2020.10.09
本番で、簡単に機械学習モデル運用ーTensorflow Servingの紹介
こんにちは、次世代システム研究室のA.Zです。
機械学習モデルを作成した後、どうすれば本番で、簡単に誰でも利用できるかお悩みある方もいると思います。モデルを利用したい時、何かしらプログラムを実行し、そのあと結果を確認する時が多いと思います。また、外部システムと連携するときに、接続するためのコミュニケーションやテストなども以外と工数がかかります。
今回は機械学習モデルのサービング(serving)フレームワーク、Tensorflow Servingについて、簡単に紹介したいと思います。
はじめに
Tensorflow(TF) Servingとは学習済の機械学習モデルサービングするためのフレームワークです。
TF ServingではREST APIとgRPCインターフェスが提供されているので、こちらのフレームワークを使えば、学習済モデルが簡単に他のシステムやだれでも利用できます。
名前がTensorflowになっていますが、もちろんtensorflow modelと相性が一番良いだが、他のモデルに対応できるように拡張することもできます。機械学習モデルにかぎらず、他のデータの前処理のロジックも同じフレームワークで対応できます。その結果、他の人システムを連携するときに、外部システムは処理がかなりシンプルになります。今までの経験した、機械学習モデルと外部システムの連携時、発生した問題が減らされると思います。
また、TF servingも以下の機能や特徴を持っているので、個人的に結構便利です。
- オンライン
- 必要な時、いつでも利用できます。
- 低遅延
- 複数モデル、複数バージョン対応
- モデル検証や効果測定などかなり便利
- モデルに問題があったら、すぐに切り戻せる
- containerベース設計なので、スケールしやすい
Tensorflow Serving概要
こちらで、簡単にTensorflow Serving概要を紹介したいと思います。
Tensorflow servingは以下のアーキテクチャで、構成されます。
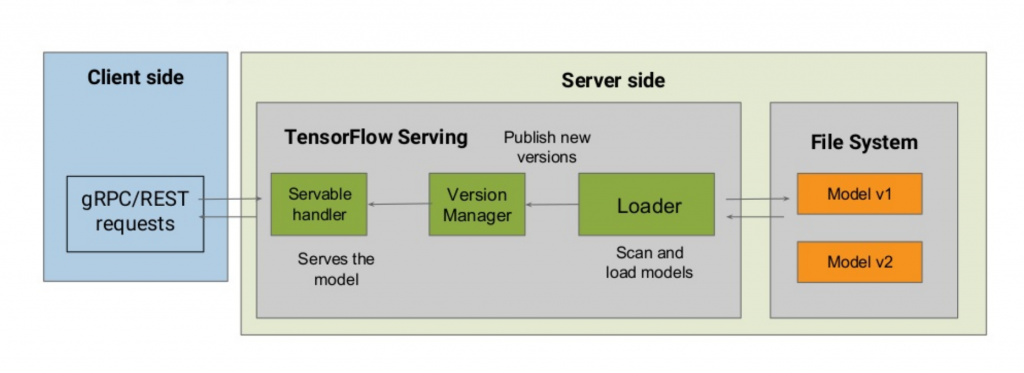
基本的に大事な部分は:
- Loader
- Loaderファイルシステムモデルをload/unloadという役割。
- Version Manager
- modelのバージョン管理の役割。
- Servable Handler
- こちらの部分にはモデルを利用し、実際の計算・予測を行う部分です
- Client Side
- こちら部分はクライアント用の専用インターフェースになります。2つインターフェス、REST APIとgRPCが用意されるので、使いやすさと外部システムの連携には良いと思います。
基本的に、Tensorflow serving使うときのパイプラインは以下のイメージです
モデル学習 -> モデルエクスポート -> TF Servingのサーバを起動 -> サーバーへリクエスト行う
Tensorflow Servingを動かしてみる
今回はdockerベースの方法を紹介したいと思います。
まず、Tensorflow servingのdocker imageを取得
docker pull tensorflow/serving
GPU版を使いたい場合は
docker pull tensorflow/serving:latest-gpu
イメージ無事に取得できたら、以下のコマンドで、サーバーを起動します。
docker run -t --rm -p 8501:8501 -p 8500:8500 \ -v "$SAVED_MODEL_PATH:/models/$MODEL_NAME" \ -e MODEL_NAME=$MODEL_NAME \ --name tf-serving tensorflow/serving
GPU版起動したい場合は:
docker run -t --rm -p 8501:8501 -p 8500:8500 \ -v "$SAVED_MODEL_PATH:/models/$MODEL_NAME" \ -e MODEL_NAME=$MODEL_NAME \ --gpus all --name tf-serving tensorflow/serving:latest-gpu
変数やパラメータの説明:
- SAVED_MODEL_PATH
- Tensorflow modelを保存したパス
- /models/$MODEL_NAME
- こちらはTF serving Loaderがデフォールトで、モデルを探す場所。基本的に、docker側はHOST file systemからこちらのパスにマッピングする
また、もし、何かエラーがあって、Debugしたいときに、以下のパラメータを上記のコマンドに追加すれば、サーバー側のログが出力されます。
-e TF_CPP_MIN_VLOG_LEVEL=1
※ もし、もっと細かいログがみたいなら、LEVELを上げるという形になります。
実際に予測行いたい時は以下のhttp POST requestで行います。
curl -d '{"instances": <FEATURES>}' \
-X POST http://localhost:8501/<MODEL_VERSION>/models/<MODEL_NAME>:predict
Tensorflow Servingの性能調査
個人的に1リクエストのモデルの予測はどれぐらいかかるか気になっています。
上記は様々なメリットや概要を紹介しましたが、実際に使いやすさも検証しました。
今回使った検証環境の情報は以下です。
- CPU : AMD Ryzen 2600x
- Memory : 32 GB
- OS : Arch Linux
- GPU : Nvidia GTX 1080 Ti
- Tensorflow 2.3
今回の検証内容は以下の視点から検証します。
- 大規模モデルと小規模モデル
- GPUとCPU
Resnet50モデルの検証
今回は学習済のResnet50 Modelを使って、検証しました。
検証プログラムは
https://github.com/tensorflow/serving/blob/master/tensorflow_serving/example/resnet_client.py
※ちょっとだけ、上記のプローグラムに、リクエスト必要な時間別の指標を追加しました
CPUの結果
avg req time: 52.0389 ms max req time : 58.445 ms min req time : 48.04 ms median req time : 51.6385 ms
GPUの結果
avg req time: 13.6731 ms max req time : 15.166 ms min req time : 12.181 ms median req time : 13.73 ms
Resnetモデルはそこそこ大きいので、CPUだと約58ms予測かかります。こちらのlatencyだけみると、画像認識タスクはそんなにrealtime性求めていないと思いますので、使っても問題なさそうなレベルだと思います。また、GPUを使うと、予測時間は15ms(約4倍)早くなります。十分使う価値があると思います。
簡易モデルの検証
小さいダミーモデルを検証として作成しました。作成したモデルは2重分類で、フィーチャの数300個
、2層のモデル([100,50])を作成しました。
具体的のモデル構造は以下になります。
Model: "sequential_5" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= dense_15 (Dense) (None, 100) 30100 _________________________________________________________________ dense_16 (Dense) (None, 50) 5050 _________________________________________________________________ dense_17 (Dense) (None, 1) 51 ================================================================= Total params: 35,201 Trainable params: 35,201 Non-trainable params: 0
基本的に、上記ので作成したモデルを以下の関数で、保存すれば、そのままtensorflow servingでロードできます。
model.save(<PATH>)
検証用のプログラムはResnetのプログラムをベースに、featureの部分だけを少しい変更しました。具体的なコード以下になります。
from __future__ import print_function
import requests
import numpy as np
# The server URL specifies the endpoint of your server running the ResNet
# model with the name "resnet" and using the predict interface.
SERVER_URL = 'http://localhost:8501/v1/models/test-model:predict'
def main():
# Compose a JSON Predict request
req_feature=np.random.rand(1,300).reshape(1,-1).tolist()[0]
predict_request = '{"instances" : [%s]}' % (req_feature)
# Send few requests to warm-up the model.
for _ in range(3):
response = requests.post(SERVER_URL, data=predict_request)
response.raise_for_status()
# Send few actual requests and report average latency.
total_time = 0
num_requests = 1000
all_req_time=[]
for _ in range(num_requests):
response = requests.post(SERVER_URL, data=predict_request)
response.raise_for_status()
req_time=response.elapsed.total_seconds()
total_time +=req_time
all_req_time+=[req_time]
prediction = response.json()['predictions'][0]
print(prediction)
print('avg latency:', np.mean(all_req_time*1000))
print('max req time :',np.max(all_req_time*1000))
print('min req time :',np.min(all_req_time*1000))
print('median req time :',np.median(all_req_time*1000))
if __name__ == '__main__':
main()
CPU実行結果
avg latency: 0.0007489 ms max req time : 0.000852 ms min req time : 0.000678 ms median req time : 0.0007455 ms
GPU実行結果
avg latency: 0.00107 ms max req time : 0.001242 ms min req time : 0.000986 ms median req time : 0.0010575 ms
小規模モデルで、CPUだと約0.8μs予測かかります。逆にGPUを使うと、予測時間は1.5倍上がります。
モデルが小さいだと、やはりCPUのほうが早いです。今回はあくまで小さいダミーモデルで使っているので、realtime性の重要なケースにはモデル規模と様々なKPI一致すれば、導入する価値があると思います
まとめ
今回、Tensorflow Servingについて、簡単に紹介いたしました。ほかのモデル予測専用のフレームワーク、NVIDIA TritonやIntel OpenVinoに比べて、専用ハードウェアが不要なので、導入しやすいと思います。
本フレームワークでは様々なパラメータや拡張機能がまだあるので、今後、より深く紹介したいと思います。
次世代システム研究室では、アプリケーション開発や設計を行うアーキテクトを募集しています。アプリケーション開発者の方、次世代システム研究室にご興味を持って頂ける方がいらっしゃいましたら、ぜひ 募集職種一覧 からご応募をお願いします。
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD