2025.04.11
GPT-4oの中身(予想)とGlyph-ByT5〜文字の画像生成への挑戦〜
TL;DR
- OpenAIがChatGPTに追加した新しい画像生成機能は、性能が大きく向上し日本語の文字も生成可能となりました。
- GPT-4oはテキストや画像を統合的に扱うAny-to-Any型の自己回帰型大規模言語モデルで、画像生成にはDiffusion headを利用していると公開情報や他の研究から示唆されています。
- 画像生成AIの「文字」表現性能は年々改良されており、アルファベットの文章生成が可能なモデルが増えています。一部の最新モデル(Ideogram 3.0やGemini 2.0)やGlyph-ByT5といった多言語の文字生成用に研究されたモデルは日本語の文字も生成可能です。
- ただ、これらの生成AIと比較してもChatGPTの日本語の文字表現は、特に高品質で安定しています。
はじめに: ChatGPTの新たな画像生成機能
こんにちは、グループ研究開発本部AI研究室のT.I.です。OpenAIは、2025年3月25日に「4o image generation」というChatGPTの新しい画像生成機能を発表しました(Introducing 4o Image Generation)。従来から画像生成機能はありましたが、文字の表現などの機能が大幅に強化されています。特に、アルファベットよりも複雑な日本語の漢字やひらがなといった文字まで生成可能です。時々不正確なこともありますが、以下のイラストのように、これほどまでに漢字・ひらがなが正確に表現されるのには脱帽ですね🤯

非英語の文字表現までが可能になった画像生成技術について、今回のブログでは、4o image generationの技術の簡単な考察を紹介します(詳細な技術情報は未公開ということもあり)。また、これまでの画像生成技術における文字表現の進展と、文字表現に注力している研究であるGlyph-ByT5シリーズを紹介します。
OpenAI 4o Image Generation: 「Autoregressive Model + Diffusion Head」の「Any-to-Any Large Language Model」(?)
OpenAIの4o Image Generationの技術詳細は不明な点が多く謎に包まれています。公開情報「Addendum to GPT-4o System Card: 4o image generation」では、以下のように説明されています。
Unlike DALL-E, which operates as a diffusion model, 4o image generation is an autoregressive model natively embedded within ChatGPT. This fundamental difference introduces several new capabilities that are distinct from previous generative models, and that pose new risks:
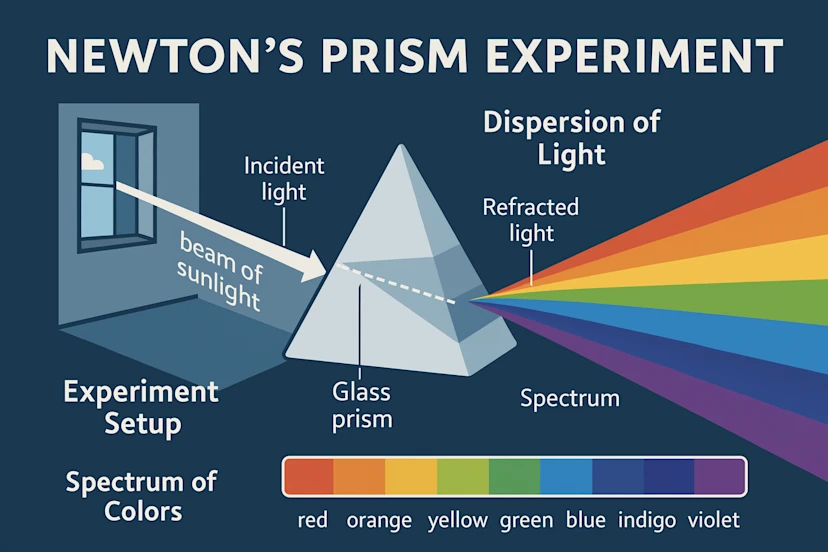
つまりひとつ前のDALL-Eのような拡散モデルではなく、ChatGPTにネイティブに組み込まれている自己回帰モデル(autoregressive)を採用しているとのことです。画像とテキストの関係をより深く統合することでプロンプトへの応答性や描写性能の向上、また、ChatGPTが獲得している知識を利用した画像生成が可能です。以下の様に簡潔にニュートンのプリズム実験の画像を生成するように指示するだけで、光がプリズムに入ってどうしたなどの具体的な内容を説明せずともChatGPTの知識から適切な画像を生成することができています。
an infographic explaining newton’s prism experiment in great detail
こちらの記事「GPT-4oとGemini-2.0の画像生成能力はいかにして作られているのか」では、4o image generationの技術について、近年の自己回帰モデルの画像生成への応用を発展を紹介し、その統合的なアプローチとして「Any-to-Any」型のLanguage Modelを紹介しています。今回のブログでは自己回帰モデルでの画像生成技術は詳しくは紹介しませんので、興味がある方は上記のブログを参照してください。「Any-to-Any」とは、文章や画像、音声などの異なるモダリティを統一的に取り扱うLanguage Modelであります。テキストのトークンと同じように画像・音声などもトークン化して処理、出力時に特別なデコーダーで画像や音声に合成するというものです。Any-to-Anyモデルの概念として、以下のAnyGPTの概念図が分かりやすいです。
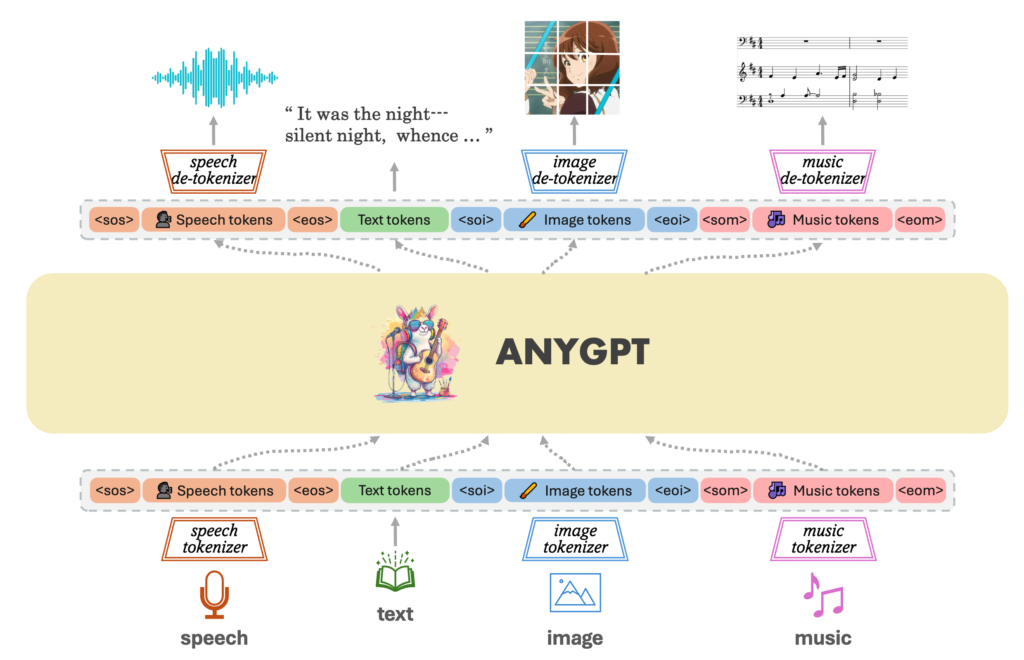
より引用
GPT-4oの音声・画像生成やGemini-2.0の画像生成は、 OpenAIやGoogleのリソースを活用し、自己回帰型のAny-to-Anyモデルを大規模化することで達成されたと考えられます。これには、エンコーダー・デコーダーの工夫や、大規模な学習データセットの作成、学習方法の改良が含まれます。特に後述するように文字を正確に表現するためには、大量の文字と対応するテキストのデータが不可欠です。OpenAIやGoogleが技術をそのまま公開することはないと思いますが、今後、同様の技術をオープンに開発する研究の潮流が進むと期待されます。そのヒントと思われるのが、OpenAIのブログで公開されていた以下の「ホワイトボードに文字を書いている人物」の生成画像です。

これほどの文字量を生成できるのはすごいですが、内容を読むと「token → transformer → diffusion」と画像生成プロセスを示唆する内容となっています。最近発表されたGPT-4oの新しい画像生成性能を包括的に評価した研究「GPT-ImgEval: A Comprehensive Benchmark for Diagnosing GPT4o in Image Generation」では、そのモデル構造に関して以下の3つの可能性から、(a)の自己回帰モデル+Diffusion headを採用していると考察しています。
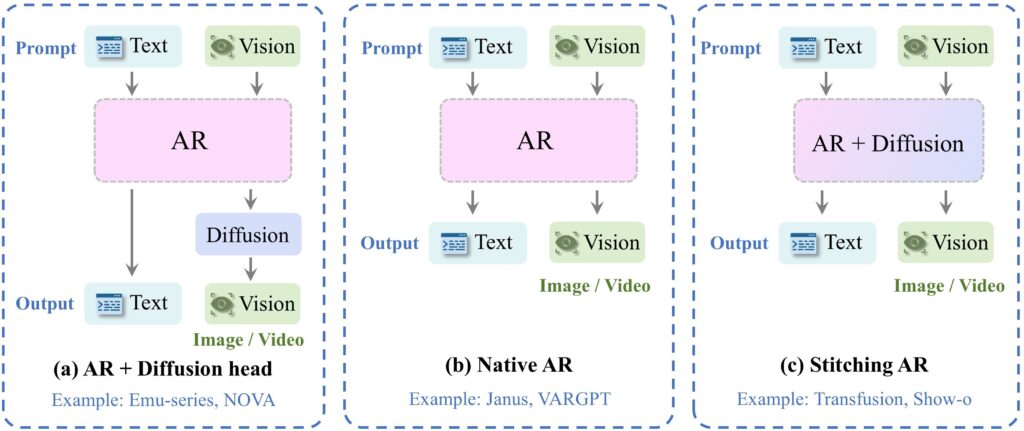
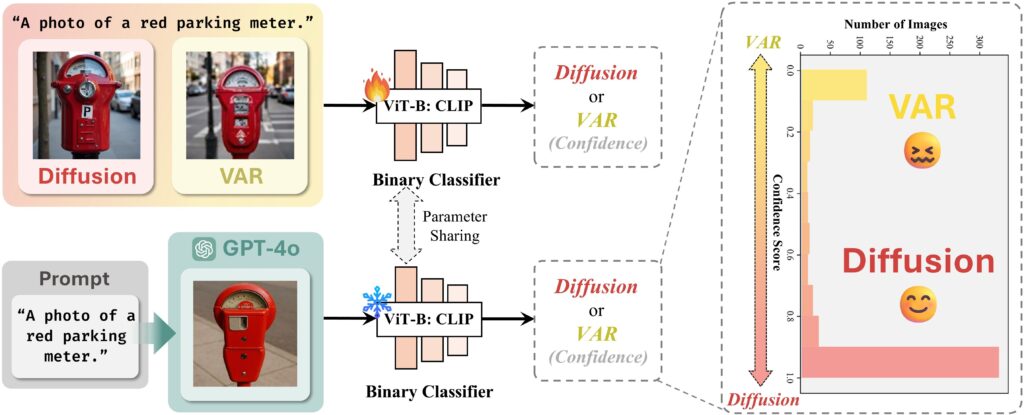
GPT-ImgEvalの研究では、4o image generationのモデル構造について、(1) Diffusion head、(2) VAR(Next-Scale Predictionによる高解像度化生成)という2種類の可能性が検討されています。どちらが使われているか調べるため、GPT-ImgEvalでは、各種方の生成画像を分類する識別器を別途学習させました。そのモデルでGPT-4oの生成画像を判別した結果、Diffusion headが採用されている可能性が高いことが示されました。(注) VAR: Visual Autoregressive Modeling: Scalable Image Generation via Next-Scale Prediction arXiv:2404.02905
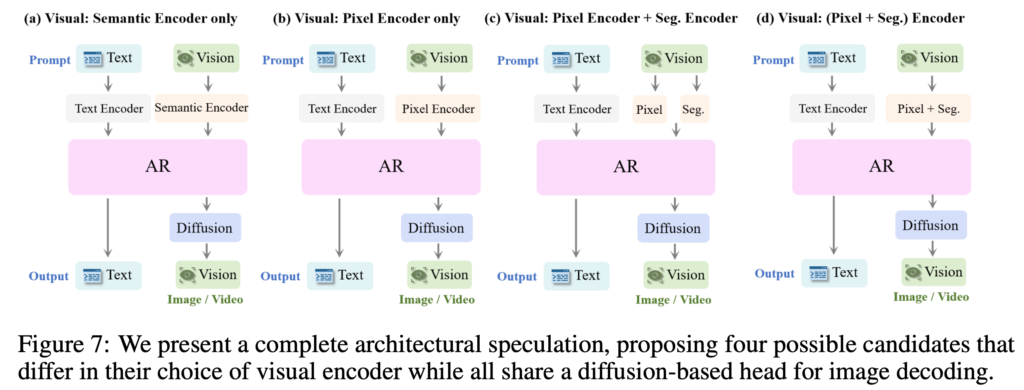
更にGPT-ImgEvalでは、画像のエンコーダーに関しても、GPT-4oの性能考察からベクトル量子化(VQ)のようなエンコーディングではないと判断し、以下の4つの可能性を最終的にGPT-4oのモデル構造の候補としています。
GPT-ImgEvalの論文では、さまざまな観点からGPT-4oの画像生成機能の性能が評価されています。その中でも興味深い結果の一つとして、GPT-4oの生成画像した画像の検出性能です。GPT-4oの生成する画像は非常に精巧であり、フェイク画像の氾濫が懸念されますが、実際には簡単に検出可能です。これは、GPT-4oの画像生成プロセスの中の高画質化に特徴的な癖があるためであり、既存のツールを用いて99パーセントの精度で容易に検出できるそうです。
また、先日に発表された論文「An Empirical Study of GPT-4o Image Generation Capabilities arXiv:2504.05979」では、GPT-4oの生成する画像を各種生成AIモデルとの結果と包括的に比較しております。画像の品質や文字の表現性能、画像修正など多岐にわたって性能評価を行っており参考になります。

画像生成AIによる「文字表現」の挑戦
ここでは画像生成AIによる文字表現について簡単に整理します。
Stable Diffusion シリーズ
最初のStable Diffusionは、2022年8月23日にリリースされました「Stable Diffusion Public Release」。これは、Latent Diffusion Modelを元に開発された画像生成AIで、10GB以下のVRAMで512 x 512の解像度の画像が生成できるため瞬く間に人気を博しました。
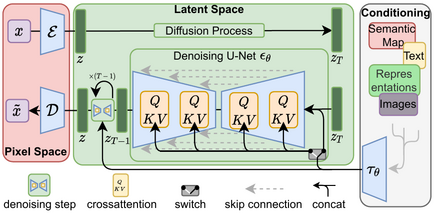
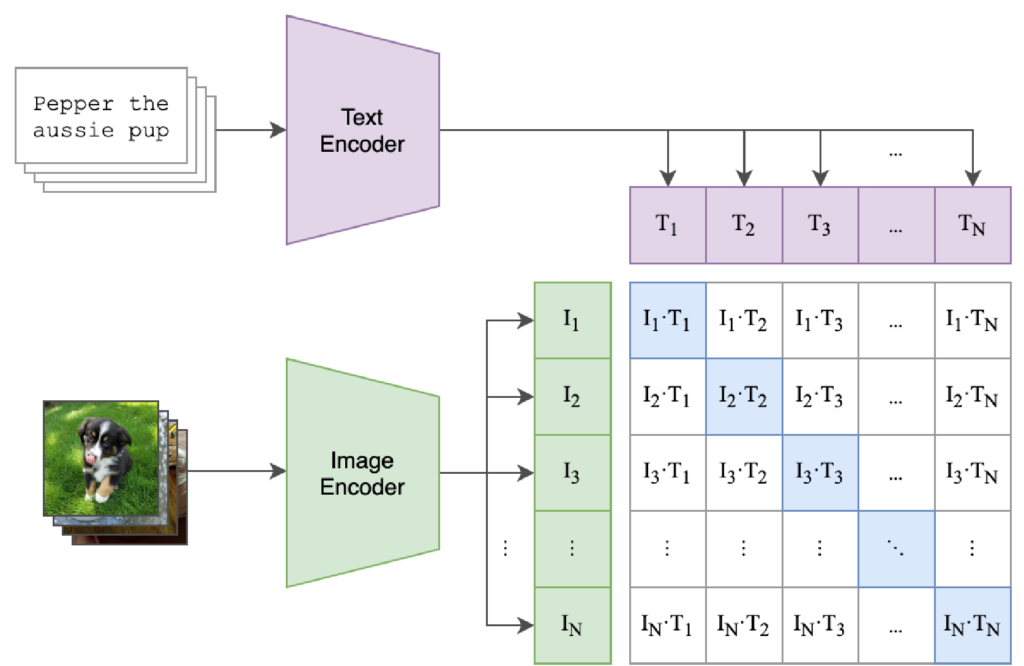
拡散モデルでは、画像にノイズを掛けるプロセスを逆再生させてノイズを徐々に取り除くことで画像を生成します。その画像の制御に関して、プロンプト(テキスト)と画像とを結びつけるためにCLIP(Contrastive Language-Image Pre-Training)というモデルを利用しています。CLIPは、OpenAIの開発した言語・画像のマルチモーダルモデルで、画像のキャプションのテキストをペアに学習します。したがって、文字を正しく生成するためには「文字表現」の埋め込みを学習する必要がありますが、解像度と学習データセットの限界もありStable Diffusion v1では、文字表現はアルファベットでもあまり正確にはできませんでした。
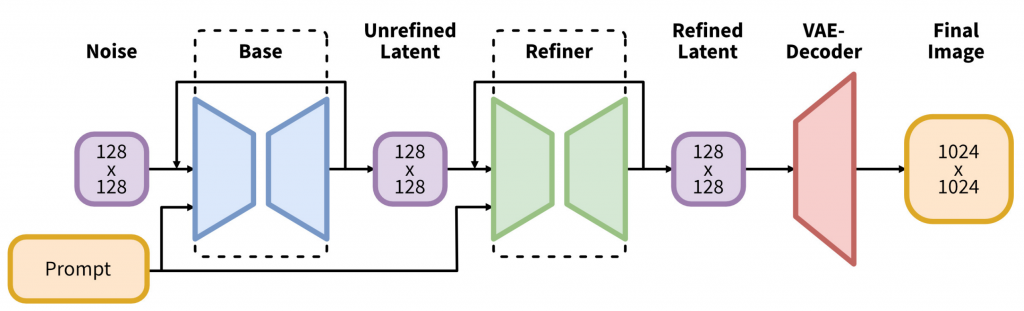
その後、Stability AIは2023年7月26日にStable Diffusion XL(SDXL)をリリースしました「Announcing SDXL 1.0」。これはStable Diffusionを更に高精度に改良したバージョンです(なお、Stable Diffusion v2も、SDXL以前にリリースされていたものの、品質面で問題があり普及はしませんでした)。SDXLのモデル構造は以下のようにBase + Refinerという2段階の構造を持っており、1024 x 1024 のより高解像度の画像を生成することが可能です。
さて、更にStable Diffusion XLの後継バージョンとして発表されたモデルがStable Diffusion 3です(これもStable Diffusion 3の発表直前にStable Cascadeというモデルが発表されたのですが)。Stable Diffusion 3では、Multimodal Diffusion Transformer (MM-DiT)という、Transformerベースの構造を採用しています。テキストと画像のモダリティをそれぞれに並列に処理する設計となっています。
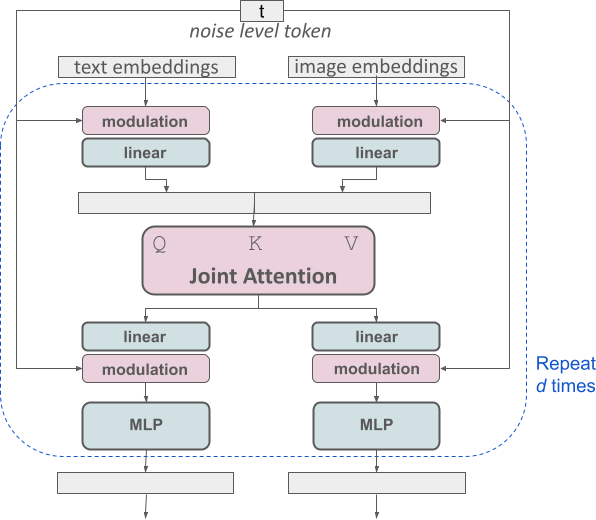
Stable Diffusion 3の全体構造は以下のようにMM-DiTブロックの多段構造で、入力に関してはプロンプトのエンコーダーとして、CLIP-G/14とCLIP-L/14、そしてT5 XXLという3つのモデルを用いています。
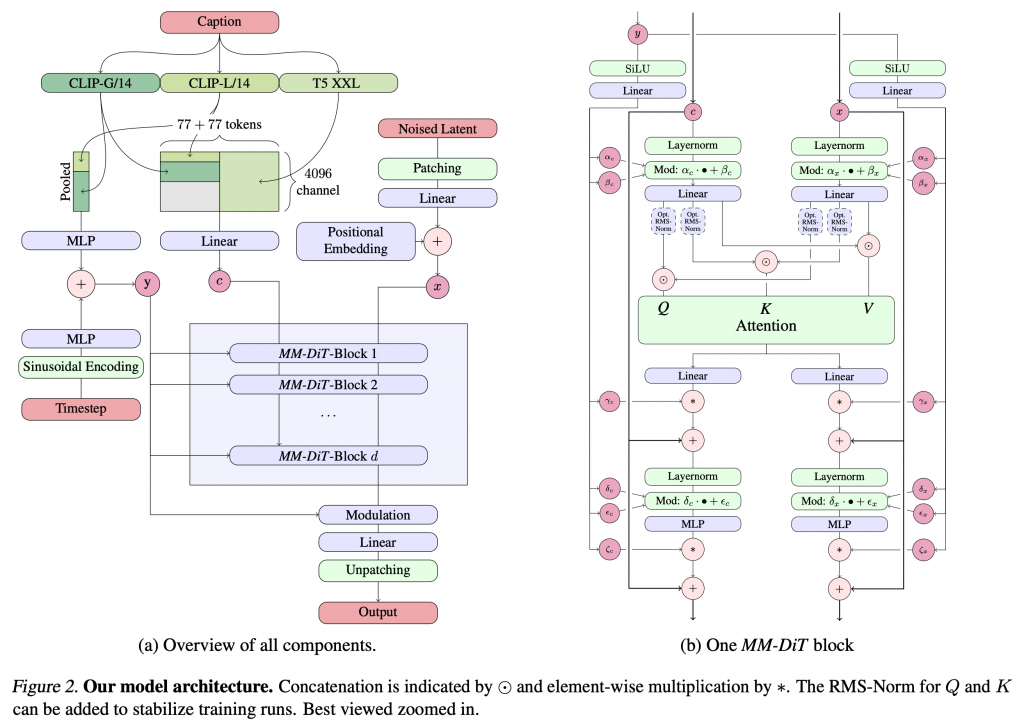
Stable Diffusionシリーズは、着実にモデルの改良しながら発展してきました。Stable Diffusion 3に関しては、2024年10月22日、改良版のStable Diffusion 3.5がリリースされています(Introducing Stable Diffusion 3.5)。最初のバージョンでは、ほとんど正しい単語を出力することは困難であったものが、SDXLでは看板などの短い英単語は表現できるようになり、Stable Diffusion 3では、短いフレーズの文章も生成可能となりました。

しかし、Stable Diffusion 3でも、日本語には対応していません。日本語の文字を生成しようとすると、以下のように奇妙な文字列が生成されてしまいます。

FLUX.1
Stable Diffusionの研究者らが立ち上げたBlack Forest Labsでは、FLUX.1という画像生成AIを開発しています。これらは、Stable Diffusion 3以降のモデルと同等以上の性能をもち文字表現も可能なモデルです。そのうちFLUX.1[dev]、FLUX.1[schnell]は、オープンウェイトで公開されておりますが、上位モデルの FLUX1.1 [pro](2024年10月2日リリース), FLUX.1 [pro] は、有料APIもしくはFLUX1が利用可能な各種ウェブサービスを通じて利用可能です。以下の例は適当にデータサイエンティスト募集中のポスターをFLUX1.1 [pro]で作った例です。細かい文字は所々怪しいですが、全体的に沢山の文字が正確に生成されています。

Ideogram 3.0
また、Ideogram AIにより3月26日にリリースされたIdeogram 3.0も同様に文字の表現が大幅に強化されております。アルファベットだけではなく、漢字やひらがなも表現可能ですが、OpenAIの4o image generationと比較するとまだ若干不安定な印象です。

Gemini 2.0
さて、OpenAI o4 image generationの画像生成性能もすごいですが、Gemini 2.0 (Image Generation) Flash Experimental も画像生成能力が飛躍的に強化されております(Experiment with Gemini 2.0 Flash native image generation)。GeminiもChatGPTと同様にテキストや画像を1つのモデルで扱うAny-to-Any型のモデルを採用しております(Gemini: A Family of Highly Capable Multimodal Models)。日本語の文字表現も可能でありますが、OpenAIの4o image generationと比較すると正確性はやや不安定です。また、Ideogram 3.0やFLUX.1の様な画像生成に特化したモデルと比較すると、生成画像の品質に関しては少々物足りない印象があります。

CogView4
非英語を表現できるオープンモデルとしては、THUDM(中国清華大学)が、2025年3月4日に発表したCogView4-6B(THUDM/CogView4-6B)は、中国語に対応し中国語の文字を生成することが可能となっています。ただ、一度に生成できる文字数は多くなく、安定した生成には今ひとつのようです。

Glyph-ByT5 シリーズ
Glyph-ByT5シリーズは、Microsoft Research Asiaの研究者らが開発した拡散モデルによる画像生成AIです。文字通り「グリフ(文字の形状)」の表現に特化しており、文字の視覚的な表現を正確な生成を目的としています。他にも文字表現に着目した研究は多々ありますが、Glyph-ByT5は日本語を含む多言語に対応している点が大きな特徴です。以下では、この技術について紹介します。
Stable Diffusionの解説で述べたように、画像生成AIではCLIPやT5のようなエンコーダーを用いて、テキストと画像という異なるモダリティの情報を同じ特徴空間にマッピングし、プロンプトに基づいた画像を生成します。しかし、汎用的なエンコーダーでは「グリフ」文字の形状やフォント情報を十分に捉えることができません。T5とは、Stable Diffusion 3でも採用されていエンコーダーですが、これをバイト単位で文字を処理できるように拡張したものがByT5エンコーダーです。更にByT5を文字形状の特徴を捉えるようにチューニングしたものがGlyph-ByT5です。Glyph-ByT5では、文字に対応するトークンに加えて、[font-color-127]や[font-type-231]などのフォントの色や種類を指定する特別なトークンも追加し、より正確で幅広い文字表現が可能となります。
Glyph-ByT5-v1: グリフ・エンコーダー
Glyph-ByT5(Glyph-SDXL)は、2024年の3月に発表された最初のバージョンです(Glyph-ByT5: A Customized Text Encoder for Accurate Visual Text Rendering)。こちらは、英語の文章を生成できます。Glyph-ByT5エンコーダーの学習のためには、グリフとテキストの対となる学習データを作成しています。また、学習時には、画面全体ではなくテキストが表現される領域に着目した損失関数を用いています。画像の生成に関しては、SDXLを利用しており、ByT5エンコーダーの入力をSDXLに与える箇所も含めてモデルを学習しています。
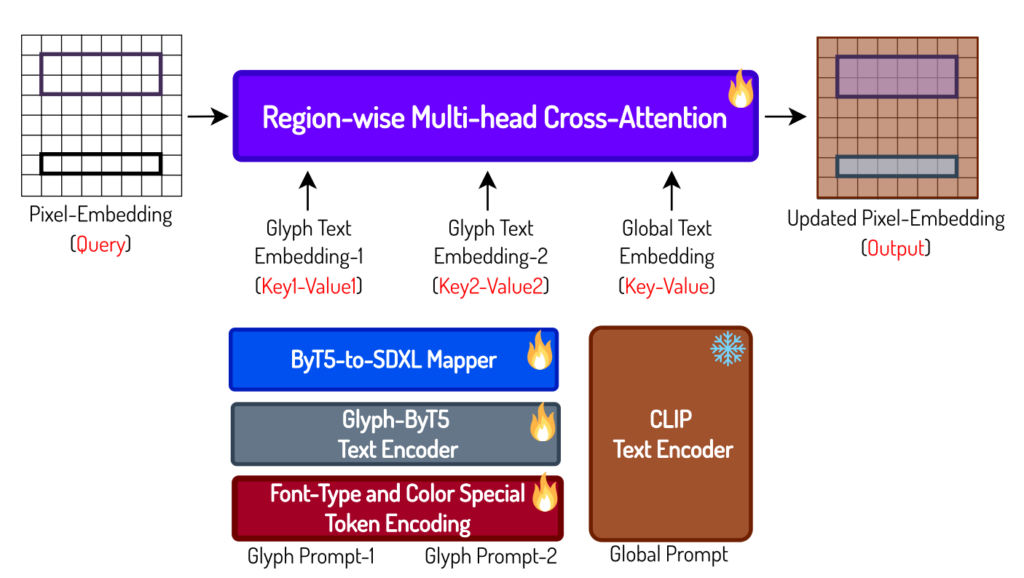
このようにして学習されたGlyph-ByT5エンコーダーとSDXLを組み合わせたモデルがGlyph-SDXLです。それを利用した生成の例は以下の通りです。様々なグリフの文字がレンダリング可能です。

Glyph-ByT5-v2: 多言語への対応
Glyph-ByT5-v2は、2024年の6月に発表されたGlyph-ByT5のバージョン2です(Glyph-ByT5-v2:A Strong Aesthetic Baseline for Accurate Multilingual Visual Text Rendering)。多言語への拡張が行われており、英語だけでなく日本語や韓国語などの合計10カ国もの多言語に対応しています。Glyph-ByT5エンコーダーを多言語へ対応させるために、多言語のグリフとテキストのペアを学習データとして用意する必要があります。これらの多言語のグリフ・テキストペアを作成することは困難であるため、英語のデータを機械的に翻訳し学習データを拡張して作成しています。
「つぶピ準8」?と日本語の例が何だか変な感じで、海外にある怪しげな日本語の商品パッケージのような雰囲気があります。ただ、個々の文字単位でのグリフの学習としては問題なかったようで、以下の通り、Glyph-ByT-v2では、日本語やハングルを生成できています。

多言語に対応するために、それぞれの言語とフォントを指定する特殊トークンが追加されています。上の例の「秋季限定のカフェ」の画像は、小さい文字が潰れて読みにくいですが、意図していた文章は以下のような内容です。
Background: The image features two iced coffee drinks, each with a layer of cream on top. The drinks are placed on a white surface, and there is a small, white cloud-like shape above the drinks. The image has a playful and whimsical feel to it. Text: Text “早起は困難な人々目を覚ますために助けが必要です” in <color-1>
, <jp-font-205>. Text “毎日は二度目のチャンスです一日一日を大切にするために” in <color-1>, <jp-font-205>. Text “人生は良すぎず、 コーヒーは悪すぎません” in <color-1>, <jp-font-205>. Text “29.9/カップ” in <color-1>, <jp-font-205>. Text “挽きたてのコーヒー豆” in <color-1>, <jp-font-42>. Text “秋季限定” in <color-1>, <jp-font-157>. Text “生活は苦しいですがカフェラテを選びましょう” in <color-1>, <jp-font-3>.
このようにText “早起は困難な人々目を覚ますために助けが必要です” in <color-1>, <jp-font-205>のように、生成したい文字列に色やフォントを指定するトークンが含まれています。機械翻訳によるものか、「生活は苦しいですがカフェラテを選びましょう」と宣伝としてはやや不穏で細かい文字など不正確な部分もありますが、漢字やひらがなを生成できています。独身のワンちゃんとはどうやら「单身狗 (dānshēn gǒu)」という中国語のネットスラングのようですね。
BizGen(Glyph-ByT5-v3): インフォグラフィックやスライドへの拡張
BizGenは、2025年3月26日に発表されたGlyph-ByT5の最新バージョンです(BizGen: Advancing Article-level Visual Text Rendering for Infographics Generation)。従来の画像生成AIの文字表現は、ポスターやチラシのような比較的シンプルなデザインの生成が中心でした。BizGenでは、より複雑な情報を含むインフォグラフィックやビジネス向けスライドのようなシーンでの利用を目的としています。

インフォグラフィックのような複雑な表現を生成するために、BizGenでは個別の要素ごとにレイヤーに分けて学習・生成を行います。1つのインフォグラフィックは、以下のように背景、タイトルや各セクション、それらに記載される文字、そして個別のアイコンやイラストなどの要素から構成されます。複雑なレイアウトのインフォグラフィックやスライドを生成するために、BizGenはそれぞれの構成要素をレイヤーに着目して生成します。そのために1000以上の長いトークンを入力に与えて、2240 x 896 の解像度の画像を生成することができます。
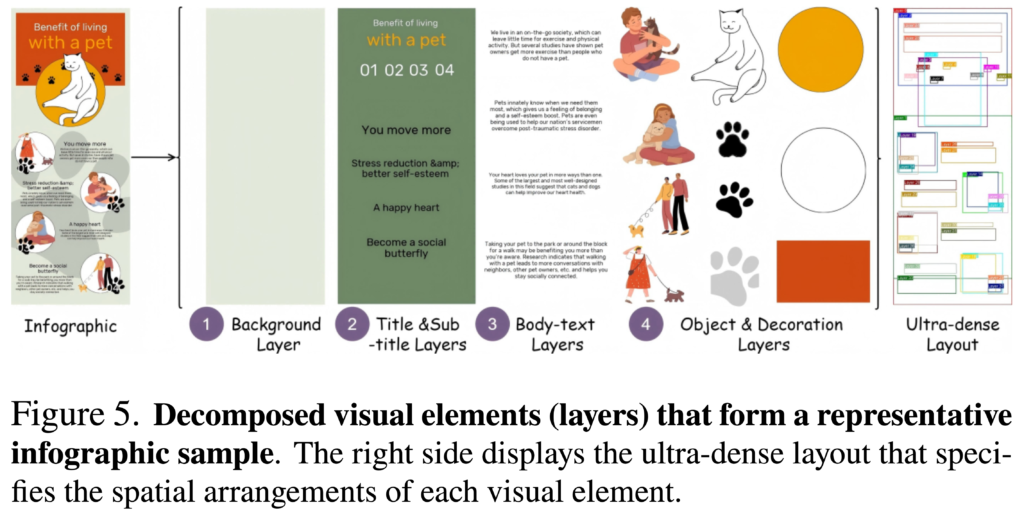
BizGenを動かしてみた
BizGenはGitHubでコードが公開されており、学習済みモデルもHugging Faceで公開されているので、READMEの指示にしたがってインストールして動かしてみました。チェックポイントとして、ByT5のモデル、ファインチューニングされたSDXLのモデル、およびインフォグラフィック、スライド用のLoRAをダウンロードする必要があります。実行時には、16GB程度のVRAMのGPUがないと動かないので注意してください。なお、Glyph-ByT5-v2(v1)に関しては、学習のデータセットに非許可のものが含まる懸念があったようで、2024年6月に学習済みモデルは非公開となっています。
$ conda create -n bizgen python=3.10 -y $ conda activate bizgen $ git clone $ cd bizgen $ pip install -r requirements.txt $ huggingface-cli login $ pip install "numpy<2.0" # 実行時にPyTorchでエラーとなったので、Numpy のバージョンを下げました $ python inference.py --ckpt_dir checkpoints/lora/infographic --output_dir infographic --sample_list meta/infographics.json
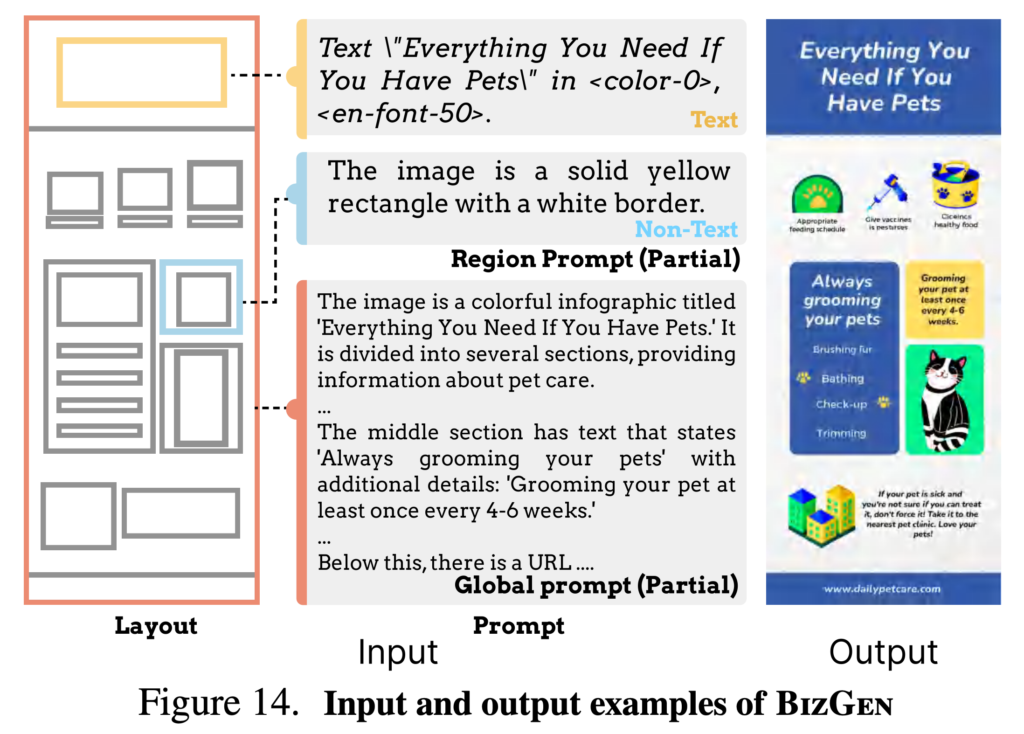
このmeta/infographics.jsonにぐらい的なプロンプトが書かれており、これを元に画像生成を行います。プロンプトは全体の内容や各レイヤー座標と内容を個別に指示する必要があります。
具体的なjsonの内容の例は以下のようになります。インフォグラフィックの構成用を個別に指示するため1から作成することは大変です。あらかじめ構成のテンプレートを準備しておき、ここのケースに合わせてプロンプトを調整すると良いでしょう。今回のデモでは、Pizzaのインフォグラフィックを生成するサンプルコードを元に、ChatGPTに適当な内容を提案して、それに合わせてプロンプトを作ってもらいました(なお、数値などの内容が正確かは不明です)。
[
{
"index": "jp_1",
"layers_all": [
{
"category": "base",
"top_left": [
0,
0
],
"bottom_right": [
896,
2240
],
"caption": "The image features a variety of rice balls (onigiri), each with different traditional Japanese fillings such as umeboshi (pickled plum), salmon, kombu (seaweed), and tuna mayo. ...(略)"
},
{
"category": "element",
"top_left": [
0,
0
],
"bottom_right": [
896,
2240
],
"caption": "The image you've provided is completely blank and white. ...(略)"
},
...(略)...
{
"category": "text",
"top_left": [
272,
1690
],
"bottom_right": [
656,
1774
],
"caption": "Text \"ツナマヨは日本で一番人気のおにぎりの具材です\" in , . ",
"text": "ツナマヨは日本で一番人気のおにぎりの具材です"
},
],
"full_image_caption": "The image features a variety of rice balls (onigiri) with different traditional Japanese fillings, ...(略)"
}
]
以上のプロンプトを与えるとこのようなおにぎりに関するインフォグラフィックを生成してくれました。概ね良い感じにたくさんの日本語の文字が正しく生成されています。おにぎりのクオリティに関しては、SDXLベースで特にファインチューニングしてないこともあり、なんだか微妙ですが、与えられたレイアウトで生成してくれました。ただ、必ずしも正しく文字を生成できるわけではなく、文字の改行位置も不安定で、乱数シードを変えて複数回試行錯誤しています。参考に、同様の指示を与えてOpenAIの4o image generationで生成した画像も載せておきます。こちらもおにぎりの画像の品質がおもちゃっぽいテイストで期待とは違いますが、全体のデザインとしてはBizGenよりは好みですね。ただ、4o image generationでは、細かい文字の一部が潰れてしまっています。全体的な品質としては、OpenAIが良い感じではありますが、オープンの小型のモデルでここまで生成できるのはすごいと思います。

BizGenはインフォグラフィックの他にもスライドが生成できるようになっています。与えるプロンプトはインフォグラフィックと同様に、スライドの構成を個別に指示する必要があります。

まとめ
今回のBlogでは、OpenAIの新しい「4o image generation」と画像生成AIによる文字表現の研究「Glyph-ByT5」について紹介しました。特に従来の画像生成AIでは困難であった日本語の文字表現において「4o image generation」では、自己回帰型モデルを利用して高い精度での文字表現が可能となっています。モデル構造など詳細は不明であるもの、Any-to-Any方式のモデルでdiffusion headを利用した画像生成をしている可能性が高いと推測されています。
Stable Diffusionをはじめとする所謂画像生成AIでは、細かい文字などの正確な表現は難しいですが、モデルの改良に伴い徐々に文字表現の精度が向上してきています。Stable Diffusion 3やFLUX.1シリーズ、Ideogram 3.0などの最新のモデルでは、短いフレーズの文字は生成可能です。ただし、長い文章や日本語の文字を生成することはまだまだ難しいようです。この点に関しては今後の改善が期待されます。
Glyph-ByT5シリーズは、拡散モデルを用いた画像生成AIで、特に文字生成に特化した一連の研究です。グリフを学習するための特別なエンコーダーを採用し、グリフとテキストのペアを学習することで、正確な文字表現を実現しています。更に日本語も含む多言語を学習することで、様々な言語の文字を生成できます。最新のBizGenでは、インフォグラフィックやスライドのような複雑なレイアウトの画像生成が可能となっております。
最後に
グループ研究開発本部 AI研究開発室では、データサイエンティスト/機械学習エンジニアを募集しています。ビッグデータの解析業務などAI研究開発室にご興味を持って頂ける方がいらっしゃいましたら、ぜひ募集職種一覧からご応募をお願いします。皆さんのご応募をお待ちしています。

参考資料
- Introducing 4o Image Generation
- Addendum to GPT-4o System Card: 4o image generation
- GPT-4oとGemini-2.0の画像生成能力はいかにして作られているのか
- AnyGPT: Unified Multimodal LLM with Discrete Sequence Modeling [arXiv:2402.12226]
- GPT-ImgEval: A Comprehensive Benchmark for Diagnosing GPT4o in Image Generation [arXiv:2504.02782]
- Visual Autoregressive Modeling: Scalable Image Generation via Next-Scale Prediction [arXiv:2404.02905]
- An Empirical Study of GPT-4o Image Generation Capabilities [arXiv:2504.05979]
- Stable Diffusion Public Release
- High-Resolution Image Synthesis with Latent Diffusion Models [arXiv:2112.10752]
- CLIP GitHub Repository
- Announcing SDXL 1.0
- SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis [arXiv:2307.01952]
- Stable Diffusion 3
- Introducing Stable Diffusion 3.5
- Black Forest Labs
- Ideogram 3.0
- Experiment with Gemini 2.0 Flash native image generation
- Gemini: A Family of Highly Capable Multimodal Models
- THUDM/CogView4-6B
- Glyph-ByT5: A Customized Text Encoder for Accurate Visual Text Rendering [arXiv:2403.09622]
- Glyph-ByT5-v2: A Strong Aesthetic Baseline for Accurate Multilingual Visual Text Rendering [arXiv:2406.10208]
- BizGen: Advancing Article-level Visual Text Rendering for Infographics Generation [arXiv:2503.20672]
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD