Kubernetes環境へのPrometheus導入の検討
TL;DR
- Kubernetesのシステム監視にPrometheusが有効に使えそう
- Prometheusを導入するためにkube-prometheus-stackが使える
はじめに
こんにちは。次世代システム研究室のT.Tです。現在開発運用に携わっているサービスの監視システムの強化を検討しています。現状では、サービスはZcomクラウド上に独自に構築したKubernetes上で稼働しており、PodにProbeを設定したりサービスのポートをNagiosで外形監視することで簡単な死活監視は実現できています。また、アプリケーションレベルではエラー発生時やレスポンス遅延発生時にSlackに通知するようにしていますが、過検知や取りこぼしを回避するためにアプリケーション内で詳細な制御が必要になりアプリケーションの煩雑化の要因になっています。さらに、Kubernetesのコントロールプレーンを監視する仕組みが導入できておらず、不定期に運用担当者がログの状況を確認して異常が見つかれば対応するといった部分もあります。
こういった問題を解決するためにPrometheusの導入を検討しています。今回はKubernetes環境にPrometheusを導入するために検討した内容についてご紹介します。
1.Prometheusの概要
1.1.Prometheusの概要
Prometheusは主にシステム監視とそれに連動したアラート機能を提供するものです。特徴としてはサービス固有のメトリクスを時系列データとして収集して保存し、PromQLというクエリ言語でデータを操作してアラートを上げます。メトリクスの例としてはWebサーバーにおけるリクエスト数やリクエストの処理時間といったものが挙げられます。アーキテクチャは以下の図のようになっており、Prometheus serverとAlertmanager、Exporterによるデータ保存とアラート、監視エージェントによるデータ収集の仕組み、クエリ言語のPromQL、データを可視化するためのVisualizationといったもので構成されています。
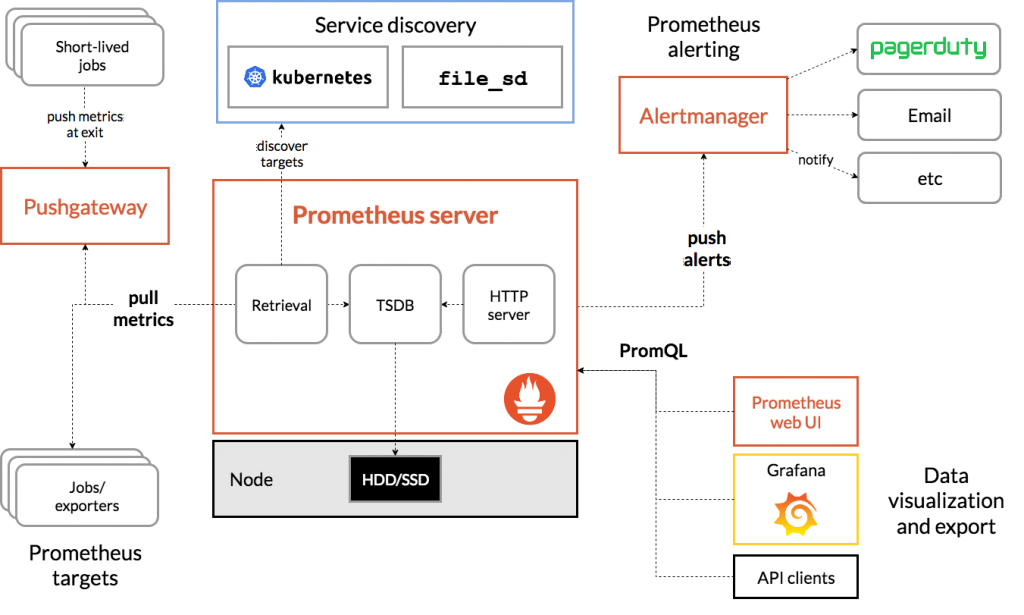 https://prometheus.io/docs/introduction/overview/#architecture
https://prometheus.io/docs/introduction/overview/#architecture1.2.Elasticsearchとの比較
Prometheusの導入を検討しているサービスには、ログの保存と分析にElasticsearchを導入していて数ヶ月分のデータを保持しています。現在アプリケーションのログのみを取り込んでいてKubernetesのコントロールプレーンのログは収集していませんが、それでも数百GBの容量が必要で、無闇にログを取り込んでいると容量が足りなくなってしまいます。このElasticsearchはバッチジョブの実行ログの監視をして正常終了していない場合にアラートをあげるといった異常検知用の仕組みとしても利用しています。この用途では特に不便はないのですが、どのノードのコントロールプレーンに異常があるかを監視するのに適用するとしたら、ログの管理やアラートの設定が煩雑化してしまう懸念があります。
監視とアラート用の簡素化したログを短期間保持するElasticsearchを用意するアプローチもあるとは思いますが、そのために個別のインスタンスや設定を用意するのであればPrometheusを導入するのが良いのではないかと思います。監視とアラートはPrometheusに寄せて、Webサーバーの急激なリクエスト数の増加やレスポンス遅延といったものを早めに検知できるようにして、Elasticsearchは長期的なシステムの傾向を分析するための仕組みとして切り分けられないか検証を進める予定です。
2.Prometheusのインストール
Prometheusはprometheus-communityのkube-prometheus-stackを使って、Kubernetes環境に簡単にインストールできます。kube-prometheus-stackはhelmでインストールできます。$ helm repo add prometheus-community https://prometheus-community.github.io/helm-charts $ helm install [NAME] prometheus-community/kube-prometheus-stack
3.kube-prometheus-stackの構成
helmで設定できる変数を確認してみると色々カスタマイズできそうです。$ helm show values prometheus-community/kube-prometheus-stack # Default values for kube-prometheus-stack. # This is a YAML-formatted file. # Declare variables to be passed into your templates. ## Provide a name in place of kube-prometheus-stack for `app:` labels ## nameOverride: "" ## Override the deployment namespace ## namespaceOverride: "" ...構成要素を把握する場合はmanifestファイルを直接見るのが便利です。
$ helm get manifest [NAME]内容を確認すると、ワークロードとしてはprometheus-grafana、prometheus-kube-state-metrics、prometheus-kube-prometheus-operator、prometheus-node-exporterの4つがあり、それを操作するためのサービスアカウントやRBAC、設定を保持するコンフィグマップ等で構成されています。
4.構成管理案
今回の導入対象のサービスでは他のKubernetesの設定をマニフェストファイルとして直接管理していて、Ansibleで変数管理しgitで世代管理をしています。そのため、Prometheus用にhelmを導入すると変数管理と世代管理用に2つの仕組みを使うことになって煩雑化してしまいます。それを避けるためにhelmを使わずに直接マニフェストファイルを使ってkube-prometheus-stackを構築することもできます。デフォルトの設定で動かす場合はエクスポートしたマニフェストファイルをそのまま使って構築できます。$ helm get manifest [NAME] > prometheus.yml $ kubectl create -f prometheus.ymlこのマニフェストファイルをベースにして環境に合わせて設定を書き換えたり、適宜変数化してAnsibleで管理すれば他のKubernetesの設定と同じように管理できます。
5.まとめ
今回はシステム監視ツールであるPrometheusの概要とアーキテクチャ、Kubernetes環境に導入するために利用できるkube-prometheus-stackの構成について見てみました。監視や障害検知の仕組みは以下のような住み分けが出来ると効率的に運用できるのではないかと思います。- 予期しないアプリケーションのエラーはSlackに即時通知して対策する
- システムへの一時的な負荷上昇によるパフォーマンス低下やレスポンス異常はPrometheusで早めに検知して対策する
- 長期的なシステムの安定稼働はアプリケーションやWebサーバーにログを出力してElasticsearchで分析して対策する
次世代システム研究室では、アプリケーション開発や設計を行うアーキテクトを募集しています。アプリケーション開発者の方、次世代システム研究室にご興味を持って頂ける方がいらっしゃいましたら、ぜひ 募集職種一覧 からご応募をお願いします。
皆さんのご応募をお待ちしています。