2022.07.08
KubernetesのPodのメトリクスによるアラート通知
TL;DR
- Webサービス監視にKubernetesが提供するメトリクスを利用できる
- メトリクスにアラートを設定してシステム内に異常を検知したらSlackに通知できる
はじめに
こんにちは。次世代システム研究室のT.Tです。
前回の記事でkube-prometheus-stackのアーキテクチャと現在開発運用に携わっているサービスに導入して解決したい問題についてご紹介しました。本記事ではKubernetesで稼働しているWebサービスのPodのメトリクスを収集して、異常検知用のアラートを設定する部分をご紹介します。
1.GrafanaでPodのメトリクスを確認
GrafanaのサービスをNodePortに変更してkube-prometheus-stackを開発環境にインストールします。インストール後にGrafanaにログインするとダッシュボードのKubernetes / Compute Resources / PodでPodのメトリクスを確認できます。
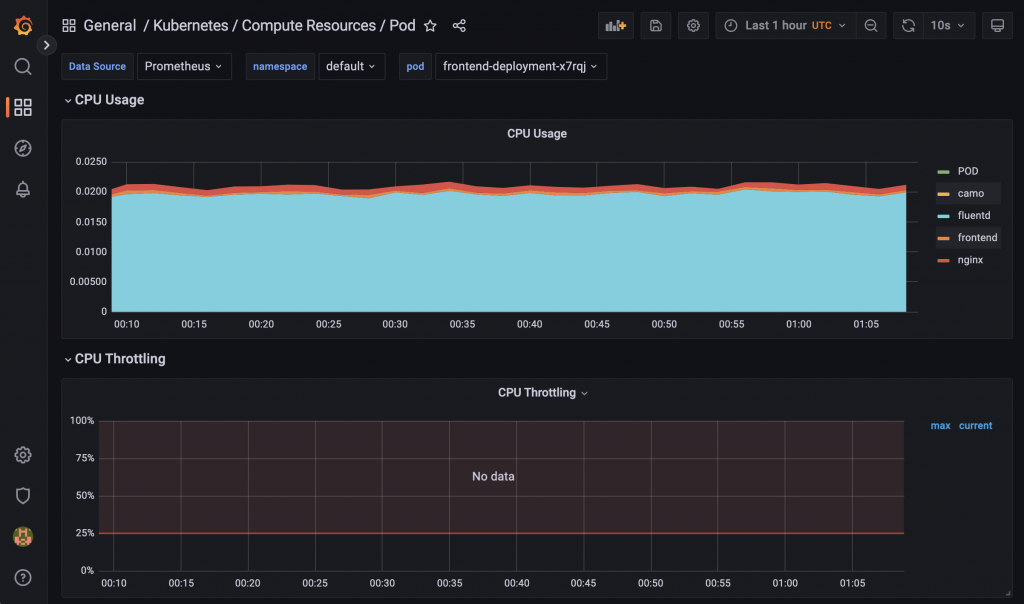
2.Kubernetesからのメトリクスの取得
kube-prometheus-stackをインストールしただけでPodのメトリクスを取得できましたが、3年程前にPrometheusを検証した際はcAdvisorの設定が必要でした。以前検証した時から大分時間が経っているのでその辺の状況を改めて確認してみました。
Kubernetesのメトリクスに関する仕様はMetrics For Kubernetes System Componentsに書かれていました(今回の検証ではKubernetesのバージョンは1.21を使っています)。このドキュメントによるとkubeletの/metrics/cadvisorからメトリクスが取得できるようです。このドキュメントだけだとはっきりとは分からないですが、Podのメトリクスが/metrics/cadvisorから取得できて、kubeletはデフォルトで/metricsエンドポイントが有効になっているようです。
他のKubernetesのコンポーネントもメトリクスが取得できるようになっているようです。ダッシュボードのKubernetes / API Serverでkube-apiserverのメトリクスが確認できます。kube-apiserverは–bind-address引数を付けて起動するとメトリクスが取得できるようで、コンテナ内で起動引数を確認すると–bind-addressが指定されていてメトリクスが取得できているようです。
sh-5.0# ps -ef | cat root 1 0 4 Jul06 ? 00:28:59 kube-apiserver ... --bind-address=0.0.0.0 ...
また、Kubernetes / Compute Resources / PodのCPU Usageのパネルの編集画面を表示するとMetrics browserのところにPromQLが定義されていて、この内容を元にグラフが描画されていることが確認できます。
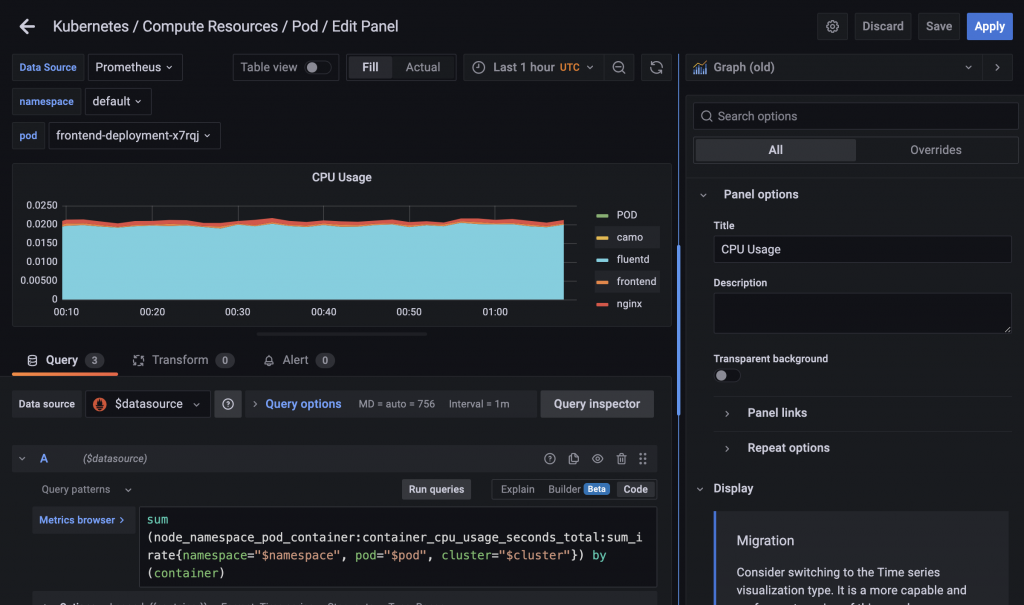
このパネルの定義はkube-prometheus-stackのマニフェストに書かれていて、helmでエクスポートしたマニフェストのConfigMapのk8s-resources-pod.json内に定義されていることが確認できます。
kind: ConfigMap
...
data:
k8s-resources-pod.json: |-
...
"targets": [
{
"expr": "sum(node_namespace_pod_container:container_cpu_usage_seconds_total:sum_irate{namespace=\"$namespace\", pod=\"$pod\", cluster=\"$cluster\"}) by (container)",
...
...
このConfigMapを更新すればメトリクスの内容を更新できます。
メトリクスを取得する仕組みと構成が概ね把握できたので次はアラートの設定に移ります。
3.アラートの設定
3.1.通知先の設定
アラートを設定するためにまずアラートの通知先を設定します。メニューのAlerting > Contact points > New contact pointで通知先を設定できます。今回の検証ではSlackに通知する設定を追加します。
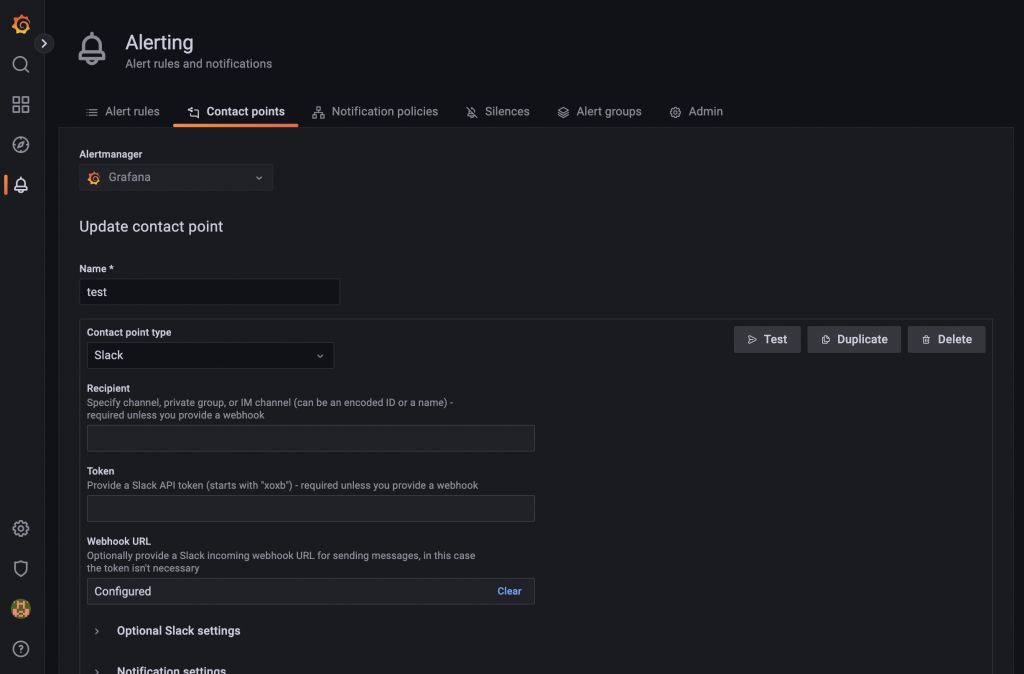
次に通知のポリシーを設定します。Notification policiesから設定できます。今回の検証ではアラート状態になったものを全て通知する設定にします。
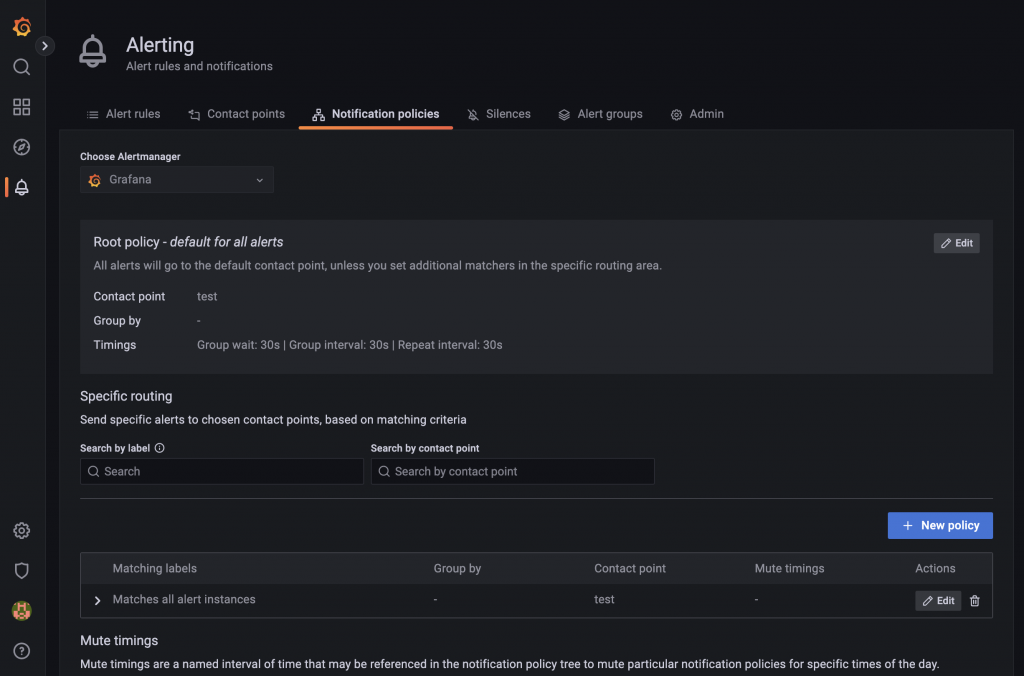
3.2.アラートの設定
通知の設定が出来たのでアラートを設定します。アラートの設定はダッシュボードのパネルから設定すると分かり易いので、Kubernetes / Compute Resources / PodのCPU Usageパネルから設定してみます。パネルの編集画面にAlertタブがあるので、そのタブを選択してCreate alert from this panelでアラートを作成します。検証用に常にアラートが出る条件に設定してみます。
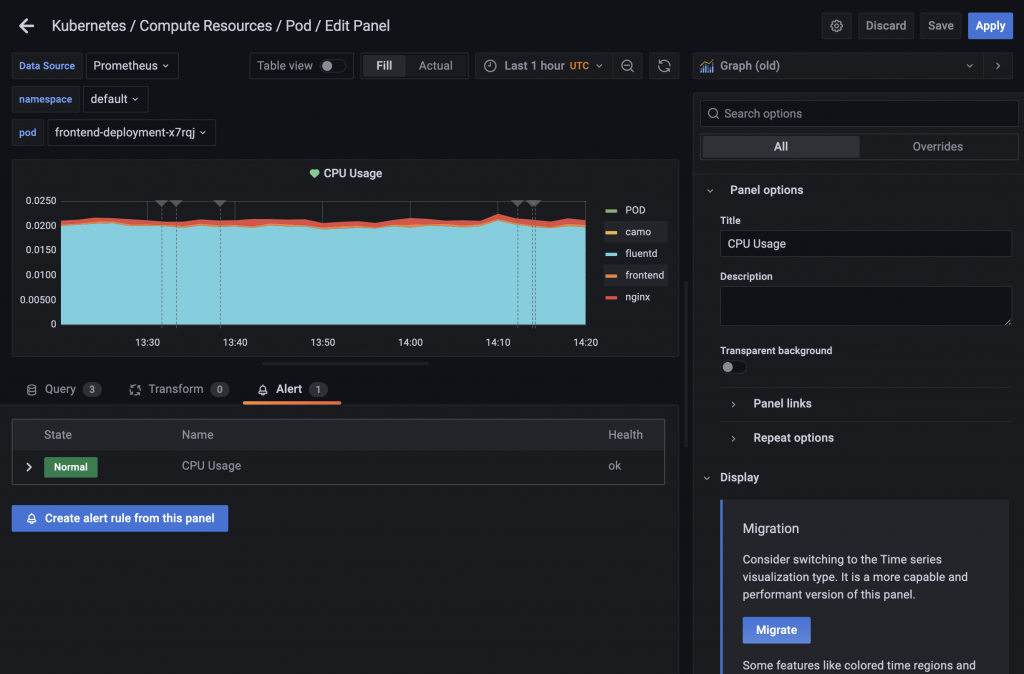
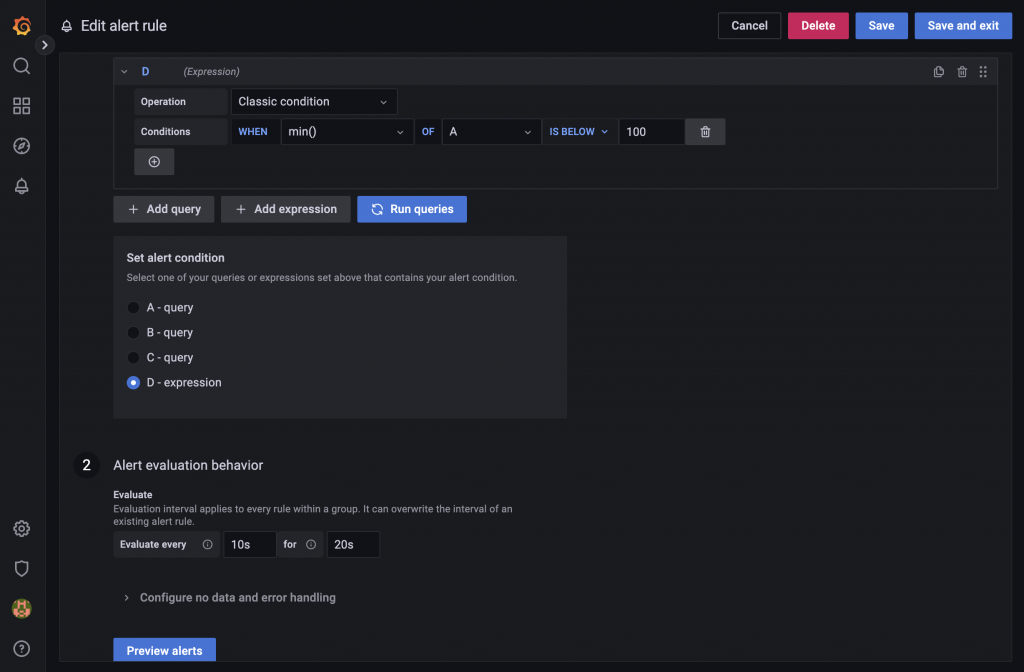
Slackに通知が飛んで来ます。
[FIRING:1] (CPU Usage)
**Firing**
Value: [ var='D0' metric='POD' labels={container=POD} value=0 ], [ var='D1' metric='camo' labels={container=camo} value=0 ], [ var='D2' metric='fluentd' labels={container=fluentd} value=0.019246426639528563 ], [ var='D3' metric='frontend' labels={container=frontend} value=0.00023701709839574144 ], [ var='D4' metric='nginx' labels={container=nginx} value=0.0006233324839868525 ]
Labels:
- alertname = CPU Usage
Annotations:
Source: http://localhost:3000/alerting/grafana/C25dHo6nk/view
...
アラートが出ない条件に変更するとRESOLVEDの通知が来ます。
[RESOLVED] (CPU Usage)
**Resolved**
Value: [ var='D0' metric='POD' labels={container=POD} value=0 ], [ var='D1' metric='camo' labels={container=camo} value=0 ], [ var='D2' metric='fluentd' labels={container=fluentd} value=0.019246426639528563 ], [ var='D3' metric='frontend' labels={container=frontend} value=0.00022692106226046476 ], [ var='D4' metric='nginx' labels={container=nginx} value=0.0006233324839868525 ]
Labels:
- alertname = CPU Usage
Annotations:
Source: http://localhost:3000/alerting/grafana/C25dHo6nk/view
...
アラート通知に適切な条件を設定することでシステム内の異常を検知してアラートを通知できるようになります。
4.Grafana OnCallの導入
Grafana OnCallを利用すると、状況に応じてアラートをエスカレーションさせることができるようです。他にもインシデント管理に便利な機能も搭載されているようなので、Grafana OnCallを導入することでよりきめ細かいインシデント管理が実現できそうです。
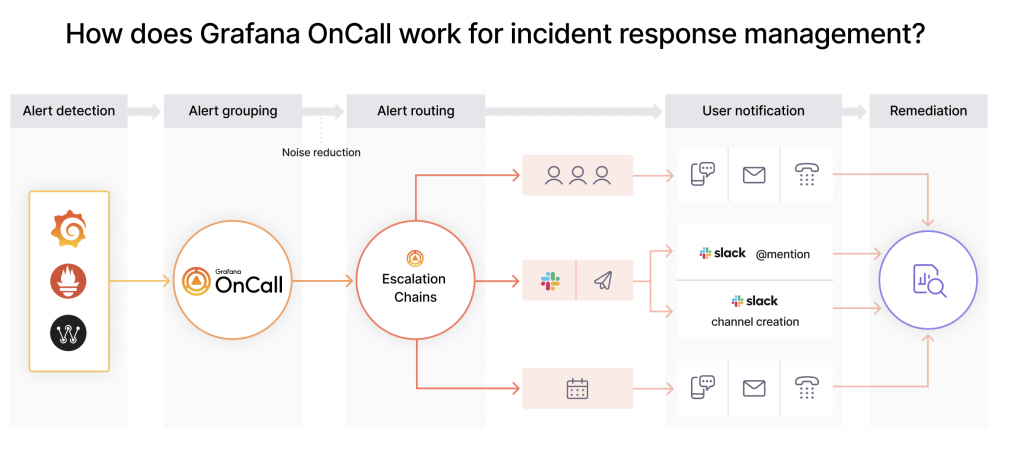
https://grafana.com/static/img/docs/oncall/oncall-alertworkflow.png
5.まとめ
今回はkube-prometheus-stackを利用してKubernetesのPodのメトリクスを可視化して、メトリクスに異常を検知したらアラートを通知する検証をしました。kube-prometheus-stackのマニフェストには様々なメトリクスやアラートが定義されていて、プリセットのメトリクスとアラートだけでも便利に利用できます。今後はそのようなメトリクスやアラートに加えて独自の設定を追加したり、Grafana OnCallの導入を進めて従来の異常検知の仕組みを改善していきたいと思います。
次世代システム研究室では、アプリケーション開発や設計を行うアーキテクトを募集しています。アプリケーション開発者の方、次世代システム研究室にご興味を持って頂ける方がいらっしゃいましたら、ぜひ 募集職種一覧 からご応募をお願いします。
皆さんのご応募をお待ちしています。
参考リンク
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD




