2021.07.07
spark mllib on kubernetesで機械学習
こんにちは。データ解析グループ・ETLチームのY.S.です。今回はspark on kubernetesで機械学習してみます。
1.概要
機械学習のチュートリアル的問題であるtitanicを、sparkの機械学習ライブラリであるmllib + kubernetesでやってみます。
titanicはタイタニック号の乗客データを学習させ、その乗客が生存したか死亡したかを予測する分類問題です。kaggleのチュートリアルで取り上げられている問題で、耳にしたことや取り組んだことがある方も多いのではないでしょうか。
今回は実行環境としてspark on kubernetesを使用し、pysparkのコードをkubernetesクラスタにsubmitし複数podを立ち上げて計算します。spark on kubernetesや環境についての詳細は、こちらの記事をご参照ください。
2.mllib
pysparkの機械学習ライブラリです。mllibでは、前処理やモデルの学習といったデータの流れをパイプラインとして定義します。このパイプラインコンセプトはscikit-learn projectにインスパイアされているらしいです。
パイプラインのコンポーネントは、transformersとestimatorsの2種類に分類できます。パイプラインはTokenizerやHashingTFのようにデータ変換を行うtransformerと、LogisticRegressionのように機械学習アルゴリズムであるestimatorで構成されています。
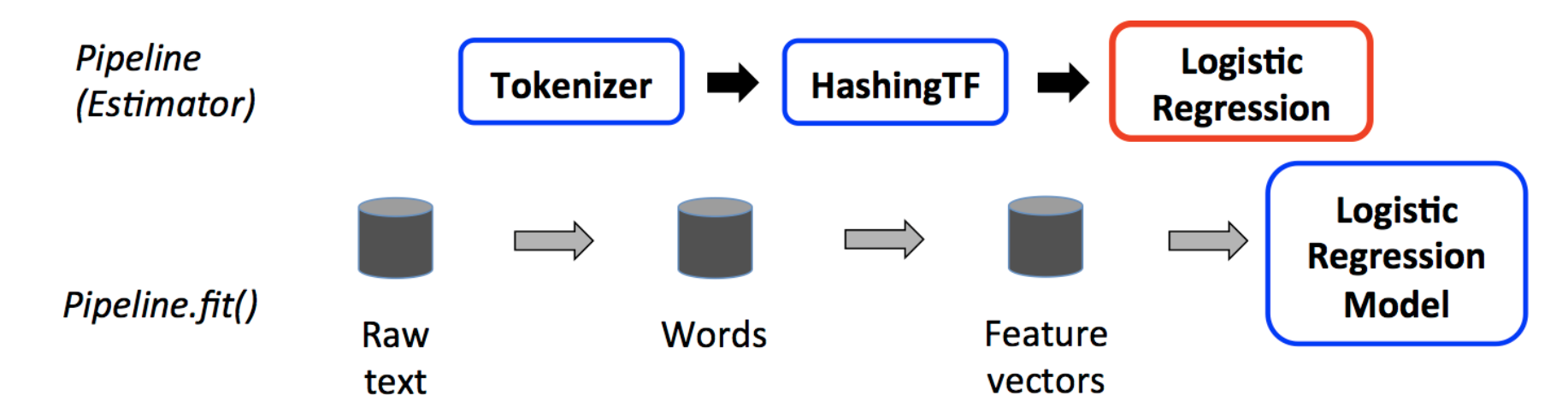
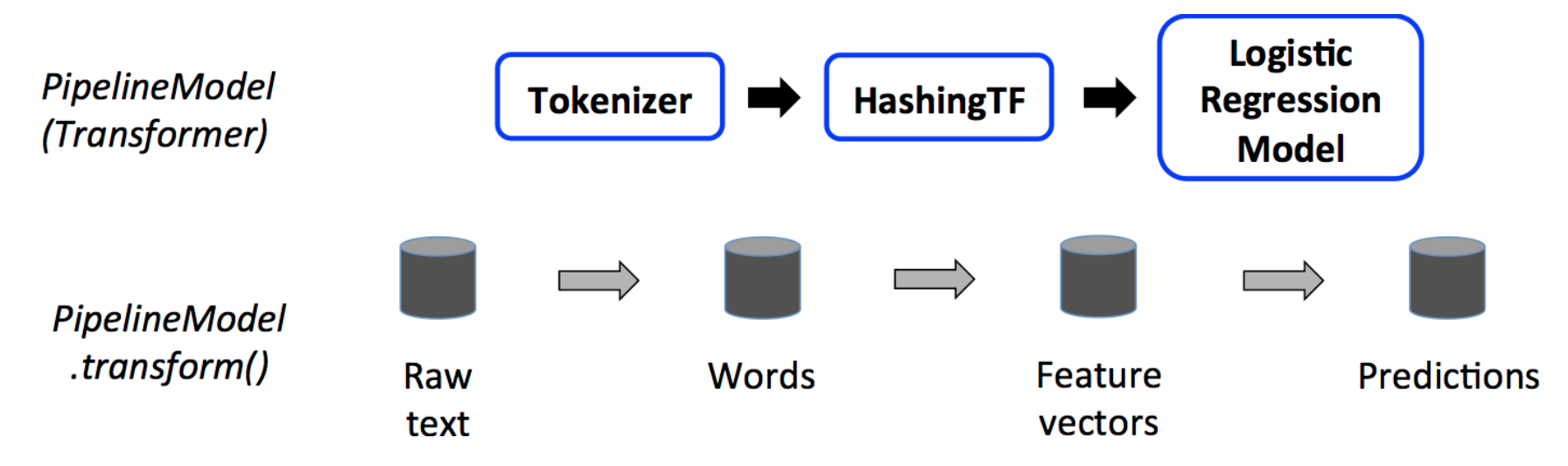
パイプラインに対してmodel = pipeline.fit(train_df)を呼ぶことで、train_dfで学習済みのestimatorを含むmodelインスタンスを得ることができます。modelの中ではLogisticRegressionはLogisticRegressionModelというtransformerとなっていて、predictions = model.transform(test_df)を呼ぶことでtest_dfに対する予測であるpredictionを得ることができます。
3.準備
Spark on kubernetessで機械学習する際のポイントとして、まずどのようにpodにデータを共有させるかということがあります。
今回はdocker imageにcsvファイルを含めてしまうことにしました。より実運用チックにやるならPersistent Volume Claimで実行ホストのローカルディレクトをマウントしたり、HDFSを使用したりするのがいいと思います。(最初は前者を試してみましたが、ファイルがディレクトリとしてマウントされてしまい(?)、上手くいきませんでした。後者に関してHDFSの環境がまだできていないので断念しました。)
Dockerfileと同じ階層にdataディレクトリを作成し、kaggleのページからダウンロードしてきたtrain/testデータのcsvファイルを配置します。
DockerfileではCOPYコマンドでdataディレクトリをimageにコピーする記述をします。このimageをspark-submit時に指定すれば、複数起動したpod間でデータを共有できます。
ARG base_img
FROM $base_img
WORKDIR /
# Reset to root to run installation tasks
USER 0
RUN mkdir ${SPARK_HOME}/python
RUN apt-get update && \
apt install -y python3 python3-pip && \
pip3 install --upgrade pip setuptools && \
pip3 install numpy && \
# Removed the .cache to save space
rm -r /root/.cache && rm -rf /var/cache/apt/*
COPY python/pyspark ${SPARK_HOME}/python/pyspark
COPY python/lib ${SPARK_HOME}/python/lib
COPY ./data/ /tmp/sparkml
WORKDIR /opt/spark/work-dir
ENTRYPOINT [ "/opt/entrypoint.sh" ]
# Specify the User that the actual main process will run as
ARG spark_uid=185
USER ${spark_uid}
4.titanicをmllibで解く
4-1.コード
pyspark.mllibでパイプラインを構築していきます。
from pyspark.sql import SparkSession
from pyspark.sql.functions import col
from pyspark.sql.types import *
from pyspark import SparkFiles
from pyspark.ml import Pipeline
from pyspark.ml.classification import LogisticRegression
from pyspark.ml.feature import VectorAssembler
from pyspark.ml.linalg import Vectors
spark = SparkSession \
.builder \
.appName("titanic") \
.getOrCreate()
# Load training datasets.
schema = StructType([
StructField("PassengerId", IntegerType(), True),
StructField("Survived", IntegerType(), True),
StructField("Pclass", IntegerType(), True),
StructField("Name", StringType(), True),
StructField("Sex", StringType(), True),
StructField("Age", IntegerType(), True),
StructField("SibSp", IntegerType(), True),
StructField("Parch", IntegerType(), True),
StructField("Ticket", StringType(), True),
StructField("Fare", DoubleType(), True),
StructField("Cabin", StringType(), True),
StructField("Embarked", StringType(), True)
])
train_df = spark.read.format("csv").options(header="true").load("/tmp/sparkml/titanic/train.csv", schema=schema)
train_df = train_df.withColumn("label", train_df.Survived)
# Configure an ML pipeline.
assembler = VectorAssembler(
inputCols=["Pclass", "Age"],
outputCol="features")
assembler.setHandleInvalid("skip")
lr = LogisticRegression(maxIter=10, regParam=0.001)
pipeline = Pipeline(stages=[assembler, lr])
# Fit the pipeline to training datasets.
model = pipeline.fit(train_df)
# Prepare test datasets, which are unlabeled.
test_df =
spark.read.options(header="true", inferSchema="true").load("/tmp/sparkml/titanic/test.csv", format="csv")
# Make predictions on test data and print columns of interest.
prediction = model.transform(test_df)
selected = prediction.select("features", "probability", "prediction")
for row in selected.collect():
features, prob, prediction = row
print("(%s) --> prob=%s, prediction=%f" % (features, str(prob), prediction))
spark.stop()
まずいつものようにspark sessionを作ります(10行目)。ちなみに最後にちゃんとspark.stop()をしないとpodがいつまでも停止しません。
31行目でtrain.csvをロードします。今回はカラム名とtypeがが分かっているので、schemaをStructTypeとして定義しておいてloadの際に指定します。ちなみに47行目でtest.csvをロードする時のようにinfer_schema=Trueにすると型を察してくれますが、そのために一回データの走査が入ります。なので予めSchema指定できるならそうした方が速いです。
パイプライン上のMLモデルは、前段から流れてきたデータフレームのfeaturesカラムを特徴、labelカラムをground truthとして学習します。今回はSurvivedカラムがground truthになるので、このカラムをwithColumnメソッドを使ってlabelカラムとしてコピーしておきます。
35行目からパイプラインを定義します。今回は特にデータ変換は行わず、VectorAssemblerで数種類の数値型のカラムをまとめてfeaturesカラムとします。また、nullが入っている列があるとパイプライン実行時にエラーになるので、.setHandleInvalid(“skip”)オプションを付けてそういう列をdropします。
今回はestimatorとしてLogisticRegressionを使用します。学習回数や正則化のパラメータ等を指定します。
パイプラインに含めるコンポーネントのインスタンスを作成し終わったら、pipeline = Pipeline(stages=[assembler, lr])でパイプラインを作成します。
作成したパイプラインに対してmodel = pipeline.fit(train_df)でtrain_dfで学習したpipelineModelを得ます。pipelineModelに対してpredict = model.transrate(test_df)で予測結果を得ることができます。
得られたpredictのデータフレームには、確信度のprobabilityカラムと予測結果のpredictionカラムが含まれています。selectでそれらを抽出して表示したりできます。
4-2.実行
Titanic.pyをhttpサーバーでホストして、下記のコマンドでkubernetesクラスターにspark-submitします。
sudo /usr/local/spark/bin/spark-submit --master k8s://https://192.168.1.14:6443 --deploy-mode cluster --conf spark.executor.instances=3 --conf spark.kubernetes.authenticate.driver.serviceAccountName=spark --conf spark.kubernetes.container.image=quytd/spark-py:v3.1.2 --name titanic http://192.168.1.14:30001/Titanic.py
実行ログはkubectl logsで確認できます。中には予測結果や確信度が出力されています。titanicのテストデータには正解ラベルが無いのでモデルの精度は分かりませんが、ラベルがあるのであればpyspark.ml.evaluationを使ってmetricsを計算することもできます。
([3.0,34.5]) --> prob=[0.8305983586067774,0.16940164139322256], prediction=0.000000 ([3.0,47.0]) --> prob=[0.891814918443835,0.10818508155616502], prediction=0.000000 ([2.0,62.0]) --> prob=[0.8165997450615972,0.18340025493840284], prediction=0.000000 ([3.0,27.0]) --> prob=[0.782134552401779,0.21786544759822102], prediction=0.000000 ([3.0,22.0]) --> prob=[0.7446601667233493,0.25533983327665066], prediction=0.000000 ([3.0,14.0]) --> prob=[0.6765203274802152,0.3234796725197848], prediction=0.000000 ([3.0,30.0]) --> prob=[0.8026340133255375,0.19736598667446248], prediction=0.000000 ([2.0,26.0]) --> prob=[0.4992998234646864,0.5007001765353136], prediction=1.000000 ([3.0,18.0]) --> prob=[0.711787103152333,0.28821289684766704], prediction=0.000000 ([3.0,21.0]) --> prob=[0.7366772340900755,0.26332276590992454], prediction=0.000000 ([1.0,46.0]) --> prob=[0.39869124812376505,0.601308751876235], prediction=1.000000 ([1.0,23.0]) --> prob=[0.20312485912644834,0.7968751408735517], prediction=1.000000 ([2.0,63.0]) --> prob=[0.8227427367101282,0.1772572632898718], prediction=0.000000 ([1.0,47.0]) --> prob=[0.40869617764833116,0.5913038223516689], prediction=1.000000 ([2.0,24.0]) --> prob=[0.47853138050480953,0.5214686194951905], prediction=1.000000 ([2.0,35.0]) --> prob=[0.5917655775165058,0.4082344224834942], prediction=0.000000 ([3.0,21.0]) --> prob=[0.7366772340900755,0.26332276590992454], prediction=0.000000 ([3.0,27.0]) --> prob=[0.782134552401779,0.21786544759822102], prediction=0.000000 ([3.0,45.0]) --> prob=[0.8835296936231415,0.11647030637685851], prediction=0.000000 ([1.0,55.0]) --> prob=[0.4907881615871509,0.5092118384128491], prediction=1.000000
最後に
次世代システム研究室では,データサイエンティスト/機械学習エンジニアを募集しています。ビッグデータの解析業務など次世代システム研究室にご興味を持って頂ける方がいらっしゃいましたら,ぜひ募集職種一覧からご応募をお願いします。皆さんのご応募をお待ちしています。
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD