2022.01.07
bitcoinのデータを触りながらGNNの基本的な手法をおさらいしてみる
こんにちは。次世代システム研究室のS.S.です。
今回はグラフに関連した問題を解くためのNNアーキテクチャであるGNNに入門し、その中で大規模グラフへのスケーラビリティに優れたGraphSAGEを中心に紹介したいと思います。
検証にあたってはbitcoinのデータセットを使うことにします。
GNNとは?
従来の機械学習アーキテクチャでは表形式データや自然言語、画像などの入力データを中心として扱っていたのに対し、GNNはグラフ形式のデータに適したアーキテクチャです。
グラフ形式のデータとしては例えば次のようなものがあります。
- bitcoinの取引ネットワーク
- 論文の引用グラフ
- タンパク質のグラフ
グラフ上のタスクとして次の代表的なタスクがあります。
- グラフ分類
- サブグラフが与えられた時にどのクラスに属するか分類
例: タンパク質が特定の機能を持っているか
- サブグラフが与えられた時にどのクラスに属するか分類
- ノード分類
- 引用グラフが与えられた時、ある論文はどのカテゴリに属するか
- 取引ネットワーク上のbitcoin walletは不正な取引に関与しているか
- グラフ埋め込み
- グラフ上で似たノード同士が近くに集まるようにサブグラフやノードの埋め込み表現をつくる
- リンク予測
- グラフ上の二つのノードにエッジが生えているか予測
GraphSAGEとは?
GraphSAGEの特徴を表にまとめると次のようになります。
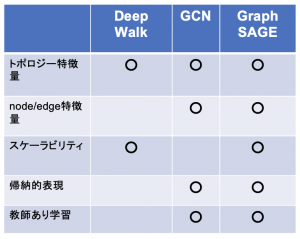
GraphSAGEではノードやエッジの特徴量を扱うことができ、スケーラビリティに優れており、帰納的表現が得られるなどのメリットがあります。
2つの先行する手法であるDeepWalkやGCNと対比しながらGraphSAGEのメリットについて具体的に見ていきたいと思います。
GNN手法の紹介
DeepWalk
DeepWalkは教師なし学習の手法で、グラフ上のノードどうしの隣接関係(トポロジー)の情報をもとにノードの埋め込み表現を獲得します。
得られる埋め込み表現はグラフ上で似たノードどうしが近くに集まるような表現となるため、グラフに関連した様々なタスクを解く時のfeatureとして使うことができます。
この埋め込み表現をどのように学習するかですが、グラフ上の隣り合うノードをランダムに選んで訪問していくRandom Walkによって得られる”文”(ノードの列)を、単語の表現を獲得するためのアルゴリズムであるWord2Vecに渡して学習を行います。
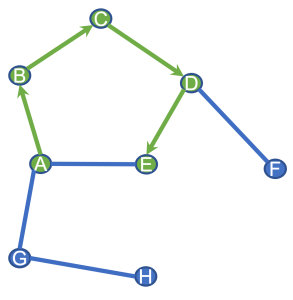
例えば図のグラフでAという頂点を起点にRandom Walkして得られた”文”がA -> B -> C -> D -> Eだったとします。この文をWord2Vecに渡します。
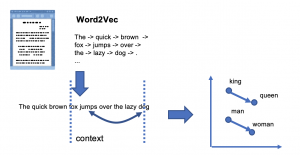
Word2Vecは大規模な自然言語の文書データをもとに単語の関係性を学習するアルゴリズムです。
注目している単語”dog”に近い位置(文脈)に出現する単語 “fox”, “jumps”などから”dog”という単語を予測できるように学習を行います。
大規模データで学習を行うことで有名な例である”king”と”queen”は”man”と”woman”の関係性に類似しているというような単語の埋め込み表現が得られます。
このアルゴリズムをGraphに適用したのがDeepWalkとなります。
GCN
GCNはノードの特徴量をもとに教師あり・なしの両方でノードの埋め込み表現を学習できるアーキテクチャです。
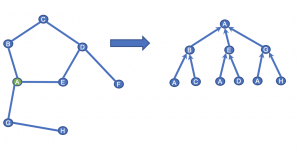
いま2層のGCNでグラフ上のノードAに対する埋め込み表現を得たいとします。
GCNでは近傍ノードの集約を繰り返してノードの埋め込み表現を計算します。
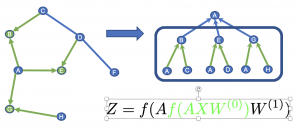
最初のステップではAの近傍ノードであるB, E, Gの埋め込み表現を計算します。
ここでBというノードは自身の近傍としてA, Cというノードを持つため、この二つのノードの情報をもとにBの埋め込み表現を得ます。E, Gについても同様です。
式の内側の部分は一層目の計算を表しており、ノードのfeature Xに対して隣接行列Aで集約を行い、重みWをかけて非線形変換を適用します。
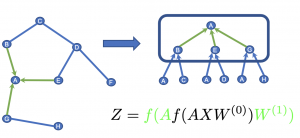
2層目では今度はAの近傍ノードの表現を受け取り、A自身の埋め込み表現を計算します。
式で言うと外側の部分に相当します。
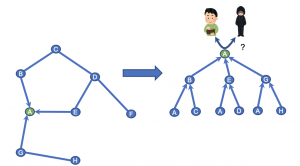
最終的に得られたノードAの埋め込み表現を使ってグラフ上のタスクを解きます。
例えば取引ネットワーク上のノードの埋め込み表現をもとに、そのノードが不正な取引に関与しているかどうかを予測する分類問題を解くという設定が考えられます。
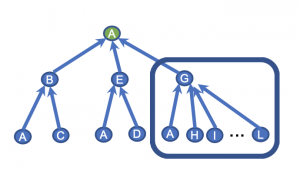
GCNのデメリットとしては隣接するノード全てを集約してノードの表現を計算するので、大規模なグラフの中で図のGのノードのように次数が高いノードがあると、その分だけ計算対象のノードが増えてしまうということがあります。
GNNを大規模なグラフに適用するにはどうすればよいのかというところですが、一つのアプローチとしてGraphSAGEがあります。
GraphSAGE
GraphSAGEではGCNで注目しているノードの埋め込み表現を計算する時に、全ての近傍ノードを集約していたところを、隣接ノードの一部をサンプリングして集約するという操作で置き換えます。
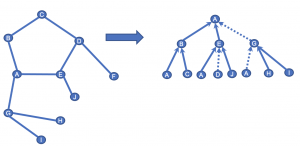
さきほどと同様に注目しているノードAの埋め込み表現を得たいとします。
Aの埋め込み表現を計算するためには、近傍ノードのB, E, Gの埋め込み表現が必要になります。
Eの表現を計算するために隣接するA, D, Jの3つのノードからサンプリングをした結果、残ったA, Jの埋め込み表現をもとにEの表現を得ます。
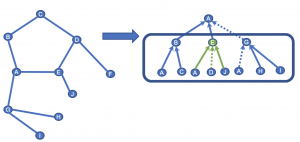
同様の計算を繰り返すことでさきほどと同様にグラフ上のタスクを解くための埋め込み表現が得られます。
GraphSAGEのもう一つの利点として帰納的表現であるということが挙げられます。
DeepWalkやWord2Vecのように単語やノードにあらかじめvectorを割り当てて学習する方式では、未知のサブグラフに対して埋め込み表現を簡単に得ることができません。
一方、GCNやGraphSAGEではノードの特徴量から(サンプルと)集約を繰り返してノードの埋め込み表現を計算するので、未知のサブグラフに対してもノードの特徴量がわかっていれば埋め込み表現を計算することができます。
このような特徴はタンパク質の分類のようにテストデータが未知のサブグラフであるような状況で役立ちます。
エッジ特徴量の活用
実験に移る前に、上記で説明した枠組みの中でグラフ上のエッジ特徴量をどのように扱うかを説明します。
GNNのアーキテクチャではノードの特徴量を中心に考えることが多いですが、はじめの段階でエッジ特徴量をなんらかの方法でノード特徴量に変換することで、元の枠組みで扱えるようになります。
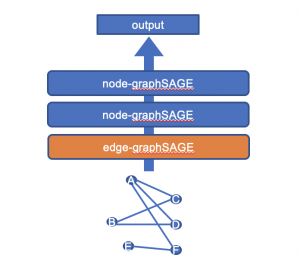
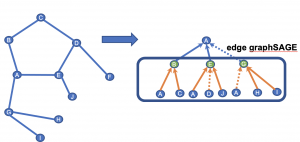
ノード特徴量に対してGraphSAGEを適用するのと同様の方法で、エッジfeatureのサンプルと集約をはじめに行っておくとノードの埋め込み表現が得られます。
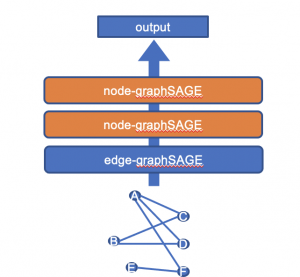
得られたノードの埋め込み表現を使って、通常の方法でGraphSAGEを適用します。
実験
実験ではbitcoinの取引データを使って、似たwalletどうしが近くに集まるようなwalletのembedding表現を学習します。
データセットは以下のようなものになります。
- 期間: 2020-01-01 ~ 2021-05-16
- 取引回数: 241438
- top 10000 walletが関わる取引のデータを利用
エッジのfeatureは次のリストのものを使います。
- 取引回数
- in/out BTC amountのavg/min/max/std
今回は教師なしの設定でトレーニングを行い、得られたwalletの埋め込み表現をいくつかのwalletに関する分類タスクを解くことで評価します。
具体的には埋め込み表現をfeatureとしてロジスティック回帰を行い、10 split CVで性能をチェックします。
- タスク1: top 10000 walletのrank予測(上位から10段階に分割)
- タスク2: top 10000 walletの2020-12のsigned volume予測(どのくらい流入・流出したかを符号付きで10段階に分割)
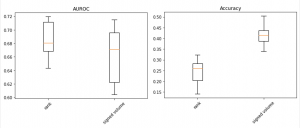
今回の設定ではランダムな予測だとAUROCは0.5, Accuracyは0.1に近くなりますが、埋め込み表現に基づく予測ではある程度二つのタスクで当てられていることがわかります。
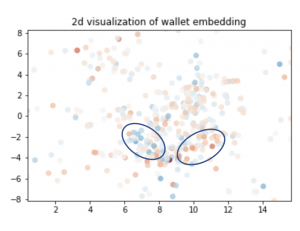
タスク2で得られた埋め込み表現を可視化したのが次の図になります。
2020-12に流入量・流出量がそれぞれ大きかった2つのグループがみてとれます。
まとめ
グラフデータに関連するタスクを解くのに適したアーキテクチャとしてGNNを紹介しました。
その中でGraphSAGEは様々なタスクに応用可能で使いやすい手法ということで、スケーラビリティや帰納的表現などの利点を先行する手法と対比しながら確認しました。
最後にGraphSAGEで得られる埋め込み表現を使って、bitcoin walletの分類タスクを解いてみる実験を行い、似たwallet同士がある程度近くに集まっていることが確認できました。
最後に
次世代システム研究室では、ビッグデータ解析プラットホームの設計・開発を行うアーキテクトとデータサイエンティストを募集しています。興味を持って頂ける方がいらっしゃいましたら、ぜひ募集職種一覧からご応募をお願いします。皆さんのご応募をお待ちしています。
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD