ERRORログが多すぎるWebアプリに出会ったら
![]()
次世代システム研究室のDevOpsネタ担当(最近は運用寄り)のM. Y.です。
最近仕事で、あるWebアプリのログファイルを解析する機会がありました。そのログファイルはERRORレベルのエラーログが非常に多く、それらのERRORログから実際に注意しなければならないログを発見する、というのがそのときの目的でした。
アプリを作り始めたときはログ形式に注意を払っていたのに、そのアプリが歴史を重ねるうちにルールが曖昧になったり、開発者が変わってルールが失伝しまうというのは良くあることだと思います。逆に、大したことないアプリだと思って適当なログ形式にして作ったら、思った以上に長年使われて後悔するというパターンもありますよね。私も、そういう経験が何度かあります。
そこで今回は、ありがちな事例を描画して、そういうWebアプリに出会ってしまったときの対処方法について考えてみます。また、後半ではログ解析の分野で最近注目されているEmbulkを活用した対策についてご紹介します。読者の方が同じような事例に出会ってしまった時の参考になれば幸いです。
ありがちな事例
過去の個人的な経験から、ERRORログが多すぎて辛い事例について、ありがちな事例を抽象化して描画してみます。ERRORログを障害検出に使えなくなる
ERRORログの数が少なければ、ERRORログが発生する=サービスに障害(サービス停止または致命的な品質劣化)が発生していると判断できます。従って、ERRORログを障害検出に使うことができます。ERRORログが発生したら担当者にアラートメールを送信する、といった仕組みはよくありますよね。しかし、例えばERRORログが1日あたり500件とか1,000件とか発生していたら、当たり前ですが障害検出には使えません。というか1件ずつ内容確認してたら、他に何も出来ないですよね。それなのに、アプリを作り始めた、ERRORログで障害検出ができていた頃と同じように、ERRORログが発生したらアラートメールを送信するようになっていたら……。
ERRORログを異常検出や傾向把握にも使えなくなる
ERRORログの数が多すぎたとしても、ERRORログの発生件数の増減自体は、何らかの異常検出(※)や傾向分析に使えるかもしれません。(※)ここでは、「異常」という言葉を、通常時とは異なる状態、将来の障害の予兆を含むものを指すために使います。
ERRORログを何種類かに分類し、それぞれの種類の発生件数を調べることができれば、異常検出や傾向分析も可能だと思います。しかし、このようにERRORログが多すぎるWebアプリでは往々にしてログ形式が不規則になっており、そのような傾向をつかむことも難しい、と個人的には考えています。
例えば、Javaで開発されたWebアプリが、以下の様な形式でログを出力していたとします。
[日時] [ログレベル] [クラス名] [行数] [エラーメッセージ]
[例外クラス名1]: [例外メッセージ1]
at [スタックトレース1.1]
at [スタックトレース1.2]
(中略)
Caused by: [例外クラス名2]: [例外メッセージ2]
at [スタックトレース2.1]
at [スタックトレース2.2]
(中略)
Caused by: [例外クラス名3]: [例外メッセージ3]
at [スタックトレース3.1]
at [スタックトレース3.2]
(中略)
[日時] [ログレベル] [クラス名] [行数] [エラーメッセージ]
[例外クラス名1]: [例外メッセージ1]
at [スタックトレース1.1]
(後略)
これは、ログ形式が統一されていると言えるでしょうか? 確かに形式は統一されているのですが、意味のある情報を入れる場所が統一されていない場合があります。例えば、エラーの種類によっては「エラーメッセージ」欄に意味のある情報があり、他のエラーでは「エラーメッセージ」欄は空なので「例外メッセージ1」を見なければならず、場合によっては「例外メッセージ3」に意味のある情報が……なんてことが起こりえます(よね?)。こうなると、「エラーメッセージ」欄ごとの発生件数でグラフを描いたりしても、実質的に意味のある情報は出てきません。
エラーの種類を一意に示すエラーコードを決めて、それをエラーメッセージに含める、ということもよくあると思います。しかし、このような現場では同じエラーコードをあちこちで使い回してしまい、結局はスタックトレースのクラス名や行番号を見ないとエラーの根本原因が分からない、というのもよく聞く話です。
ERRORログの特徴をつかむ方法
このようなログに出会った場合の、自分の過去の行動を振り返ってみると、結局は自作のパーサと、Excelのピボットテーブル機能に頼ってきた気がします。だいたい以下のような感じです。似たようなことをしている人も多いのではないでしょうか。- 複数行からなるログを、1つの塊としてパースするパーサを書く。
- 明らかに分析する意味のないログ(INFOレベルのログなど)を除外する。
- ログの塊のなかで、意味がありそうな部分をCSVファイルに出力する。上の例で言うと、
[日時],[ログレベル],[クラス名],[行数],[エラーメッセージ],[例外クラス名1],[例外メッセージ1],[スタックトレース1.1],[例外クラス名2],[例外メッセージ2],[スタックトレース2.1],[例外クラス名3],[例外メッセージ3],[スタックトレース3.1]
といった、少しでも可能性がある列をすべて含むCSVをまずは出力する。 - 出力したCSVファイルをExcelで読み込み、ピボットテーブル機能を使って、日ごと(または週ごとや月ごと)の発生件数を出力する。

この例で言うと、”Some kind of error message”エラーメッセージが発生する原因には6個の例外があり、AaaaExceptionは8月から急に発生し始め、FfffExceptionは恒常的に発生している……といった傾向が分かります。
- ピボットテーブル機能で行ラベルを取っ替え引っ替えして、抽出して意味のありそうな部分を絞り込む。
- 意味のありそうな部分が多すぎる場合は、列を結合する。このクラス名の場合はエラーメッセージに意味があり、別のクラス名の場合は例外メッセージ1に意味がある、という場合は、両者の文字列を繋いだ新しい列を作る。
- ピボットテーブルを眺めて、行が多すぎる場合は、行を結合する。
例えば、ログメッセージの中に “userId=(数値)” という文字列があって行が多すぎる場合は、(数値)の部分を”****”などに置換して、行の数を減らす。
- ただし、この例で言うと、特定のユーザでだけそのログメッセージが多く発生している場合は、問題の原因を見逃してしまう可能性があるので、その場合は結合しない。
- ピボットテーブルを眺めて、エラーメッセージの中に意味のある構造がありそうな場合は、パーサを修正して、CSV出力からやり直す。
- 例えば、エラーメッセージの中が”エラーコード: 日本語メッセージ”といった構造になっている場合は、エラーメッセージの列を、エラーコードの列と日本語メッセージの列に分ける。
- エラーの種類ごとの発生件数を確認し、総発生件数が上位10件のログ(=ずっと出ているログ)や、過去数日~数ヶ月の発生件数が上位10件のログ(=急に出始めたログ)をランク付けする。そして、上位のログについて、発生元のクラスやメソッドを詳しく調べる。
この方法の問題点
この方法はお手軽かつ、一応はERRORログの傾向が把握できるのですが、明らかな問題がいくつかあります。- ログの量が増えたらExcelで開けない
- 経験上、ログを絞り込んで、パースした結果のCSVファイルが100MB程度に収まれば、Excelで開いて、ピボットテーブル機能を使えました。ただ、そのくらいのサイズになるとファイルを開くまでに数分かかるため、中身を見てパーサを直して……というサイクルは回しづらくなります。これ以上の規模になったら恐らく実用に耐えないでしょう。
- 人間の勘に頼っており、自動化できず、時間がかかる
- 上の手順に書いた「意味のありそうな列」や「意味のある構造」というのは感覚的なものでしかないため、他の人には伝達できず、自動化も難しいです。また、勘に頼っているので、重要なエラーの見逃しもありえます。
上記の問題点への対策
まず問題点Aについては、パース結果を一旦データベースに格納し、データベース上のデータからピボットテーブル相当の表を自動生成する、という対策が考えられます。例えば、PostgreSQLであればCOPYコマンドを使って、CSVファイルをテーブルに挿入できます。あとは、列の組合せごとの出現回数をCOUNT関数で数えて、その結果をExcelで眺める……まあExcelでなくてもいいんですけど。列の絞り込みは最終的に必要なので、そこは結局Excelのピボットテーブル機能を使うのが楽かもしれません。
あるいは、これから新たにパーサを開発する場合であれば、Embulkのparserプラグインとしてパーサを開発するという方法もあります。Embulkとは、バルクデータローダを簡単に開発できるようにするためのミドルウェアで、データの入力方法、出力方法、パース方法などをプラグインとして差し替え可能になっています(以下の図は、Embulkに関する発表資料からの抜粋)。
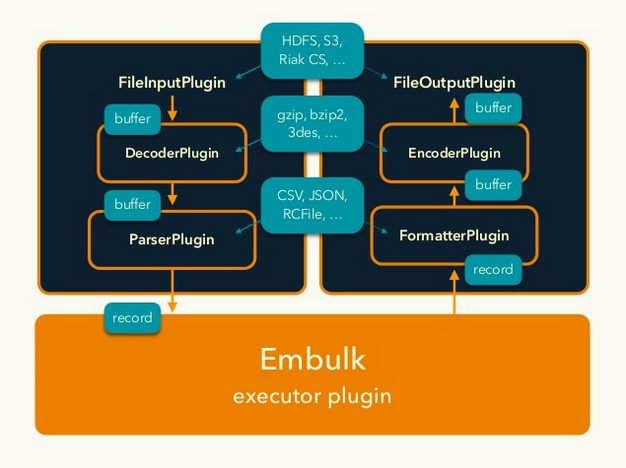
例えば、以下の機能は、既存のプラグインを使うだけで実現できます。また、embulkコマンドにはパース結果のプレビュー機能(embulk previewコマンド)があり、パーサの開発中には便利です。
- 連番(あるいは連続した日付)が付けられたログファイルの自動読み込み
- gzip圧縮されたログファイルの解凍
- データベースへの書き込み(データベースの種類はプラグインで差し替え可)
- 複数行からなるログを解析するために、EmbulkのparserプラグインをRubyで開発する話(準備編)
- 複数行からなるログを解析するために、EmbulkのparserプラグインをRubyで開発する話(実践編)
問題点Bについては、問題点Aよりもかなり難しくて、意味のある列の発見を自動化することは難しいと思いますが、試行錯誤を助けることはできるかもしれません。例えば、ログ発生件数をランク付けしたり、ログ発生件数が極端に変化した日をハイライトするくらいは可能ではないでしょうか。
まとめ
今回は、ログ形式は変えられず、分析方法を色々工夫するしか無い、という前提で話を進めてきました。しかし、もちろん理想的な対策は、ログ形式をきちんと決めて、FluentdやFlume、Sentryのようなツールを使って、最初からログを構造化して蓄積することです。ただ、ログ形式をまともに統一できないような開発現場では、結局はそれぞれのキーに格納すべき情報を統一できない、あるいは特定のキーの中に”userId=1234″のような構造を持った文字列を埋め込んでしまう、といったことになるのではないかと思います。ツールの導入は、このような事態を避ける根本的な解決策にはならないでしょう。
プログラミングをしていると、常に新しいアプリを作るという立場に居られるとも限りません。ERRORログが多すぎるWebアプリに出会ったときに、落ち着いて
次世代システム研究室では、グループ全体のインテグレーションを支援してくれるアーキテクトを募集しています。インフラ設計、構築経験者の方、次世代システム研究室にご興味を持って頂ける方がいらっしゃいましたら、ぜひ 募集職種一覧 からご応募をお願いします。
皆さんのご応募をお待ちしています。




