2019.10.03
Kubernetesクラスタのバージョンアップ
はじめに
こんにちは。次世代システム研究室のT.Tです。
運用を担当しているサービスのアプリケーション基盤にKubernetesを導入して一年程経ちました。その間稼働中のサービスでは大きな問題が発生することもなく無事運用できています。オンプレでKubernetes環境を構築しているため、環境構築が大変だったのもさながら、サービス影響を与えずに運用中のKubernetesに新しいPodグループの追加したり、Pod内のソフトウェアのバージョンを更新したりといった構成の変更をするのもまた一苦労ありました。ここ一年あれこれ検証しながら色々な運用ノウハウを蓄積しつつなんとか安定運用に辿りついたところです。
そんな中Kubernetesは導入後一度もバージョンアップができておらず、稼働中のバージョンはサポート対象から外れてしまいました。サポート期間が短いのは導入当初から把握していてバージョンアップも大きな課題の一つとして認識してましたが、運用初期は構成変更も多くKubernetesのバージョンアップ時に起きるであろうトラブルシューティングを並行して対処する自信もなく先送りになっていました。
ここのところアプリケーション更新に伴う構成変更は落ち着き、稼働中のKubernetesのバージョンがサポート対象から外れたことも相まって、いよいよKubernetesのバージョンアップに取り組んでみました。今回はバージョンアップでの留意点と実際のバージョンアップ作業の内容についてご紹介したいと思います。
環境の概要
本環境のKubernetesはKubernetesのクラスタ環境を構築するツールであるRKEを使って構築されており、Kubernetesのバージョンはv1.10系からv1.14系に直接バージョンアップしています。本稿ではこのRKEを使ったバージョンアップについて触れたいと思います。
バージョンアップ時の留意点
どのバージョンに上げるか
RKEでバージョンを上げるため、まずRKEのリリース情報からどのバージョンのKubernetesにバージョンアップできるか確認します。この中でRKEの安定バージョン(rcXがついていなもの)のリリースノートに書いてあるバージョンから選択します。今回は現時点で最新バージョンのv0.2.8がサポートしているv1.14.6を選択しました。
バージョンアップ対象のKubernetesの依存情報や更新情報(各バージョン分)を確認して他に更新するものがないか確認します。今回Dockerのバージョンはサポート対象のバージョンでしたが、少し古いのでDockerも合わせて更新しました。
RKEによるKubernetesコンポーネントの更新
RKEでのKubernetesコンポーネントのローリングアップデートは現時点ではサポートされていないので、稼働中のクラスタをRKEでバージョンアップするとダウンタイムが発生します。バックログによると将来的にはサポートされる見込みのようです。
バージョン混在ポリシー
Kubernetesのバージョンアップ中は旧バージョンと新バージョンが混在した状態になるので、バージョン混在ポリシーを確認します。概ね一つ違いのバージョンの混在しかサポートされていないので注意が必要です。クラスタ単位でバージョンが異なっていてクラスタ間連携せずにサービス内に混在する場合は特に問題ありません。また、kubectlのバージョンを上げる必要があるかも確認しておきます。
-
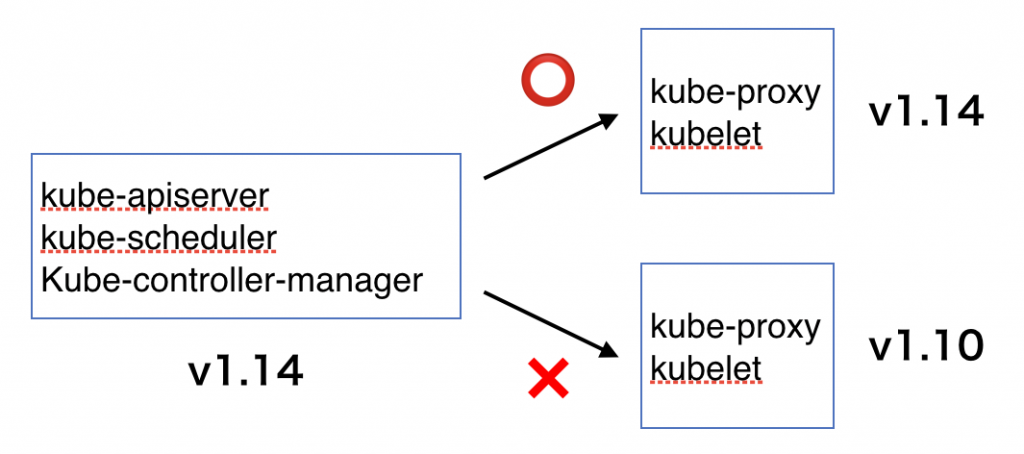
- コントロールプレーンのバージョン混在
-
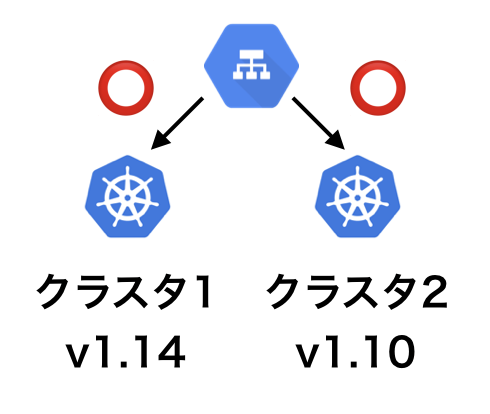
- クラスタのバージョン混在
他のコンポーネントとの互換性
RKEでは以下のKubernetesコンポーネントのバージョンをまとめて管理しているので、これらのコンポーネントについては特にバージョンの齟齬を気にする必要はありません。
- kube-apiserver
- kube-scheduler
- kube-controller-manager
- kube-proxy
- kubelet
一方、etcd、CNIプラグイン、DNSプラグイン等については個別に互換性を確認する必要があります。
バージョンアップの方針
方針の検討
バージョンアップ時の留意点を踏まえてバージョンアップの方針を検討しました。Kubernetesのバージョンは一つずつ上げるのが良さそうですが、複数バージョンを上げたい場合はその回数分手間が掛かってしまいます。一方、数バージョンを跨いで一気にバージョンアップしてしまうと思わぬ落とし穴にはまりそうです。
今回はKubernetesで標準コンポーネント以外のものをほとんど使っていないのと、あまり工数を掛けられない事情もあったためv1.10からv1.14に直接バージョンアップすることにしました。本番環境に適用するまでに開発環境とステージング環境で一週間程度の安定稼働を確認して、本番環境更新時はサービスからバージョンアップ対象のクラスタを切り離してバージョンアップ作業を行い、切り離された状態で疎通確認した上でバージョンアップしたクラスタをサービスに切り戻す形にしました。バージョンアップ中は普段は社内でのサービス検証用に使っているサービスから切り離されているクラスタを代わりに利用できたので特にバージョンアップのためにクラスタを用意する必要もありませんでした。
この方針ならクラスタ内のバージョン混在の検証も不要で一度のバージョンアップ作業で済むので工数の削減に繋がります。ステージング環境で安定稼働が実現できない場合は別の方針を検討することにして、この方針での検証を進めました。
バージョンアップ手順の概要
大まかなバージョンアップ手順は次のような手順になりました。クラスタ1が通常時本番稼働しているクラスタで、クラスタ2が社内確認用のクラスタです。
- クラスタ1を稼働中のサービスから切り離してクラスタ2でサービスを稼動させる
- クラスタ2での安定稼動を確認する
- クラスタ1のDockerをバージョンアップする
- クラスタ1のKubernetesをRKEでバージョンアップする
- kubectlのバージョンアップする
- クラスタ1を切り離した状態でクラスタ1の動作を確認する
- クラスタ1を切り戻してクラスタ2を切り離す
- クラスタ1での安定稼動を確認する
本番環境でのバージョンアップ
開発環境とステージング環境でのバージョンアップと安定稼働が確認できてから本番環境へ適用しました。ここでは本番環境のRKEでのバージョンアップ部分と発生した問題と対策について見ていきたいと思います。
RKEの設定
RKEではrancher-cluster.ymlファイルにクラスタの構成情報を記述してrke upコマンドによりクラスタを構築することができます。コンポーネントのバージョンアップもこのファイルにコンポーネントのバージョンを追記してからrke upにより実行できます。system_imagesプロパティにバージョンアップ対象のDockerイメージを指定します。
system_images: kubernetes: rancher/hyperkube:v1.14.6-rancher2
RKEの実行
バージョンアップ時に問題が発生したときに対処するために、デバッグログを標準出力とログファイルに出力するようにしてrke upを実行します。クラスタのノード数によってログサイズが数十MBから数百MBになるので少し注意が必要です。
rke -debug up --config rancher-cluster.yml | tee -a rke-update.log
実行ログを確認しているとhealthcheckエラーがしばらくの間出ていましたが、そのまま待っていたら落ち着いたので疎通確認を開始しました。
疎通確認
疎通確認のポイントとしては以下の箇所になります。ログやコンテナの監視ツールが導入できていない場合は直接各ノードのログやコンテナを確認しないといけないので大変です。
- 管理ノードとワーカーノードの疎通(kubectl get nodes)
- Podの起動状態(kubectl get pods –all-namespaces)
- サービスの起動状態(kubectl get svc –all-namespaces)
- サービスのエンドポイント(kubectl get ep –all-namespaces)
- 全ノードの各コントロールプレーンのログ(docker logs)
- アプリケーションやバッチ処理の動作とログの確認
- 監視ツールが監視しているURLとポートの確認
- その他Kubernetesリソースの確認(kubectl get all –all-namespaces)
一通り確認した上で特に問題がなかったので、クラスタ1を稼働サービスに切り戻して運用を再開してしばらくアプリケーションログ等を確認して問題なく稼働することを確認してバージョンアップ作業を終了しました。
発生した問題と対策
発生した問題
ところが、翌日になって監視ツールによるクリティカルなエラーが通知されてきました。いくつかのノードのkube-proxyとkube-apiserverのヘルスチェックエラーの通知でした。kube-proxyが動いていないとサービス影響が出るので急いでサービス側を確認してみましたが、特に障害があるようには見えません。
そこでもう少し詳細に調べてみると、クラスタ外から監視しているツールからのヘルスチェックがエラーになっていることが分かりました。kube-proxyのエラーが403で、kube-apiserverが400です。バージョンアップ作業完了に伴って監視設定を戻したタイミングで通知されたようです。本番環境でcurlでそのURLにリクエストを投げてみると確かに同じエラーが返ってきます。まだ古いバージョンで稼働している社内確認用のクラスタにリクエストを投げるとちゃんと200の内容が返されたので、バージョンアップ時に変更がありそうな起動引数に当たりを付けてバージョンアップ前後の環境でkube-proxyの起動引数を比較してみました。
古いバージョン(主要部のみ抜粋)
exec kube-proxy ... --healthz-bind-address=0.0.0.0 ...
新しいバージョン(主要部のみ抜粋)
exec kube-proxy ... --healthz-bind-address=127.0.0.1 ...
kube-proxyは、healthz-bind-addressを運用環境では設定していなかったためデフォルト値の変更の影響を受けて、クラスタ外部からヘルスチェックが(直接には)出来なくなってしまったために監視エラーを誘発していました。バージョンアップ時の疎通確認時にクラスタ外部から監視の確認が抜けてしまっていました。
一応確証を得るためにkube-proxyのリリースノートを確認してみましたが、特にそのような変更はありません。RKEを使っている場合はkube-proxyはhyperkube経由で起動するのでそちらの変更も確認してみました。するとどうやらhyperkubeの仕様変更だということが分かりました。
kube-apiserverも同じような問題だろうと思って同じように起動引数を比較してみると、こちらはhyperkubeのanonymous-authのデフォルト値の変更の影響を受けて監視エラーになっていることが分かりました。
対策
今の運用環境ではネットワークセキュリティ的にはバージョンアップ前の設定で問題ないので、ひとまず監視が成功するようにrancher-cluster.ymlに設定を追記してRKEで設定を更新して復旧しました。
kube-api:
extra_args:
anonymous-auth: true
kubeproxy:
extra_args:
healthz-bind-address: "0.0.0.0"
ステージング環境は監視部分も含めて本番環境に合わせておくと早めに問題が検出できると思います。また、ミドルウェアのバージョンアップ後にデフォルト値が変わることは割とよくあることなので、可能な限り明示的に設定しておくのが良さそうです。
証明書の更新
今回のバージョンアップとは直接関係ありませんが、RKE v0.2.0からKubernetes内ネットワークで使っている証明書を更新する機能が追加されました。以下のコマンドで実行できます。
rke cert rotate --config rancher-cluster.yml
証明書の期限が一年のため、証明書の更新も必要な時期になっていましたがこの機能が利用できるRKEのバージョンに上げていたので楽に証明書を更新することができました。利用する際はダウンタイムが発生する可能性があるので注意が必要です。
まとめ
今回初めてKubernetesのバージョンを上げてみましたが、EKSのKubernetesのバージョンでも最新ものが1.13.10のようなので、ちょっとゴールドエクスペリエンスしちゃいました。
それはさておき、サービス稼働に影響を与えない方法等の調査や準備、問題が発生した際のバックアッププラン等に時間を掛けたので予想していた通りの大変な作業になりました。しかし、実際の更新作業自体はそんなに時間は掛からず、各環境を今回の作業内容で同様に更新した(安定稼働確認期間や障害対応除く)としても全部で3人日くらいに収まりそうな工数感です。
それでもKubernetesは3ヵ月ごとにバージョンアップが行われ、9ヵ月でサポート期限が切れる更新サイクルなので、なるべくバージョンアップに掛ける工数は減らして置きたいところです。今回は慎重に進めるために実作業でも人手を多め掛けたところもありましたが、そういった部分はコントロールプレーンのログやコンテナの監視機能を強化したり、Kubernetesのバージョンを一つずつ上げて確認項目を減らすことで効率化できそうです。また、バージョンアップ後に問題が発生する可能性にも備えてクラスタを切り離して更新できる環境やカナリアアップデートで切り戻せる仕組みも工数の削減に繋げられそうです。
次世代システム研究室では、アプリケーション開発や設計を行うアーキテクトを募集しています。アプリケーション開発者の方、次世代システム研究室にご興味を持って頂ける方がいらっしゃいましたら、ぜひ 募集職種一覧 からご応募をお願いします。
皆さんのご応募をお待ちしています。
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD