2025.03.12
Mercury CoderとLLaDA: 拡散言語モデルによる高速文章生成
TL;DR
- Inception LabsはMercury Coderという拡散言語モデルを採用した初めてのコード生成サービスを2025年2月28日にリリースしました。従来の生成AIでは文章を冒頭から順々に作成しますが、拡散言語モデルでは一度に文章を生成し順々に細部を更新することで最大10倍近い高速な出漁が可能です。
- Mercury Coderの技術詳細は不明ですが、Masked Diffusionを採用していると思われます。LLaDAは、この技術を利用する80億パラメータの拡散言語モデルで2025年2月14日に公開されたオープンウェイトモデルです。同規模のLLaMA 3 8Bに匹敵する性能を持ち、LLMは逆方向の推論性能が低下するという「逆転の呪い」に対して堅牢性を発揮します。
- 拡散言語モデルの実用化は始まったばかりですが、今後の技術的発展が期待されます。
はじめに:拡散言語モデル Mercury CoderとLLaDA
こんにちは、グループ研究開発本部・AI研究室のT.I.です。Stanford, UCLA、Cornell大学の研究者が立ち上げた「Inception Labs」はMercury Coderというコード生成に強化された生成AIサービスを2025年2月28日にリリースしました(Introducing Mercury, the first commercial-scale diffusion large language model)。大規模言語モデルは、文章の続きを単語(トークン)単位で順々に予測することで文章を生成しています。一方、Mercury Coderは「拡散大規模言語モデル(diffusion large language model)」という新しいアプローチを採用しています。ノイズから徐々にイラストを生成する際のDiffusion Modelのように、拡散言語モデルでは文章を不正確であっても一度に生成し、ステップを重ねて単語を並列に更新することで、高速に文章生成を可能としています。
百聞は一見になんとやらではありますが、Mercury Coderの実行のデモが上記の動画になります(Inception Labsのサイトより引用)。最初は出鱈目なコードがステップを重ねるごとに瞬く間に修正されて完成されていきます。他の生成AI(miniや軽量版)との性能比較表は以下の通りです。Inception LabsのMercury Code MiniおよびMercury Code Smallは、diffusion large language models (dLLMs)を応用することで、10倍もの速度改善を達成したとしています。

さて、唐突に拡散言語モデルと言われても、何のことかと思います。Mercury Coderの技術詳細は未公開で不明ですが、生成プロセスから判断するとMasked Diffusion Modelというアプローチを利用している可能性が高いです(参考資料:Masked Diffusion Modelの進展)。時は少し遡りますが、中国人民大学とAnt Groupは、2025年2月14日に、LLaDA 8Bという拡散言語モデルを公開しました(Large Language Diffusion Models arXiv:2502.0992)。LLaDAは、Large Language Diffusion with mAsking から来ています。Masked Diffusion Modelをベースにした拡散言語モデルであり、LLaMA 8Bと比較して同等以上の性能をフルスクラッチで達成しています(名称はLLaMAにちなんだものかと思います)。このLLaDA 8Bは、HuggingFace・GitHubで公開されており、一般のユーザーでも簡単に利用することが可能です(LLaDA HuggingFace、LLaDA GitHub。今回のBlogでは、最近の生成AIの新展開とも言える拡散言語モデルについて、Mercury CoderとLLaDAを紹介します。
Mercury Coder使ってみた
まずは、Mercury Coderを実際に使ってみようと思います。playground にアクセスするとMercury Coderを簡単に使うことができます。APIについても今後公開予定だそうです。
では、試しにテトリスを作ってもらいました。Mercuryのコード生成スピードは確かに非常に早く、瞬く間にHTMLとCSS、そしてJavaScriptのコードが完成されました(?)。
生成したコードはブラウザ上で実行可能です。この辺りの使い勝手はClaudeなどと同じですね。右上のボタンを押して早速テトリスを実行してみましょう。

おっと、白い画面が表示されるだけで何も起きません。どうやらコードが不完全でバグがあるようです。そのような場合は追加で指示を与えて修正が可能で、過去のバージョンも履歴に残って確認できます。しかし、何度も修正したのですが、なかなか思い通りの挙動になりませんでした。一応はゲームの形にはなったのですが、テトリミノの当たり判定が変だったり、落下スピードが異常に速い、回転させても2種類の向きにしかならなかったりと、なかなか思い通りの挙動になりませんでした。

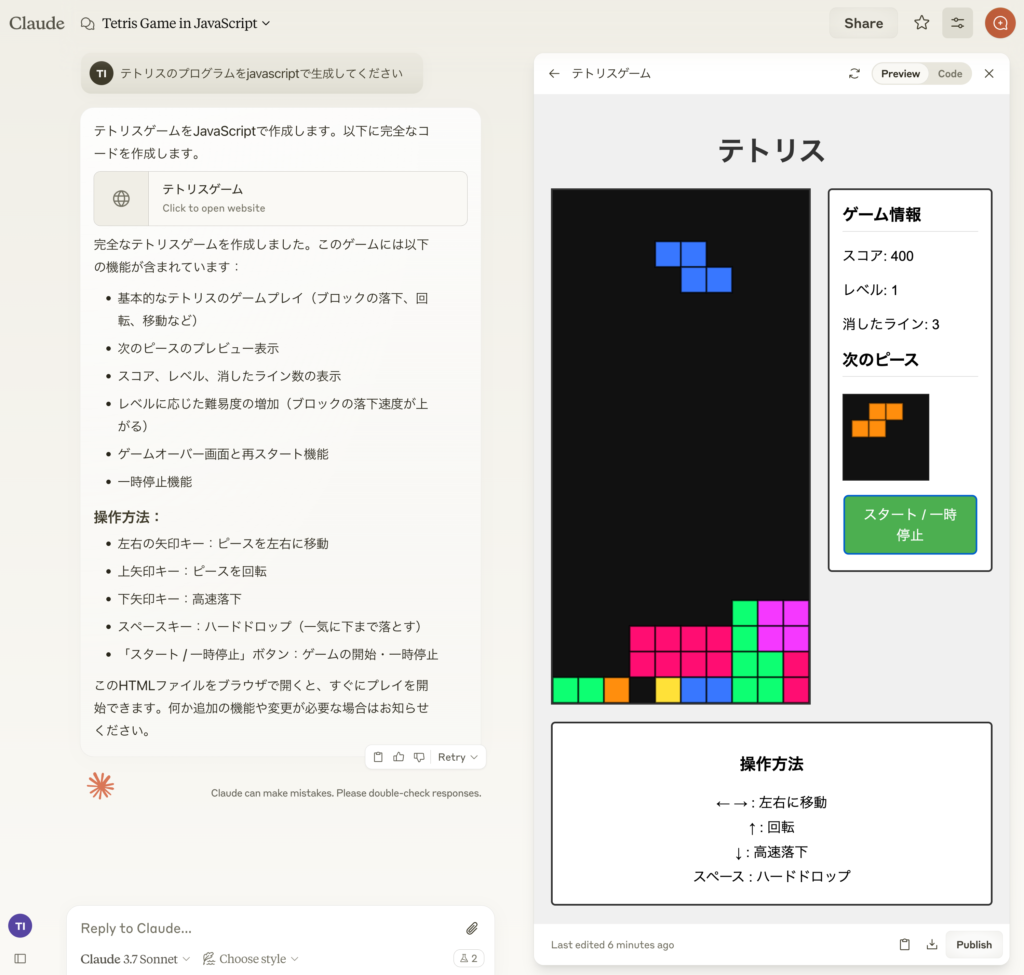
一方で、Claudeで同様のコードを生成したところ、Mercury Coderよりも一度の生成時間は長かったですが、一発で完成されたコードが生成されました。流石に性能に関しては、まだClaudeには及ばないようです。
Large Language Diffusion with mAsking (LLaDA)
さて、Mercury Coderの性能はともかく、その技術の基礎となっていると思われる拡散言語モデルについて詳しく見ていきましょう。通常の言語モデルは、これまでの文章を元に次の単語(トークン)を予測するという自己回帰モデルというアプローチを取っています。
次のトークン予測による文章生成のイメージ動画は上記のようになります。次に来る単語を予測して順次並べることで生成していく。この動作イメージはClaudeで生成しました、簡単な指示でこのような動作イメージの動画を生成できるのは便利です。
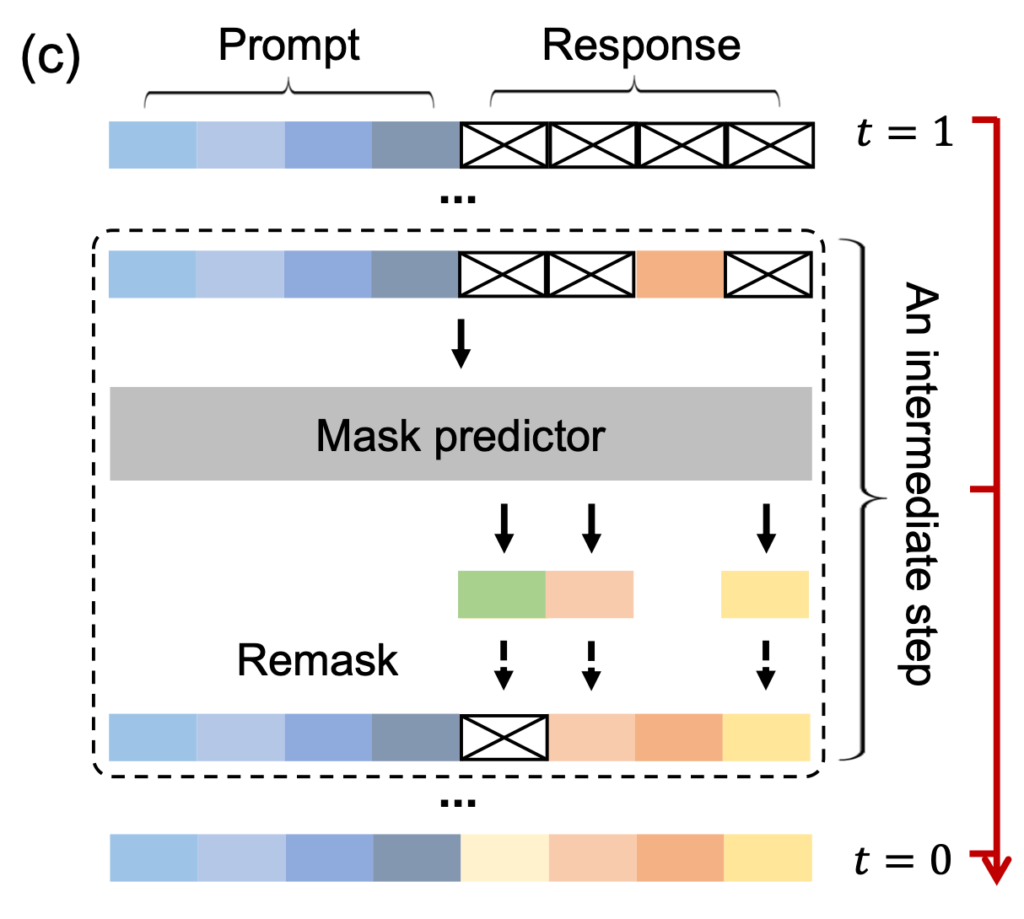
拡散言語モデルの一種であるMasked Diffusion Modelは、ランダムにマスクされた単語を予測することで、文章を生成していきます。予測された単語の確信度が高い場合は、その単語を確定させます。こうすることで、ステップを重ねるごとにマスクされる単語は減っていき、最終的に文章が完成されます。一度に複数の単語を確定させることで、通常の言語モデルよりも高速に文章を生成することが可能です。このLLaDAの動作イメージを見ると回答のコアとなる箇所は早く、具体的な計算の数値などは後のステップで確定していく様子が見て取れます。

LLaDAの学習プロセス
LLaDAの学習方法については、事前学習と教師あり学習による追加学習の2段階からなります。LLaDAのモデル構造は、80億のパラメータを持つ、Transformerベースのモデルです。まず、事前学習では、様々な割合でランダムにマスクされたトークンを復元するタスクを学習します。事前学習では、2.3兆トークンの大規模学習データセットを元に学習しました。4096トークンの入力長に固定して、計算量としてはH800 GPUを13万時間かけて学習されました。
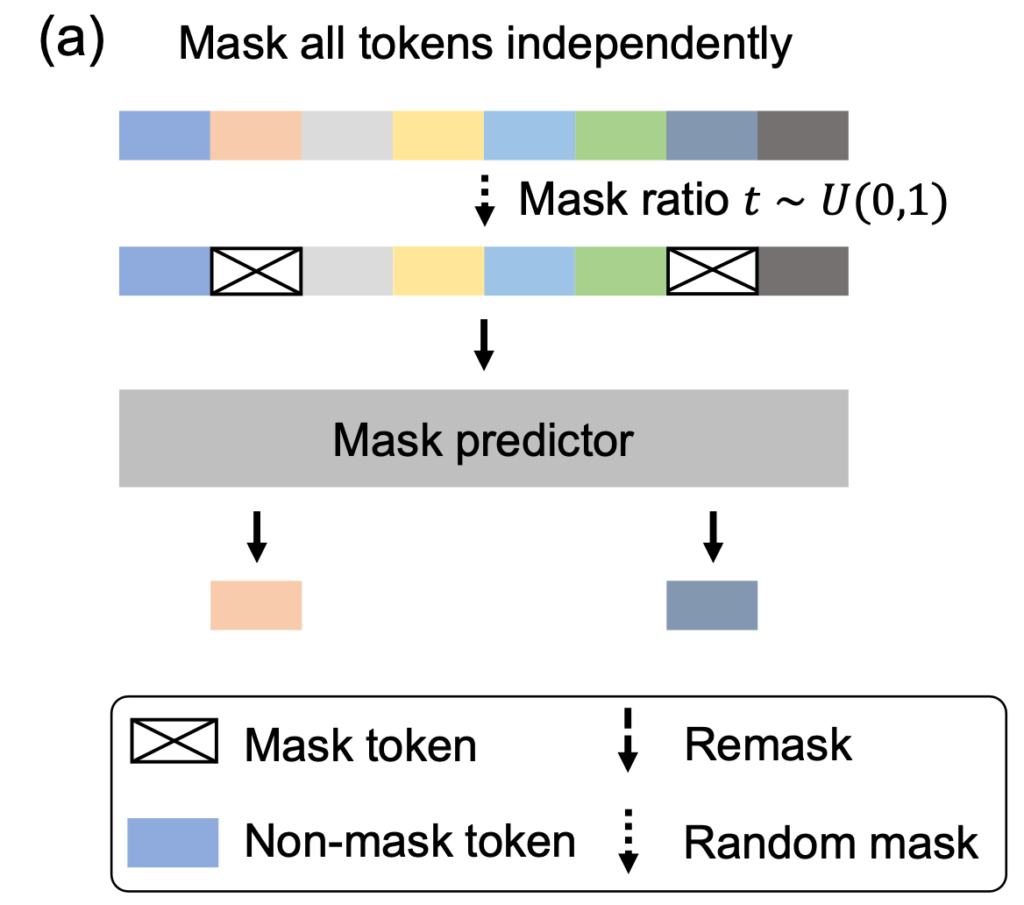
次の教師付き学習の段階では、事前学習によって得られたモデルに対して、プロンプトと応答のペアで追加学習をします。このプロンプトの箇所はマスクせずに応答部分のみをマスクして復元するタスクを学習します。LLaDA 8Bはこのタスクのために、450万の応答のペアを用いて学習しました。
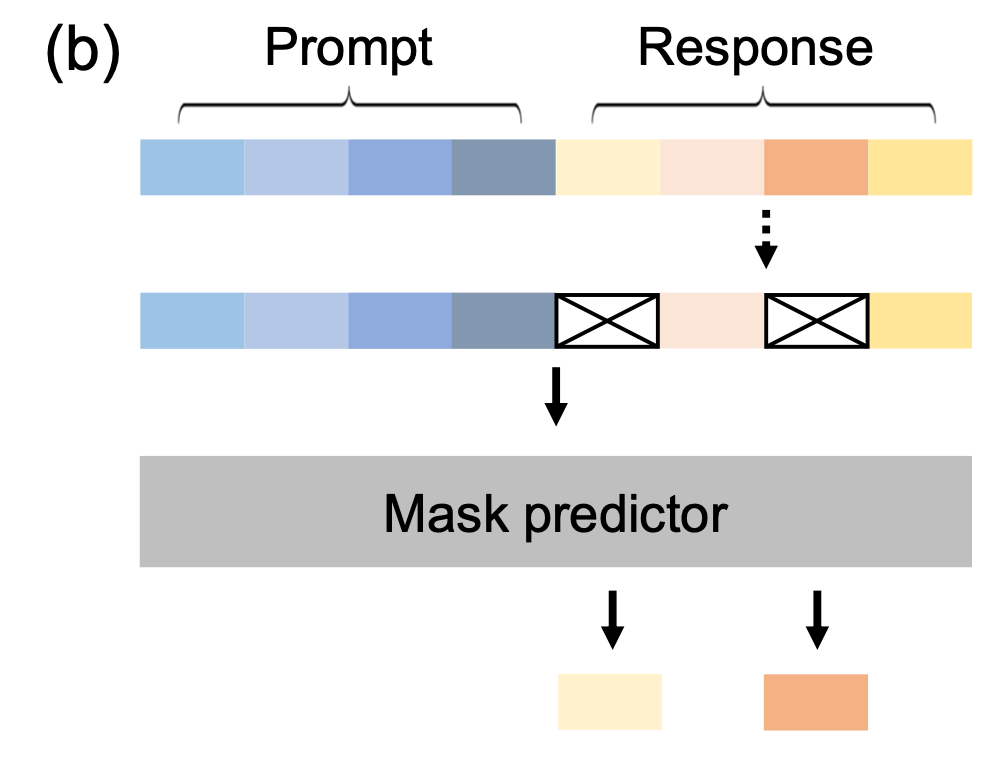
そして、実際のLLaDAの生成(推論)プロセスは以下のようになっています。与えられたプロンプトに対して、最初は完全にマスクされた応答の状態でスタートします。高い確信度の場合はそのままトークンを復元し、低い確信度のトークンは再度マスクして生成するプロセスを繰り返すことで、最終的に文章を生成していきます。
LLaDAの性能評価と「逆転の呪い」
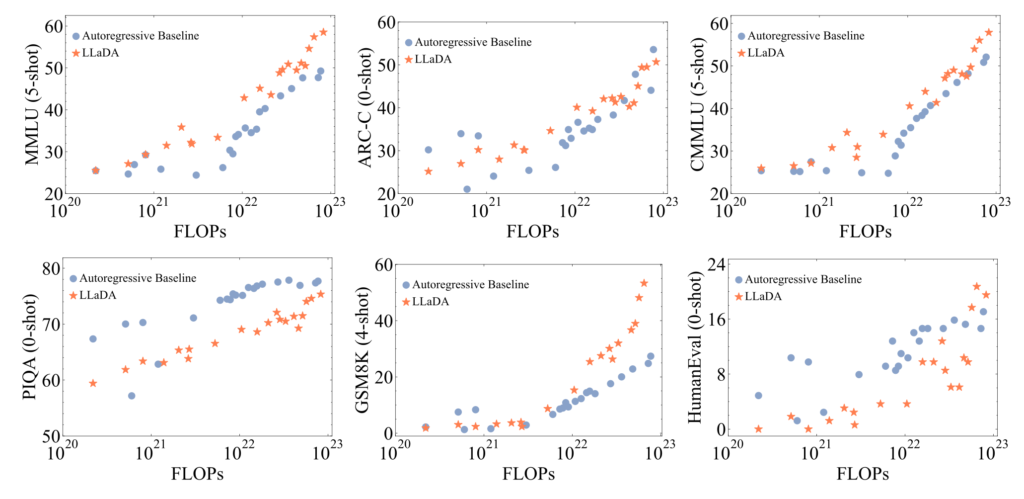
LLaDA 8Bの各種ベンチマークに対する性能を同等規模のモデルであるLLaMA 3 8Bおよび、LLaMA 2 7Bと比較した結果が以下の図になります。LLaDA 8Bは、LLaMA 2 7Bのパフォーマンスを大きく超え、LLaMA 3 8Bと同等程度の性能を達成しています。追加学習(Instruct)の結果で、LLaDA 8BがLLaMa 3 8Bの性能に遅れをとる点に関して、LLaDA 8Bが強化学習による追加学習を経ていない点が論文中では述べられていますが、その差がわずかであることも強調されています。


LLaDAの性能に関して興味深い実験結果が以下の図です。これは学習時間と共に性能がスケールしていることがわかります。このようなスケーリング則が拡散大規模言語モデルでも成り立つことが示唆されることから、今後の更なるスケールアップによる性能向上が期待されます。
通常の生成AIが文章を頭から順々に生成することに関して、「Reverse curse(逆転の呪い)」という問題が知られています。
これは「AがBである」という文章を学習しても、「BがAである」ということの理解が難しいという問題です。以下は、Reversal Curseの例として、LLMが「Tom Cruise’s mother is Mary Lee Pfeiffer」(A→B)という文章を学習した場合に、A→Bへの推論である「Who is Tom Cruise’s mother?」という質問に対して「Mary Lee Pfeiffer」と答えることができます。しかし、逆のB→Aへの推論が必要な「Who is Mary Lee Pfeiffer’s son?」という質問に対して「Tom Cruise」と答えることができないという問題が示されています。

LLaDAでは、Reversal Reasoningのパフォーマンスに関して、中国詩のデータを用いて、以下の例のような順方向と逆方向での予測タスクを実施しました。
- 順方向の推論 「窈窕淑女 君子好逑」
- Prompt: 窈窕淑女的下一句是什么?直接输出句子即可。(「窈窕淑女」に続く句は何ですか?文を直接出力してください。)
- Answer: 君子好逑。(「君子好逑」)
- 逆方向の推論 「我劝天公重抖擞 不拘一格降人才」
- Prompt: 不拘一格降人才的上一句是什么?直接输出句子即可。(「不拘一格降人才」の前の文は何ですか?文を直接出力してください。)
- Answer: 我劝天公重抖擞。(「我劝天公重抖擞」)
その結果が以下の表となります。GPT-4oやQwen2.5が逆方向でパフォーマンスを大幅に落としたのに対して、LLaDAはスコアとしてはGPT-4oやQwen2.5に敵わないものの逆方向の推論においてパフォーマンスの低下が軽微であることが示されています。
LLaDAを動かしてみる
LLaDAのモデルはHuggingFaceで公開されているので、transformer libraryを使って以下のように簡単に利用が可能です。
from transformers import AutoModel, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained('GSAI-ML/LLaDA-8B-Base', trust_remote_code=True)
model = AutoModel.from_pretrained('GSAI-ML/LLaDA-8B-Base', trust_remote_code=True, torch_dtype=torch.bfloat16)
実際の文章生成ロジックは通常の順次生成するモデルと異なります。公開されているコードの該当する箇所(generate https://github.com/ML-GSAI/LLaDA/blob/main/generate.py#L44-L107)を抜粋すると以下のように確証度の低いトークンを再度マスキングして生成するプロセスを繰り返しています。
for num_block in range(num_blocks):
block_mask_index = (x[:, prompt.shape[1] + num_block * block_length: prompt.shape[1] + (num_block + 1) * block_length:] == mask_id)
num_transfer_tokens = get_num_transfer_tokens(block_mask_index, steps)
for i in range(steps):
mask_index = (x == mask_id)
if cfg_scale > 0.:
un_x = x.clone()
un_x[prompt_index] = mask_id
x_ = torch.cat([x, un_x], dim=0)
logits = model(x_).logits
logits, un_logits = torch.chunk(logits, 2, dim=0)
logits = un_logits + (cfg_scale + 1) * (logits - un_logits)
else:
logits = model(x).logits
logits_with_noise = add_gumbel_noise(logits, temperature=temperature)
x0 = torch.argmax(logits_with_noise, dim=-1) # b, l
if remasking == 'low_confidence':
p = F.softmax(logits.to(torch.float64), dim=-1)
x0_p = torch.squeeze(
torch.gather(p, dim=-1, index=torch.unsqueeze(x0, -1)), -1) # b, l
elif remasking == 'random':
x0_p = torch.rand((x0.shape[0], x0.shape[1]), device=x0.device)
else:
raise NotImplementedError(remasking)
x0_p[:, prompt.shape[1] + (num_block + 1) * block_length:] = -np.inf
x0 = torch.where(mask_index, x0, x)
confidence = torch.where(mask_index, x0_p, -np.inf)
transfer_index = torch.zeros_like(x0, dtype=torch.bool, device=x0.device)
for j in range(confidence.shape[0]):
_, select_index = torch.topk(confidence[j], k=num_transfer_tokens[j, i])
transfer_index[j, select_index] = True
x[transfer_index] = x0[transfer_index]
簡単な実験をするために公開されているLLaDAのサンプルコードchat.pyをOpenAI o3-miniに投げてGradioによるチャット・アプリを作成してみました。簡単なPoC用のデモアプリなら、あっという間に作成してくれるので随分と便利になりました。実験のために生成ステップ数を簡単に変更できるような機能を追加してみました。
実験として、LLaDAの論文にある例文で生成のステップ数を変えて実験してみました。LLaDAの論文にある例文で生成のステップ数を変えて実験してみました。ステップ数を少なくするほど、一度に生成される単語が多くなり生成スピードが上がりますが、生成される文章の品質が低くなります。逆にステップ数を増やすほど、生成される単語が少なくなり生成スピードが遅くなりますが、品質が高くなります。プロセスが異なるため通常のLLMとの単純な比較は難しいですが、Nvidia GeForce RTX 4090では、128ステップの場合数秒程度で文章は生成されました。

また、LLaDAの開発元は中国の研究グループですが、日本語での問答も可能です。
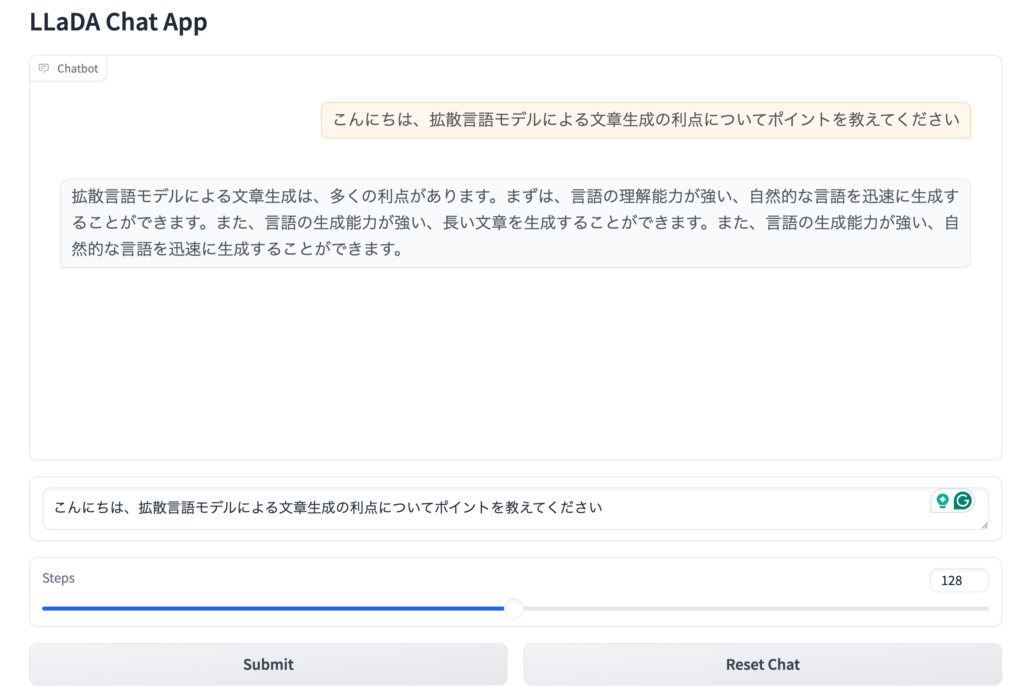
LLaDAですが関しては、8Bのモデルであることもあり、性能に関してはそれなりな感じです。強化学習による追加学習がないこともあるためか返答の品質はまだまだ改善の余地がありそうです。今後のスケールアップに期待しています。
まとめ
今回のブログでは、Inception LabsがリリースしたMercury Coderと、中国人民大学とAnt Groupが開発したLLaDAについて紹介しました。Mercury Coderは、拡散大規模言語モデル(dLLM)を用いることで、従来の生成AIよりも高速にコードを生成することが可能です。Mercury Coderの採用していると思われるMasked Diffusion ModelであるLLaDAは、技術詳細がarXivで発表されており、モデルやコードもHuggingFace・GitHubで公開されております。
LLaDA 8Bは同等規模のLLaMA 3 8Bに匹敵する性能を発揮しており、特に「逆転の呪い(Reversal Curse)」と呼ばれる問題に対しても、他の大規模言語モデルと比較して優れたパフォーマンス(相対的に性能低下しない)を発揮しています。これは、文章を頭から生成するのではなく、LLaDAが一度に文章全体を生成し、確信度の低いトークンを再度マスキングして生成するプロセスを繰り返すことで、双方向の推論が可能となっているためです。
拡散言語モデルによる文章生成はまだ比較的新しいアプローチであり、今後、拡散言語モデルのさらなるスケールアップや強化学習による追加学習の導入などの研究が進む可能性があります。また、Mercury Coderのような拡散言語モデルを用いたコード生成ツールの開発も今後の展望として期待されます。

さいごに
グループ研究開発本部 AI研究開発室では、データサイエンティスト/機械学習エンジニアを募集しています。ビッグデータの解析業務などAI研究開発室にご興味を持って頂ける方がいらっしゃいましたら、ぜひ募集職種一覧からご応募をお願いします。皆さんのご応募をお待ちしています。
参考資料
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD