2019.10.03
Kubernetes をオンプレの本番環境に導入してそろそろ1年経つよっていう話
イントロダクション
D.M. です。10年以上に渡って小さなリニューアルを繰り返しながら運営している GMO ポイントですが、2018年11月に Docker / Kubernetes を導入しました。導入のモチベーションとしてはそろそろコンテナ技術を使いこなして依存ライブラリのヴァージョンアップとかを行えるようにしたいといったあたりでした。全くダウンすることなくだいたい1年運用できましたのでどんな感じになのかをご紹介します。
この記事を読むべき人
・Docker / Kubernetes を利用したコンテナ化の事例に興味がある人。
・Kubernetes の基本概念や用語はあまり説明しないのである程度理解している人向けです。
やったこと
・オンプレ運用している Openstack クラウドに Kubernetes を入れました。
・もともと全体で100個ぐらいの VM で運用していた環境で、いくつかのアプリケーションを Kubernetes 配下の Docker コンテナ化しました。以前は PHP が素で VM にインストールされてものを Kubernetes の Pod / Service 化しました。
・VM は Openstack で予め作ってます。負荷に応じて自動的に増えたり減ったりするのはできてないです。
・Kubernetes クラスタは rke で作っています。公式はこちら。
用語のおさらい
Kubernetes の世界ではアプリ1種類の最小単位は Pod です。Pod にはアプリ動作に必要な Docker コンテナが複数入っています。同じ機能の Pod が複数集まって Service というグループになります。
(例)Frontend Service = Frontend Pod を複数個をグルーピングしてある。アプリサーバ複数台構成的な概念。
Frontend Pod = Nginx, PHP-FPM, NodeJS の3つの Docker コンテナを持ち1つのアプリケーションとして動作する。アプリサーバ1台と捉えてよい。
1つの VM に複数の Pod を載せたりできます。
1つの VM に複数の Pod を載せたりできます。
構成
出来上がった構成はこんな感じです。(だいぶデフォルメしてる)
従来のアプリサーバの枠をまるっと Kubernetes クラスタにした感じです。
従来のアプリサーバの枠をまるっと Kubernetes クラスタにした感じです。
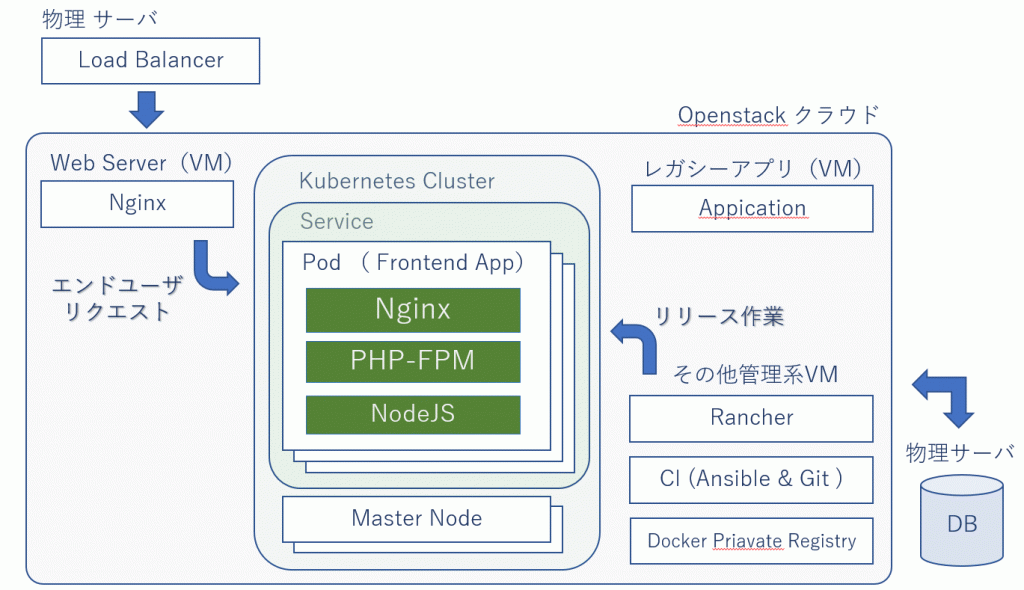
上図では Service が Frontend App だけですが、実際は6種類ありまして Elasticsearch も入っています。
Kubernetes 導入後に開発したアプリはすべてこの仕組みに乗せる前提で作られています。
DB はもともと物理だったのでクラスタに入れていません。
また一部のレガシーアプリは普通の VM にそのまま残っています。
デプロイ時のフロー
こんなフローです。
1. ローカル PC で PHP のソースや Dockerfile を修正して git レポジトリへプッシュ。
2. CI サーバでコマンドを使って Docker イメージをビルド、Docker Private Registry へプッシュします。
3. クラスタへの反映は Bamboo( Atlassian 社のツール。いわば高機能 Jenkins です)のブラウザの管理画面からデプロイボタンを押す。内部的には ssh で kubectl apply -f deployment.yml コマンドを発行してます。これで各 Service の Pod が最新の Docker イメージへ更新されます。
4. Rancher で Pod 更新の確認。問題が起きれば Rancher と Prometheus からログを参照する。( kubectl logs 、kubectl describe などが画面から見られる)
開発と本番で環境ごとにクラスタが別れているので、互いに影響なくデプロイできます。開発環境でのテストが終わったら本番で同じことを実行します。
頑張ったところ
・Docker イメージをつくる Dockerfile は1種類で全環境共通です。設定ファイルなどを初期化時に読む感じ。
・Deployment.yml も共通にしたかったですが Docker イメージのタグ名が環境ごとに変わるので別のファイルになっています。
Docker イメージのタグを変えるのは以下のような感じです。
Docker イメージのタグを変えるのは以下のような感じです。
gmo_point/frontend:develop
gmo_point/frontend:production
・アプリログが複数種類あって別々に処理する必要があったので Logging Driver の fluentd は利用していません(これをやるとログが1種類になってしまう)。アプリログはマウントした Host 側のディレクトリにファイル出力して、別の独立した fluentd の Pod がそれらをまたマウントしてログ集積環境へ流しています。(サイドカー方式)
妥協したところ
・アプリは DaemonSet でデプロイしていて 1 Node 1 Pod みたいな感じになっています。自動で VM が増えたりリソース割当を細く設計するなどはやれてないです。 Openstack なので API で VM 増やすなどは頑張ればできるのですがあまり強いニーズがありませんでした。重いアプリが同じ Node でかぶらないように Label をつかって管理しています。
・全アプリのコンテナ化はできておらず比較的新しいプロダクトを中心に対応しました。レガシー系はまだ手付かずなので時期を見て改善したいです。
やっててハマった問題
iptables 問題
セキュリティの都合で Kubernetes 配下の VM で Firewalld の設定を変更する運用が必要になったのですが、これが原因で iptables 取り合い問題が発生しました。 Docker / Kubernetes は iptables を変更して Host とコンテナの通信をしていますが、 Firewalld を設定するとこちらも iptables を変更するので通信が不能になる問題が発生しました。
Docker の通信の復活には以下のコマンドで iptables を一旦初期化します。Kubernetes の場合は自動的に iptables を再生してくれます。Docker 単体の場合は Docker デーモンを再起動します。
iptables --flush
このあと Firewalld を当て直すのですが正直手順が混乱したので運用上厳密に Firewalld が必要な VM とそうでない VM を分けて、Firewalld と Docker / Kubernetes と一緒に使わないようにしました。どうしても必要な場合は Firewalld を書き換えたら Docker も再起動するなど然るべき手順を踏んで iptables を作り直すようにしています。
ヴァージョンアップ更新コスト
ヴァージョンアップ動作確認+各環境ごとのメンテは手動なのでそこそこ工数が必要です。 Kubernetes のヴァージョンアップは1年で 2018年3月 1.10 -> 2019年3月 1.14 っていう感じで結構頻繁にあって、現状複数のクラスタがあるので切り離して作業しています。
これについては別記事があるのでこちらをご参照ください。
おまけ:マニフェストファイルの設定のポイント
マニュフェストファイル deployment.yml でいろいろ設定していますが運用上重要だったり議論の余地がありそうなポイントだけを列挙して紹介します。
kind: DaemonSet
DaemonSet は 1 VM で 1Pod に固定するときに使います。負荷が高いことがわかっているアプリをほぼ 1 VM 専有で使っていく感じの設定です。また複数のアプリログを Host へファイル出力する都合で1つにしたほうが楽だったのでこれを選んでます。
updateStrategy: rollingUpdate: maxUnavailable: 1
Pod の更新時にローリングアップデート機能で更新が1つずつ走るように maxUnavailable パラメータを 1 に設定しています。この値は負荷や Pod 数をみてアプリごとに変更しています。例えば Pod 数 4 で負荷の懸念が弱い場合は maxUnavailable 2 にしたりしてます。
- name: frontend image: "private.registry/gmo_point/frontend:develop" imagePullPolicy: "Always"
ここは Docker イメージの指定箇所ですが、必ず環境名のタグ付きにしています。全環境を latest とかで運用すると開発中のイメージがいきなり本番に上がってしまう問題があったので分けるようにしました。
livenessProbe: initialDelaySeconds: 10 periodSeconds: 10 exec: command: - "true"
livenessProbe で Pod の死活監視をしています。レスが来ないときは自動的に再生されます。
readinessProbe: initialDelaySeconds: 5 periodSeconds: 20 httpGet: path: / port: 80 httpHeaders: - name: X-k8s-Header value: readiness
readinessProbe は Pod 入れ替えのときにそこにアクセスを振り分けてよいかを判定する仕組みです。 path の箇所で、アプリが起動したらレスポンス可能になる URL を指定している。
成果
・アプリを Docker コンテナ化できた。
・Kubernetes クラスタ内に自在にコンテナを展開できるようになった。
最後に
次世代システム研究室では、グループ全体のインテグレーションを支援してくれるアーキテクトを募集しています。アプリケーション開発者の方、次世代システム研究室にご興味を持って頂ける方がいらっしゃいましたら、ぜひ 募集職種一覧 からご応募をお願いします。
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD