2020.12.18
FPGAに機械学習モデルを実装する –
その1:ランダムフォレストによるクラス分類
こんにちは,次世代システム研究室のS.T.です。普段はHadoopネタを書いていますが,今回はテーマをがらっと変えて,FPGAネタです。
「FPGAに機械学習の推論部分を実装し高速に処理を行う」という技術は耳にしたことがありましたが,漠然としたイメージがあるだけで実際にどのように実装していくのかということは知りませんでした。調べてみると,高位合成を用いた手法(1)や,学術研究として開発されたアクセラレータとしてのアーキテクチャ(2)は存在するようですが,シンプルなサンプルコードの形で存在するものはないようです。
もちろん「ソフトウェアエンジニアやデータサイエンティストが作成したモデルを高位合成でFPGAに落とし込みアクセラレータとして使用する」というユースケースを考えれば納得がいきますし,応用できる範囲もHDLで直接実装するより広くなると思います。
しかし,「低コスト小規模なローエンドFPGAと5Gの低遅延通信を生かしたエッジコンピューティング」の可能性を考えたとき,よりコンパクトに設計しやすいHDLベースのアプローチが効いてくるのではないかと考えたため,今回はHDLを使って機械学習モデルをFPGAに実装することにしました。まずはシンプルに定番の「ランダムフォレストを用いたMNIST手書き文字のクラス分類(画像の手書き文字を当てる)」をFPGAに実装して推論を行い,ソフトウェアの実装と比較してみます。
結果を先に書くと,組み合わせ回路を用いたランダムフォレストの推論器をIntel Cyclone Vにて120個のALMで実装でき,入力・出力間の遅延(処理時間)は約22ns(ソフトウェアは1.4ms)となりました。
1.概要
scikit-learnでMNIST手書き文字のクラス分類モデルをランダムフォレストで作成し,それをVerilog HDLに変換してFPGAに実装することを目指します。
このブログを読んでいる方はソフトウェアエンジニアの方が多いと思いますので,ごく簡単にFPGAそのものがどういったものなのかについて触れた後,本題であるランダムフォレストの実装に入っていきます。scikit-learnで実装したモデルをVerilog HDLに変換するまでの道のりを解説し,シミュレーション結果とFPGA実機で動かした結果を紹介します。
FPGAに関する深い解説や各種用語,ランダムフォレストのアルゴリズム,scikit-learnの使い方については,本記事では触れません。また,モデルの性能はソフトウェア実装と同様になるため,この評価も対象外とします。
2.FPGAとは
FPGA(Field Programmable Gate Array)は,その名前の通り開発現場で書き換え可能な論理ゲートアレイです。ANDやORのような論理ゲートやレジスタ,乗算器などを繋ぎ変えることで,好きな動作の論理回路を作ることができます。「特定の処理専用のハードウェア」のように振る舞うため,ソフトウェアで同じ処理を実装するよりも高速ですが,別の処理を行うためには回路の情報を書き換える必要があり,ソフトウェアほどの柔軟性はありません。また,処理をハードウェアの動作に落とし込むのはソフトウェア開発の手法・知識・ノウハウとはだいぶ毛色が違うため,ソフトウェアエンジニアが新規に学習するコストは大きいでしょう(この点が先に述べたようにC言語やPythonから論理回路を生成する高位合成を用いた手法が台頭している理由だと思います)。
FPGAの振る舞いはHDL(Hardware Description Language:ハードウェア記述言語)で記述します。作成したソースファイルは論理合成や配置配線といったプロセスを経てFPGAに書き込める形式になり,専用のコンフィギュレーションツールを用いて書き込みます。メジャーなHDLとしてVHDL,Verilog HDLの2つがありますが,本記事ではVerilog HDLを用います。
FPGAはXilinxやIntel(旧Altera),Lattice Semiconductorの製品が有名ですが,今回はIntel Cyclone Vを使用します。
3.ランダムフォレストをFPGAに実装する
3-1.環境
今回使用した環境は以下の通りです。FPGAボードの選定理由は偶然所有していたというだけで特に深い理由はありません。言語は使用経験があるためVerilog HDLを選択していますが,VHDLでも同様の実装は可能です。
- FPGAボード:Terasic社 DE0-CV / Intel Cyclone V E 5CEBA4F23C7N
- FPGA開発環境:Quartus Prime Lite 20.1
- FPGA開発言語:Verilog HDL
- シミュレータ:ModelSim Intel FPGA Starter Edition 2020.1
- PC:CPU AMD Ryzen 7 1700X / RAM 32GB / SATA SSD
- ソフトウェア・ライブラリ:Windows 10 / Python 3.6.2 / scikit-learn 0.23.2
3-2.学習
学習はscikit-learnのRandomForestClassifierを使用してサクっと行います。MNISTの画像データ(784次元のベクトル)を2値化したものを学習・推論に用います。今回は性能の良いモデルを作ることは目的ではないので,2値化は20以上が1,それ未満は0という単純な方法で行い,ハイパーパラメータは基本的にデフォルトで,木の本数と深さのみデバッグしやすいように10設定します。もちろん,ハイパーパラメータを最適化してもモデルの構造自体は変わらないため,この記事で紹介する方法を適用することができます。
参考までに,モデル作成部分のコード片を掲載しておきます。
# x_train, y_train, x_test, y_test # に2値化した学習・テストデータを準備しておく rf = RandomForestClassifier(max_depth=10, n_estimators=10) rf.fit(x_train, y_train) rf.score(x_test, y_test) # => 0.9248
3-3.ランダムフォレストの論理回路表現
さて,今回のキモとなる部分です。まずは今回実装するモデルについて整理してみます。
- ランダムフォレストは決定木を束ねたモデルである。
- 決定木は「ベクトルのある要素」が「各ノードが持つ条件」を満たす(True)か否(False)かで辿ることができる木である。
- 特に今回は入力が0または1の2値で構成されたベクトルであるため,各ノードの条件は「ベクトルのある要素」が1か否かである。
つまり,木の各ノードの出力は以下のように表現できます。
これを葉まで辿って,葉に紐付いているクラスがその木の識別結果となります。あとはそれぞれの木(今回は10本)で同じ操作を行い,最も多く識別結果として採用されたクラスが全体の識別結果となるわけです。
さて,ここから徐々に思考を論理回路チックにしていきます。先に示した各ノードの出力を表す式は「自身に入る枝が選択されている」と「ノードが指定したベクトルの要素」の2つの信号のANDをとったものと考えることができます。つまり,ノード1つは図1のように2入力ANDゲートとみることができます。1点注意しなければならないのは,決定木は「自身に入る枝が選択されている」条件が満たされない場合は「そのノードに到達していない」わけですから,TrueもFalseも0が出力されるということです。

「前のノードの出力」が1というのは,「自身に入る枝が選択されている」と対応します。これを前提条件として「ノードが指定したベクトルの要素」が1のときに図1の上のゲートの出力は1になりますから,ノードの条件がTrueの場合に1を出力する回路となります。反対に,条件がFalseの場合は「ノードが指定したベクトルの要素」が0であることが条件なので,入力にNOTをつければよさそうです。このANDゲートのTrueとFalseの出力を枝とみて,2つのANDゲートの組を次々に繋げることで,図2のように決定木を論理回路で表現することができます。

図の左側の決定木を論理回路で表現すると右側のようにANDゲートをたくさん並べたものになります。最後に到達した葉ノードのみ出力が1になるため,以下のようにラベルごとに葉ノードの出力のORをとることで,識別結果を得ることができます。。
最後にそれぞれの木が出力したラベルから多数決で最終的な識別結果を判断します。今回は単純にトーナメント方式で,同点の場合は「ラベルの値が小さいほう勝ち」で決定したいと思います。抜粋すると下記の式のようになります。多数決の取り方がscikit-learnのモデルと異なる場合,同点の識別結果に差がでますが,今回はそこは考えないことにします。
1つ1つはシンプルですが,木全体,さらに複数の木を束ねるとなると,なかなの回路規模になります。これを汎用ロジックICを使って実装するのは骨が折れると思いますが,今回はソースコードから回路を作れるFPGAの強みを活かし,ソースコードを生成することで実現するわけです。
3-4.Verilog HDLコードへの変換
ランダムフォレストを論理回路で表現できることがわかったので,scikit-learnで学習したモデルを元ネタにして,Verilog HDLのソースコードを生成します。
実際に変換を行うコードはこちらです。create_rf_module関数に作成するモジュールの名前とランダムフォレストのモデルを渡すと,Verilog HDLコードの文字列が返却されます。あとはこれをファイルに書き出せば,Verilog HDLのランダムフォレストモジュールの完成です。このVerilog HDLモジュールをFPGAの開発環境にインポートし,784次元のMNIST手書き文字画像をそのまま784ビットの入力信号として接続すると,4ビットの識別結果(2進値)が得られます。
中身を詳しく見てみます。create_rf_module関数は,前半部分で木1本分の処理を担当するcreate_tree_function_wire関数を呼び出しながら,与えられたモデルの情報を使って決定木を1本ずつ組み立てます。後半部分のVerilog HDLのソースコードをそのまま出力している部分では,トーナメント形式で識別結果を決定を行っています。キモとなるのは前半部分,特にcreate_tree_function_wire関数です。
scikit-learnのランダムフォレストモデルは,下記のようなメンバ変数を持っています(使用する部分のみ抜粋)(3)。
- estimators_[M]:識別器の配列。今回は要素数M=10となる。
- tree_:決定木(ノード数N)の情報が格納されている。
- feature[N]:各ノードが注目するベクトルの要素番号。
- children_left[N]:各ノードの条件がFalseのときの移動先(負なら葉)。
- children_right[N]:各ノードの条件がTrueのときの移動先(負なら葉)。
- value[N]:そのノードの識別結果(葉の場合に見る)。
つまり,n番目のノードは入力ベクトルの「feature[n]番目」が1であれば「children_right[N]番目」のノードに進み,0であれば「children_left[N]番目」のノードに進むわけです。また,n=0が根ノードであり,必ず木の上側のノードほどnが小さい値をとります。create_tree_function_wire関数では,n=0から1,2,3…(つまり木の上側から)と順番に処理をして,ノードの繋がりを記録しながら回路を構築していきます。
3-5.周辺回路の実装
無事に推論部分のモジュールを作ることができたので,次にこのモジュールに対する入力や出力を処理する部分を作っていきます。図3に今回のシステムの構成図を示します。
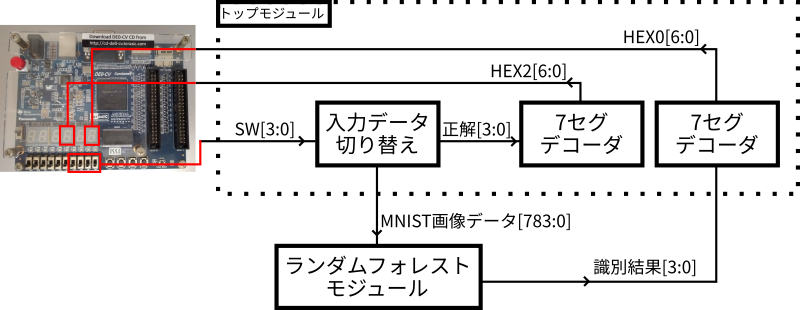
ランダムフォレストモジュールを中心に据え,他の機能はすべてトップモジュールに実装します。入力は,予め準備しておいた16種類の画像をDE0-CVに実装されているスイッチSW[3:0]を使って切り替えることにします。元ネタとなる画像は学習に使わなかったテストデータから拝借してくることにします。出力はデコーダ(2進値→点灯パターン変換回路)を通して7セグメントLED(7セグ)に接続して,識別結果を確認できるようにします。参考のため,正解データも入力と一緒にスイッチで切り替え,7セグに表示しておきます。
開発環境であるQuartusを使って実装していきます。FPGAのピンと直接つながるトップモジュールを作成し,内部に上述の回路を実装します。といっても,定数をスイッチで切り替える組み合わせ回路なので,実装は非常にシンプルです。そして,生成したランダムフォレストモジュールをインポートし,トップモジュールから呼び出します。
余談ですが,DE0-CVには6桁も7セグが実装されていますが,贅沢なことにそのすべてのピンがFPGAのピンと1対1で接続されており,ダイナミック駆動を実装する必要がありません。とても便利ですね。
3-6.シミュレーション
トップモジュールの入力信号を操作してシミュレーションを行うためのモジュールを作成します。スイッチの信号SW[3:0]を切り替えてランダムフォレストモデルの入力データを変化させ,各決定木の出力と最終的な識別結果を観測してみます。テストベンチは特に複雑なことはせず,時間経過でSW[3:0]の値を変更するのみとします。ModelSimによるシミュレーションの実行結果を図4に示します。画面左側が信号名,右側が観測信号です。最初はSW[3:0]=0からスタートし,画面の半分あたりで1に変化しています。
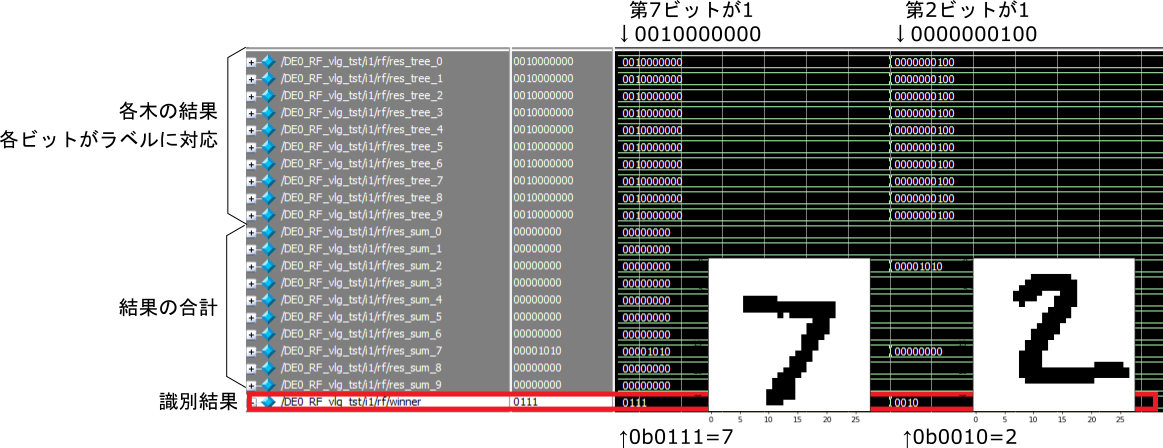
上半分が,それぞれの決定木が出力した結果で,各ビットがラベルに対応しています。第0ビット(一番右)が0,第9ビット(一番左)が9といった具合です。下半分は多数決を行うための各木が出力した結果の合計で,この値が最も大きいクラスが識別結果(最下段)です。
SW[3:0]=0のときは図中の手書き文字「7」,1のときは「2」が入力として与えられており,識別結果はそれぞれ7,2と正解です。このケースでは10本の木すべてが正解のラベルを結果として出力しており,下半分の合計値もSW[3:0]=0のときにラベル7が10,そして0から1に切り替わると,ラベル7は0に変化しラベル2が10に変化しています。シミュレーション結果は問題なさそうです。
3-7.実機での実行
さて,いよいよ実機でも実行です。今回の回路は組み合わせ回路で外部デバイスとの連携もないため,シミュレーション結果に問題がなければ動作するはずですが,実際に動かすまではドキドキです。論理合成や配置配線のプロセスを完了し,コンフィギュレーションを実行します。では,実際の動作している様子をご覧ください。左が正解,右が識別結果です。
問題なく分類できており,良い感じです。もちろん,人間の目で感じられる遅延はありません。繰り返しになりますが,モデルの性能はソフトウェア実装と同じになるはずですから評価の対象とはしません。が,SW[3:0]=0x8のときに間違ったラベルを出力しています。参考までに,この手書き文字画像を図5に示します。

まあ,これは間違えても仕方ないですね。。。
合成時のレポートを見ると,ALM(IntelのFPGAで論理回路を作るための機能)の使用率は120 / 18,480 ( < 1 % )となっており,Cyclone Vではまだまだ余裕があります。より複雑なモデルを実装したり,複数のモデルを並列で動かしたりすることができそうです。
さて,完全に挙動が一致することまでは確認していませんが,当初の目的どおり,scikit-learnで作成したランダムフォレストモデルからVerilog HDLのコードを生成し,FPGA上でクラス分類を行うことができました。技術的に可能なことは既知でしたが,論理回路でこのような仕組みが動いているのを目の当たりにすると少しワクワクしますね。
引き続き,もう1つの目的であるパフォーマンス面の比較を行います。
4.遅延の評価
4-1.伝搬遅延
今回実装したランダムフォレストモデルは組み合わせ回路によるものでした。組み合わせ回路は出力が入力の信号から一意に定まる回路,つまり入力が変化すれば即座に出力にも反映される回路です。しかし,その中身は論理ゲートを組み合わせた回路,もっと言えばトランジスタなどを用いた電気回路です。
今回のランダムフォレストモデルは,回路の入力ポートに0(電圧低)または1(電圧高)の信号784本を繋ぐと,出力ポートに4本の0または1の信号が出てくる電気回路として見ることができます。電気回路は電子が移動することで動作するものですから,入力が変化してから出力が変化するまでに伝搬遅延が生じます。今回は,この伝搬遅延を実質的な「推論に要する時間」と考え,ソフトウェア実装の処理時間となる「predictを呼び出してから結果を得るまでの時間」と比較します。
伝搬遅延のシミュレーション結果は,QuartusからTiming Analyzerを起動して,Report Pathから確認することができます。FPGAは同じ製品であっても製造時の誤差や温度や電圧などの条件により動作速度が変化するため,シミュレーション結果は複数出力されます。図6に最も遅い条件(Slowコーナー)での入力(SWの変化)から出力(HEXの変化)までの伝搬遅延を示します。

Delayの項目に表示されているものが伝搬遅延です。単位はデフォルトでナノ秒なので,この回路の遅延は22.388nsということになります。これは,例えば入力信号が30MHzのクロックに同期して変化しても追従できるわけですから,カメラの映像に対するリアルタイム処理にも耐えられる性能です。
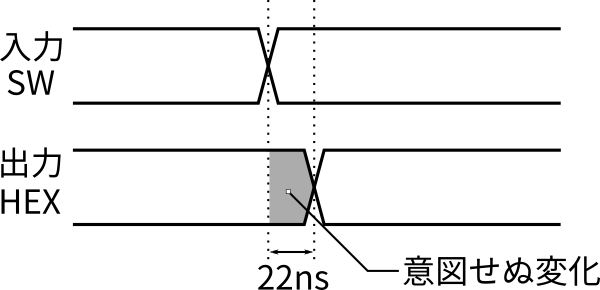
あくまでも電気回路ですから,入力をしてから出力を得るまでのプロセスは,ソフトウェアとは異なります。ソフトウェアでは順次命令を実行して変数に処理結果を受けることになります。しかし,回路ではこの22nsの間にそれぞれの決定木やトーナメントの出力が次々に変化し,最終的に識別結果が安定するわけです。つまり,図7に示すように,22nsの間は短い周期で変化するノイズ(グリッチノイズ)が出現することになります。今回は7セグに結果を表示するだけなので問題にはなりませんが,他の回路と連携する場合は対策が必要になることもあります。
4-2.ソフトウェアとの比較
3-2.学習で実装したscikit-learnのモデルと処理速度を比較します。3-1.環境に示したPC上で,predictの実行にかかる時間をtimeitモジュールで計測したところ,1.4msでした(10回の平均)。FPGAの実装と比べると,10の5乗オーダの差があります。これは一般的なPCによる計測ですから,処理速度の低いMPUを搭載したエッジデバイスではさらに実行時間が長くなります。
このように,FPGAによる(単純な組み合わせ回路での)ランダムフォレストの実装はソフトウェアに比べて非常に高速という結果が得られました。また,FPGAは低コストのモデルに置き換えてもMPUに比べて速度の低下が少ない(回路規模は小さくなる)ため,エッジコンピューティング用デバイスで高速な推論処理を実行したい場合に有利です。一方,推論結果をソフトウェアで処理したい場合,MPUとの通信のオーバヘッドが発生し,利点が小さくなります。
4.まとめ
scikit-learnのRandomForestClassifierで学習したMNISTクラス分類器をVerilog HDLに変換し,FPGA実機で動かすことができました。処理速度もソフトウェア実装が1.4msであるのに対し,FPGA実装は22nsと非常に高速でした。
今回はランダムフォレストを用いましたが,決定木のアルゴリズムであればランダムフォレスト以外でもこの記事で紹介した手法が利用できるでしょう。また,回路規模は大きくなりますが,2値画像ではなくグレースケールやRGB信号を入力とした推論にも応用可能です。
一方,推論結果を別の処理に使用する際の柔軟性に欠ける点が大きな欠点です。これらの欠点を補う方法としては,以下のものが使えそうです。
- FPGAに外部からの入力取り込みから結果処理を行う回路を実装する:パフォーマンス高・実装コスト高
- Nios IIのようなソフトコアプロセッサを実装しカスタム命令などで連携する:パフォーマンス中・実装コスト中
- 大量の推論を並列に実施してまとめてMPUに連携:回路規模大
いずれの手法も実装コスト,パフォーマンス,回路規模,柔軟性などがトレードオフの関係にあります。推論結果の他機能との連携やモデルの高性能化を考えると,今回実装した組み合わせ回路では限界がやってきます。パフォーマンスは低下しますが,順序回路化し,パイプライン処理ができるようにする,しきい値をハードコードではなくパラメータ化するなどの工夫が必要になるでしょう。
今回の実装により,HDLを使ってFPGAに機械学習モデルを実装するイメージがつきました。次回は上記の欠点を解決するようなテーマの記事を執筆したいと思います。
最後に
次世代システム研究室では,データサイエンティスト/機械学習エンジニアを募集しています。ビッグデータの解析業務など次世代システム研究室にご興味を持って頂ける方がいらっしゃいましたら,ぜひ募集職種一覧からご応募をお願いします。皆さんのご応募をお待ちしています。
参考文献
- (公開版)FPGAエクストリームコンピューティング2017
- J. Oberg, K. Eguro, R. Bittner, and A. Forin, “Random decision treebody part recognition using FPGAs”, 22nd International Conference on Field Programmable Logic and Applications (FPL), 2012
- 3.2.4.3.1. sklearn.ensemble.RandomForestClassifier
※Web上の文献は記事公開日時点の情報です。
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD