2022.07.08
「機械学習 × 金融取引」 実導入に向けた検討
こんにちは。AI研究開発室のY. O.です。
AI研究開発室ではこれまで「機械学習 × 金融取引」の分野で様々な研究を行ってきました。
そのような背景の中、実導入も見据えるとどのような観点を追加できるのか、というのが今回のテーマです。
TL;DR;
- 実世界と機械学習の世界の全体像を考えよう
- 全体像の中で3つほど検討ポイントがありそうだ
機械学習を実導入まで検証する全体像
金融取引にテクノロジーをかけ合わせた実導入を!というような話を聞くと、すぐに「AI」「ロボット」というようなワードが頭をよぎるのは自然と思います。
そんな中、改めて実導入の観点で整理すると、機械学習を金融取引に組み込む全体像は下図のようになり、検討すべきは難しいモデルだけではないことがわかります。
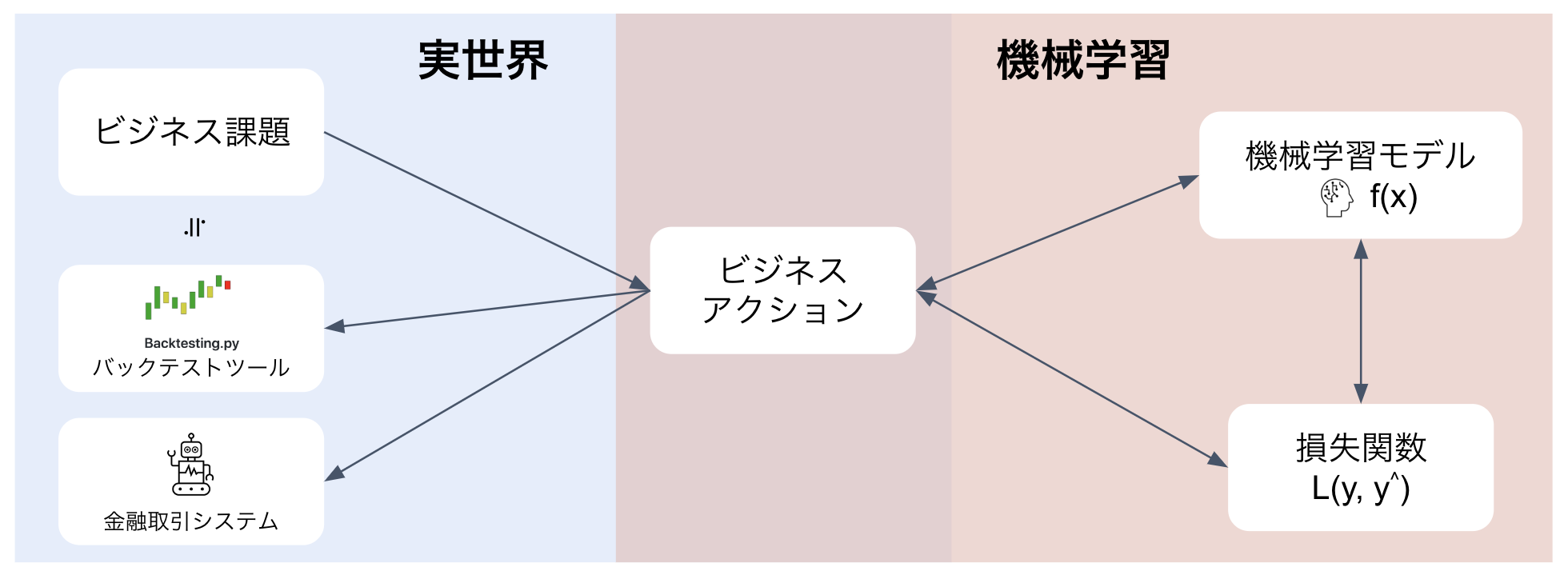
今回はこの第1の結論「実世界と機械学習の世界の全体像を考えよう」にたどり着くため、全体像1つ1つについて取り上げ、どういった論点があるのかを見てみることにします。
ビジネス課題 → ビジネスアクション
実世界で発生する課題は、そのままでは機械学習が解くことができません。このステップでは、実世界における課題(= ビジネス課題)を機械学習が解ける問題へ落とし込む方法について考えてみます。
方法としては2つのアプローチがあり、落とし込むビジネスアクションを、機械学習が解きやすい問題としビジネス課題から遠ざける or 機械学習には解きにくい問題だがビジネス課題に近づける、となるかと思います。
どちらにも良し悪しあり、後半部で深堀りを行いたいと思います。
ビジネスアクション ↔ 機械学習モデル ↔ 損失関数
このステップに特段コメントはありません。上段ステップで機械学習に解かせるビジネスアクションが決まったら、後は機械学習の世界で培ったモデリング手法のあれこれを実施するだけです。
一点注意するのであれば、金融取引データ = 時系列データ、ということで学習時に未来データを用いないようにすることくらいでしょうか。
ビジネスアクション → バックテストツール
上段ステップで一定のモデル精度が担保できたら、その成果が実世界のビジネス課題を模した環境でも上手くいくのかをテストします。このテストをバックテストと呼び、現在はバックテストを行うことができるOSSライブラリが数多く出回っているので、こちらを利用していきます。後半部では、バックテストを行うOSSライブラリの1つであるBacktesting.pyについてTipsを紹介したいと思います。
また、バックテストでは実世界のすべての状況を模しているわけではない点に気をつけなければいけません。過去のAI研究開発室ブログでも紹介しているように、実際の取引には間接コストと呼ばれるものが存在し、バックテスト通りには成果を出せない可能性もあります。
ビジネスアクション → 金融取引システム
バックテストにより実世界でも成果を出せることが担保できたら、システム化に取り掛かります。このステップでは、システム化の知見に併せて金融取引向けのライブラリ利用も検討対象となってきます。
実導入で成果を出すための検討ポイント
ここまでは、機械学習を実導入する上での全体像のお話をしました。後半部では、全体像を抑えた上でどこにより成果を出すための改善ポイント・Tipsがあるのか、について考えていきたいと思います。
ビジネスアクションへの落とし込み
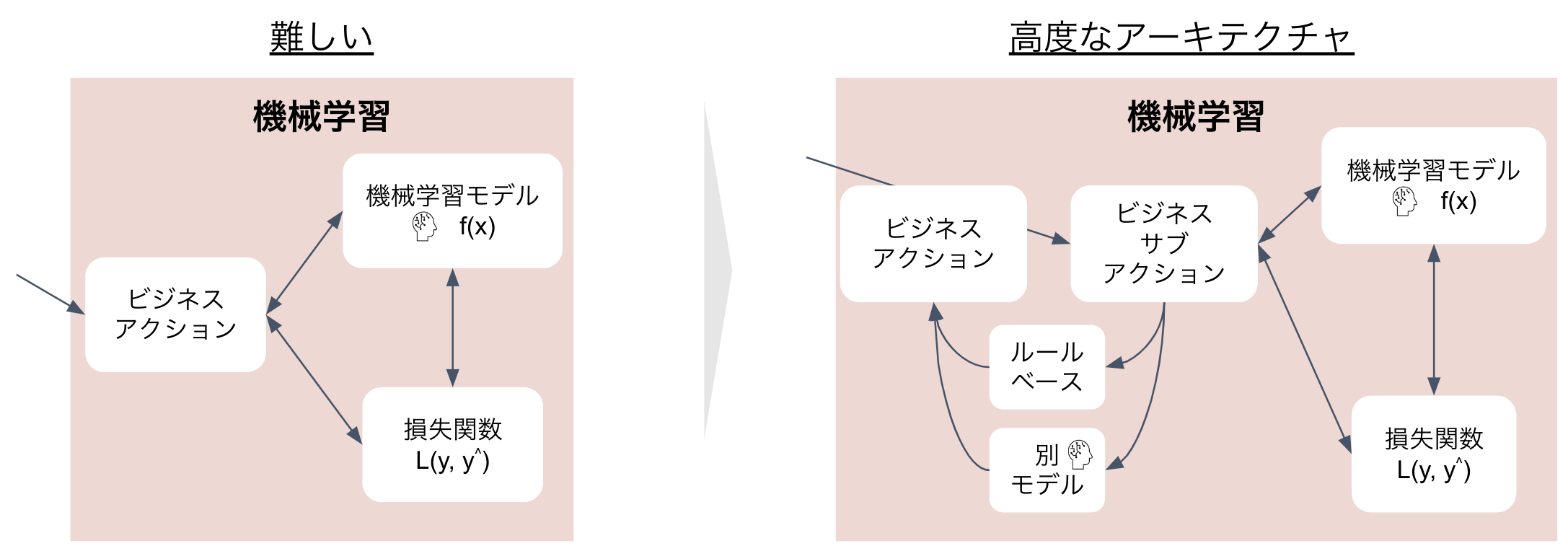
前半部にて、機械学習が解きやすい問題としビジネス課題から遠ざける or 機械学習には解きにくい問題だがビジネス課題に近づける、という2つのアプローチがあると指摘しました。
今回研究した範囲では、特に金融取引データでは、この2つの単純なアプローチをベースにより高度なアプローチを検討しなければならないということが分かりました。
具体的には、下図のようにビジネス課題に近いアクションに落とし込むと1-modelで学習させるのは相当難しく、高度なアーキテクチャなどの検討が必要というように考えています。
機械学習のコア:最近のディープラーニングモデル
続いて、機械学習のコア、機械学習モデルについて直近の動向をキャッチアップしてみます。
金融取引データのような時系列データを扱うモデルとしては、LSTM (S. Hochreiter, 1997)やTransformer (A, Vaswani, 2017)が有名でブレイクスルーを作ってきました。
その後の動向としては、DeepAR (D. Salinas, 2017)・Temporal Convolutional Network (S. Bai, 2018)・N-BEATS (BN. Oreshkin, 2019)・Temporal Fusion Transformers (B Lim, 2021)、といったディープラーニングモデルが提案されています。それぞれの特徴としては、DeepAR→LSTMの拡張、TCN→画像領域で成功している畳み込み層の取り込み、N-BEATS→画像領域で成功している勾配消失へ対応したスキップコネクションの取り込み、TFT→Transformerの拡張、と大まかに書き下すことができ、提案されたアーキテクチャ自体はブレイクスルーとは言い難い状況にあります。
そんな中、時系列データにディープラーニングがそれほど効果的ではないのでは、というような主張もされています(S. Elsayed, et.al., 2021)。この手の論文は(そして機械学習分野全般的にも)幾分かチェリーピックな要素も含まれているので注意が必要ですが、筆者としても、特に開発期間が決まっているような実導入現場ではGB系モデルの方が高精度となってもおかしくない、と考えています。決まった期限という枠組みだと、ディープラーニングが持つ、ハイパラが多い・学習が不安定・Null/カテゴリ/スケールへの対処が必要・GPUでも学習が遅い、といった特性により、開発イテレーションサイクルが少なくなってしまうことのデメリットが目立ってしまいます。
バックテストの利用Tips
最後に、Backtesting.pyを導入する上でのTipsを紹介します。チュートリアルなどを参照すると、次のような構成を採用しStrategyクラス内で機械学習モデルを逐次トレーニングさせることを推奨しています。

ですが、このような普段機械学習の局面で利用しないStrategyクラス内での操作は、モデル精度改善フローとの相性が悪いことが問題となります。
そこで下図のように予測自体は機械学習の世界でのベストプラクティスを採用し、Strategyクラスではただ単に投入した時系列データのBuy|Sell|Closeアクションを読み取るだけ、とするのが、機械学習のモデル精度改善フローとの相性がよいTipsになります。

最後に
今回はこれまでAI研究開発室が行ってきた「機械学習 × 金融取引」に、実導入の観点で研究を実施しました。
冒頭TL;DR;をまとめ直し、「機械学習を金融取引に組み込む際、難しいモデルを考えがちだが、それ以外にも重要な点はある」「全体像の中で3つほど検討ポイントがあり、1. 高度なアーキテクチャなどの検討が必要、2. 最新DLモデルも発表されているがGB系も十分検討対象、3. Backtesting.pyのStrategyクラス内に機械学習の世界を混在させない」の2点を再度強調して終わりとさせていただきます。
グループ研究開発本部 AI研究開発室では、データサイエンティスト/機械学習エンジニアを募集しています。ビッグデータの解析業務などAI研究開発室にご興味を持って頂ける方がいらっしゃいましたら、ぜひ 募集職種一覧 からご応募をお願いします。皆さんのご応募をお待ちしています。
参考資料
[1] LONG SHORT-TERM MEMORY (S. Hochreiter, et.al., 1997)
[2] Attention Is All You Need (A, Vaswani, et.al., 2017)
[3] DeepAR: Probabilistic Forecasting with Autoregressive Recurrent Networks (D. Salinas, et.al., 2017)
[4] An Empirical Evaluation of Generic Convolutional and Recurrent Networks for Sequence Modeling (S. Bai, et.al., 2018)
[5] N-BEATS: Neural basis expansion analysis for interpretable time series forecasting (BN. Oreshkin, et.al., 2019)
[6] Temporal Fusion Transformers for interpretable multi-horizon time series forecasting (B Lim, et.al., 2021)
[7] Do We Really Need Deep Learning Models for Time Series Forecasting? (S. Elsayed, et.al., 2021)
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD