2019.12.27
HyperOptによる深層機械学習モデルのハイパーパラメータチューニングをしてみた
こんにちは。次世代システム研究室のT.D.Qです。 前回は「TCNを用いてFX予測してみる」をテーマとしてブログを書きました。FX予測精度を向上するため、モデルのハイパーパラーメーターをうまくチューニング方法があるか興味を持っているので関連するチューニング技術及びツールを調査しました。今回の記事はHyperOptというライブラリーを用いて構築したTCNモデルのハイパーパラメータ最適化を紹介したいと思います。
ハイパーパラメータ最適化
機械学習におけるハイパーパラメータはモデル自身や学習に関わる手法が持つ性能に影響を及ぼす調整可能なパラメータです。例えばニューラルネットワークでは層数、ユニット数、活性化関数、ドロップアウト率、最適化手法等がハイパーパラメータにあたります。ハイパーパラメータはモデルの結果に大きく影響するので試行錯誤が必要です。 ハイパーパラメータ最適化(英語:Hyperparameter Optimization 省略:HPO)は未知の関数の出力を最大化あるいは最小化する問題と捉えられます。ハイパーパラメータを入力として、それで学習した機械学習モデルを関数、モデルを評価して得られた何らかの性能指標 (出力) を最も良くする (最大化・最小化) ことが目的です。
ハイパーパラメーターチューニング手法が満たすべき条件
下記は深層機械学習モデルはハイパーパラメーターチューニング手法が満たすべき条件です
- Strong anytime performance: 厳しい制約のもとで、良い性能が得られること
- Strong final performance: 緩い制約のもとで、非常に良い設定が得られること
- Effective use of parallel resources: 効率的に並列化できること
- Scalability: 非常に多くのパラメータ数でも問題なく扱うことができること
- Robustness & Flexibility: 目的関数値の観測ノイズや非常にセンシティブなパラメータに対しても頑健かつ柔軟であること
ハイパーパラメータ最適化の主な方法
ハイパーパラメータ調整の自動化は最適化問題として解くことができます。主な課題としては探索空間が広大、関数評価コストが高価、目的関数がノイジー、変数のタイプが多様などです。 下記の画像に現在で代表的なハイパーパラメータ最適化に関する方法が纏められています。詳細はこちらをご参照ください。 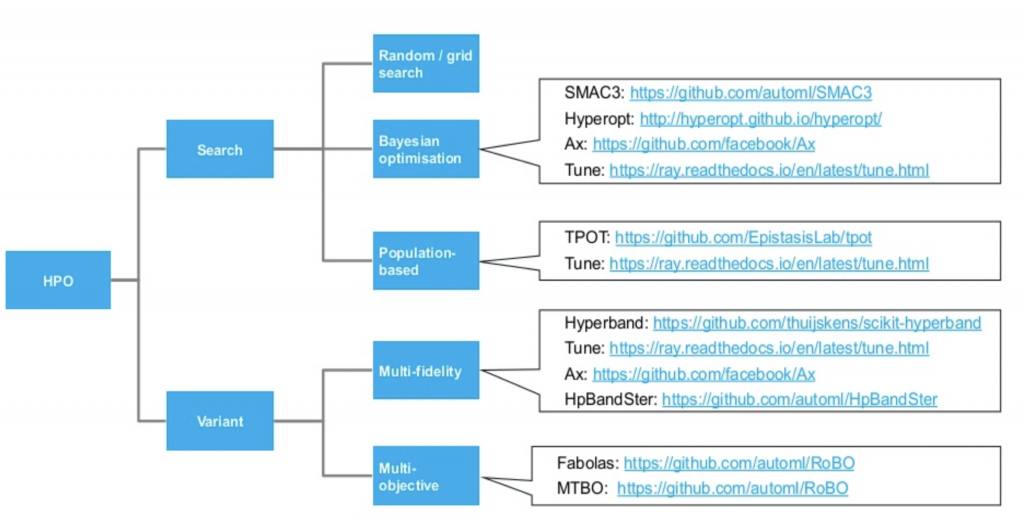 今回の記事はベイズ最適化を中心に研究開発が発展しているHyperOptフレームワークを使って見たいと思います。
今回の記事はベイズ最適化を中心に研究開発が発展しているHyperOptフレームワークを使って見たいと思います。
HyperOpt
HyperOptは「Distributed Asynchronous Hyperparameter Optimization」フレームワークで、機械学習モデルのハイパーパラメーターをBayesian Optimizationで最適化するフレームワークです。Tree-structured Parzen Estimator (TPE)アルゴリズムを使っていて、MongoDBまたはSparkで並列化に対応しています。 このフレームワークは、機械学習コンペティションの一つであるKaggleでよく用いられるものとして知られています。
HyperOptの最適化関数(fmin)
fminはHyperOptの基本となる関数です。Hyperoptでは、最適化したい目的関数及び検索するハイパーパラメータの範囲を用意して、それをfmin()に渡すと最適化をやってくれます。 下記はHyperOptのFmin関数の重要な引数です。具体的な設定は後ほどソースコードを公開しますのでご確認ください。 ・最小化する目的関数 ・検索するハイパーパラメータの範囲 ・検索したすべてのポイントの評価を格納するデータベース(任意) ・使用する検索アルゴリズム ・検索回数
機械学習のモデルに適用してみる
実行環境
今回もGPUクラウド by GMOの1GPUプランで下記のマシンで、nvidia-docker、Googleが提供するtensorflow:latest-gpu-jupyterイメージを使って機械学習の開発環境を構築してチューニングを行いました。
検索するハイパーパラメータの範囲
space = {
# nb_filters: The number of filters to use in the convolutional layers. Default nb_filters=64
'nb_filters': hp.choice('nb_filters', [16, 32, 64, 96, 128]),
# kernel_size: The size of the kernel to use in each convolutional layer. Default kernel_size=2
'kernel_size': hp.choice('kernel_size', [2, 4, 8]),
# dilations: The list of the dilations. Example is: [1, 2, 4, 8, 16, 32, 64]. Default dilations=(1, 2, 4, 8, 16, 32)
'dilations':hp.choice('dilations', [(1, 2, 4, 8, 16);
INSERT INTO `wp_posts` VALUES (1, 2, 4, 8, 16, 32);
INSERT INTO `wp_posts` VALUES (1, 2, 4, 8, 16, 32, 64)]),
# nb_stacks : The number of stacks of residual blocks to use. Default nb_stacks=1
'nb_stacks':hp.choice('nb_stacks', [1, 2, 3, 4]),
# padding: The padding to use in the convolutional layers, 'causal' or 'same'. Default padding='causal'
'padding': hp.choice('padding', ['causal']),
# use_skip_connections: Boolean. If we want to add skip connections from input to each residual block. Default use_skip_connections=True
'use_skip_connections': hp.choice('use_skip_connections', [True, False]),
# return_sequences: Boolean. Whether to return the last output in the output sequence, or the full sequence. Default return_sequences=False
'return_sequences': hp.choice('return_sequences', [False]),
# activation: The activation used in the residual blocks o = Activation(x + F(x)). Default activation='linear'
'tcn_activation': hp.choice('tcn_activation', ['relu', 'elu','linear']),
# dropout_rate: Float between 0 and 1. Fraction of the input units to drop. Default dropout_rate=0.0
'dropout_rate': hp.uniform('dropout_rate', 0.0, 0.3),
# name: Name of the model. Useful when having multiple TCN. Default name='tcn'
'name': hp.choice('name', ['tcn']),
# kernel_initializer: Initializer for the kernel weights matrix (Conv1D). Default kernel_initializer='he_normal'
'kernel_initializer': hp.choice('kernel_initializer', ['he_normal']),
# use_batch_norm: Whether to use batch normalization in the residual layers or not. Default use_batch_norm=False
'use_batch_norm': hp.choice('use_batch_norm', [False, True]),
#'use_batch_norm': hp.choice('use_batch_norm', [False]),
# Batch size fed for each gradient update
#'batch_size': hp.quniform('batch_size', 100, 450, 5),
# Choice of optimizer:
'optimizer': hp.choice('optimizer', ['Adam', 'Nadam', 'RMSprop']),
# Learning rate
'learning_rate':hp.uniform('learning_rate', 0.000001, 0.01),
# activation: The activation used in the residual blocks o = Activation(x + F(x)). Default activation='linear'
'dense_activation': hp.choice('dense_activation', ['relu', 'elu','linear'])
}
ハイパーパラメーターチューニング用のモデルを用意する
def build_tcn_model(hyper_space=None):
print(hyper_space)
i = Input(shape=(lookback_window, num_x_signals, ))
m = TCN(
nb_stacks=hyper_space['nb_stacks'],
nb_filters=hyper_space['nb_filters'],
kernel_size=int(hyper_space['kernel_size']),
dilations=hyper_space['dilations'],
padding=hyper_space['padding'],
use_skip_connections=hyper_space['use_skip_connections'],
dropout_rate=hyper_space['dropout_rate'],
return_sequences=hyper_space['return_sequences'],
activation=hyper_space['tcn_activation'],
name=hyper_space['name'],
kernel_initializer=hyper_space['kernel_initializer'],
use_batch_norm=hyper_space['use_batch_norm']
)(i)
m = Dense(num_y_signals, activation=hyper_space['dense_activation'])(m)
model = Model(inputs=[i], outputs=[m])
optimizer = get_optimizer(hyper_space['optimizer'], hyper_space['learning_rate'])
# We will set the loss-function that will be minimized.
model.compile(optimizer=optimizer,
loss='mse',
metrics=['mae'])
return model
目的関数の定義
FX予測するTCNモデルの欠損関数をHypOptの目的関数として定義します。
def build_and_train_tcn_model(hype_space=None, save_best_weights=False, log_for_tensorboard=False, verbose=0):
"""Build the deep TCN model and train it."""
K.set_learning_phase(1)
K.set_image_data_format('channels_last')
model = build_tcn_model(hype_space)
model_uuid = str(uuid.uuid4())[:5]
callbacks = []
callback_early_stopping = EarlyStopping(monitor='val_loss',
patience=5, verbose=verbose)
callbacks.append(callback_early_stopping)
# Weight saving callback:
if save_best_weights:
weights_save_path = os.path.join(
WEIGHTS_DIR, '{}.hdf5'.format(model_uuid))
print("Model's weights will be saved to: {}".format(weights_save_path))
if not os.path.exists(WEIGHTS_DIR):
os.makedirs(WEIGHTS_DIR)
callbacks.append(keras.callbacks.ModelCheckpoint(
weights_save_path,
monitor='val_loss',
verbose=verbose,
save_weights_only=True,
save_best_only=True))
# TensorBoard logging callback:
log_path = None
if log_for_tensorboard:
log_path = os.path.join(TENSORBOARD_DIR, model_uuid)
print("Tensorboard log files will be saved to: {}".format(log_path))
if not os.path.exists(log_path):
os.makedirs(log_path)
tb_callback = keras.callbacks.TensorBoard(
log_dir=log_path,
histogram_freq=2,
write_graph=True
)
tb_callback.set_model(model)
callbacks.append(tb_callback)
# Train net:
history = model.fit(
x_train_scaled,
y_train_scaled,
epochs=EPOCHS,
shuffle=True,
verbose=verbose,
validation_split = 0.1,
callbacks=callbacks
).history
# Test net:
K.set_learning_phase(0)
score = model.evaluate(x_test_scaled, y_test_scaled, verbose=0)
min_loss = min(history['val_mean_absolute_error'])
model_name = "model_{}_{}".format(str(min_loss), str(uuid.uuid4())[:5])
print("Model name: {}".format(model_name))
result = {
'loss':min_loss,
# Fine stats:
'best_evaluate_mae': min(history['val_mean_absolute_error']),
'best_evaluate_loss': min(history['val_loss']),
'model_name': model_name,
'space': hype_space,
'history': history,
'status': STATUS_OK
}
return model, model_name, result, log_path
ベースラインモデル
前回のブログで適用したハイパーパラメータをベースラインとして使いました。このハイパーパラメータは開発者の経験ベースで選択した値です。予測結果から見ると悪くはなかったが改善する余地あるはずです。
baseline_params = {
'nb_filters':64,
'kernel_size':2,
'nb_stacks':1,
'dilations':(1, 2, 4, 8, 16, 32),
'padding':'causal',
'use_skip_connections':True,
'dropout_rate':0.0,
'return_sequences':False,
'tcn_activation':'linear',
'name':'tcn',
'kernel_initializer':'he_normal',
'use_batch_norm':False,
'batch_size':256,
'dense_activation':'linear',
'optimizer':'RMSprop',
'learning_rate':0.0001
}
build_and_train_tcn_model(baseline_params, True, True, verbose=1)
上記のbuild_and_train_tcn_model関数を実行することでBaselineモデルの予測結果を得ました。テストセット評価でMAEとLossはかなり小さいですね。
{
'loss':0.0043330817,
'best_evaluate_mae':0.0043330817,
'best_evaluate_loss':2.6153981490890906e-05,
'model_name':'model_0.0043330817_f054e',
'space':{
'nb_filters':64,
'kernel_size':2,
'nb_stacks':1,
'dilations':(1,2,4,8,16,32),
'padding':'causal',
'use_skip_connections':True,
'dropout_rate':0.0,
'return_sequences':False,
'tcn_activation':'linear',
'name':'tcn',
'kernel_initializer':'he_normal',
'use_batch_norm':False,
'batch_size':256,
'dense_activation':'linear',
'optimizer':'RMSprop',
'learning_rate':0.0001
}
ハイパーパラメータチューニングを行う
下記はTCNの最適化関数です。この関数はHyperOptの最適化目的関数として使います。HyperOptの探索空間から選択したハイパーパラメータをこの関数に指定して実行することでベストMAEが返却されます。
def optimize_tcn(hype_space):
"""Build a temporal convolutional neural network and train it."""
try:
model, model_name, result, _ = build_and_train_tcn_model(hype_space)
# Save training results to disks with unique filenames
save_json_result(model_name, result)
K.clear_session()
del model
return result
except Exception as err:
try:
K.clear_session()
except:
pass
err_str = str(err)
print(err_str)
traceback_str = str(traceback.format_exc())
print(traceback_str)
return {
'status': STATUS_FAIL,
'err': err_str,
'traceback': traceback_str
}
次は、最適化関数の実験関数を実装します。この関数はHyperOptの最適化関数を呼ぶだけではなくて、HyperOptで探索した結果を記録し、前回の実験を基づいて次の探索に繋がるようにpickleの形式で保存しておきます。
def run_a_trial():
"""Run one TPE meta optimisation step and save its results."""
max_evals = nb_evals = 1
print("Attempt to resume a past training if it exists:")
try:
trials = pickle.load(open("results.pkl", "rb"))
print("Found saved Trials! Loading...")
max_evals = len(trials.trials) + nb_evals
print("Rerunning from {} trials to add another one.".format(
len(trials.trials)))
except:
trials = Trials()
print("Starting from scratch: new trials.")
best = fmin(
optimize_tcn,
space,
algo=tpe.suggest,
trials=trials,
max_evals=max_evals
)
pickle.dump(trials, open("results.pkl", "wb"))
print("\nOPTIMIZATION STEP COMPLETE.\n")
最後に、HyperOptの実行回数を指定してハイパーパラメータのチューニングを開始します。計算リソースに余裕があれば多く設定しても良いかと思いますが、今回はひとまず300回でやって見たいと思います。実験時間を見積もり・追跡したいので、tqdm_notebookを加えました。
MAX_SEARCH_NO = 300
for i in tqdm_notebook(range(MAX_SEARCH_NO)):
# Optimize a new model with the TPE Algorithm:
print("[Round {}]OPTIMIZING NEW MODEL:".format(i))
try:
run_a_trial()
except Exception as err:
err_str = str(err)
print(err_str)
traceback_str = str(traceback.format_exc())
print(traceback_str)
 上記は探索後のキャプチャーですが、開始してから約120時間経過してハイパーパラメータ探索が無事に終了になりました!かなり長かったですね。探索の平均時間は1440秒で約24分かかりました。
上記は探索後のキャプチャーですが、開始してから約120時間経過してハイパーパラメータ探索が無事に終了になりました!かなり長かったですね。探索の平均時間は1440秒で約24分かかりました。
ハイパーパラメータ最適化結果の確認
かなり時間かかってしまったので、今回のチューニングは実行し続けて223回目にて結果を確認して見ました。1回ごとに15 Epochsで欠損値とMAEを記録していますので、昇順でソートして一番良いMAE(最小値)を取得して評価して見ました。
results_folder_path = "logs/results" results = sorted(os.listdir(results_folder_path)) print(results)
ファイル名は「model_」.「ベストMAE」の形で作成されていますので、ファイル一覧を見るだけでベストモデルを判断できました。 モデルのハイパーパラメータをチューニングしている途中、MAEがあまり改善されなかったことも確認できましたね。
['model_0.0014724516_0f5da.txt.json', 'model_0.0014823143_cf742.txt.json', 'model_0.001553502_03dcd.txt.json', 'model_0.0015607874_b3bdd.txt.json', 'model_0.0015664555_5b819.txt.json', 'model_0.00158263_5c84f.txt.json', 'model_0.0015929794_ef530.txt.json', 'model_0.0015942692_ab6eb.txt.json', 'model_0.0016052735_2d08e.txt.json', 'model_0.0016188883_143bd.txt.json', 'model_0.0016313856_9a997.txt.json', 'model_0.0016326515_82d9b.txt.json', 'model_0.001634147_18209.txt.json', 'model_0.0016394991_a7759.txt.json', 'model_0.0016505416_cc7e5.txt.json', 〜〜〜〜一部抜粋〜〜〜〜 'model_1.7541016_5cf10.txt.json', 'model_1.7541016_8fa9c.txt.json', 'model_1.7541016_a6d30.txt.json', 'model_1.7541016_d34b1.txt.json', 'model_1.7541018_151d3.txt.json', 'model_1.7541018_ae4cc.txt.json', 'model_1.7541019_c8d74.txt.json', 'model_1.7541019_f6944.txt.json', 'model_1.7541021_7ea96.txt.json', 'model_1.7541022_9c0a2.txt.json', 'model_1.7541022_b7ac3.txt.json', 'model_1.754102_52cac.txt.json', 'model_68542100000000.0_f0f59.txt.json']
チューニングで記録されたベストモデルの詳細を確認したいので、ファイルをロードして中身を確認します。
jsons = []
for file_name in results:
file_path = os.path.join(results_folder_path, file_name)
with open(file_path) as f:
j = json.load(f)
jsons.append(j)
pp.pprint(jsons[0])
下記は探索した結果の中にベストハイパーパラメータの内容です。確認しましょう。
{ 'best_evaluate_loss': 4.480127813710875e-06,
'best_evaluate_mae': 0.001472451607696712,
'history': { 'loss': [ 0.06268401839113275,
0.0015634290061643276,
0.0005453722971145023,
0.0002131523218243765,
0.00025820608772427823,
4.987375059439565e-05,
6.589414158823326e-05,
2.848575257424118e-05,
2.3875383859668296e-05,
2.7494435403037255e-05,
1.7007686243778408e-05,
1.8732064150341902e-05,
1.6311658059624716e-05,
1.620866679394158e-05,
1.317642670889807e-05],
'mean_absolute_error': [ 0.10559753328561783,
0.030397586524486542,
0.017583195120096207,
0.010852760635316372,
0.00834423117339611,
0.004964512772858143,
0.004883946850895882,
0.003626481629908085,
0.003496214747428894,
0.0033904502633959055,
0.002882162109017372,
0.002965498948469758,
0.002738888142630458,
0.0026187465991824865,
0.0025458817835897207],
'val_loss': [ 0.005977910406874418,
0.002082707959908194,
0.00040531986878417016,
8.288625325409957e-05,
0.00012694310525644323,
2.2358165810500684e-05,
5.8206981840351024e-05,
2.4381655882940325e-05,
6.41042601685523e-05,
9.399124342739771e-06,
1.368851328198169e-05,
5.534408654978776e-06,
5.1817418195463024e-06,
4.480127813710875e-06,
4.675390646438434e-06],
'val_mean_absolute_error': [ 0.06221213564276695,
0.038206133991479874,
0.01635485701262951,
0.007225386798381805,
0.009348967112600803,
0.003478585509583354,
0.006274291314184666,
0.0042326138354837894,
0.007503245025873184,
0.002387133426964283,
0.0031227213330566883,
0.001781730679795146,
0.0016113659366965294,
0.001472451607696712,
0.0015395664377138019]},
'loss': 0.001472451607696712,
'model_name': 'model_0.0014724516_0f5da',
'space': { 'dense_activation': 'elu',
'dilations': [1, 2, 4, 8, 16, 32, 64],
'dropout_rate': 0.05929842084138553,
'kernel_initializer': 'he_normal',
'kernel_size': 4,
'learning_rate': 0.0014054657681539478,
'name': 'tcn',
'nb_filters': 16,
'nb_stacks': 2,
'optimizer': 'Adam',
'padding': 'causal',
'return_sequences': False,
'tcn_activation': 'linear',
'use_batch_norm': True,
'use_skip_connections': False},
'status': 'ok'}
下記は今回のチューニングでベストなハイパーパラメータとなっています。Manual Search(ベースライン)で選択されたハイパーパラメータと比較するとActivation関数やOptimizer、Dilationsパラメータ値が全然違いますね。HyperOptが良い選択肢をやってくれました。
{ 'dense_activation': 'elu',
'dilations': [1, 2, 4, 8, 16, 32, 64],
'dropout_rate': 0.05929842084138553,
'kernel_initializer': 'he_normal',
'kernel_size': 4,
'learning_rate': 0.0014054657681539478,
'name': 'tcn',
'nb_filters': 16,
'nb_stacks': 2,
'optimizer': 'Adam',
'padding': 'causal',
'return_sequences': False,
'tcn_activation': 'linear',
'use_batch_norm': True,
'use_skip_connections': False}
テストセット評価でベスト欠損値とベストMAEもベースラインよりかなりよくなりました。良い感じですね。このハイパーパラメータで実際のモデルに適用してForex予測をしたいと思いますが、今回の記事は長いので次回に予測結果を紹介しようと思います。
'best_evaluate_loss': 4.480127813710875e-06, 'best_evaluate_mae': 0.001472451607696712
ハイパーパラメータのチューニングプロセスの確認
連続データ型のハイパーパラメータの散布図(Scatter plot)を確認しましょう。HyperOptが各ハイパーパラメータの値を設定した分布で試していました。各ハイパーパラメータペアの関係及びどの辺でTCNの最適値もある程度確認できますね。 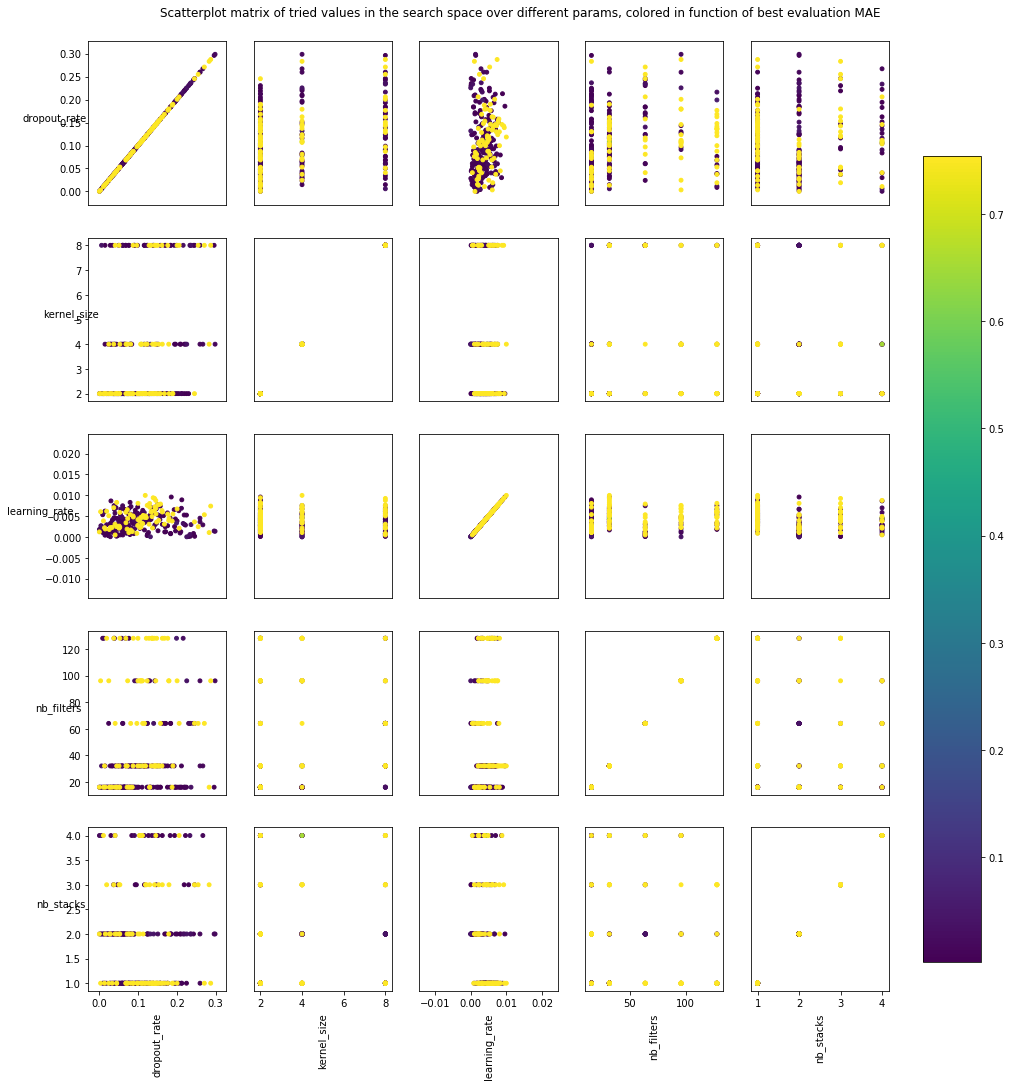 下記は探索過程で記録されてベスト欠損値です。ゼロの近いエリアに他の値(1.75や0.75)より集中して分布されましたね。これもHyperOptの特徴です。
下記は探索過程で記録されてベスト欠損値です。ゼロの近いエリアに他の値(1.75や0.75)より集中して分布されましたね。これもHyperOptの特徴です。 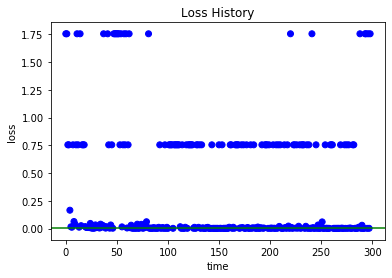 探索過程で記録した欠損値は最適化エリア周りに何回くらい試したか下記のHistogramで確認できますね。半分以上になっています。
探索過程で記録した欠損値は最適化エリア周りに何回くらい試したか下記のHistogramで確認できますね。半分以上になっています。 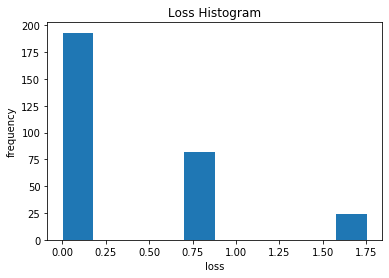
所感
いかがでしょうか?今回はHyperOptでFX予測するTCNモデルのハイパーパラメータをチューニングしてみました。深層機械学習モデルなので,結構ハイスペックなGPUマシンで行っても実行時間が少し長かったですが,最後の結果はもちろん,数十回探索した時点で自分の経験で設定したハイパーパラメータ(ベースライン)を上回ったので,良さそうですね。ではまた!
最後に
次世代システム研究室では、ビッグデータ解析プラットホームの設計・開発を行うアーキテクトとデータサイエンティストを募集しています。次世代システム研究室にご興味を持って頂ける方がいらっしゃいましたら、ぜひ 募集職種一覧 からご応募をお願いします。
皆さんのご応募をお待ちしています。
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD