2025.07.23
OpenAIのGPT Image 1 APIで入力画像に高い忠実度(high input fidelity)の画像生成を試してみた
TL;DR
- OpenAIが公開していた画像生成API(gpt-image-1)に、入力画像への忠実度(input fidelity)を指定する機能が追加されました。これにより入力画像の顔やロゴ、物体のディテールなどが非常に高い精度で再現可能です。それを応用するとアイテムを画像から抽出して、別の画像に配置するなど柔軟で多様な画像編集が可能です。
- GPT Image 1とGeminiやBlack Forest Labsの最新画像編集・生成モデル「FLUX.1 Kontext」と比較してみましたが、GPT Image 1の高忠実度の画像生成は、他のモデルに比べて非常に高い精度で入力画像を再現できることがわかりました。
- なお、GPT Image 1 APIの利用には、特別な身元確認の追加が必要です。また、APIの利用料金も割高という点に注意が必要です。高解像度・高忠実度の画像編集・生成の場合、1枚の画像に対して約0.2ドルの料金が発生します。
はじめに
こんにちは、グループ研究開発本部のAI研究開発室のT.I.です。今年3月末に、OpenAIはChatGPTの画像生成機能を大幅に強化しました(Introducing4o Image Generation)。そして、その画像生成機能のAPI版であるgpt-image-1が4月にリリースされています(Introducing our latest image generation model in the API)。これにより、ChatGPTの画像生成機能をAPI経由で利用できるようになり、様々なアプリケーションでの画像生成が可能となりました。さらに、このAPIに新たに「input fidelity」という機能が追加されました(Image generation: high fidelity editing)。これは、入力した画像に対する忠実度(fidelity)を設定する機能で、highに設定すると、顔やロゴ、物体のディテールなどが非常に高い精度で再現されるようになります。(参考:input fidelityのチュートリアル Generate images with high input fidelity」)。どのように入力画像に対して忠実度の高い画像生成を実現しているのか、技術詳細は公開されていませんが、high fidelity mode では、API利用時に画像のアスペクト比に応じて、4096から6144の追加トークンが付加されており、ここに元画像のより高密度な情報が含まれていると推測されます(Images and vision – Calculating costs)。今回のBlogでは、この新機能(input fidelity)を利用して、どの程度入力した画像に忠実な画像生成が可能かを実験してみます。
GPT Image 1 APIによる画像編集のデモ
まず、OpenAIの高性能な画像生成・編集APIであるgpt-image-1の利用には、通常のOpenAIのアカウント(≠ChatGPT)に加えてOrganizationの認証が必要です。Personaという認証系サービスを利用し、必要なものは免許証などの証明書とWebカメラ(もしくはスマホのカメラ)を利用した3次元的な顔の形状の照会を行います。「OpenAI Organizationの認証方法」のZennの記事が具体的なステップごとの詳細が解説されています。認証が完了すると、gpt-image-1が利用できるようになり、OpenAI Platformでの画像生成も可能となります。
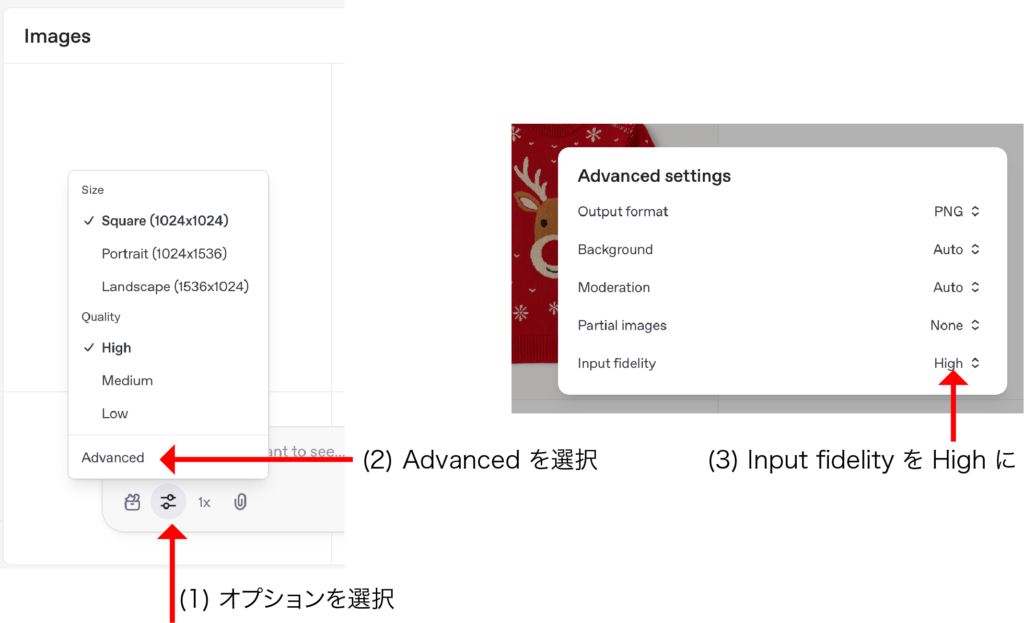
今回追加された「input fidelity」は、Image-to-Image の生成で、入力画像により忠実な画像を生成するための設定です。Playgroundの画像生成の画面では、少々わかりにくいのですが、まずは設定をクリックして、「Advanced」と選択、その後現れる「Input fidelity」のスライダーを調整することで、画像の忠実度を設定できます。
APIを利用する場合は以下の通りで、モデルはgpt-image-1を指定し、input_fidelityをhighに設定します。
import base64, os
from io import BytesIO
from PIL import Image
from openai import OpenAI
API_KEY = os.environ.get("OPENAI_API_KEY", "")
client = OpenAI(api_key=API_KEY)
input_path = 'some_image.jpg'
input_img = open(input_path, 'rb')
prompt = "some prompt"
input_fidelity = "high" # or "low" based on your requirement
response = client.images.edit(
model="gpt-image-1",
image=input_img,
prompt=prompt,
input_fidelity=input_fidelity,
quality="high",
output_format="jpeg"
)
image_base64 = response.data[0].b64_json
image_bytes = base64.b64decode(image_base64)
image = Image.open(BytesIO(image_bytes))
image.save("output.jpg")
WebUIやAPIを利用しての今回の画像生成には、1枚あたり1分強ほどの時間がかかります。
OpenAIのデモでは、ユースケースとして以下のようなものが挙げられています。
- 画像の編集、物体の追加・除去
- 人物の表情編集、スタイルの変更、写真の合成
- アイテムの抽出と再配置
物体の編集:マグカップの色を変えてみる
さて、簡単なデモを行ってみます。まずは、以下のようなデスクの画像でマグカップの色を変更してみます。
プロンプト:デスクの上のマグカップの色をオリーブグリーンに変更してください。

さて、結果は以下の通りとなりました。左が高忠実度、右が低忠実度の画像です。このような単純な場合ではあまり違いはわかりにくいですが、よく見るとマグカップの取手の形状が低忠実度では丸く元の画像から変わっています。他にも葉っぱの形などをよく見ると高忠実度の方がオリジナルとの再現性が高いことがわかります。

画像の編集:クリスマス・シーズンから夏のビーチへ
次の例として、以下のクリスマス・シーズンの画像を夏のビーチサイドに変更してみます。
プロンプト:クリスマス・シーズンの画像を、ビーチとヤシの木がある夏のシーズンの画像に変更してください。

結果は以下の通りです。左が高忠実度、右が低忠実度の画像です。クリスマスから夏への変更に伴い、背景だけではなく、人物の服装もダサいセーターから、元の柄・色合いを反映したTシャツに変更されています。高忠実度の場合、表情や顔のシワなどの細部までよく再現されています。一方の低忠実度の場合、表情や肌の質感などが少しぼやけており、全体的に抽象的な印象を受けます。また、マグカップなどのテーブル上のアイテムの再現性も高忠実度の方がよく再現されています。

物体の抽出:着ているセーターを抽出してみる
また、画像のアイテムを抽出することも可能です。先ほどのクリスマスの画像から、右側の男性のセーターを抽出して、白の背景に配置してみます。
プロンプト:右側の男性の着ている赤いセーターを抽出して、白い背景にセーターを配置してください。

高忠実度の場合、肩の模様やトナカイのディテールまでしっかりと再現されています。一方の低忠実度の場合では、セーターの各々のパーツは似ているのですが、肩の模様やトナカイの口の周りなどのディテールが失われています。また、トナカイが、低忠実度の場合、単にワッペンで貼り付けられていることがわかります。
複数の画像による物体の編集:抽出したセーターに着替えさせてみる
複数の画像を与えることも可能です。以下のように、画像のリストを入力すればよいです。WebUIの場合は、2つの画像をそれぞれアップロードします。
input_imgs = [
('model.png', open('PATH_TO_IMAGE_1', 'rb'), 'image/png'),
('sweater.png', open('PATH_TO_IMAGE_2', 'rb'),'image/png'),
]

さて、この人物の白いTシャツをセーターに変更してみます。
プロンプト:男性のTシャツをこのセーターに変更してください。

高忠実度の場合、元の人物の顔や腕の組み方が自然に再現され、Tシャツもちゃんと例のセーターに変わっていることがわかります。一方の低忠実度の場合、顔つきや腕の組み方が違いますし、セーターの柄もトナカイの耳の部分のディテールが違っています。
GeminiとFLUX.1 Kontextと比較してみた
GPT Image 1 APIの高忠実度のと低忠実度の比較からわかったように、入力された画像に対して非常に高く再現されることがわかります。せっかくなので、同様の画像編集が可能な他の生成AIモデルと比較してみます。ここでは、Gemini と「FLUX.1 Kontext」を利用して比較してみます。「FLUX.1 Kontext」とは、Black Forest Labsにより2025年5月29日にリリースされた最新のマルチモーダルモデルで、画像生成や編集においても高い性能を発揮します。Introducing FLUX.1 Kontext and the BFL Playground
さて、ではクリスマス・シーズンの画像を夏のビーチサイドに変更した結果の比較は以下の通りです。なお、プロンプトで細かく指示すれば結果は変わる可能性がありますが、基本的に全てのモデルに同じシンプルな編集指示のプロンプトを与えています。

FLUX.1 Kontextの場合は、何故か服の色は変更されていますがセーターのままです。よくよく元の画像と比較すると人物やテーブルなどはそのまま切り抜かれて背景のみを夏のビーチサイドに差し替えられているようです。一方で、Gemini関しては、人物の顔つきがすっかりと変わってしまっていますし、服装もまた別の変なセーターになっています。これに対して、GPT Image 1 APIの高忠実度では、FLUX.1のような切り抜きではない新規の作成でありながら画像のディテールがよく再現されております。
次にセーターの抽出の比較をしてみます。

今回の場合、FLUX.1 Kontextの結果は中々良い感じです。一方で、Geminiの場合、見切れてしまっており、また、人が着ている画像から顔を抜き取っただけのようなやや不自然な結果となっていますし、柄も全く違います。これに対して、GPT Image 1 APIの高忠実度では、元の画像がよく再現されており、セーターの模様やトナカイのディテールがしっかりと抽出されています。
最後に、この抽出したセーターをモデルに着替えさせる実験をしてみます。FLUX.1の場合、複数の画像を入力して結合するような生成ができなかったため割愛します。

さあ、結果はこのようになりました。GPT Image 1 APIの高忠実度は、先ほどの実験にあるようにしっかりと元の人物の特徴を残しながらセーターに交換できています。一方のGeminiですが、セーターの画像の方に人物を合わせてしまっている様子で、顔は見切れてしまい、背景も無くなってしまいました。
APIの料金について
さて、GPT Image 1 APIで色々と遊んで見ましたが、APIの料金には要注意です。テキストの入力は100万トークンあたり5ドル、そして画像は入力100万トークンあたり10ドル、出力は100万トークンあたり40ドルとなります(OpenAI API Pricingより)。更に、忠実度の高い画像生成にはその情報量として、入力画像のアスペクト比が正方形の場合、4096トークン、ポートレイトやランドスケープの場合は6144トークンが追加されます(Images and vision – Calculating costsより)。
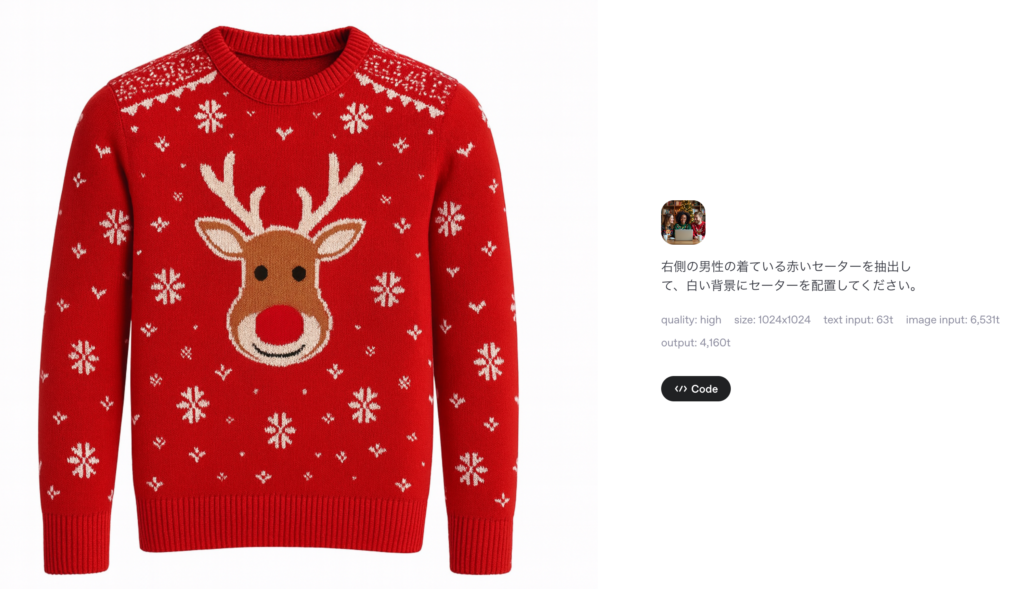
具体的に使用したトークン数はAPIのレスポンスやWebUIを使った場合、生成した画像を選択すると確認できます。この例の場合では、テキストトークン数63、入力画像トークン数6,531、出力画像のトークン数は4,160なので、計算すると約0.23ドルとなります。自分の場合、色々と実験で遊んでいる間にあっという間に20ドル近くを消費してしまいました。
まとめ
今回のBlogでは、OpenAIのGPT Image 1 APIの新機能である「input fidelity」について解説しました。従来の画像生成・修正APIに比べて、入力画像への忠実度が飛躍的に改善しており、人物やアイテムの一貫した再現や画像の編集が可能です。性能比較としてGeminiやFLUX.1 Kontextと比較してみましたが、画像の一貫性や指示への追従などはGPT Image 1が最も優れていることがわかりました。GPT Image 1 APIの利用はコストが高いため料金には注意が必要ですが、非デザイナーであってもこれらのAPIを利用することで様々な画像生成や編集が可能となります。ただ、人物などの再現性が高い分、悪用される懸念もあるため色々と心配な点もあります。
最後に
グループ研究開発本部 AI研究開発室では、データサイエンティスト/機械学習エンジニアを募集しています。ビッグデータの解析業務などAI研究開発室にご興味を持って頂ける方がいらっしゃいましたら、ぜひ募集職種一覧からご応募をお願いします。皆さんのご応募をお待ちしています。

Ideogram 3.0)
参考資料
- Introducing 4o Image Generation
- Introducing our latest image generation model in the API
- Image generation: high fidelity editing
- Generate images with high input fidelity
- Images and vision – Calculating costs
- OpenAI Organizationの認証方法
- OpenAI Platform
- Introducing FLUX.1 Kontext and the BFL Playground
- OpenAI API Pricing
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD





