2016.03.25
シングルノードのSpark R performance
こんにちは、次世代システム研究室のA.Zです。現在、広告のデータ解析プロジェクトに関わっています。
これから、このプロジェクトで採用するかどうか判断するために、sparkRのperformanceを調査しました。その際に分かった特徴・欠点などを紹介します。
SparkRについて
SparkRはR から、apache sparkを利用するためのR packageです。
SparkRはUC Berkleyのamplabが開発したものです。2015年4月から、こちらのプロジェクトは正式にapache sparkに統合されました。
SparkRのarchitectureは以下です。
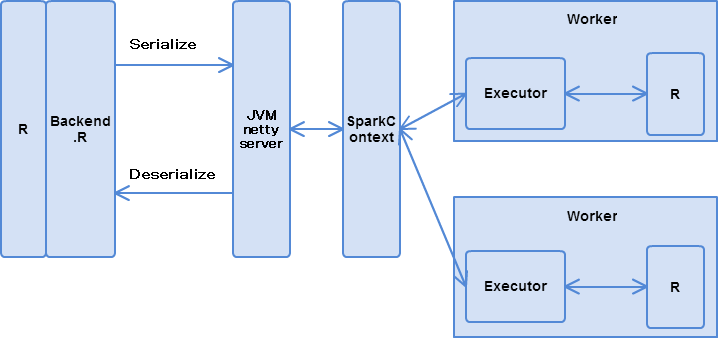
図 1
現在SparkRが提供しているAPIは以下です:
- Spark Data frame API
- 一部SparkのMLLibの連携API
Performance検証
検証目的
今回の検証は主に以下のことを確認します。
- SparkRの実行時間増加とデータ量のパフォーマンスの劣化があるかどうかを確認する
- データ量の増加による、sparkの効果(実行時間)を確認する
- データ量の増加による、R側の学習時間を確認する
- データ量の増加による、R側の推定時間を確認する
検証環境
[table id=8 /]
データ概要
今回使ったデータは、米国の飛行機の遅延データ(2007-2006)です。
http://stat-computing.org/dataexpo/2009/the-data.html
各データセットの情報は以下の通りです。
[table id=11 /]
各データセットは以下の割合で、学習データとテストデータに分けます。
学習データ:80%
テストデータ:20%
Feature Selection
今回は以下のfeatureとfeatureのデータタイプを利用します。
[table id=9 /]
今回は以下のcategoricalデータに対して、上位25のカテゴリだけを選択します。26番目以下のcategoryはすべて一つの特定カテゴリにまとめます。
- Origin
- Dest
- UniqueCarrier
Random Forest 検証
今回の検証で、RのrandomForestパッケージを利用します。
具体的な処理は以下の流れで行います。
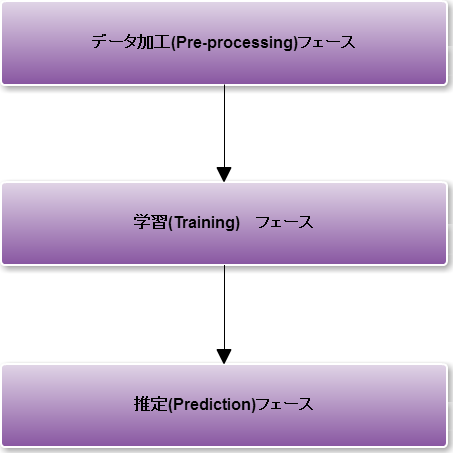
図 2
今回のテストコードは以下に公開します。
各実行フェーズの実行時間の比較
各フェーズの実行時間のグラフは以下になります。
[table id=10 /]
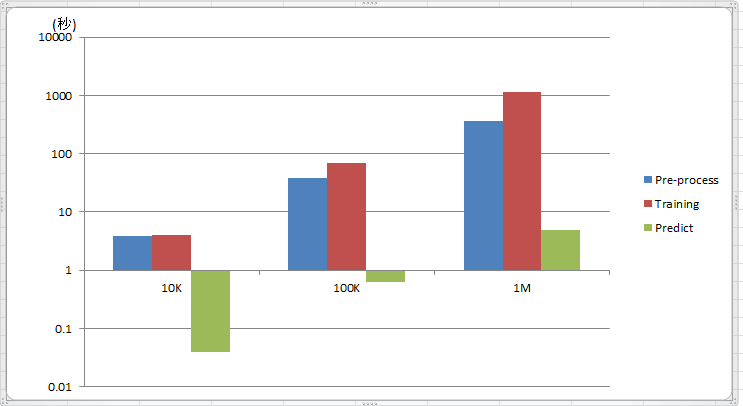
図 3
データ量と実行時間の比率(以下のグラフ)を計算すると、データ量の増加と共にパフォーマンスが劣化していることが分かります。
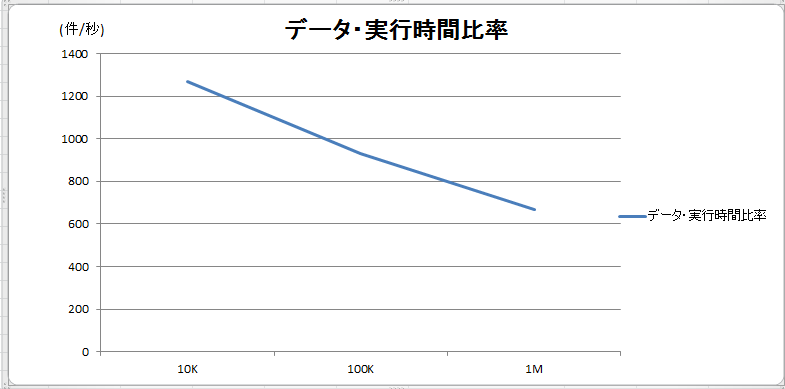
図 4
一方、データ加工(Pre-process)はデータ量の増加と共にパフォーマンスが向上していることが分かります。
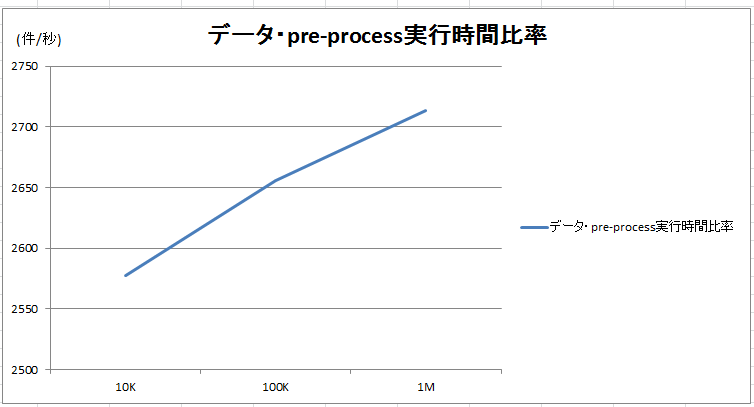
図 5
次は、どこのフェーズで、bottleneckが発生するか、もっと詳しく調査します。
各実行フェーズの実行時間と全体実行時間の割合の比較
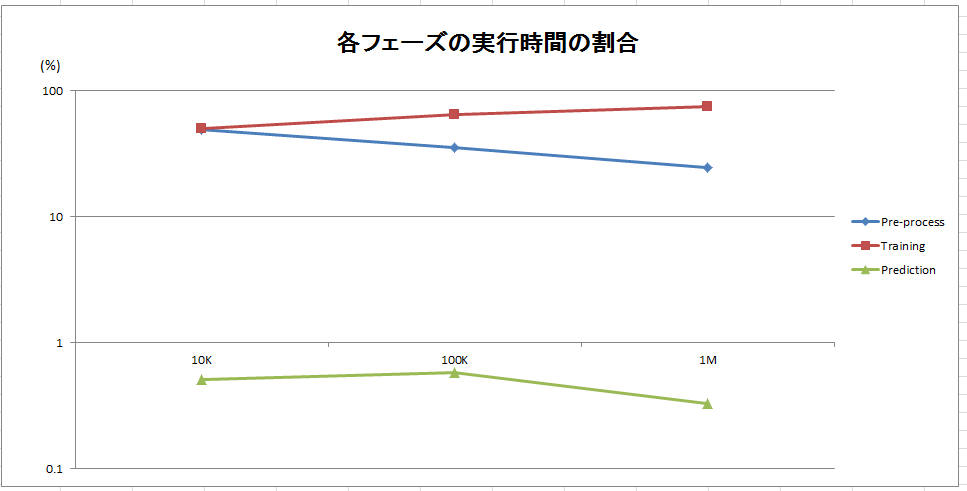
図 6
以上のグラフから、データが増加すると、データ加工(Pre-process)フェーズの割合が減ることが分かりました。データ加工の処理はすべてSparkで行うので、データ量が増えるとSparkの効果も見えてきます(図 5)。
一方、データの増加により、学習(Training)のフェーズの割合はますます増えました。学習フェーズがすべてRで行い、Rがsingle threadで動くので、Bottleneckが発生すると思われます。さらに、R で解析モデルを学習する、直接Sparkのdata frameを利用できないため、Sparkのdata frameはR のdata frameに変換することが必要です。R のdata frameはすべてmemoryにロードされるので、大量なデータのdeserializeの処理が一つの原因ではないかと思います。
推定(Prediction)フェーズは実行時間の割合が安定しており、全体の1%以下になりました。
結論
- データ量が増加すると、SparkRのパフォーマンスは劣化しました。
- データ量が増加すると、Spark上のデータ加工のパフォーマンスが向上しました。
- データ量が増加しても、R側の推定時間は安定していました(全体の1%以下)。
- データ量が増加すると、R側のモデル学習のパフォーマンスは劣化しました。
最後に
SparkRを検証した結果、まだR data frameとSpark dataframeの不適合があり、その結果変換処理のoverheadが発生します。また、Rのdata frameに変換するときに、すべてのデータをメモリーにロードしなければならないため、大量なメモリーが必要です。もしこちらの問題が解決できたら、Rのモデルやパッケージの豊さとSparkの分散処理スピードを生かし、大規模なデータ解析はもっと簡単にできるではないかと思います。
次世代システム研究室では、アプリケーション開発や設計を行うアーキテクトを募集しています。アプリケーション開発者の方、次世代システム研究室にご興味を持って頂ける方がいらっしゃいましたら、ぜひ 募集職種一覧 からご応募をお願いします。
皆さんのご応募をお待ちしています。
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD