2023.07.10
LLM 対応自然言語処理フレームワークをいろいろ触ってテーブルデータで試してみたかった
ご覧頂きありがとうございます。グループ研究開発本部 AI 研究開発室の N.M.と申します。
2022 年末に公開された ChatGPT を皮切りに、2023 年に入って大規模言語モデル(LLM)に対する世の中の関心が集まっているのはこのブログを見ておられる方であれば体感しておられるかと思います。弊社も例外ではなく、AI しあおうぜという AI 技術の活用がテーマの社内コンペをはじめとした取り組みが盛んになっています。
もちろん ChatGPT や Bard といった既にサービス化されているものをどう使うかも重要ですが、提供されいているモデルをどう自社サービス・アプリに組み込んでいくかと考えたいところ。そして当然ながらそう考える先駆者も多く、そういったことを目的としたいくつかの OSS が存在しています。
このブログでは、LangChain, LlamaIndex, そして Haystack の 3 種類の LLM 関連 OSS に対し、それぞれの特徴や実装例を紹介できればと思います。結果的にそこまで面白いものにもなりませんでしたが、最後までご覧いただければ幸いです。
TL;DR
- LangChain は LLM を幅広くアプリケーションへ実装できるようにするためのフレームワーク。ReActを実現する Agent の機能がキー。javascript/typescript による API も提供しているので Web アプリとの相性も良い。
- LlamaIndex は独自のドキュメントを LLM に知識と与えて拡張するためにプロンプトに対して与えるインデックスを作ることに中心としたフレームワーク。Llama Hubという様々なカスタムローダーを提供するサービスもありインデックス作成にただならぬ熱意を感じる。
- Haystack は LLM などによる自然言語処理を検索システムを構築するためのフレームワーク。LangChain と比べて検索システムに振り切っているだけあってフレームワークのコンセプトは堅牢。
- 色々やってみましたが、結局は LangChain が一番使いやすいかったです()
ライブラリの特徴比較
昨今の LLM をはじめとした AI ブームに対して、特に自然言語処理分野でアプリケーションに対してどのように実装に組み込んでいくかを考えている人は多く、2023 年初頭はフレームワークの乱立が危惧されました。その中でも周囲でよく話題に上がる LangChain, Llamaindex に加えて、Haystack というフレームワークがあり、これらの 3 つのフレームワークの特徴を比較していきます。
LangChain
LangChain は LLM を幅広くアプリケーションへ実装できるようにするためのフレームワークです。Python の他 JavaScript/TypeScript で実装されているなど、幅広いアプリケーションに対して LLM のリソースを利用できる仕組みを提供する思想です。実際グループ研究開発本部内でもこのライブラリの話を聞くことは多く、かなり主要なライブラリになっている印象です。
LangChain のサポートする主な処理として以下の 6 つが挙げられています。
- LLMs and Prompts: OpenAI などの LLM リソースに対して投げるプロンプトの最適化やインターフェース・ユーティリティーなどの機能。LLM ライブラリ開発のメインストリームが開発の中、JS/TS でも整備されているのは今の所 LangChain が筆頭だと思います。アプリケーション開発との相性がよさそう。
- Chains: LLMに投げるまでのいくつかの工程をまとめたものです。例えば、ユーザーの入力を受け取った後Promptに入力する形にフォーマットしてLLMに投げるといった一連の動作をまとめたものをChainと言います。
- Data Augmented Generation: document に接続して分割したり、それを埋め込み表現に変換したりする機能。インターネット上では Llama index と併用して使われることも多い様子。
- Agents: Reasoning and Acting(ReAct)を実現する機能。LLM がどのような Action をとるかを決定して、それを元に Action を実行して、その結果を見て…ということを繰り返すような挙動を実装できます。これが持ち味といっても過言ではない印象。
- Memory: 過去の推論結果を保持・管理しておく機能。ChatGPT を最初に使うと当然のように感じる部分もありますが、自分のアプリケーションに組み込む場合は一回一回の推論は基本的に独立しています。チャットアプリケーションを作るなどの場合は必須となる部分で、それを実装するための機能になります。
- Evaluation: 生成モデルのための評価を実装する機能。LLM の評価は LLM にさせるという思想のもとその関連機能をまとめている様子。記事執筆時点ではベータ版だそうです。
中でも Agent はかなり特徴的な機能になっています。Agent はクエリを受けて次にどのようなアクションを取るべきかを LLM が生成(Thought)し、それを元に適切な関数(Python を使うか、Web で検索するか、etc…)を選択してその関数の実行(Action)を生成した入力(Action Input)をもとに行います。そして得られた応答(Observation)をもとに次にどのようなアクションを取るべきかを再度生成し…というループでクエリを解決しようとする挙動を言います。これの強力な点としては ChatGPT といった LLM チャットが苦手としていた学習に含まれない期間のインターネット上の情報、決定論的な計算などを LLM に任せずに解決することによってより正確な応答を生成する可能性が高まるというところです。もちろん Action を決めるのは LLM なので本来意図していない Action をとる可能性はあるので完全な決定論ではないことには注意しなければいけません。
他にも ChatGPT ではあまり意識せずに使えているものの、チャットボットを API を利用して開発する際には工夫が必要とされる Context を考慮するステートフルな処理の実装や LLM の精度評価など凄まじいスピードで機能が開発されています。今後より stable な状態が保たれさえすれば、デファクトスタンダードも近いのではないかと思えるほどです。
なお、弊部署先輩が書いた LangChain の Custom Agent についてのブログもあります。ご一緒にどうぞ。
推論し、行動する ChatGPT(OpenAI API) Agent を作る – langchain ReAct Custom Agent 基礎 –
Llamaindex
Llamaindexは LLM アプリケーションに対するデータフレームワークです。「データフレームワーク」というだけあり、前述の LangChain の項目にあった「Data Augmented Generation」の部分に特化したものになっています。ただし、先述の Agent の機能も Llama index に実装されているため単純に document → index という部分だけ担うというわけでもなさそうです。
LangChain のサポートする主な処理として以下の 4 つが挙げられています。
- Data Connectors: 様々なデータソースやデータ形式から document を取得する機能。Web ページのようなものから Slack, Discord などもデータソースにできる。Llama Hubという様々な Data Connectors を配布している Repository もあり、かなり力が入っている。取得されたdocumentはNodeと呼ばれる単位に分割されて保持される。
- Data Index: 上記で取得された document から index を作成し、後述のクエリエンジンやチャットエンジンでクエリできるようにする機能。
it’s the core foundation for retrieval-augmented generation (RAG) use-cases.とあるように、ここは Llama index でも重要視している機能の一つ。 - Retriever: indexからユーザーのクエリ (またはチャット メッセージ) から最も関連性の高い Node を取得する機能。大量の node を持つ indexstore に対してより効率良く検索することができるようにするためのもの。
- Query Engine/Chat Engine: 上述の Retriever を介してnodeを取得して応答を生成する機能。この部分を LangChain で実装している記事も多いですが、現状であればクエリも Llama index の機能で実装することができます。Chat Engine は Query Engine のステートフル版で、上述の ReAct を利用したエンジンもある。
Llama「index」と言うだけあって、データを document として取得し、そこから index の作成までをメインとしている印象は受けます。データの取得に関しては Llama Hub と呼ばれるデータ取得する Loader が多数用意された Repository が存在し、この種類に関しては LangChain にも引けを取りません。例えば、GoogleCalendar で前述の Agent を使ってクエリしたい場合は以下のように実装します。
from llama_index import GPTVectorStoreIndex, download_loader
from llama_index.langchain_helpers.agents import IndexToolConfig, LlamaIndexTool
GoogleCalendarReader = download_loader('GoogleCalendarReader')
loader = GoogleCalendarReader()
documents = loader.load_data()
index = GPTVectorStoreIndex.from_documents(documents)
tools = [
Tool(
name="LlamaIndex",
func=lambda q: str(index.as_query_engine().query(q)),
description="useful for when you want to answer questions about the author. The input to this tool should be a complete english sentence.",
return_direct=True,
),
]
memory = ConversationBufferMemory(memory_key="chat_history")
llm = ChatOpenAI(temperature=0)
agent_executor = initialize_agent(tools, llm, agent="conversational-react-description", memory=memory)
なお、弊部署先輩が書いた Llamaindex を使って社内文書の QA ツール構築を行なったブログがあります。ご一緒にどうぞ。
Llamaindex を用いた社内文書の ChatGPT QA ツールをチューニングする
Haystack
Haystackは大規模ドキュメントコレクションに対して自然言語処理技術を適用させた検索システムを構築するためのフレームワークです。上記 LangChain や Llama index と比べてインターネット上の情報はそこまで多くない OSS になります。
LangChain や Llama index と異なる点として、「検索システムを構築するためのフレームワーク」と銘打っていて、LangChain ほどの柔軟性はなさそうですが、こと検索システムに関しては llama index のような indexing と後述する Reader-Retriever モデルをベースにした search を pipeline を使って整備する、というフレームワークを形成しています。
Haystack のサポートする主な処理として以下の 5 つが挙げられています。
- pipeline
- nodes
- agent(1.15 以降)
- tools
- document store
…要は 少し document store や nodes(及び retriever)に重心を置いた lang chain と考えて差し支えなさそうです。できることはほぼ同じで、LangChain と比べて明確にできなかった Agent すら 3/30 ごろに リリースされた version 1.15 で実装されました。
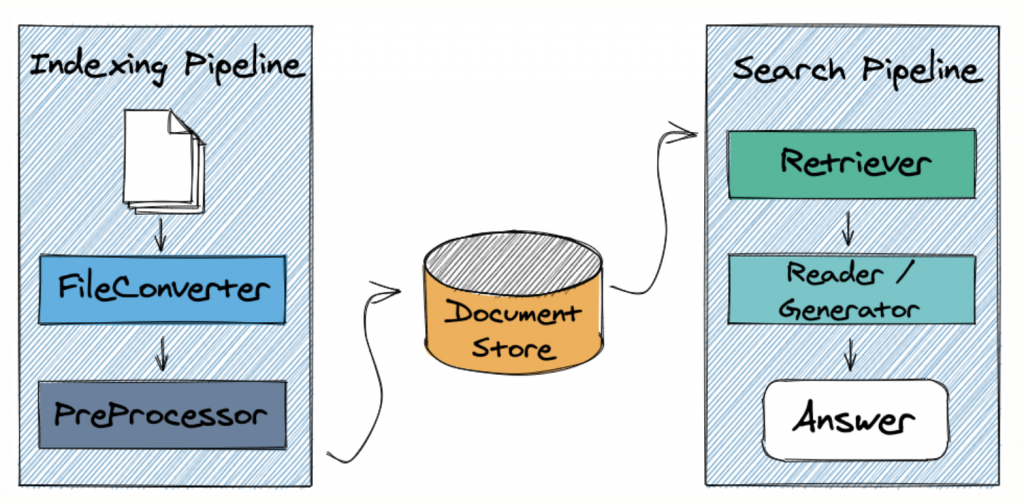
LangChain や Llamaindex では直接的には触れられていませんでしたが、Haystack は Reader-Retriever モデルと呼ばれる検索システムのアーキテクチャを踏襲しています。document store に追加された document(LangChain や Llamaindex とは異なり、独自の外部データを自然言語処理で取り扱えるようにしたものを document と呼んでいる様子。document instance で document.embedding という attribute もあったりする)に対して、クエリと関連性の高い document を抽出する Retriever と呼ばれる機構と、Retriever によって実際の document store より少量に抽出された document を読み込み応答を生成する Reader と呼ばれる機構に明示的に分けています。Retriever のみであれば正しい結果を得ることはできず、Reader のみであれば相当な document を探索する必要があり効率が悪いと位置付けています。このように検索システムに関しては一家言ありそうな haystack では「本番環境に対応した検索パイプラインの構築を目的としている」というだけあり、大規模システム構築の際は利用する期待が高まりそうです。
ちなみに、外国人の先輩にこの話をしたところ、英語でneedle in a haystack(干し草の山の中の針)という比喩表現があるそうです。意味は探し出すことが極めて困難といった類のものらしいです。なるほど…
それぞれのライブラリでの実装比較
今回は例として、単純な text document に対しての検索ではなく、 local にある csv (テーブルデータ)の情報を集計することを目的とした QA システムをそれぞれのライブラリで構築していきましょう。
今回はサンプルとしてPredict students’ dropout and academic successというデータを加工し、ランダムに 100 行抽出したものを使用します。
カラムは以下のようになっています。
- student_id: 番号(1~4424 までの数字)
- course: コース(e.g. Management, Social_Service など)
- mothers_occupation: 母親の職業(e.g.Intermediate_Level_Technicians_and_Professions, Unskilled_Workers など)
- fathers_occupation: 父親の職業
- scholarship_holder: 奨学金の有無(True or False)
- age_at_enrollment: 入学時の年齢
- result: 最終的な進路(dropout, enrolled, graduate の 3 つ)
そして質問は以下の 2 つです。
- 質問 1(query_1): What is one of the IDs of a student whose father and mother are both unskilled workers?
- 質問 2(query_2): How many people who were at least 22 years old when they enrolled dropped out?
1 つ目の質問は、父母の職業ともに”Unskilled worker”ある学生の ID の一つを答えるもので、行単位で処理が済むものになっているのに対し、2 つ目の質問は、22 歳以上で入学した人のうち dropout した人数を聞いているためテーブル全体をみる必要があります。そのため、1 つ目の質問は Agent を利用せず、2 つ目の質問は Agent を利用して実装していきます。
LangChain の場合
まずは LangChain での実装です。
質問 1
質問 1 に対しては Agent を使用せず、vectorstore である FAISS に csv を登録して検索してみます。
from langchain.document_loaders.csv_loader import CSVLoader from langchain.embeddings.openai import OpenAIEmbeddings from langchain.vectorstores import FAISS langchain_save_path = os.path.join(save_path,"langchain_index") langchain_index = FAISS.from_documents(CSVLoader(file_name).load(), OpenAIEmbeddings()) langchain_index.save_local(langchain_save_path) # langchain_index = FAISS.load_local(langchain_save_path, OpenAIEmbeddings()) results_q1_1 = langchain_index.similarity_search(query_1, k=1) print(results_q1_1[0].page_content)
結果は以下のようになりました。
student_id: 3494 course: Informatics_Engineering mothers_occupation: Unskilled_Workers fathers_occupation: Unskilled_Workers scholarship_holder: False age_at_enrollment: 33 result: Dropout
こちらは実際に確認したところ正解でした。

ローカルの csv を一度 FAISS 経由で処理する必要があるのは若干煩わしいところはありますが全体的にいい感じです。
質問 2
質問 2 に対しては前述の Agent の機能の中からCSV Agentを利用して実装していきます。これは言うまでもなく LangChain の得意分野です。
from langchain.agents import create_csv_agent from langchain.llms import OpenAI from langchain.agents.agent_types import AgentType langchain_agent = create_csv_agent( OpenAI(temperature=0), file_name, verbose=True, agent_type=AgentType.ZERO_SHOT_REACT_DESCRIPTION, ) langchain_agent.run(query_2)
実行結果は以下のように表示されました。
Entering new chain... Thought: I need to filter the dataframe to only include people who were at least 22 years old when they enrolled and then count the number of dropouts. Action: python_repl_ast Action Input: df[df['age_at_enrollment'] >= 22]['result'].value_counts()['Dropout'] Observation: 18 Thought: I now know the final answer Final Answer: 18 > Finished chain. 18
こちらも正解です。csv を入力することで pandas で勝手に処理した結果を出してきます。もちろんこの Action は LLM が生成したものなので不正解の処理はおろか、とんでもなく重たい処理を吐いたりする可能性もあります。この辺りの制御は ReAct の課題です。
Llamaindex の場合
次に Llamaindex での実装です。
質問 1
質問 1 に対しては SimpleCSVReader を使って実装していきます。
from llama_index.storage.docstore import SimpleDocumentStore
from llama_index.vector_stores import SimpleVectorStore
from llama_index.storage.index_store import SimpleIndexStore
llamaindex_save_path = os.path.join(save_path,"llamaindex_index")
SimpleCSVReader = download_loader("SimpleCSVReader")
llamaindex_index = VectorStoreIndex.from_documents(SimpleCSVReader().load_data(file=file_name))
llamaindex_index.storage_context.persist(llamaindex_save_path)
# storage_context = StorageContext.from_defaults(
# docstore=SimpleDocumentStore.from_persist_dir(persist_dir=llamaindex_save_path),
# vector_store=SimpleVectorStore.from_persist_dir(persist_dir=llamaindex_save_path),
# index_store=SimpleIndexStore.from_persist_dir(persist_dir=llamaindex_save_path),
# )
# llamaindex_index = load_index_from_storage(storage_context)
query_engine = llamaindex_index.as_query_engine()
results_q1_2 = query_engine.query(query_1)
print(results_q1_2)
結果は以下のようになりました。
2375
では実際に確認してみると…

!?
ということで不正解でした。llamaindex における as_query_engine()内部での挙動が要因でしょうか…
質問 2
質問 2 に対してはLlama index の Agentを使用してみます。OpenAIAgent という Class を読み込み、QueryEngineTool として渡します。
from llama_index import download_loader, VectorStoreIndex, StorageContext, load_index_from_storage
from llama_index.storage.docstore import SimpleDocumentStore
from llama_index.vector_stores import SimpleVectorStore
from llama_index.storage.index_store import SimpleIndexStore
from llama_index.tools import QueryEngineTool, ToolMetadata
from llama_index.agent import OpenAIAgent
llamaindex_save_path = os.path.join(save_path,"llamaindex_index")
SimpleCSVReader = download_loader("SimpleCSVReader")
llamaindex_index = VectorStoreIndex.from_documents(SimpleCSVReader().load_data(file=file_name))
llamaindex_index.storage_context.persist(llamaindex_save_path)
storage_context = StorageContext.from_defaults(
docstore=SimpleDocumentStore.from_persist_dir(persist_dir=llamaindex_save_path),
vector_store=SimpleVectorStore.from_persist_dir(persist_dir=llamaindex_save_path),
index_store=SimpleIndexStore.from_persist_dir(persist_dir=llamaindex_save_path),
)
query_engine = llamaindex_index.as_query_engine(similarity_top_k=3)
metadata = ToolMetadata(name="custom_csv", description="provides Predict-students-dropout-and-academic-success information")
llamaindex_agent = OpenAIAgent.from_tools([QueryEngineTool(query_engine=query_engine, metadata=metadata)], verbose=True)
llamaindex_agent.chat(query_2)
実行結果は以下のように表示されました。
=== Calling Function ===
Calling function: custom_csv with args: {
"input": "Predict-students-dropout-and-academic-success.csv"
}
Got output:
It is not possible to answer this question with the given context information. The context information provided does not include any data that would allow for a prediction of student dropout and academic success.
========================
Response(response="I'm sorry, but I don't have access to the necessary data to answer your question.", source_nodes=[], metadata=None)
!?!?
と、期待していた回答は得られませんでした。それもそのはずで、Llamaindex における Agent は“Agent-like” Components within LlamaIndex と評され、LangChain のような挙動はせず、クエリの内容を QueryEngineTool の Metadata の description と照らし合わせて判断するようなので、適当な description では正しい結果は得られなさそうです(そこに気を遣うくらいであれば LangChain で十分だなぁと思いつつ…)。
といったように llamaindex 単独でのクエリはこれらの方針ではあまりいい結果は得られませんでした。
が、llamaindex には PandasQueryEngine という QueryEngine が用意されており、こちらの使い勝手が非常に良かったです。
# これが質問1の回答 > Pandas Instructions: """ df[(df['mothers_occupation'] == 'Unskilled_Workers') & (df['fathers_occupation'] == 'Unskilled_Workers')]['student_id'].iloc[0] """ df[(df['mothers_occupation'] == 'Unskilled_Workers') & (df['fathers_occupation'] == 'Unskilled_Workers')]['student_id'].iloc[0] > Pandas Output: 2427 # これが質問2の回答 > Pandas Instructions: > """ len(df[(df['age_at_enrollment'] >= 22) & (df['result'] == 'Dropout')]) """ len(df[(df['age_at_enrollment'] >= 22) & (df['result'] == 'Dropout')]) > Pandas Output: 18
Haystack の場合
最後に Haystack での実装です。
質問 1
質問 1 に対しては SimpleCSVReader を使って実装していきます。haystack についてはこちらの例をベースに pandas DataFrame の形で document store に貯めて読み込む形をとります。
from haystack import Document
from haystack.document_stores import InMemoryDocumentStore
from haystack.nodes.retriever import BM25Retriever
from haystack.nodes import TableReader
from haystack.utils import print_answers
haystack_save_path = os.path.join(save_path,"haystack_index")
document_store = InMemoryDocumentStore(use_bm25=True)
df = pd.read_csv(file_name)
tables = [Document(content=df, content_type="table", id="Predict-students-dropout-and-academic-success")]
document_store.write_documents(tables, index="document")
reader = TableReader(model_name_or_path="google/tapas-base-finetuned-wtq")
table_doc = document_store.get_document_by_id("Predict-students-dropout-and-academic-success")
results_q1_3 = reader.predict(query=query_1, documents=[table_doc])
# print_answers(results_q1_3, details="minimum")
print(results_q1_3["answers"][0].answer)
結果は以下のようになりました。
2427
こちらは確認してみたところ正解でした。

質問 2
質問 2 に対してはこちらの例に沿って、ExtractiveQAPipeline → Tool → Agent という流れで component を渡していきます。
from haystack import Document
from haystack.document_stores import InMemoryDocumentStore
from haystack.nodes.retriever import BM25Retriever
from haystack.nodes import TableReader, EmbeddingRetriever, PromptNode
from haystack.utils import print_answers
from haystack.pipelines import ExtractiveQAPipeline
from haystack.agents import Agent, Tool
from haystack.agents.types import AgentToolLogger
haystack_save_path = os.path.join(save_path,"haystack_index")
document_store = InMemoryDocumentStore(use_bm25=True)
df = pd.read_csv(file_name)
tables = [Document(content=df, content_type="table", id="Predict-students-dropout-and-academic-success")]
document_store.write_documents(tables, index="document")
retriever = EmbeddingRetriever(document_store=document_store, embedding_model="sentence-transformers/multi-qa-mpnet-base-dot-v1", use_gpu=True)
document_store.update_embeddings(retriever=retriever)
reader = TableReader(model_name_or_path="google/tapas-base-finetuned-wtq")
csv_qa = ExtractiveQAPipeline(reader=reader, retriever=retriever)
prompt_node = PromptNode(model_name_or_path="text-davinci-003", api_key=OPENAI_API_KEY, stop_words=["Observation:"])
haystack_agent = Agent(prompt_node=prompt_node)
search_tool = Tool(
name="custom_csv_QA",
pipeline_or_node=csv_qa,
description="useful for when you need to answer questions with Predict-students-dropout-and-academic-success information",
output_variable="answers",
)
haystack_agent.add_tool(search_tool)
results_q2_3 = haystack_agent.run(query_2)
結果は以下のようになりました。
find out how many people enrolled who were at least 22 years old. Tool: custom_csv_QA Tool Input: total number of people who were at least 22 years old when they enrolled Observation: 7 Thought: Now I need to find out how many of them dropped out. Tool: custom_csv_QA Tool Input: number of people who were at least 22 years old when they enrolled who dropped out Observation: 4 Thought: This is the final answer. Final Answer: 4
Thought の部分をみると恐ろしく真っ当なことを考えていますが、答えが違います。前述の LangChain の Agent や Llamaindex の PandasQueryEngine のようにどのようなロジックで取得したかがわからないので処理を細かく追っていかないといけないのも厄介です(そこに気を遣うくらいであれば LangChain で十分だなぁと思いつつ…)。
まとめ
今回のブログでは、アプリケーションに対して LLM を適用させるための OSS の一部を紹介させていただき、テーブルデータへの実装例を紹介させていただきました。
実装を通して感じたことは、やはり LangChain がよく使われるだけあって情報も多く、API も使いやすいものが多かったです。Llamaindex は index を作成するところに関しては LangChain に負けず劣らずのバラエティを誇るので、独自 document を処理する必要がある場合は LangChain と合わせて実装するのはやはり最適な解なのかもしれません。そして今回興味本位で取り上げた Haystack に関してですが、フレームワーク自体はしっかりと Pipeline が整備されているイメージで好印象だったのですが、今回のテーブルデータへのタスクとの相性が悪い印象を受けました。セマンティック検索のタスクに落とし込めれば使い所はあるかもしれませんが、やはり LangChain の得意とする ReAct の汎用性は高く、様々なタスクに対応できそうな分人気も高まっていきそうです。最後までご覧いただきありがとうございました。
最後に
グループ研究開発本部 AI 研究開発室では、データサイエンティスト/機械学習エンジニアを募集しています。ビッグデータの解析業務など AI 研究開発室にご興味を持って頂ける方がいらっしゃいましたら、ぜひ募集職種一覧からご応募をお願いします。皆さんのご応募をお待ちしています。
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD