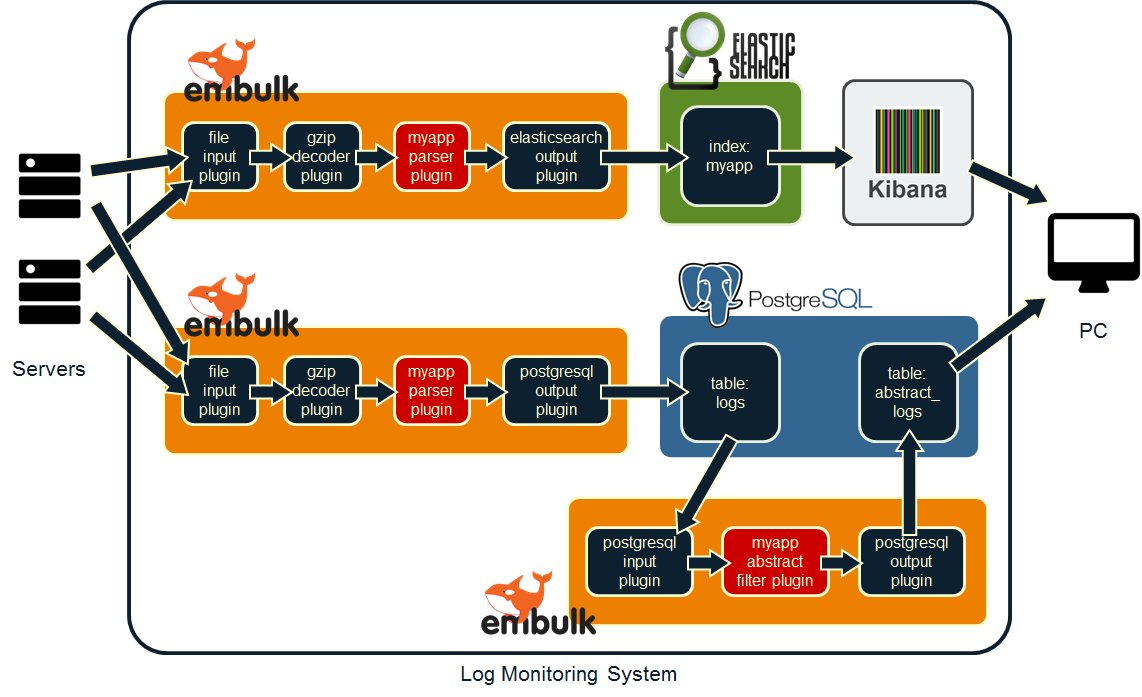
このシステムを構築するにあたり、実装したのは2種類のEmbulkプラグイン(図中の”myapp parser plugin”と”myapp abstract filter plugin”)のみで、2つのプラグインを合わせてもコード量は300行弱。一度やり方が分かれば、非常に手軽に実装できました。この手軽さは強いメリットだと思います。
また、今回私がシステムを構築した際は、Embulk + Elasticsearch + Kibana + PostgreSQLを、すべて1台のサーバにインストールしました。ただ、監視対象の規模によっては、サーバを複数台使っても良いでしょう。
以下、各コンポーネントの詳細です。
3.2. Embulk + Elasticsearch + Kibana(システム構成図の上半分)
ERRORログの件数/日を可視化するために、Elasticsearch + Kibanaの組合せを使います。また、ログの検索もKibanaで実現します。
3.2.1. Embulkがインストールされたサーバへのログファイルのコピー
Embulkのfile input pluginには、後述するように一度読み込んだログファイルを無視する機能があります。もし、監視対象のログファイルが日付や時間単位でローテートするようになっていない場合、先にそちらの設定が必要です。
今回私が扱ったログファイルは日単位で、日付の入ったファイル名(myapp.log.2015-06-01のような形式)でローテートされるものだったため、これをrsyncで1日1回コピーするようにcrontabを設定しました。
3.2.2. Embulkの設定(gzipファイル入力 → パース → Elasticsearch出力)
監視対象のWebアプリに合わせたEmbulkのparserプラグイン(図中の”myapp parser plugin”)を開発し、以下のように設定ファイルに記載します。
in:
type: file
path_prefix: /data/service01/host01/myapp.log.
decoders:
- {type: gzip}
parser:
charset: UTF-8
newline: LF
type: myapp
log_levels: [ "ERROR" ]
host: "host01"
service: "service01"
out:
type: elasticsearch
index: myapp
index_type: myapp_logs
nodes:
- {host: localhost}
設定ファイルのparser以下の属性のうち、type属性はプラグイン名の指定、その他の属性はembulk-parser-myappプラグイン独自の設定です。ホスト名やサービス名も分析に使いたいがログには含まれていない場合、このように設定ファイルを通してパーサに渡すのが楽だと思います。設定ファイルの数が増えるのが難点ですが……。
今回実装したパーサでは、ログファイルを以下のようにパースしました。図中の文字(timestamp、log_level_nameなど)は、パース結果に付与したカラム名です。デフォルトの設定では、このカラム名がそのままElasticsearchのカラム名になります。

Embulkのパーサは、ログを1行ごとにパースするのが基本のFluentdと比べて、この手の処理を書きやすくなっています。複数行に渡るログをパースするparserプラグインの実装方法については、以下の記事をご参考ください。
- 複数行からなるログを解析するために、EmbulkのparserプラグインをRubyで開発する話(準備編)
- 複数行からなるログを解析するために、EmbulkのparserプラグインをRubyで開発する話(実践編)
そして、前述のrsyncの後続ジョブとして、以下のようなコマンドをcrontabに登録します。
embulk run config-es-service01-host01.yml -o config-es-service01-host01.yml
Embulk runコマンドは、-oオプションで渡された場所に、処理結果を含む設定ファイルを出力する機能を持ちます。embulk-input-fileプラグインの場合は、最後に読んだログファイルの絶対パスを以下のように出力します。そのため、入力の設定ファイルと出力の設定ファイルを同じにしておくと、Embulkを実行するたびに、新しく増えたログファイルだけを自動的に読み込んでくれます。
in: type: file path_prefix: /data/service01/host01/myapp.log. (中略) last_path: /data/service01/host01/myapp.log.2015-06-01.gz (後略)
Embulkのfile input pluginはこのようにファイル単位で履歴を扱うため、もしも行単位の履歴が必要(=リアルタイム性が必要)なら、素直にFluentdなどを使ったほうが良さそうです。
3.2.3. Elasticsearchの設定
Elasticsearchはスキーマレスなので、何も設定しなくても、Embulkのembulk-output-elasticsearchプラグインが自動的にデータを追加してくれます。
ただ、Kibanaで、表のcolumnや、円グラフのsliceとして使いたい項目については、要素解析されないように事前に設定しておく必要があります(参考:Kibana+Elasticsearchで文字列の完全一致と部分一致検索の両方を実現する)。カラム名を指定した設定もできるのですが、今回は手軽さを優先して、末尾が”_name”のカラムは要素解析の対象外になるように設定しました。
まず、以下のようなMapping Template(myapp.json)を用意します。
{
"template": "*",
"mappings": {
"_default_": {
"_source": { "compress": true },
"dynamic_templates": [
{
"string_template": {
"match": "*_name",
"match_mapping_type": "string",
"mapping": {
"type": "string",
"index": "not_analyzed"
}
}
}
]
}
}
}
そして、これを以下のコマンドで登録します。これで、パーサの方で多少カラムを増減させても、末尾が”_name”のカラムについては常に要素解析の対象外になります。
curl -XPUT localhost:9200/myapp/ -d "`cat myapp.json `"
3.2.4. Kibanaの設定
Elasticsearchへのデータ登録が完了したら、index nameとしてmyapp、time-field nameとしてtimestampを指定すれば、Kibanaでデータを閲覧できるようになります。あとは、Visualize機能で表やらグラフを作って、Dashboard機能にポチポチ貼っていけば設定完了です。
このDashboard画面の作り方は、想定する運用設計によって変わるところで、ログ監視システムの肝になるところです。今回は運用設計の節で説明した運用を想定し、以下のようにDashboardを設定しました。
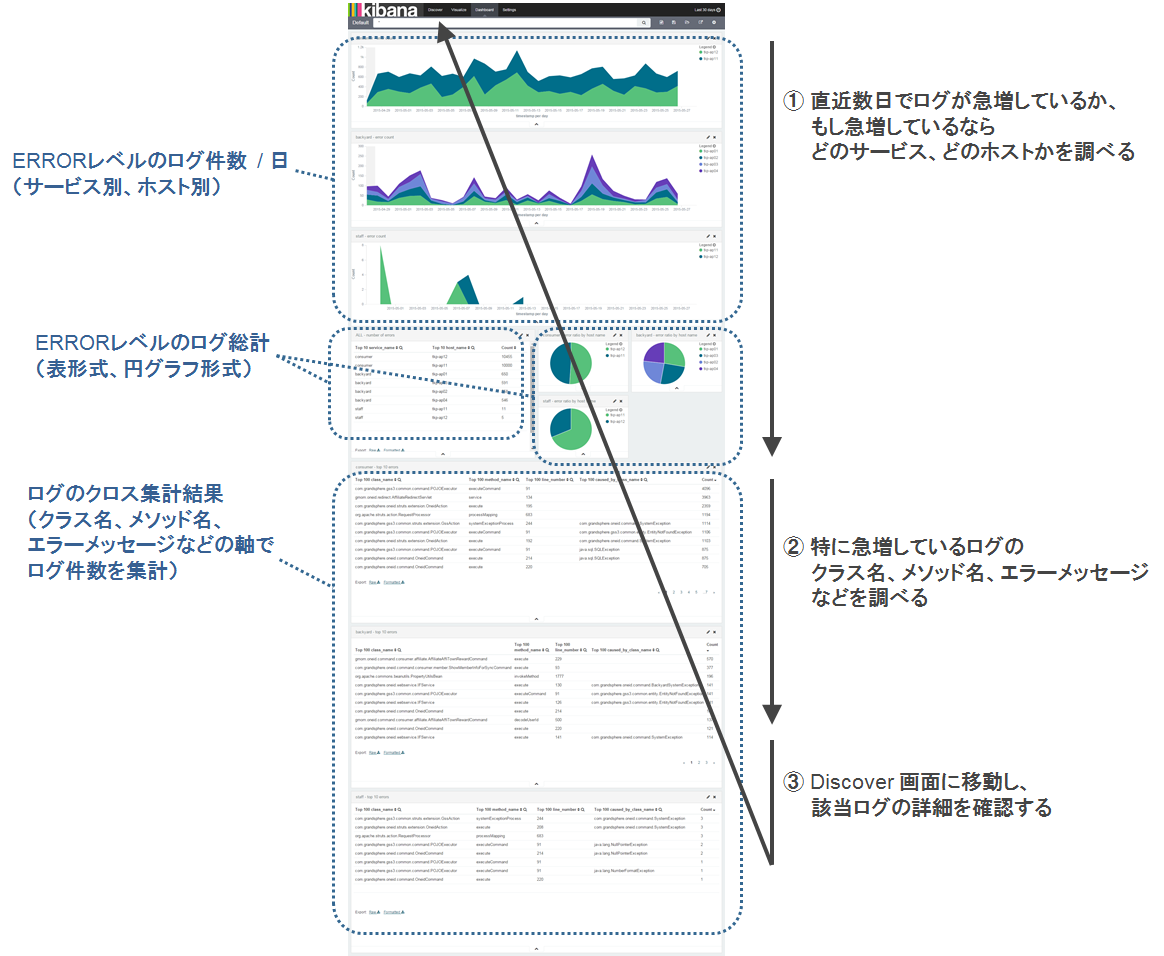
実際にKibanaを使ってみて気付いた欠点としては、Dashboardで、件数が急増しているログの種類(クラス名、メソッド名など)を発見しても、その種類を検索条件としてDiscoverの画面に持ち越せないことが分かりました。そのクラス名などを、Discoverの画面で再度手入力しなければいけないのは面倒なので、なにかよい方法があるといいんですが……。
3.3. Embulk + PostgreSQL + Excel(システム構成図の下半分)
Elasticsearch + Kibanaの可視化機能はすばらしいのですが、手慣れたSQLやらExcelを使った集計を行いたい場合もあります。そのために、PostgreSQLにもログを格納します。
3.3.1. Embulkの設定(gzipファイル入力 → パース → PostgreSQL出力)
Embulkの設定ファイルは、Elasticsearchの場合とほぼ同じです。outputプラグインの部分だけ、以下のようにembulk-parser-postgresqlの設定に変更します。
in:
type: file
path_prefix: /data/service01/host01/myapp.log.
decoders:
- {type: gzip}
parser:
charset: UTF-8
newline: LF
type: myapp
log_levels: [ "ERROR" ]
host: "host01"
service: "service01"
out:
type: postgresql
host: localhost
user: myapp
password: "nankasugoipassword"
database: myapp
table: logs
mode: insert
embulk-output-postgresqlプラグインのmodeを”insert”に設定すると、すべてのレコードの追加に成功した場合のみ、logsテーブルへの書き込みが行われます。その他の選択肢についてはembulk-output-postgresqlプラグインのページをご参照ください。
3.3.2. PostgreSQLの設定
Embulkからデータを登録するために、データベースと、そのデータベースを操作する権限を持つロールを事前に定義しておく必要があります。
テーブルの作成は、embulk-output-postgresqlプラグインが勝手に行ってくれるので特に必要ありません。また、このプラグインが勝手に決めるテーブル定義を変更したい、例えばNOT NULL制約を付けたい、という場合は、プラグインの設定にテーブル定義を含めておけばOKです。
3.3.3. Embulkの設定(PostgreSQL入力 → フィルタ → PostgreSQL出力)
エラーメッセージのなかには、そのままクロス集計するには向かないものがあります。例えば、「ログイン失敗: userId=(数値)」というエラーメッセージがあると、集計結果の行数が必要以上に多くなってしまいます。このようなエラーメッセージはすべて「ログイン失敗」のように抽象化してから集計したほうが実用的でしょう。
このような抽象化処理は、Embulkのfilterプラグインとして手軽に実装できます。filterプラグインの実装方法については、以下の記事をご参考ください。
そして以下のように設定ファイルを記載すると、PostgreSQLのlogsテーブルからログを取り出して、filterプラグイン(図中の”myapp abstract filter plugin”)に通し、abstract_logsテーブルに登録できます。
in: type: postgresql host: localhost user: myapp password: "nankasugoipassword" database: myapp table: logs filters: - type: myapp-abstract out: type: postgresql host: localhost user: myapp password: "nankasugoipassword" database: myapp table: abstract_logs mode: replace
file inputプラグインと違って、postgresql inputプラグインには「前回読んだところの続きから読む」機能はありません。そのため、modeに”replace”を追加して、abstract_logsテーブルを毎回作りなおしています。
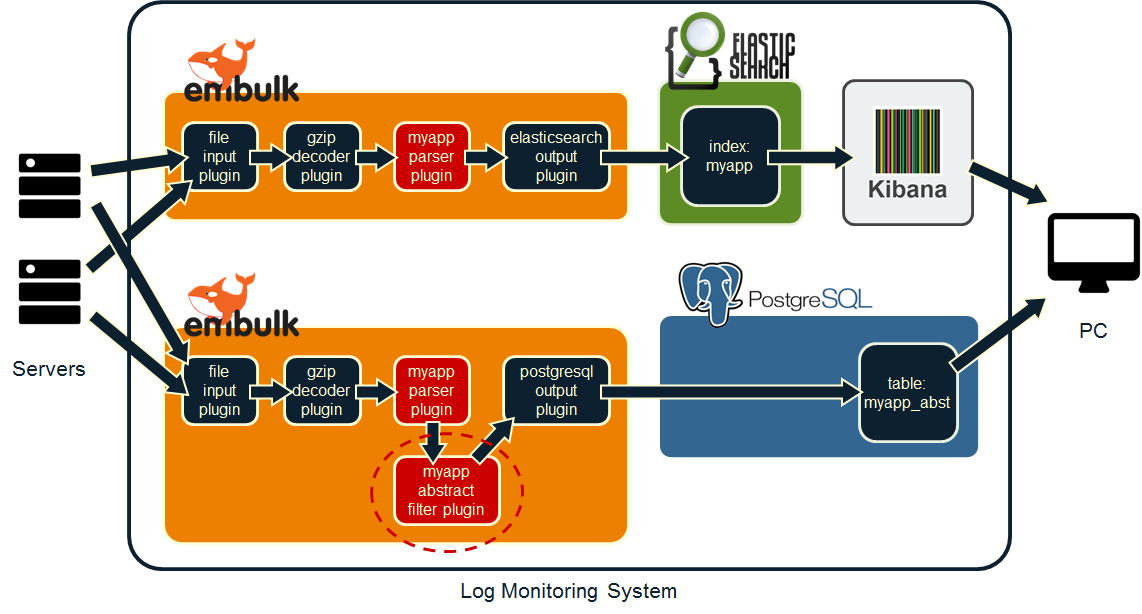
ただ、すべてのログを毎回抽象化処理に通すのはさすがに時間がかかるので、ある程度運用してフィルタの内容が固まったら、以下のようにシステム構成を変えると良いでしょう(変更点は図中の点線丸枠)。入力/出力が変わっても、一度作ったフィルタをこうやって使いまわせるのは、Embulkの大きなメリットだと思います。
3.3.4. PostgreSQLやExcelでのクロス集計
ここまでくれば、あとはSQLを使うなり、その集計結果をCSVやTSVファイルに出力してExcelに渡すなりして集計できます。私の環境では、
SELECT
date_part('year', timestamp) AS year,
date_part('month', timestamp) AS month,
date_part('day', timestamp) AS day,
class_name,
method_name,
message,
second_line,
COUNT(timestamp) as count
FROM abstract_logs
GROUP BY year, month, day, class_name, method_name, message, second_line
ORDER BY year, month, day, class_name, method_name, message, second_line;
のようなSQLをテキストファイル(summary.sql)に記載し、
psql -U oneid tokup -t -A -F#039;\t' -f summary.sql -o summary.tsv
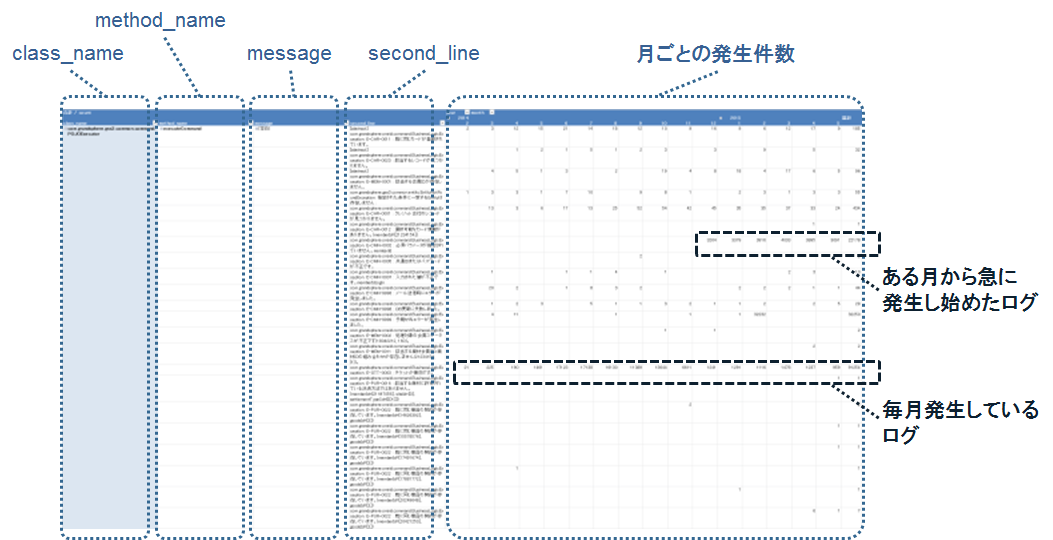
のようなコマンドを実行してTSVファイルに出力し、Excelに読み込ませて、以下のようなピボットテーブルを作成しています。これで、ログの種類ごとに、月ごとのログ発生件数を一覧し、特定の種類のログが急増しているかどうかを発見できる、というわけです。
4. まとめ
今回は、大量のERRORログを吐き出すWebアプリに対して、僅かな時間で行える監視作業の運用設計(運用パターンの定義)を行い、その運用を助けるログ監視システムを構築しました。
監視したいログに合わせて2種類のEmbulkプラグイン(parserとfilter)を開発した以外は、既存のソフトウェアやEmbulkプラグインを組み合わせることで、手軽に実用的なログ監視システムを実現できることが分かりました。
実際にシステムを構築してみた感想としては、いままでスクリプト言語で実装していたログのパース処理をEmbulkのプラグインとして実装することで、パース処理の再利用性をかなり上げられそうな手応えを感じました。今回の例で言うと、filterの試作段階ではpostgresqlをinputとして使い、filterの実装が固まったらパース処理に挟み込む、といったことがコードの修正なしでできるのは嬉しいところです。
一方、課題としては、Embulkにはログの差分読み込みの機能が不足しているので、即時性が必要なログの解析にはやはり向かなそうです。例えば、1分前のログもKibanaで検索したいといった場合には、無理にEmbulkで頑張ろうとせずに、素直に大本のWebアプリを改善し、Fluentdなどを使ってシステム構築したほうが良さそうです。そこは、導入の手軽さとのトレードオフですね。
今後は、今回構築したシステムを運用しながら改善しつつ、よく使いそうな機能についてはEmbulkプラグインとして配布するなど、ノウハウを展開していきたいと思います。似たような状況に遭遇して
逃げそこなっている読者の方は、今回ご紹介した方法を是非お試しください。次世代システム研究室では、グループ全体のインテグレーションを支援してくれるアーキテクトを募集しています。インフラ設計、構築経験者の方、次世代システム研究室にご興味を持って頂ける方がいらっしゃいましたら、ぜひ 募集職種一覧 からご応募をお願いします。
皆さんのご応募をお待ちしています。
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD