2021.07.16
ポストクッキー時代における自然言語処理技術の応用(キーワード・エンティティ表現集)
こんにちは。次世代システム研究室のA.Z.です。
インターネット広告業界は現在、新たな時代に向かっています。
今まで、クッキーというブラウザ機能を利用し、個人の関心や興味をもとに、関連性が高い広告を配信しています。
しかし、最近個人のプライバシーを守るとの理由で、クッキーという機能の利用できる場面が制限されています。
クッキーが制限されることで、今までのインターネットの広告のやりかたががらっと変わって、これからはポストクッキー時代とよく言われています。
今回、ポストクッキー時代の一つ対策としてコンテクストマッチングに自然言語の活用について紹介します。
具体的に、CTRを予測するために、メディア記事のメタデータ(主にキーワードやエンティティ)の表現のアプローチについて、話したいと思います。
背景
2020年に、Google Chromeは2022年にサードパーティクッキーのサーポートが終了する計画を発表しました(現在、2023年までの延期)。
それ以前、EUのGDPRや米国カリフォルニア州のCCPAなどの法規制、SafariやFirefoxがサードパーティクッキーをブロックしたということはあったが、このGoogleの発表がポストCookie時代の本格的になります。
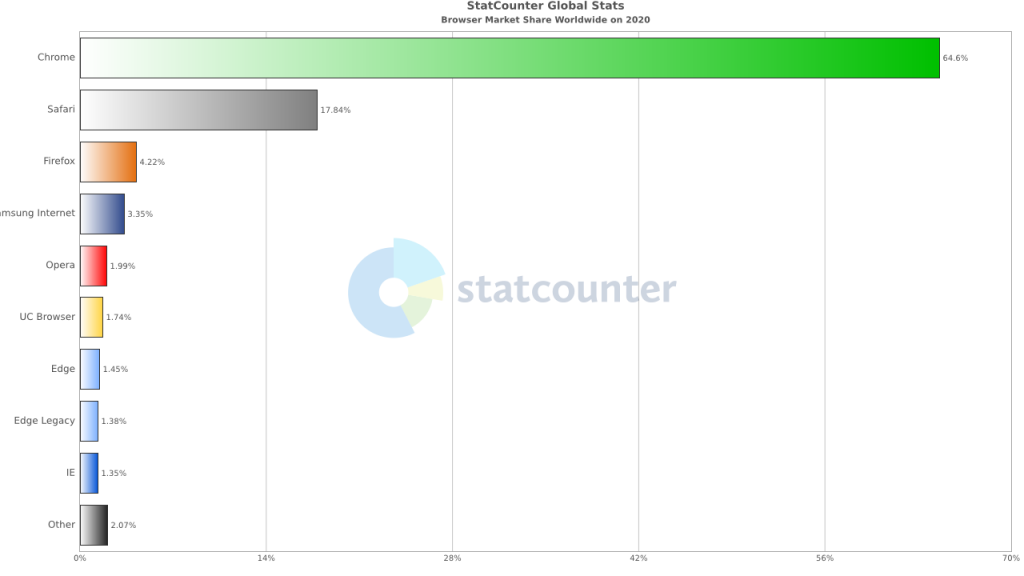
以下の昨年のブラウザのマーケットシェアのデータをみると、Chrome, Firefox, Safariがサードパーティクッキー利用できなかったら、ほぼすべてのインターネットが、サードパーティクッキーは利用できない状態になります。 今回はポストクッキー時代は、サードパーティクッキー完全に利用できなくなる状況を表します。
サードパーティクッキーがなくなると、インターネット広告がなぜ困っているか。理由は今までインターネット広告配信プラットフォーム(DSP、SSP)がサードパーティクッキーを利用し、複数メディアのユーザー行動履歴を利用し、効果が高い広告を配信しています。ユーザー行動履歴取れなくなると、効果測定や広告・ユーザーのマッチングや特定ユーザーの興味などの情報が取れなくなり、効果が高い広告の配信が難しくなります。こちらの困難を乗り越えるために、様々な動きがあります。具体的に次に紹介したいと思います。
ポストクッキー時代の様々な動き
クッキーの利用制限により、今後の動きはだいたい2つの大きな方法に分かれてる。
クッキーの変わりに、別のIDの仕組みを利用し、ユーザーをトラッキングする
こちらはクッキー以外、様々なuser情報や1st partyの情報を組み合わせて、クロスサイト用のidを発行する技術を利用し、トラッキングを行います。
例えば、アクセス時間+IPアドレス+ブラウザのUA+サイト情報から、特定のアルゴリズムで、同一人物かどうか判断し、uniqueなIDを発行します。
いくつか事例上げると、Google ChromeはFLOCS(Federated Learning on Cohorts)という仕組みを検討し、個人特定に使用できないクロスサイト用のidを用意します。
しかし、こちらのアプローチもまた様々な声があり、結局実施時期が延期されました。
他にはクロスサイト用id(universal id)を提供するサービス、Intimate Merger社の IM Universal Identifier (IM UID)です。
IM UIDは様々なデータソースから組み合わせて、独自アルゴリズムで、高い精度のuniversal idが実現できます。
欧州では、ログインアライアンス(Login Alliance)というサービスがあり、複数サイトで、同じログインでログインでき、結果的に、複数サイトの間(cross site)の行動履歴がとれます。
しかし、こちらのアプローチでは、今後また利用できなくなる可能性があると思います。
理由としてはやはりプライバシーを保護するために、クッキーだけではなく、様々な取得できる情報が減っていると予想されます。
直近ではIOS 15のSafari機能で、ウェッブサイトをアクセスするときに、自動的に別のサーバからルーティングされ、ユーザーのIPアドレスが取れなくなります。
また、Google ChromeがUserAgent文字列から、ブラウザのバージョンなどの情報が正確に取得することが出来なくなり、代わりにUser-Agent Client Hintsという機能を今実験中です。
これらで、どんどんユーザーから取得情報が減って、unique idの発行精度が今後落ちる可能性があると思います。
また、今回みたいな3rd party cookieの問題また繰り返されると思います。
トラッキングが不要なコンテクストベースターゲティング
コンテキストターゲティングとは現在ユーザーが見ているページのコンテキストをもとに適切な広告を表示する。
例えば、ユーザーがスポーツ関連の記事を見たときに、そのページにスポーツの靴の広告を表示する
ユーザーの現在の興味や関心をフォーカスすることで、過去のユーザー行動などの情報が不要になり、その結果、3rd partyクッキーがなくてもできる。
コンテクストを特定するために、自然言語処理の技術は不可欠になります。具体的な内容について、次のパーツで紹介したいと思います。
ポストクッキー時代で、自然言語の応用について
記事コンテンツのアプローチ
こちらのアプローチでは、できるだけメディア記事のコンテンツを詳細に分析し、正確なコンテキスト、トピック、感情などを判定します。
現在自然言語の最先端技術はこちらのアプローチでほぼ応用できると思います(正確なテキストデータがあれば)。
私が参加しているプロジェクトにもこちらのアプローチを利用していますが、いくつか問題点があります。具体的には
- Webページから正確なコンテンツだけ抽出するのはかなり大変
様々なwebページはデザインがちがって、人間もどれがメインコンテンツかどれかが広告などの区別するのは困難なときもあり、機械を自動かするのはもっと大変。抽出したデータが不要なものもたくさん含まれていおり、良い精度を得るために、データのクリーニングのコストがかかります。 - データの保存するコスト
当たり前ですが、たくさんテキスト情報を保存するためにはストレージコストがかかります。
こちらのアプローチでは最先端の技術(BERT,GPTなど)を利用できるのは面白いですが、ビジネス面からすると、かなりコストがかかります。
Webページのメタデータのアプローチ
こちらのアプローチは基本的に人間が直接入れた情報かつ簡単に取得できるテキスト情報を利用します。
一般的なサイトからは簡単に取得できるのはtitleとkeywordになります。
今回の一番シンプルで、keywordにフォーカスしたいと思います。keywordはほとんどのウェッブサイトで、必ず設定されており、データとしてはそんなに大きくなく、ほとんどの記事の内容の重要な部分が推定できます。しかし、keywordを利用するにはいくつか
- 単語の曖昧な意味の可能性
keywordはただの単語の並びで、コンテキストはほとんどがないので、例えばAppleという単語があった場合は、会社を表すか果物を表すかの曖昧さ発生します。 - 単語と単語の間のの関連性が不明
文章のように単語の並び順番は特に決まっていないので、関連性が作るのは難しいです。
(1)の問題で、直接単語を利用するではなく、ある程度Name Entity Recognition(NER)で処理で、Entityに変換すれば、解決できるではないかと思います。
(2)の問題について、次回で話したいと思います。
実験
いよいよ本題に入ります。
今回実験の目的:
- ctr予測にはいくつかのkeyword/entityの表現方法を検証するため
今回はEmbedding layerとAuto Encoderを検証しています。
期待している結果はCTRが似たような値を近くに集まるとうにすることです。
Datasetについて
今回利用しているデータセット:
https://www.kaggle.com/c/outbrain-click-prediction/data
ちょどdocumentとentityの情報があるデータがあり、今回はそれなりに、検証しやすいです。
データセット内のテーブルの概要は以下になります。
- page views
全体のページのアクセス履歴 - events
clickが発生したアクセス履歴 - promoted content
広告関連の情報 - clicks
clickの情報 - documents_*
documents関連の情報
実験条件
今回、ローカルPCで実験を行うため、ある程度データを絞って、いろんな条件をつけます。
- entityは10000回以上出るentity
- (1) のentityを含まれているドキュメント
- ad_id=175214が表示されるアクセスのみ
- ctrの計算は(3)のad_id対してのCTR
- 利用しているデータがentityのみ
entityの数は40165 entity
Neural Network Embedding Layer
今回利用しているモデルの構造は以下になります。
model = tf.keras.Sequential() model.add(tf.keras.layers.Embedding(PREPROC_ENT_NUM, 1024)) model.add(tf.keras.layers.GlobalAveragePooling1D()) model.add(tf.keras.layers.Dense(1, activation='relu'))
今回、目的変数としてはCTRを利用し、回帰の形で学習を行います。
embedding layerのinputにはentity idとして、入れていました
PREPROC_ENT_NUM=40165
Auto Encoder
今回利用したautoencoderのコードは以下になります。
class Autoencoder(tf.keras.Model):
def __init__(self, latent_dim, org_dim):
super(Autoencoder, self).__init__()
self.latent_dim = latent_dim
self.encoder = tf.keras.Sequential([
tf.keras.layers.InputLayer(input_shape=(org_dim,), sparse=True),
tf.keras.layers.Dense(latent_dim, activation='relu'),
])
self.decoder = tf.keras.Sequential([
tf.keras.layers.Dense(org_dim, activation='sigmoid'),
])
def call(self, x):
encoded = self.encoder(x)
decoded = self.decoder(encoded)
return decoded
latent_dim=1024
org_dim=40165
encoderの場合は、inputにはエンティティの信頼度の数字として、入れていました
結果
それぞれの方法のembeddingした結果は以下になります。
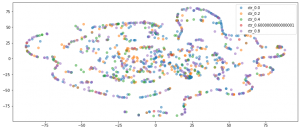
Embedding LayerのT-SNEの結果

AutoencoderのencodeしたT-SNEの結果
実質1024次元から2次元変更することもあり、上記のT-SNE結果からすると、結果から見ると、encoderのほうがある程度高にいたような記事(似たようなentityの構造)が集まって、そして、ctrの値もだいたい同じ値になります。一つの理由はautoencoderでは、entityの信頼度もinputとして利用できて、もっとドキュメント間の傾向がキャプチャしやすいと思います。
一方embedding layerの結果では、似たようなctrの記事が遠く離れて、バラバラな状態に見えています。もちろんembedding layerは最終のモデルで、別のfeatureと学習でき、もっと最適化する余地が沢山ありますが、最小限のfeatureに利用するのはauto encoderのほうが良いではないかと思います。
まとめ
- 今回、ポストクッキー時代に向けて、CTR予測にキーワードやエンティティの表現方法について検証しました
- 検証した結果、キーワードやエンティティの表現するにはautoencoder系のほうが良い結果を得られました。
- 今後、フィーチャーの表現より、CTR予測までの応用例について紹介する予定です。
次世代システム研究室では、ビッグデータ解析プラットホームの設計・開発を行うアーキテクトとデータサイエンティストを募集しています。次世代システム研究室にご興味を持って頂ける方がいらっしゃいましたら、ぜひ 募集職種一覧 からご応募をお願いします。
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD