2016.10.12
Hive テーブルのバケット分割や Spark 分散処理によるデータファイル細分化などの話
こんにちは。次世代システム研究室のデータベース(MySQL, PostgreSQL, Hive, HBaseなど) 担当のM.K.です。
今回はまた Hadoop 関連技術に戻って、Hive テーブルのバケット分割や Spark 分散処理によるデータファイル細分化、などについて書きたいと思います。
なお、本文で述べている Hive は Hortonworks HDP の Hive on Tez を前提にしており、Hive テーブルは ORC フォーマットを前提にしています。
Hive テーブルのバケット分割
Hive テーブルは以下のような CLUSTERED BY … INTO n BUCKETS 句をつけて作成することでバケット分割できます。
CLUSTERED BY (col_name, col_name, ...) [SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS
CLUSTERED BY の あとにバケット化したい特定のカラムを指定して、そのカラムをキーに分割します。この目的はテーブルを結合するときにバケットマップジョイン(もしくは、ソートマージバケットマップジョイン)をさせるためです。
バケットマップジョインの前提として、まずマップジョインがあります。
マップジョインは一方のテーブルをハッシュテーブル上に読み込んで Map フェーズでジョインするやり方で、条件を満たせば通常のジョインより高速に処理できます。
対して通常のジョインは Map フェーズでテーブルのデータを読み込んで結合キー/値を出力し、Shuffle フェーズでソート、最後に Reduce フェーズでジョインします。
マップジョインはかつては条件を満たしたクエリの中でヒント句を設定していたりしていましたが、今回検証で利用したHDP2系では以下のパラメータを設定し Hive に任せる形が推奨されています。
hive.auto.convert.join = true (default) hive.auto.convert.join.noconditionaltask = true (default) hive.auto.convert.join.noconditionaltask.size = xxx (default 10000000) hive.mapjoin.smalltable.filesize = xxx (default 25000000)
詳細はこちらのマップジョイン変換に関するドキュメントが参考になります。
続けてバケットマップジョインですが、結合する2つのテーブルが同じ結合キー(カラム)でバケット化され、一方のバケット数がもう一方の整数倍となっているという条件を満たしたときに利用することができます。
大きなテーブル同士はメモリに乗らないことが多く、マップジョインが使われにくいのですが、バケットマップジョインは大きなテーブル同士を結合するようなときに、同じ結合キーでどれくらいのバケット数で分割するかをうまくやれば効果を発揮します。
ただし注意点があり、バケットマップジョインの効果をうまく発揮するには、データを格納する段階でバケット分割しないといけません。
データ格納時のバケット分割とデータファイル分割
Hive は Schema on Read なので、参照するときに初めてそのテーブル定義が評価されます。
つまり、データ格納時はテーブル定義と同じようにデータファイルを作ることは保証しないということなので、INSERT するとき自動的には定義したバケット数と同じようにデータファイルを分割しません。
そのため、バケット数と同じ数だけデータファイルを分割するには以下のパラメータを true に設定する必要があります。
hive.enforce.bucketing = true
以前の Hive はデフォルトではこのパラメータは false でしたが、 Hive2.x 系からは常に true になります。今回検証に利用した HDP2.4.0 の Hive はバージョン 1.2.1 で、デフォルトで true になっています。
バケット分割のソート
CLUSTERED BY 句には SORTED BY を付け加えることができます。
CLUSTERED BY (colA) SORTED BY (colB) INTO 16 BUCKETS
のように CLUSTERED BY と SORTED BY に別々のカラムを指定することができますが、SORTED BY に闇雲にカラムを設定するとソートのために余計な Reducer を走らせてしまい、負荷が大きくなるおそれがあります。
例えば、CLUSTERED BY にIDカラムを指定し、日時の降順でクエリを投げることが多そうだからと SORTED BY に日時カラムを指定するような場合です。
常に最新の数件を参照するような場合は良いかもしれないですが、そうしたクエリだけを実行するのでなければ、余計な処理が増えておすすめできません。
Hive テーブルのバケット分割と Spark の分散処理
実際のシステムでは、Hive の INSERT 文だけでなく、他のアプリケーションでデータを格納することがよくあります。Spark の分散処理を行った後、SparkSQL を使って Hive テーブルにデータを格納するような場合です。
Spark には RDD または Dataframe というデータを扱う単位があり、それらをパーティション分割することによって分散処理の並列度を増やすことができます(Hive テーブルのパーティションとは別のもの)。
Spark のパーティションによる分散処理を行ってからデータを書き込むとどうなるか?
実はサイズの小さいデータファイルがたくさん出来上がってしまうということが起きます。
小さい・細かいデータファイルがたくさんできてしまうと、実際のデータサイズの割にHDFSのデータブロックを大量に消費したり、Hive クエリで参照するときに効率的に読み込めないなど、性能に悪影響を及ぼす可能性が高いです。
Spark のパーティションによる分散処理を行ったときのデータファイル例
part-00000 part-00000_copy_1 part-00001 part-00001_copy_1 part-00002 part-00002_copy_1 ...
この状態でバケット分割を定義した Hive テーブルを参照しても、データファイルがうまくバケット分割されていないことになるので、当然、バケットマップジョインなどバケット分割で期待する効果が出ません。
Spark の分散処理と Hive テーブルのバケット分割を両方利用したいときは何か対策が必要です。
データファイルの細分化対策
データファイルの細分化は運用時に最も注意しないといけないことの一つとも言えます。
Hive の INSERT 文でデータを格納する場合であれば、便利な以下のパラメータがあります。
指定したサイズを下回るデータを格納しようとすると、データを特定のファイルサイズでマージして書き出してくれるというものです。
hive.merge.mapfiles = true (default) hive.merge.mapredfiles = true hive.merge.tezfiles = true hive.merge.smallfiles.avgsize = xxx (default 16000000) hive.merge.size.per.task = xxx (default 256000000)
これらのマージに関するパラメータは、データを上書きする INSERT OVERWRITE 文だけではく、差分のデータを追記する INSERT INTO 文でも効果があります。
INSERT INTO で追記する差分のデータごとにデータファイルをマージしてくれます。
※すでにあるデータファイルとマージしてくれるわけではないので注意が必要です。
簡単なテストをしてみました。検証に利用したのは HDP2.4.0 の Hive は 1.2.1 です。
マージに関するパラメータを false にしたとき
1回目
hive> insert into table test1_table partition (create_date=20160829) select test_id, test_values, create_date from test2_table where create_date=20160829; hive> dfs -du -h /apps/hive/warehouse/xxx.db/test1_table/create_date=20160829; 344.7 K /apps/hive/warehouse/xxx.db/test1_table/create_date=20160829/000000_0 38.4 K /apps/hive/warehouse/xxx.db/test1_table/create_date=20160829/000001_0
2回目
hive> insert into table test1_table partition (create_date=20160829) select test_id, test_values, create_date from test2_table where create_date=20160829; hive> dfs -du -h /apps/hive/warehouse/xxx.db/test1_table/create_date=20160829; 344.7 K /apps/hive/warehouse/xxx.db/test1_table/create_date=20160829/000000_0 344.7 K /apps/hive/warehouse/xxx.db/test1_table/create_date=20160829/000000_0_copy_1 38.4 K /apps/hive/warehouse/xxx.db/test1_table/create_date=20160829/000001_0 38.4 K /apps/hive/warehouse/xxx.db/test1_table/create_date=20160829/000001_0_copy_1
マージに関するパラメータを true にしたとき
1回目
hive> insert into table test1_table partition (create_date=20160829) select test_id, test_values, create_date from test2_table where create_date=20160829; hive> dfs -du -h /apps/hive/warehouse/xxx.db/test1_table/create_date=20160829; 382.6 K /apps/hive/warehouse/xxx.db/test1_table/create_date=20160829/000000_0
2回目
hive> insert into table test1_table partition (create_date=20160829) select test_id, test_values, create_date from test2_table where create_date=20160829; hive> dfs -du -h /apps/hive/warehouse/xxx.db/test1_table/create_date=20160829; 382.6 K /apps/hive/warehouse/xxx.db/test1_table/create_date=20160829/000000_0 382.6 K /apps/hive/warehouse/xxx.db/test1_table/create_date=20160829/000000_0_copy_1
INSERT INTO を2回繰り返したときのデータファイル数を見ると、マージに関するパラメータを true にしたときは、一回の INSERT INTO ごとにマージされていることがわかります。
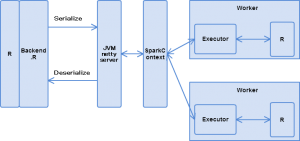
SparkSQL の SQLContext と hiveContext
Hive の INSERT 文でデータを格納すれば上記のマージに関するパラメータがありますが、Spark の分散処理後に SparkSQL の INSERT 文を使うときはどうするのか?
そこで考えたのが SparkSQL の HiveContext の利用です。
SparkSQL には SQLContext と HiveContext があり、前者は SparkSQL そのもの、後者は SparkSQL に Hive クエリの機能を使えるよう拡張したものです。
HiveContext であれば Hive のマージに関するパラメータを利用できると考えて色々試しましたが、しかし結果は HiveContext を利用しても上記のマージに関するパラメータは効かず、細かいファイルが残ったままでした。
なお、今回検証に利用した HDP2.4.0 の Spark は 1.6 です。
HiveContext ではなく HiveServer2 接続
結局のところ、Spark のパーティションによる分散処理からファイル細分化を避けて Hive テーブルに格納されるようにするには、何のひねりもないですが、HiveContext ではなく HiveServer2 接続を呼び出して Hive の INSERT 文を投げる、ということを考えても良さそうです。
ただし、厄介なことに Spark は spark-submit によって各スレーブノードにプログラムがそれぞれ展開されて分散処理する感じなので、分散処理がすべてうまくいったことを待ってから HiveServer2 経由で Hive の INSERT 文を実行しないとおかしなことになります。
そんなことを考えると、実装上の注意点が増えるので、これをやるのであれば別プログラムでデータファイルをマージする、というのも選択肢の一つです。
ここまでくるともはや前述のマージに関するパラメータも利用せず、パーティショニングされた Hive テーブルであれば、前日などのデータに対して INSERT OVERWRITE して書き戻すというのでも良いかもしれません。
巨大なデータとデータファイルの細かさ
パーティションが多い巨大なテーブルを結合し集計する Hive のクエリを使って、データファイルが細かいときとマージされたときで処理速度がどれくらい変わるかを検証してみました。
検証した Hadoop クラスタは、スレーブノード4台でスペックもそこそこ良い感じです。hive.tez.container.size などのメモリ系パラメータもデフォルトから低くしたりはしていません。
相対的な処理時間を比較したかったので各ノードのスペックや Hive パラメータなどの環境の詳細は割愛しますが、テストデータの作り方や、実際には使われないようなクエリで試したためか、かなり処理時間がかかる検証となりました。
データファイルをマージした場合とそうでない場合の検証結果
検証した Hive クエリは、以下のようなものです。
テーブルAとテーブルBを INNER JOIN で結合し、複数カラムで GROUP BY をかけて、avg()、min()、max() を取るような SELECT 文で処理時間を計測
テーブルAとテーブルBについて、データファイルが細かいものと、マージされたもの、あとはおまけで orc.stripe.size をデフォルトの 64M から 256M に増やした3種類で試しました。
テーブルのサイズやファイル数などの詳細は以下の表の通りです。
[table id=19 /]
検証した結果は以下の表のようになりました。データファイルが細かいときとデータファイルをマージしたときと比べると、3倍くらいの処理時間の差がでました。
orc.strip.size は 256M に変えてみてもそれほど変化はありませんでした。
[table id=18 /]
巨大なテーブルになるほど、データファイルのマージが大事になってくることがわかると思います。
Hive のデータ参照における Mapper 数と性能
データファイルがマージされて一つになると、Hive で参照するときに起動される Mapper 数が減り、場合によってはマージ前より遅くなることもありえます。
起動される Mapper 数がどれくらいでちょうど良いかは Hadoop クラスタのリソースや色々なパラメータ設定、クエリの内容など環境によって変わります。
もし、Mapper 数を増やした方が速くなりそうなときは、下記のパラメータを設定して起動される Mapper 数を調整すると良いです。
Mapper 数を調整するときのパラメータの設定例
tez.grouping.split-count=10; tez.grouping.min-size=67108864; tez.grouping.max-size=67108864; mapreduce.input.fileinputformat.split.minsize=64000000; mapreduce.input.fileinputformat.split.maxsize=64000000;
設定の一例として、上記例の下4つのパラメータを、読み込みたい入力データのサイズを同じ値に指定します。実際の一個のデータファイルサイズより小さく設定することで、その分 Mapper 数が増えていきます。
あまり小さくしすぎると、Mapper 数が増えすぎてしまい返って遅くなることがあるので、読み込むデータ全体のサイズが巨大になりそうなときは、tez.grouping.split-count で上限数を決めると良いです。
別の裏ワザ?としては、INSERT 文でデータを書き込むときに、Mapper 数を増やすのではなく、DISTRIBUTE BY 句を使うなどして Reducer 数をわざと増やして並列度を上げて処理を速くするというやり方もあります。
Reducer が増えると書き込まれるデータファイルがその分細かくなりますが、前述したマージに関するパラメータを設定することで自動でファイルマージしてくれるので、うまくやれば処理性能を上げられると思います。
まとめ
改めて、Hive や Spark を利用するときは、書き込み時のデータファイル分割サイズを考慮してシステム設計やアプリケーション開発しないといけないと思いました。
特に今回はあまり言及していませんが、Hive テーブルのパーティショニングを行うと、そのパーティション( HDFS 上は一つ一つのディレクトリ)の中でデータファイルが分割されるので、パーティション数が多くなるような設計をしていると、データファイル細分化はさらにややこしくなります。
今回のポイントをまとめると、次のようになります。
- Hive のバケット分割はクエリ条件が決まってないときは闇雲に使わない、それよりも先ずデータファイル細分化を対策すべき
- Hive のデータファイルマージやバケット分割は、Spark のパーティションによる分散処理と相性がよくない
- Hive の INSERT 文を使う場合はデータファイルのマージに関するパラメータは便利
- SparkSQL の HiveContext は HiveServer2 からクエリを実行するのと違い、Hive パラメータ設定やクエリの挙動が同じではないので要注意
- 必要があれば、関連パラメータを調整し Mapper 数を増やして処理速度をチューニングするのも手
最後に、Spark のパーティションによる分散処理後にデータファイルをマージしてくれる機能や、SparkSQL から Hive の機能をフルに使えるインターフェースが開発されるといいな、と思う今日このごろです。
最後に
次世代システム研究室では、アプリケーション開発や設計を行うアーキテクトを募集しています。アプリケーション開発者の方、次世代システム研究室にご興味を持って頂ける方がいらっしゃいましたら、ぜひ 募集職種一覧 からご応募をお願いします。
皆さんのご応募をお待ちしています。
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD