2025.02.03
DeepSeek R1 and V3 〜OpenAI o1級のオープンモデルの作り方〜
TL;DR
- DeepSeekは、OpenAI-o1級の推論能力を持つ「DeepSeek-R1」を公開しました。DeepSeek-R1は、DeepSeek-V3-Baseを基に、複数回の教師あり学習と強化学習を組み合わせて学習したモデルで、パラメータ数は6710億にも及ぶオープンウェイトモデルです。さらに、知識蒸留した小型軽量モデルも6種類公開されています。
- DeepSeek-R1の基盤となった「DeepSeek-V3-Base」はMixture-of-Expert構造とMulti-Head Latent Attentionを採用したモデルです。効率的な学習方法を導入したことで、2048基のH800 GPUを用いて、約2ヶ月弱という短期間で学習しました。これをファインチューニングした「DeepSeek-V3」は、GPT-4o級の性能を発揮しています。(このGPU利用費用は約560万ドルと試算されており、これがDeepSeek-R1の開発費用と紹介されることもありますが、流石に過小評価です。)
- 一方で、DeepSeek-V3-Baseを純粋に強化学習のみで学習したモデルが「DeepSeek-R1-Zero」です。これはOpenAI-o1級のベンチマークスコアを達成しましたが、出力の可読性に課題がありました。「DeepSeek-R1」は、複数の教師あり学習と強化学習を組み合わることでこの問題点を解決してより高い性能を達成しました。
はじめに
こんにちは、グループ研究開発本部・AI研究室のT.I.です。2025年1月27日に、Nvidiaの株価が急落し、時価総額約91兆円近が失われました(中国のAI「DeepSeek」ショックでハイテク株がパニック売りに、NVIDIAの時価総額が91兆円消し飛んで暴落記録を2倍以上更新 )。これは中国のAI企業DeepSeekが開発したDeepSeek-R1がOpenAI-o1を超えるベンチマークスコアをOpenAIよりもはるかに低コストで達成した発表したことが原因とされています(DeepSeek-R1 Release)。DeepSeek-R1は、6710億パラメータを持つ生成AIで、MITライセンスで公開されているオープンウェイトのモデルです(Hugging Face DeepSeek-R1)。さらにDeepSeekは、このモデルを蒸留し、700億から15億パラメータまでの小型軽量モデルも公開しました。そのためOSSの界隈では、非常にインパクトがあるニュースとなりました。一方で、DeepSeekの個人情報保護方針やOpenAIのデータを学習に使用している疑惑なども浮上しており、今後の展開に注目が集まっています。
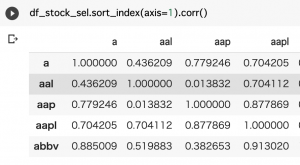
これらの議論はさておき、今回は、このDeepSeek-R1の技術的な詳細について解説します。DeepSeek-R1は、DeepSeek-V3-Baseをベースに開発されたモデルです。以前のブログ(OpenAI o1 pro mode でデータ分析してみた〜「Deliberative Alignment」による推論能力と安全性の強化〜)でで説明したように、 基本的にLLMは、大量のテキストデータによる事前学習と、その後のファインチューニング(教師あり学習+強化学習)を経て開発されます。そのような一般的なプロセスでDeepSeek-V3-BaseからチューニングされたモデルがDeepSeek-V3です。一方、強化学習のみで開発されたモデルがDeepSeek-R1-Zeroで、自己学習により高い推論能力を獲得したものの、出力が読みづらいという問題がありました。このDeepSeek-R1-Zeroの検証を踏まえて、教師あり学習と強化学習を複数回組み合わせて学習したものがDeepSeek-R1となります。そしてDeepSeek-R1の出力を元に蒸留で開発されたモデルが6種類にもわたるDeepSeek-R1-distilled modelsです。詳細は後述しますが、それぞれのモデルの関係性は以下の図の通りです。
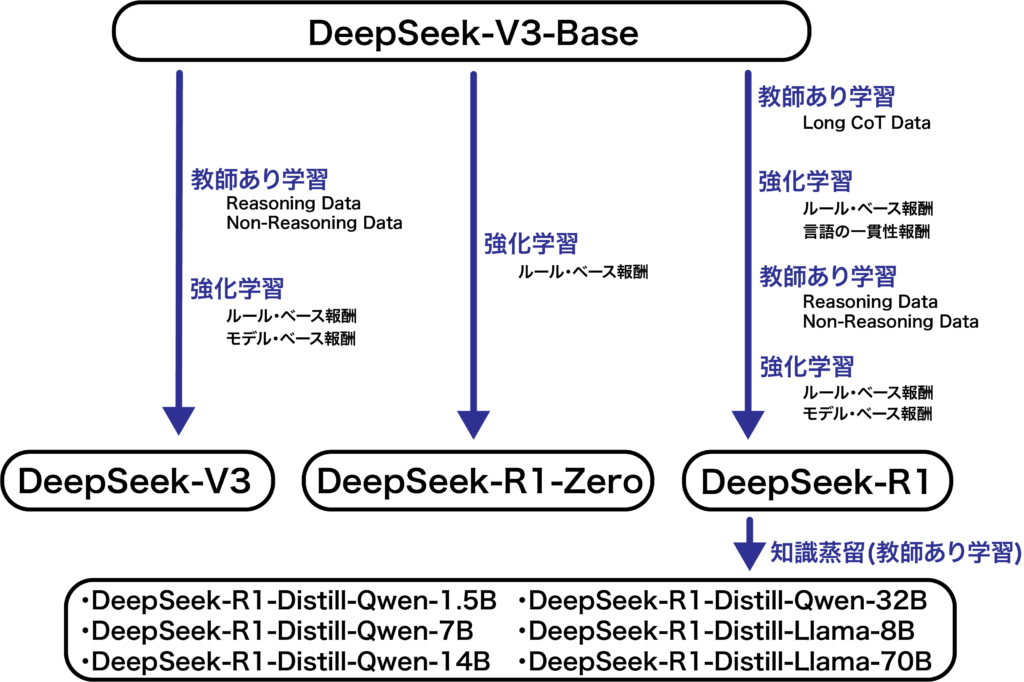
DeepSeek-R1は、モデルウェイトが公開されていますが、6710億のパラメータなので、FP16ならば単純換算して1.3TB級のメモリが必要となり、個人での利用は現実的ではありません。しかし、蒸留された軽量モデルであれば、簡単に利用可能です。お手軽に試したいのであれば、LM Studio がおすすめです。OpenAI-o1が途中の思考プロセスをユーザーから隠しているのに対して、DeepSeek-R1ではその考えている内容がすべて可視化されます。ただし、公開されている蒸留モデルでは、途中の思考が中国語や英語混じりになることがあります。自然な日本語での回答が欲しいのであれば、Cyber Agent の公開した日本語追加学習モデルがおすすめです(CyberAgent DeepSeek-R1-Distill-Qwen-32B-Japanese)。
DeepSeekMath
DeepSeek-R1の開発の前提となった強化学習技術がGroup Relative Policy Optimization (GRPO)です。これはDeepSeekが2024年2月に発表した「DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models」で導入された強化学習アルゴリズムです。より詳細については、こちらのブログ記事「LLMチューニングのための強化学習:GRPO(Group Relative Policy Optimization)」が参考になります。
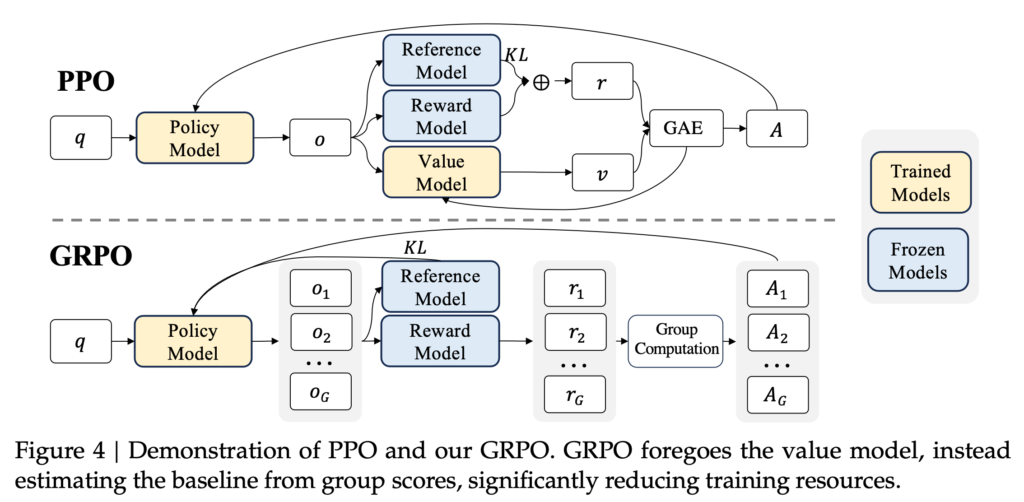
GRPOは、従来のProximal Policy Optimization (PPO)の改良版です。その比較が以下の図になります。Group Relative Policyという様に複数の出力結果をグループ化して評価します。PPOとの差異としては、Advantage の算出方法とReference ModelとのKL divergence での制約の追加、およびValue Modelの省略などが特徴です。
GRPOのAdvantageの計算では、報酬モデルの結果(\( r_i \))を正規化して評価しています。このように1つの質問(\(q\))に対する複数の出力結果(\(\{o_1, o_2, \dots, o_G\}\))をグループ化し評価することで性能を改善させています。
$$
\hat{A}_{i,t} = \tilde{r}_i = \frac{r_i – \mathrm{mean}(r)}{\mathrm{std}(r)}
$$
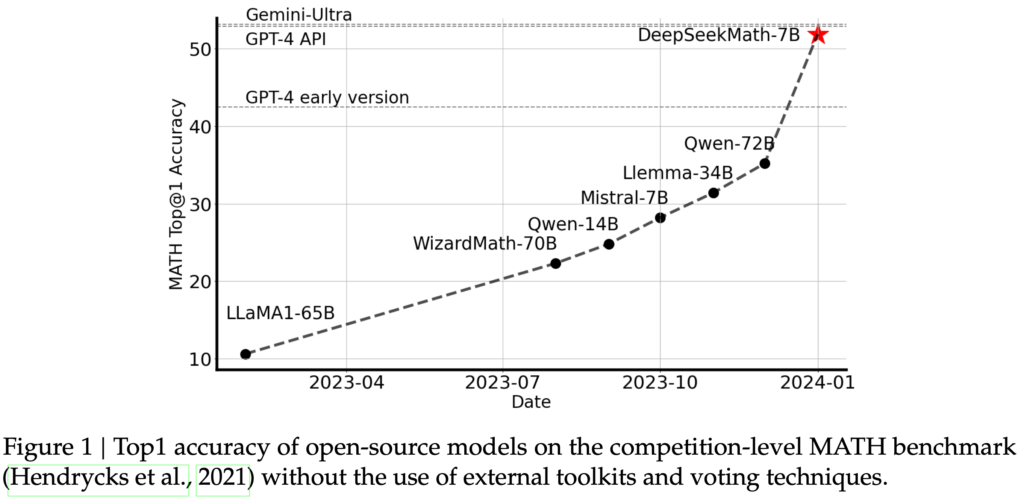
DeepSeekMathは、DeepSeek-Coder-Base-v1.5 7Bを1200億トークンのデータで学習しています。以下の図はMATHベンチマークの性能の比較です。DeepSeekMathは、70億パラメータでありながら、700億級のオープンモデルを超え、GPT-4並みの性能を発揮しています。
DeepSeek-V3 series
DeepSeek-R1のベースとなる事前学習モデルがDeepSeek-V3-Baseです。これをファインチューニングしたものがDeepSeek-V3であり、R1とV3は双子のような関係にあります。DeepSeek-V3は、2024年12月26日にリリースされました(Introducing DeepSeek-V3)。6710億パラメータのMixture-of-Experts(MoE)モデルで、実際のアクティブなパラメータは370億となっています。MoE構造のおかげで、巨大なパラメータ数を持ちながらも、高速な推論が可能です。
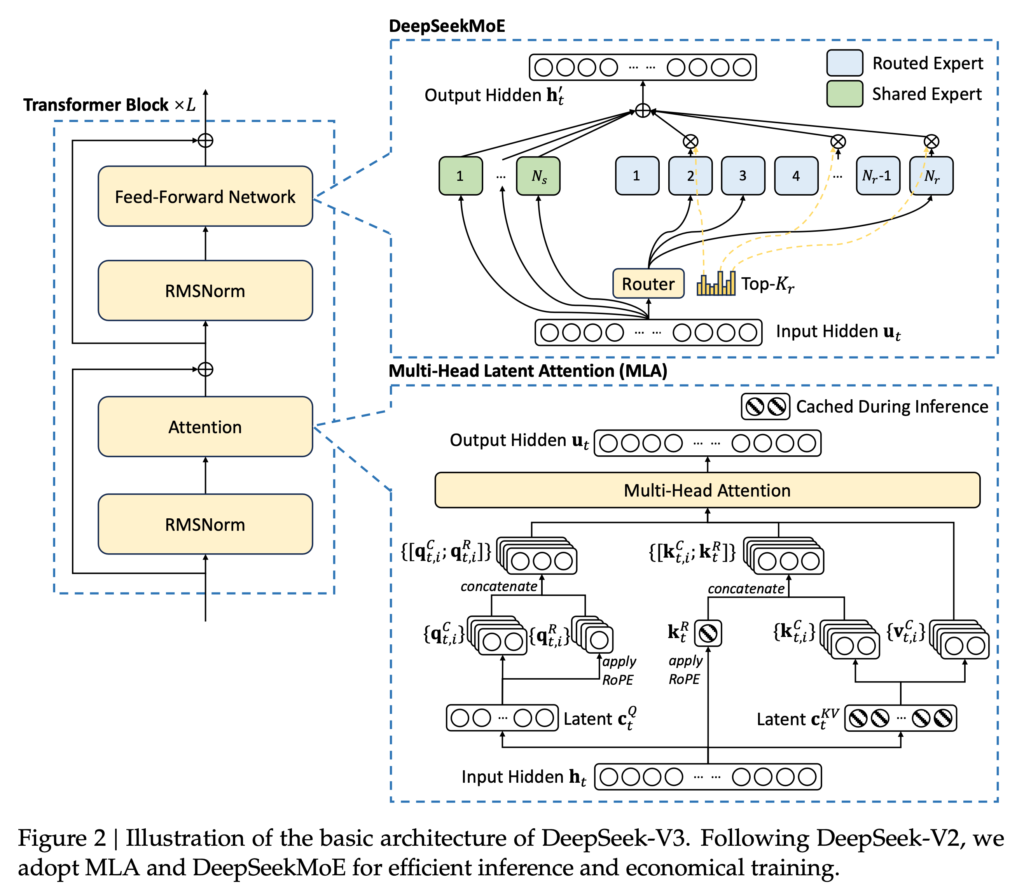
DeepSeek-V3の構造は以下の図の通りです。DeepSeekMoE構造とMulti-Head Latent Attention (MLA)という工夫が施されています。MoEは、複数のExpertのNeural Network を切り替える仕組みで、DeepSeekの独自のものではなく、既存の技術です。MLAは、DeepSeek-V2で導入されたもので、通常のTransformerのMulti-Head Attention (MHA)と比較して、Key-Value cacheのサイズを縮小してボトルネックを解消する技術です。これは入力をより低次元のlatent spaceに圧縮することでより効率的な学習が可能となります。(DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model)。
更に、DeepSeekは学習方法を効率化する様々な工夫を施すことで、H800 GPUで約279万時間の学習でGPT-4oを超えるパフォーマンスを達成しました。
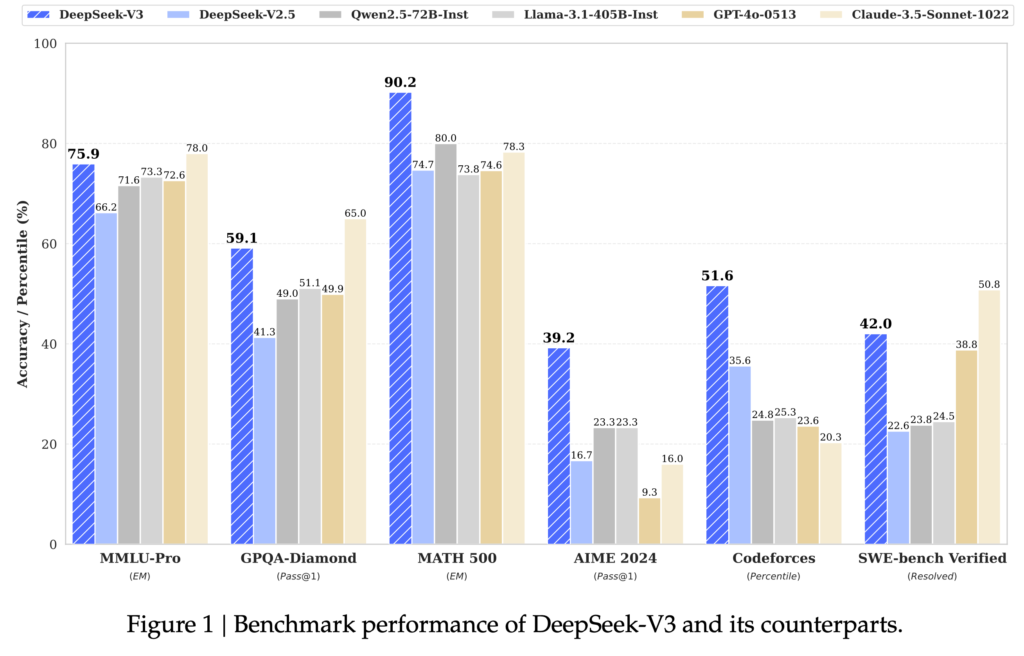
GPT4-oやClaude-3.5-Sonnetを超えるベンチマークスコアもすごいのですが、特筆すべきは学習コストの大幅な削減です。DeepSeekは、輸出規制により性能が制限されたH800 GPUを使用しています。DeepSeek-V3の学習では、2048基のH800 GPUを2ヶ月弱使用しました。これは約279万GPU時間に相当します。これをGPUのコストとして一時間あたり2ドルとして概算すると、事前学習には約533万ドル、ファインチューニングも諸々含めると全体では約560万ドルとなります。ニュースなどで、「DeepSeek-R1が600万ドルで開発された」と報じられている金額の根拠はここにあると思われます。ただし、これはGPUの計算コストのみであり、研究開発の試行錯誤、設備、人件費などを考慮すると、実際の開発費はこのような金額よりもはるかに高額になると思われます。

H800は、H100と比較してチップ間の通信が半分程度に制限されているそうです。それによる具体的な性能がどの程度低下するのか不明ですが、H100で同じ学習を実施するコストを概算してみます。ConoHa VPSのレンタルGPUサーバーでは、H100 GPUが1台あたり1ヶ月582,010円なので、2048台では約12億円/月となります(ConoHa VPSGPUサーバー)。H100の方が高性能ですが、半分の1ヶ月で終わるとは考えにくいのでもう少しのコストが必要だと思いますが、DeepSeekのGPUコストの見積もり600万ドル(約9億円)を考えると、GPUの利用コストに関しての規模感としては妥当なものと思われます。
DeepSeek-V3-Base
DeepSeek-V3-Baseは、事前学習のみを行ったモデルで、ファインチューニングは施されていません。先述の学習コストの表にある通り、この事前学習のプロセスがコストの大半を占めています。DeepSeek-V3-Baseの学習では、MoEでExpert間のバランスが取れるように「Auxiliary-Loss-Free Load Balancing」という手法を導入しています。また、通常のLLMでは、1つ次のトークンを予測するタスクを学習しますが、DeepSeek-V3では、Multi-Token Predictionという複数のトークン予測のタスクを実施します。
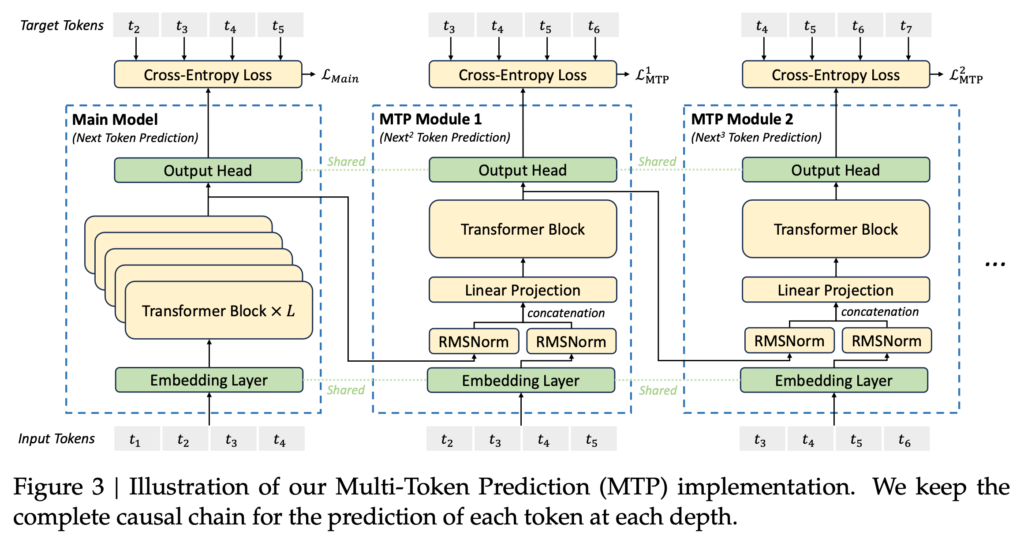
更に、学習コストの削減のために、一部の計算をFP8(低精度少数)で実施していますが、計算精度の低下を防ぐために、高精度数値との混合計算にさまざまな工夫を施しています。他にもハードウェアなどの諸々の工夫により、DeepSeek-V3-Baseは非常に効率的な学習プロセスを達成しています。事前学習では4.8兆トークンの高品質データセットを使用して、H800 GPUで合計266万時間分学習した結果が、DeepSeek-V3-Baseとなります。
DeepSeek-V3
DeepSeek-V3-Baseを更にファインチューニングしたものがDeepSeek-V3となります。このファインチューニングの過程で、「DeepSeek-R1」の出力を流用した知識蒸留も行なっています。唐突にDeepSeek-R1が現れ、「なぜお前が今ここに」と混乱するのですが、テクニカルレポートには「one of the DeepSeek-R1 series models」や「an internal DeepSeek-R1 model」という記述となっているので、実際に公開されているDeepSeek-R1とは別の内部モデルである可能性が高いです。というのも後述するようにDeepSeek-R1は、DeepSeek-V3の出力を一部学習データとして使用しており、DeepSeek-R1(公開版)は、DeepSeek-V3の後に開発されたはずなので因果関係が逆転してしまいます。DeepSeek-V3のファインチューニングは、教師あり学習と強化学習の2つのステップで行われています。一般的なLLMの学習では指示データセットによる教師あり学習と選好データセットによる強化学習(DPO)をすることが多いですが、DeepSeek-V3の学習データと強化学習では以下のような特徴があります。
教師あり学習
ファインチューニングの最初のステップは教師あり学習です。教師あり学習のためのデータセットは、DeepSeek-R1(仮)で生成した数学やコードの問題といった推論データと、DeepSeek-V2.5で生成して抽出した非推論データを利用しています。
強化学習
次の強化学習のステップでは、後述するDeepSeek-R1-Zeroと同様に、数学の問題などの正解が明確な問題に対してはルールベースの報酬モデルを採用し、そうでない場合は、別途報酬モデルを作成(DeepSeek-V3 SFTモデルを元に)しています。強化学習では、DeepSeekMathで導入されたGRPOを利用します。
DeepSeek-R1 series
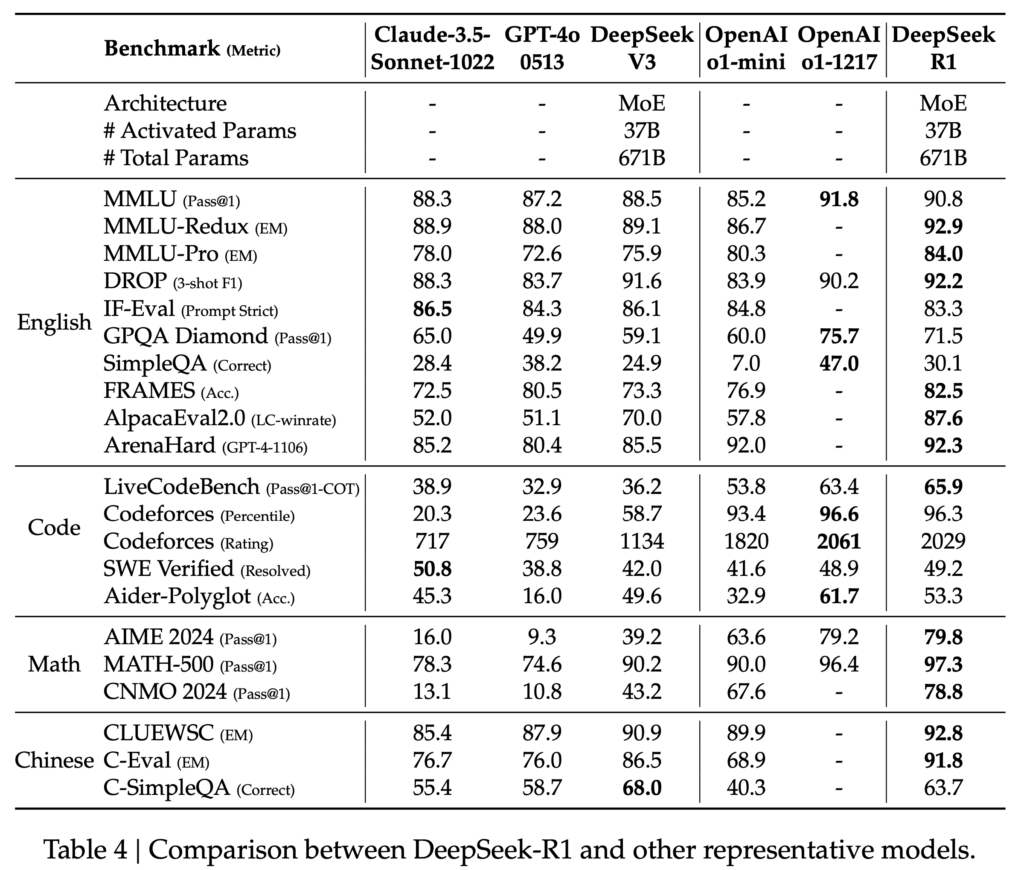
DeepSeek-R1は、2025年1月20日にリリースされました(DeepSeek-R1 Release)。OpenAI o1を超えるベンチマークのスコアを記録したこと話題になりました。以下はDeepSeek-R1とOpenAI-o1などとの比較です。DeepSeek-R1は、DeepSeek-V3よりも大幅にスコアを伸ばしており、各ベンチマークに対してOpenAI-o1-1217に匹敵もしくは上回るスコアとなっております。先ほど紹介したDeepSeek-V3のパフォーマンスが、随分低く見えますが、DeepSeek-V3のベンチマークの比較では、GPT-4oやClaude-3.5-Sonnetまでで、OpenAI-o1は含まれてませんでした。

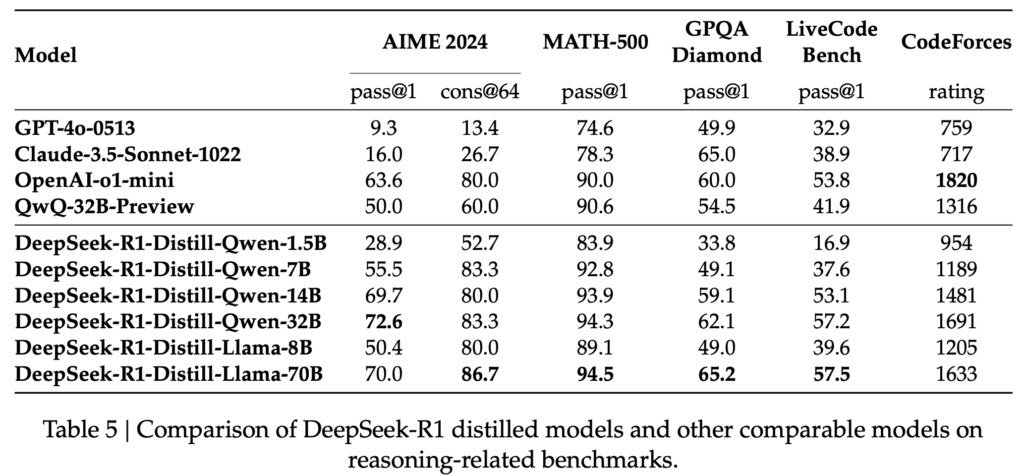
また、DeepSeek-R1を蒸留した小型モデルも同時に公開しました。これらのモデル(DeepSeek-R1-Distill-xxx)は700億から15億パラメータまでの6種類が提供されており、その性能は以下の通りです。

DeepSeek-R1の利用コストも注目されています。以下は、DeepSeek-R1のAPIの利用コストですが、OpenAI-o1のAPIの利用コストの約3%程度で圧倒的なコストパフォーマンスを誇っています。Input API PriceにあるCache HitとCache Missとは、複数ラウンドの対話時に、以前の入力をキャッシュしているかどうかの違いです。

DeepSeek-R1-Zero and Aha Moment
DeepSeek-R1-Zeroは、純粋に強化学習のみで推論能力を向上させたモデルです。「Zero」という名称は、同様に強化学習のみで開発したDeepMindの囲碁AIであるAlphaGo Zeroに因んでいると思われます。DeepSeek-R1-Zeroは、DeepSeek-3-Basedをベースに先ほど紹介したGRPOで強化学習を施します。強化学習の報酬モデルとしてDeepSeek-R1-Zeroでは、以下の2種類のルールベースのモデルを採用しています。
- Accuracy rewards
- Format rewards
前者のAccuracy rewardsというのは、数学の問題が正しく回答できているか、codingなら正しい結果が得られているか?とういう正確性に関する報酬です。後者のFormat rewardsというのは、思考のプロセスを<think>と</think>で囲まれた部分で実行しているか?という報酬です。DeepSeekでは、Neural Networkの報酬モデルを採用すると、強化学習がそのモデルに最適化されすぎる問題や、別途報酬モデルを訓練する必要があるため、このようなルールベースモデルを採用したとしています。
DeepSeek-R1-Zeroのプロンプトのテンプレートは以下のようにシンプルなものとなっています。これを元に推論能力を強化するための強化学習が行われています。

DeepSeek-R1-Zeroのモデルのベンチマークスコアは以下の通りです。数学などの問題解決能力においてはOpenAI o1に同等以上のスコアを記録しています。
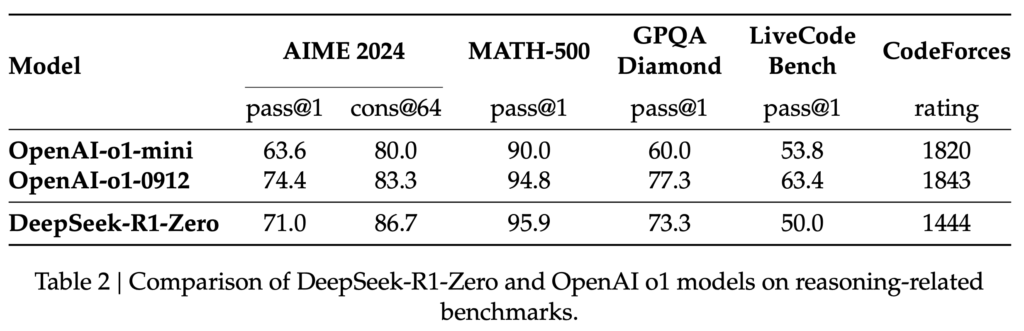
DeepSeekは、DeepSeek-R1-Zeroの重要なポイントとして、Aha moment (意訳:なんか分かった!)に達したと報告しています。これは思考の途中でDeepSeek-R1-Zeroが、問題解決のためには更なる思考が必要であることに気がついて、再度問題を1から考えることを指しています。

このように学習したDeepSeek-R1-Zeroですが、推論能力確かに高いものの、出力結果が読みにくかったり、言語が混在するなどの問題がありました。
DeepSeek-R1
DeepSeek-R1-Zeroの実験を踏まえて開発されたのが、DeepSeek-R1です。R1の開発は以下の様な複数の教師あり学習・強化学習のパイプラインを経ています。
1. CoTデータによる教師あり学習
最初のステップでは、DeepSeek-B3-BaseをChain-of-Thought (CoT)のデータで教師あり学習を行います。このCoTデータは、few-shot プロンプトで生成させたり、DeepSeek-R1-Zeroの出力を修正したりなどで生成し合計数千件のデータで学習を行います。これらは推論ステップとまとめを区切るトークンでより読みやすく工夫されています。
2. 推論能力強化のための強化学習
次のステップでは、DeepSeek-R1-Zeroで実施したような強化学習です。これは正解の明確な問題に対しては報酬を与える学習ですが、この途中で、言語が混在する問題が発生するため、言語の一貫性報酬を追加導入しています。この追加報酬の結果、若干性能は下がるそうですが、その分、生成される文章の読みやすさは改善されるとのことです。
3. Rejection Samplingによる教師あり学習
ここまでのステップで学習されたモデルを使用して学習データを生成して、教師あり学習を実施します。推論データに関しては、ルールベースおよびDeepSeek-V3に判定して抽出させた60万件のデータセットを作成します。非推論データに関しては、DeepSeek-V3で利用した学習データセットの一部やDeepSeek-V3で生成したデータを利用した20万件、合計80万件のデータセットで教師あり学習を行います。
4. 強化学習
そして、最後に更に追加の強化学習を実施します。推論データに関しては、DeepSeek-R1-Zeroと同様にルールベースの報酬を与え、一般のデータに関しては、別途報酬モデルを訓練して採用します。
以上のプロセスを経て、DeepSeek-R1のパフォーマンスは以下の通りです。幾つか欠損している項目もありますが、OpenAI o1と同等以上のスコアを記録しています。
DeepSeek-R1-distilled models
DeepSeek-R1の学習は以上で完了ですが、更にDeepSeek-R1の出力を元にした小型の蒸留モデルも開発されています。基となったモデルはそれぞれQwen2.5-Math-1.5B、Qwen2.5-Math-7B、Qwen2.5-14B、Qwen2.5-32B、Llama-3.1-8B、Llama-3.3-70B-Instructの合計6種類です。蒸留ではDeepSeek-R1の出力を元に抽出した800kのデータセットで教師あり学習を行います。
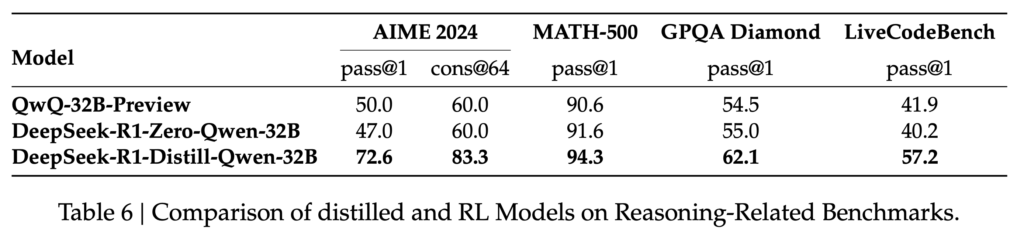
蒸留ではなく、DeepSeek-R1-Zeroのような強化学習のみで小型モデルが開発できるのでは?と考えるかもしれません。DeepSeekはQwen-32B-Baseを元に推論で強化学習の検証も実施しています。その結果は以下の表ですが、R1-Zeroの方式で強化学習した場合、元のモデルからの性能は殆ど改善していません。この点から、強化学習のみによるモデルの改良はDeepSeek-V3-Baseのような巨大なモデルでないと難しいことが分かります。
まとめ
今回はDeepSeekの開発したDeepSeek-R1について、その背景となったモデルについて解説しました。DeepSeek-V3に関してはモデルの詳細やハイパーパラメータなどの詳細な技術レポートが公開されており、開発コストの600万ドルという数字には疑問がありますが、非常に参考になる内容です。また、強化学習のみで開発されたDeepSeek-R1-Zeroや、そこから発展したDeepSeek-R1の開発プロセスも推論性能を向上させるための工夫が施されていることが分かりました。DeepSeek-R1や小型蒸留モデルはMITライセンスで公開されており、今後の研究開発に活用できそうです。
しかしながら、DeepSeekは、DeepSeek-R1のテクニカルレポートを公開しておりますが、読んでいて感じたのは具体的な学習データや報酬モデルなどの詳細は明かされず、説明が抽象的な部分が多い印象があります。この点に関してOpen-R1(Open-R1: a fully open reproduction of DeepSeek-R1)というプロジェクトでは完全にオープンな形でDeepSeek-R1の再現を目指しています。このような試みを通じてOpenAIなどのクローズドな研究ではなく真にオープンな形でLLMの研究開発が今後進んでいくことが期待されます。
さいごに
グループ研究開発本部 AI研究開発室では、データサイエンティスト/機械学習エンジニアを募集しています。ビッグデータの解析業務などAI研究開発室にご興味を持って頂ける方がいらっしゃいましたら、ぜひ募集職種一覧からご応募をお願いします。皆さんのご応募をお待ちしています。
参考資料
- 「中国のAI「DeepSeek」ショックでハイテク株がパニック売りに、NVIDIAの時価総額が91兆円消し飛んで暴落記録を2倍以上更新 」
- 「DeepSeek-R1 Release」
- 「Hugging FaceDeepSeek-R1」
- 「DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning」
- 「OpenAI o1 pro mode でデータ分析してみた〜「Deliberative Alignment」による推論能力と安全性の強化〜」
- 「LM Studio」
- 「CyberAgent DeepSeek-R1-Distill-Qwen-32B-Japanese」
- 「DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language」
- 「Introducing DeepSeek-V3」
- 「DeepSeek-V3 Technical Report」
- 「DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model」
- 「ConoHa VPS」
- 「Open-R1: a fully open reproduction of DeepSeek-R1」
- DeepSeek-R1に関連した技術に関する解説資料
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD