表形式Diffusion Model(TabDDPM)で、生成したデータの品質の検証について
こんにちは。次世代システム研究室のA.Z.です。
前回のブログでは簡単に表形式データに特化したDiffusionモデル(TabDDPM)を簡単に紹介いたしました。
今回のブログはTabDDPMでの生成したデータ関して、いくつかの指標で検証結果の紹介になります。
背景
TabDDPMは表形式データに特化したdiffusionモデルとして紹介されています。特徴としては、表形式の中にある、数字の特徴量とカテゴリの特徴量を分けて、diffusionプロセスを行っています。そこのプロセスの中に、カテゴリと、数字の特徴量が別々diffusionプロセスやdiffusion手法を行うため、TabDDPMが生成したデータの品質について、どのようになっているか気になっています。特に特徴量間の関連性がちゃんと維持できるか、違う種類の特徴量の関連性が失っていないか興味があります。元の論文ではある程度上記のような評価が記載されますが、やはり定量的な数字やどのような形で維持できるか記載されないので、今回はこちらに関しては実際に検証・調査します。次は検証内容と結果について、紹介になります。
検証 1: TabDDPMで生成したデータと元のデータの比較
もとの論文では、生成したデータの品質に対して、様々な指標の結果が記載されいましたが、検証対象データに対して、全てのデータの結果が記載されておらず、良い結果のところだけを記載したという印象がありました。今回は一般的に利用されている、分類問題データセットを中心に、cardioとadultのデータセットについて、調査します。
cardio dataset
cardio datasetは心臓の病気があるかないかの予測するためデータセットになります。詳細のデータセット情報は以下のページに参照https://www.kaggle.com/datasets/sulianova/cardiovascular-disease-dataset
このデータセットのトレーニングの情報は論文と同じく、以下の設定を行いました。
- 行の数 : 44800件
- 数字の特徴量の数: 5
- カテゴリの特徴量の数: 6
一部の特徴量の変化の状況について、以下図になります。
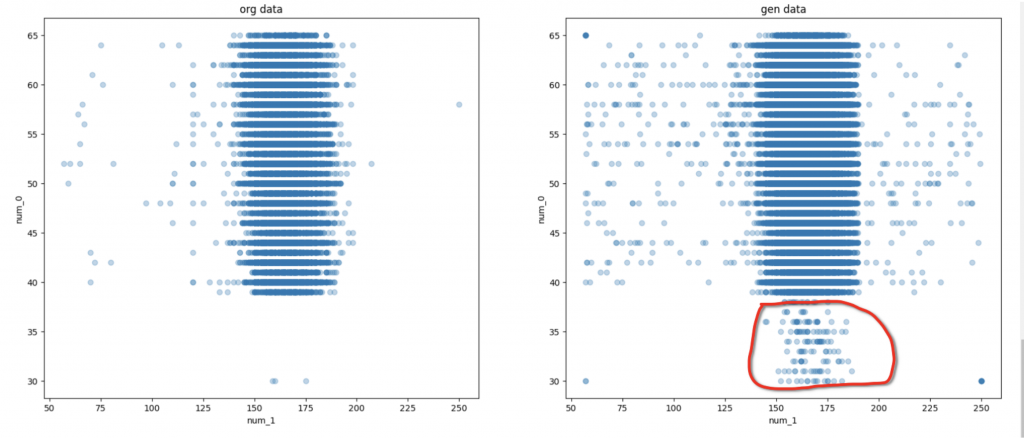
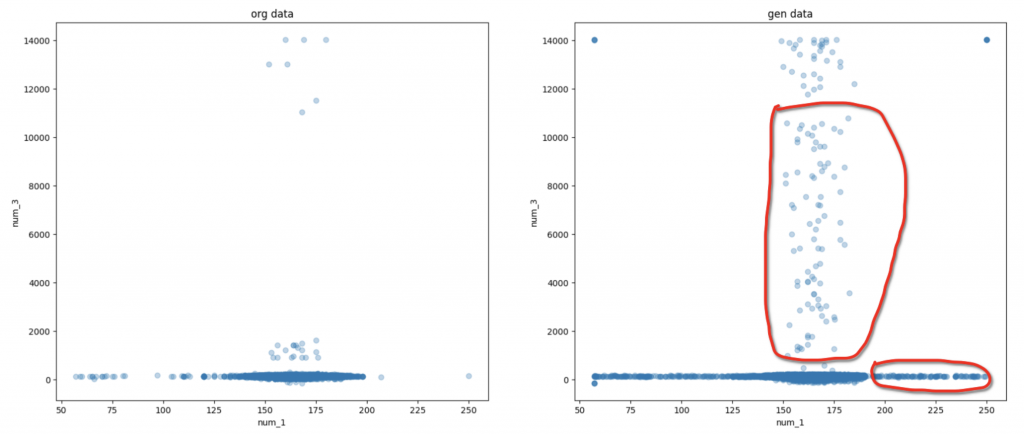
上記の2つ図では、数字特徴量と数字特徴量の変化の例になります。赤い枠のところで、生成モデルでしかないデータと思われ、元のデータにない関連性や特徴です。それ以外の部分はほとんど元のデータと同じ傾向になっています。
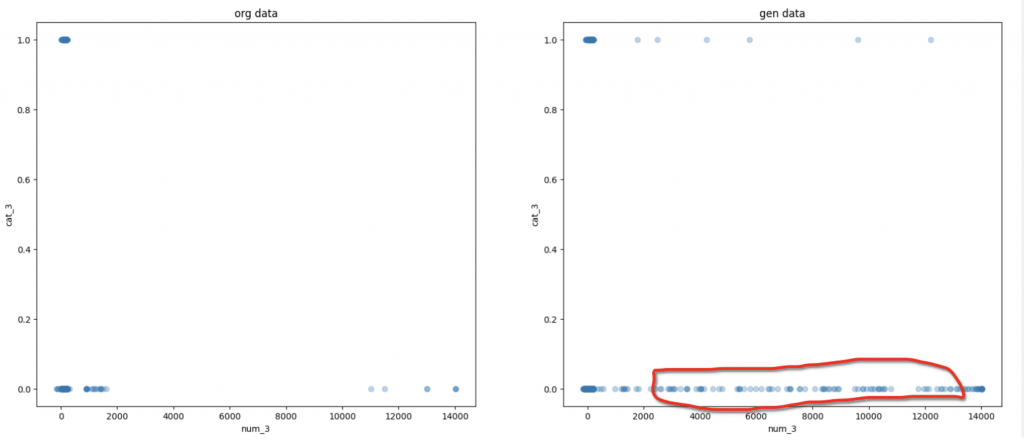
上記の1つの図では数字特徴量とカテゴリ特徴量の変化の例になります。
こちらのデータセットに関しては、生成したデータに関しましては、元のデータと異なるところが発生します。特にこのようなはセンシティブのデータに関して、生成したデータは実世界にありえないデータで生成されたら、利用するリスクが結構高いので、データ生成後、何ら化のバリデーションやチェックが必要にだと思います。異常な部分を除くと、全体的に生成データをみると、傾向はほぼ元データと似ていると思いますので、性能てきには良いかと思います。
adult dataset
adult datasetは心臓の病気があるかないかの予測するためデータセットになります。詳細のデータセット情報は以下のページに参照https://archive.ics.uci.edu/ml/datasets/adult
このデータセットのトレーニングの情報は論文と同じく、以下の設定を行いました。
- 行の数 : 26048件
- 数字の特徴量の数: 6
- カテゴリの特徴量の数: 8
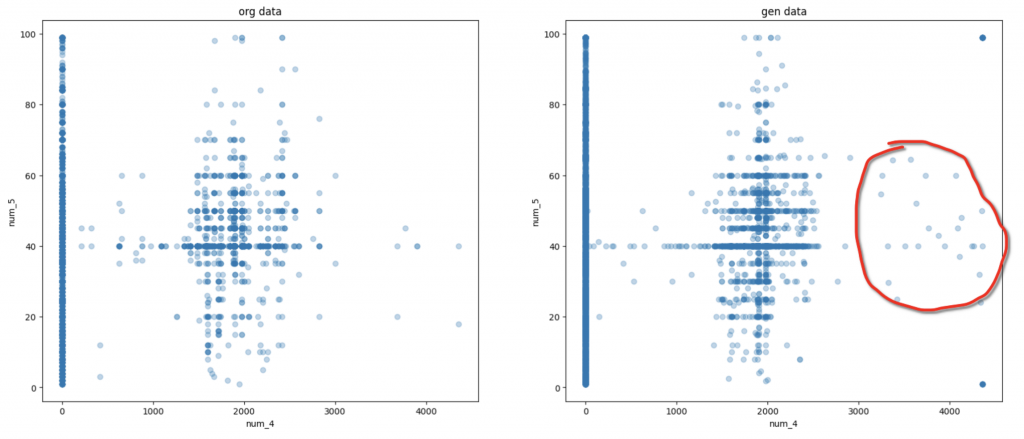
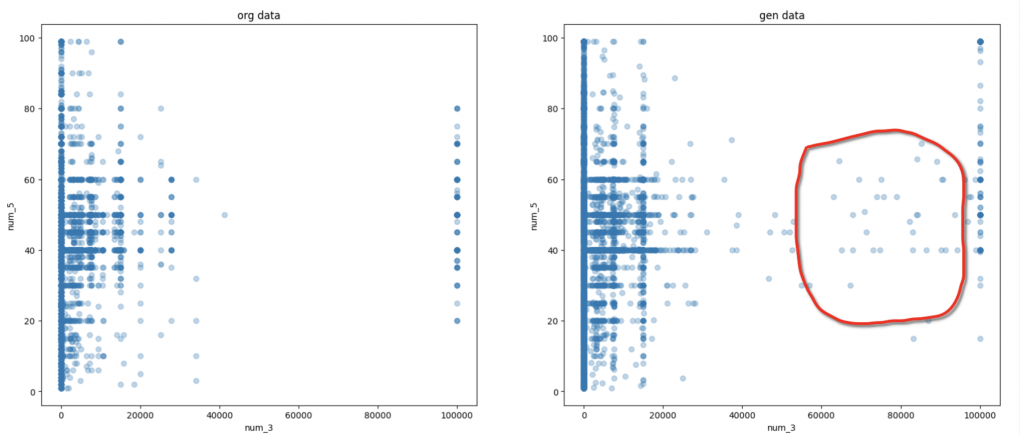
上記の2つ図では、数字特徴量と数字特徴量の変化の例になります。赤い枠のところで、生成モデルでしかないデータと思われ、元のデータにない関連性や特徴です。それ以外の部分はほとんど元のデータと同じ傾向になっています。
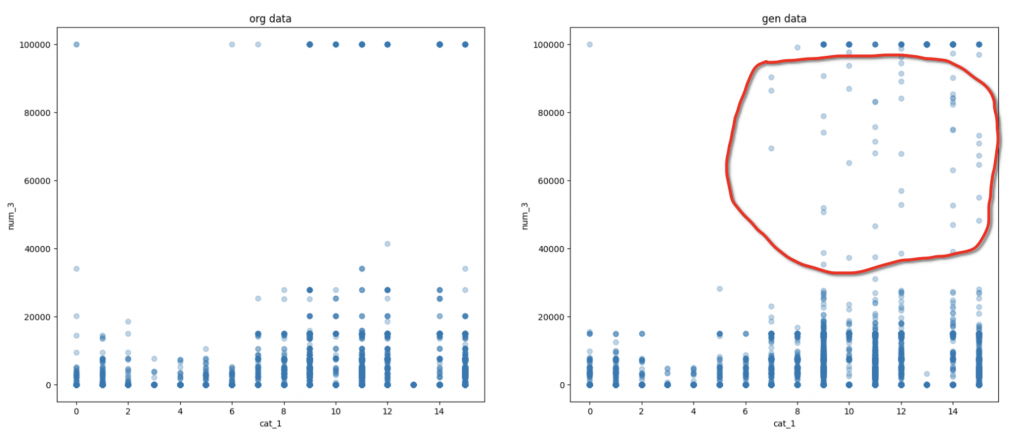
上記の1つの図では数字特徴量とカテゴリ特徴量の変化の例になります。
こちらのデータセットも、異なるところを除くと、生成したデータと元のデータの傾向が似ているので、全体的にTabDDPMの性能は良いとは言えると思います。
検証 2: TabDDPMで生成したデータは特徴量間の関連性が保てるか
もとの論文にも、こちらのところがありますが、検証対象のデータセットでは、定量的な数字や全データセットの評価がなかったので、今回は改めて、定量的な評価を行ってみる。論文の中では特徴量の相関の数字は以下の値を行います。
- (1) 数字と数字の特徴量の関連性はpearson-correlationの数字で表す
- (2) 数字とカテゴリの特徴量はcorrelation Ratioという指標で表す
- (3) カテゴリとカテゴリの相関は Theil U Statisticの指標を表す
correlation ratioについて
correlation ratioは数字とカテゴリの特徴量の間の関連性(相関)を表す指標として、よく使われています。correlation ratioη(eta) とは、カテ/ゴリの中に、発生した観測値を利用し、カテゴリと観測値の相関・関連性を計算しています。具体的な計算式は以下になります。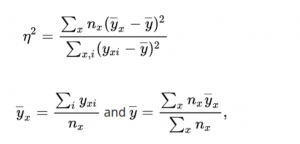
- x: カテゴリ
- n_x: カテゴリ内の観測したデータの数
- y_xi: カテゴリxの観測iの値
- y^bar_x: カテゴリ内の観測値の平均値
Thiel’s U Statisticについて
Thiels’s Uというのはある2つの離散的なランダム変数を間に、関連性を表す指標の一つです。具体的に、以下の数式で計算されます。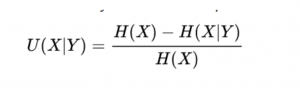
H(X)は変数のentropyになって、具体的な計算は以下です。
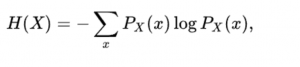
H(X|Y)はY変数に対するのXのentropy(conditional entropy)
対象データセットの特徴量の相関関係を調べてみる。
以下の対象のデータセットを上記の指標作成し、元データ相関と生成データの相関を調べます。cardio dataset
元のデータの相関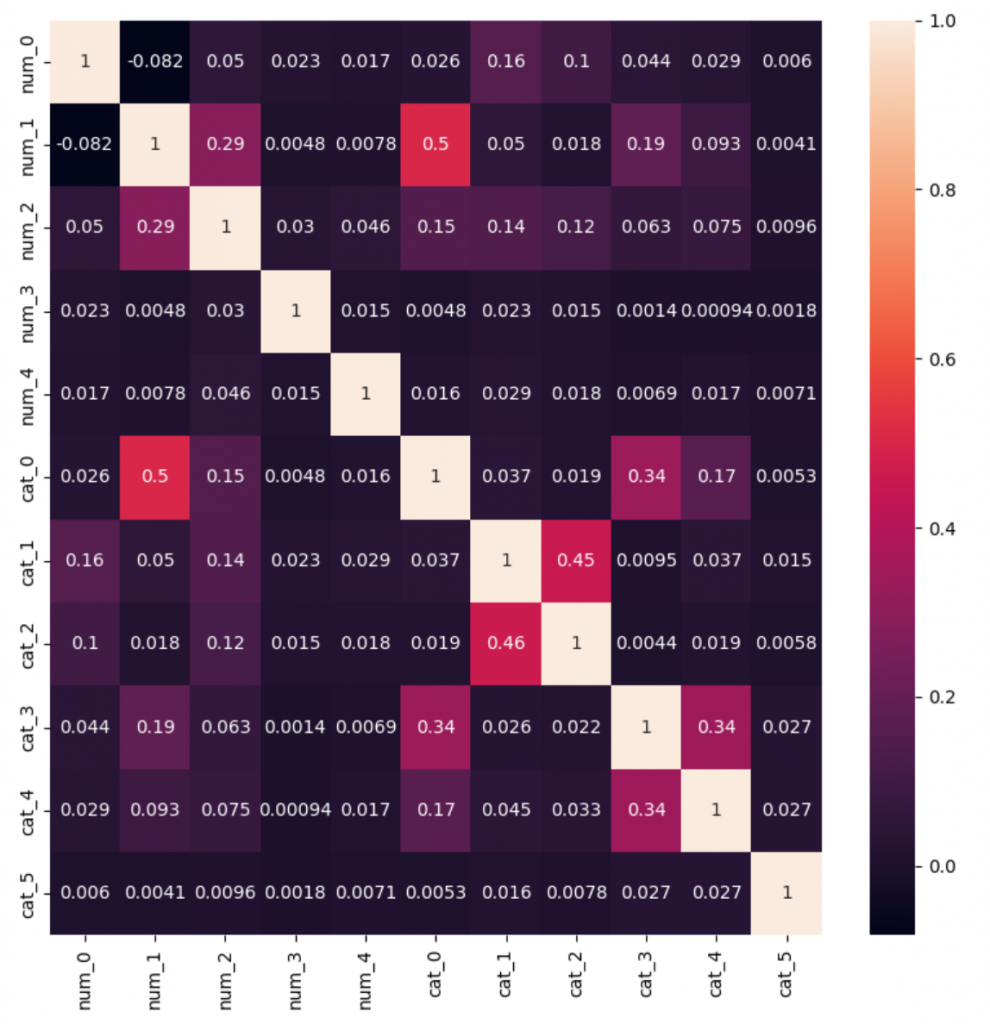
生成データ相関
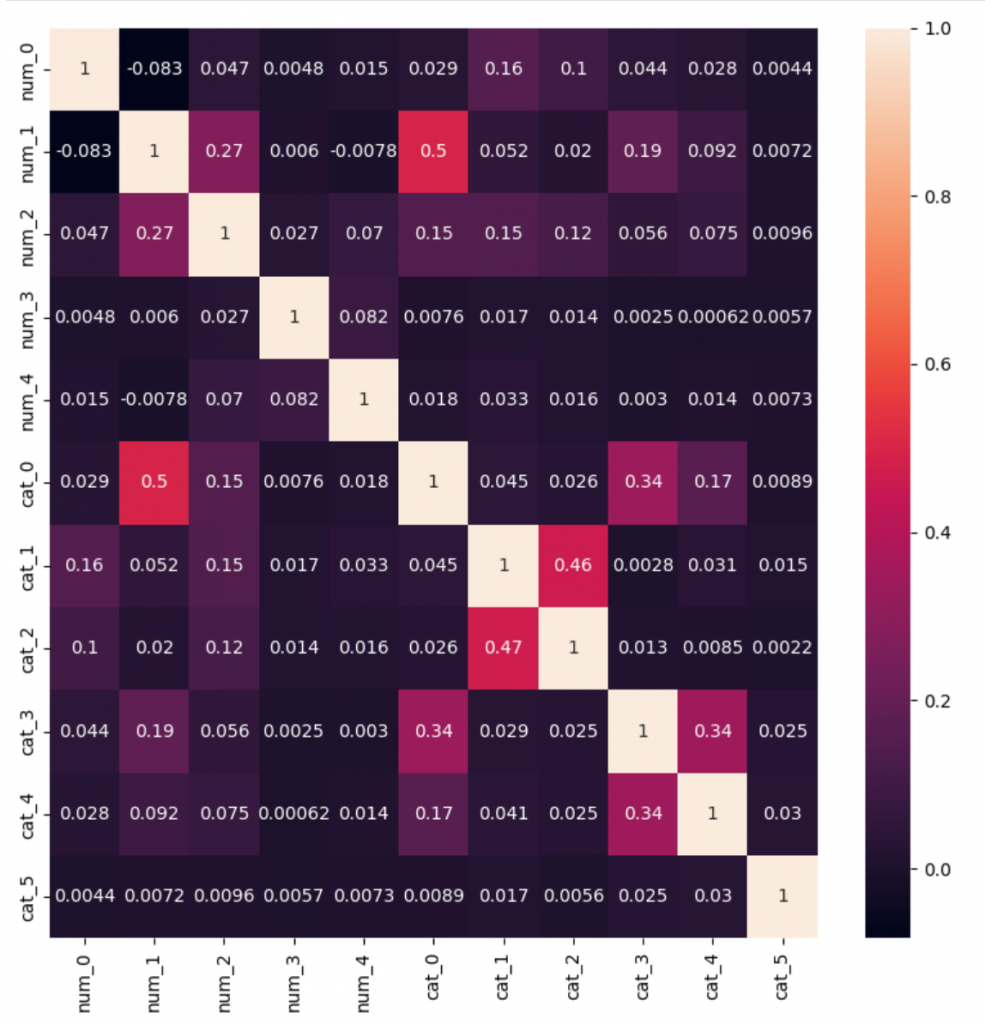
上記の図を見ると、元のデータと生成したデータの関連性(相関)が維持できることがわかりました。
adult dataset
元のデータの相関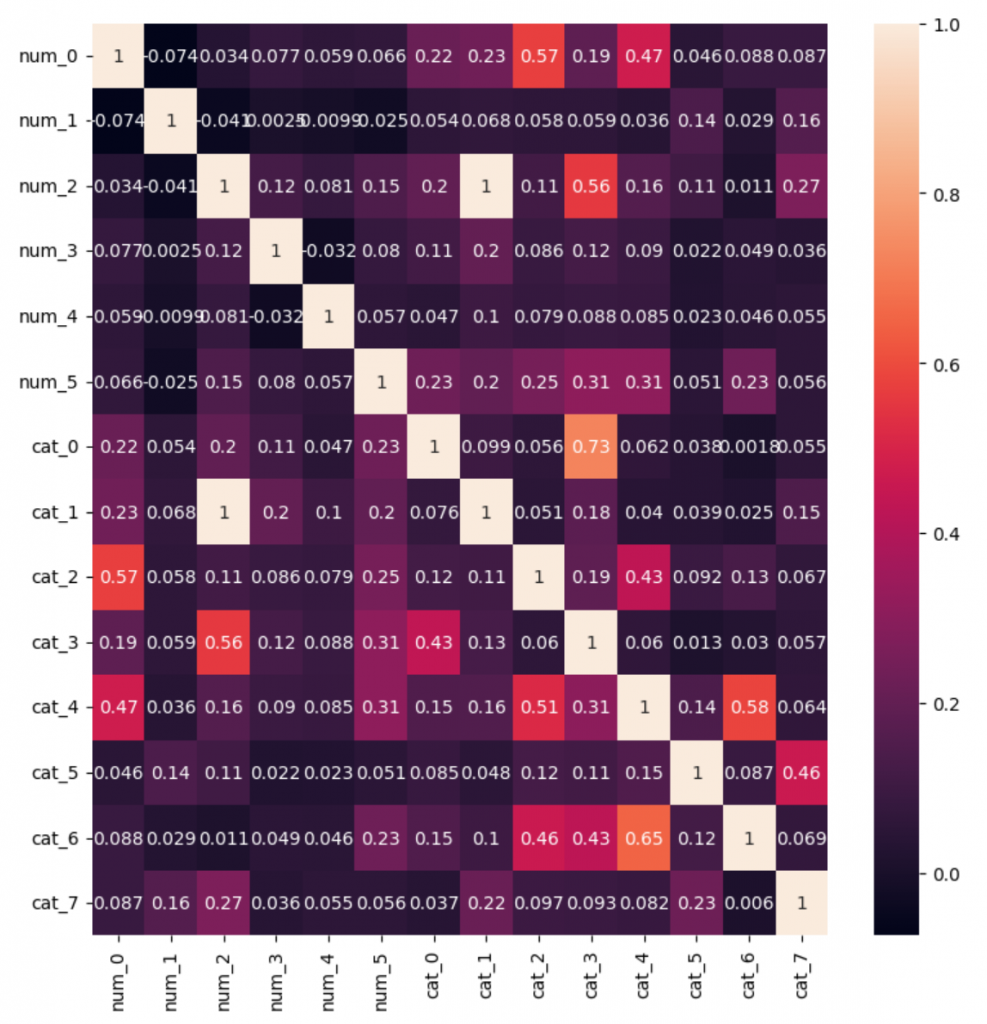
生成データ相関
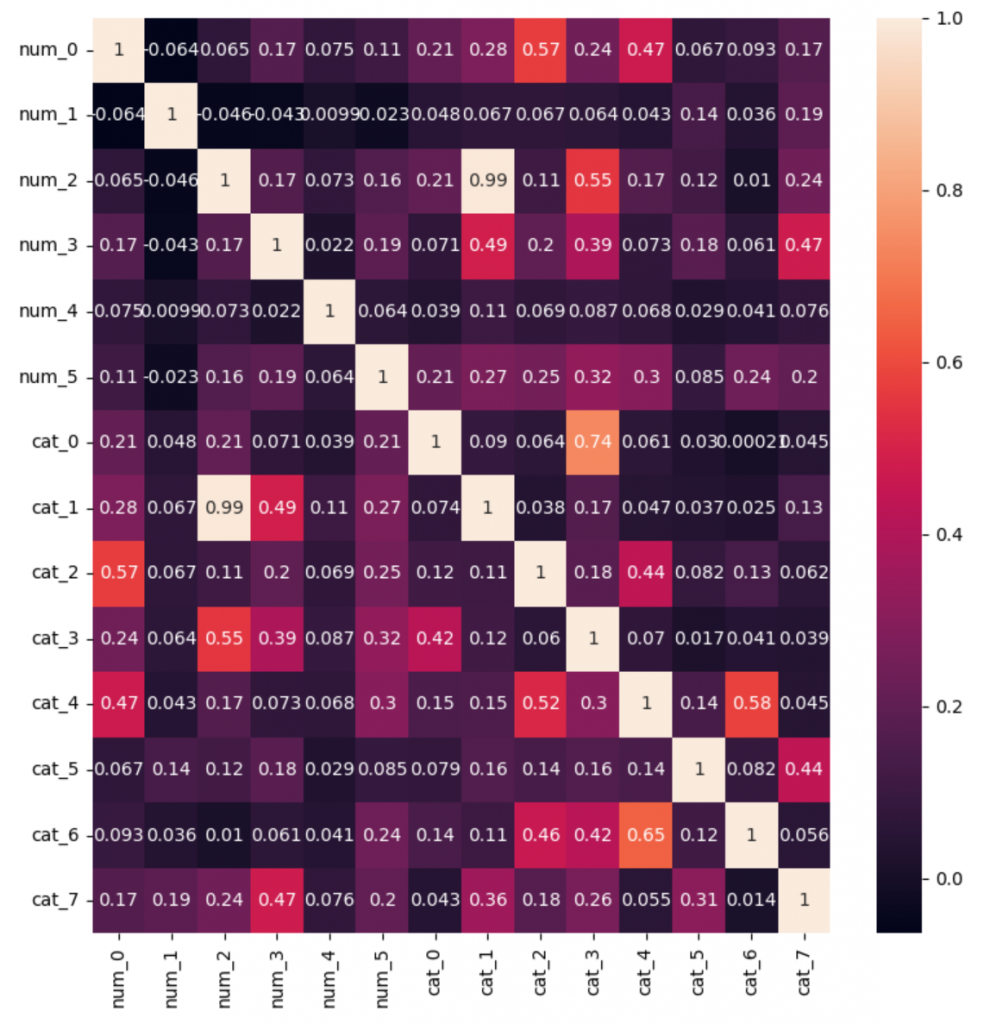
上記の見ると、いくつかの特徴量の相関が変わることがわかりました。
例えば
num_3 とcat_7 の部分の相関の値が結構変わりました。ここから、TabDDPMの生成データで、もとのデータの特徴量の関連性が失うことがあるとわかりました。まとめ
- TabDDPMのデータ生成の品質について、調査しました。元データと異なる部分を除くと、元データの性質を担保できていると思います。
- 元データと異なるデータの生成に関しては、想定通り、ある程度生成されていますが現在の確認したでーたせっとの中に少ないと思います。データセットやユースケースによって、問題になる可能性があります、生成からすぐに使うではなく、ある程度validationやチェックのプロセスを取り入れたほうた良いと思います。
グループ研究開発本部 AI研究開発室では、データサイエンティスト/機械学習エンジニアを募集しています。ビッグデータの解析業務などAI研究開発室にご興味を持って頂ける方がいらっしゃいましたら、ぜひ 募集職種一覧からご応募をお願いします。皆さんのご応募をお待ちしています。