2021.04.06
フルマネージドサービス+Feast(onK8S)で構築するレコメンドサービス基盤
「AIの民主化」という言葉もありますが、昨今クラウドベンダにおいては簡単に誰でも機械学習を利用できるサービスが出てきています。GCPのAutoMLに始まり、AWSのAmazon Personalizeなど様々なサービスがローンチされていますね。我々エンジニアとしてはこれらを活用しつつ最速で最大限の成果を上げることが求められる時代となりました。
そこで今回はGCPのRecommendatios AIを利用しつつ、Feast/BigQueryでも解析・機械学習できる基盤の例をご紹介したいと思います。
あくまでサンプルであるのですが、皆様のアイディアの種の一つとなれば幸いです
GCPのRecommendatios AIとは
Recommendations AIとはいわゆるレコメンドを提供するフルマネージドサービスです。
ショッピングサイトなどにある「おすすめ商品」や「他の人はこれも買っています」を実現するサービスだと思えばよいかと思います。
機械学習でいうと協調フィルタリングやFactorization Matrixなどで実現できる機能ですね
利用できるモデルタイプ
利用できるモデルタイプはアルゴリズムの種類ではなく、実現したい機能で選択することとなります。
機能は4つ存在しており、「関連商品のおすすめ」「よく一緒に購入される商品」「あなたへのおすすめ」「最近表示した商品」になります。
またこれを最適化する目標に「CTR」「CVR」「注文あたりの収益」があり、これを4つの機能と合わせて実現したいモデルを選択することになります
利用データと取り込み方法
Recommendations AIでは、大きくわけて「カタログ」と「イベント」の2つを利用します
カタログ
商品カタログをあらわすデータとなります
内容はSKU単位であったりITEM単位であったりや画像価格など様々なものが登録できるのですが、最低限ではID/商品名/カテゴリ名程度あれば問題ありません
取り込みも定期的にバッチで投入することが多いかと思います
例(movieLens):
id,title,categories
777,Pharaoh’s Army (1995),War
イベント
こちらはユーザがどういったページを閲覧し、購入したかなどの行動データとなります。
イベントは以下の7種類存在しており、細かな粒度でデータ収集することが可能です。
- add-to-cart: 商品をカートに追加
- category-page-view: セールページやプロモーション ページなどの特別なページを表示する
- detail-page-view: 商品の詳細ページを表示する
- home-page-view: ホームページを表示する
- purchase-complete: 購入手続きを完了する
- 検索: カタログを検索する
- shopping-cart-page-view: ショッピング カートを表示する
これらのユーザ行動イベントは当然ユーザ閲覧ごとに収集する必要があります。
「JavaScriptピクセル」「GA360を利用」「APIを利用」などの種類があります。
例えば以下がJavaScriptの例となります。(詳細はGCPドキュメントをご覧ください)
<script type="text/javascript">
var user_event = {
"eventType" : "detail-page-view",
"visitorId": "visitor-id",
...
};
var _gre = _gre || [];
// Credentials for project.
_gre.push(['apiKey', 'api-key']);
_gre.push(['logEvent', user_event]);
...
(function() {
var gre = document.createElement('script'); gre.type = 'text/javascript'; gre.async = true;
gre.src = 'https://www.gstatic.com/retail/v2_event.js';
var s = document.getElementsByTagName('script')[0]; s.parentNode.insertBefore(gre, s);
})();
</script>
こまったこと
Recommendations AIはデータ収集から学習、推測、効果分析までは包括的に扱う非常に優れたサービスだと感じています。
ただ一つ困ったことに「ユーザイベントが他で扱いにくい」という点がありました。
せっかくここかまでデータを集めるのですからBQで分析もしたいし、他の機械学習でデータも使ってみたいと思うのがエンジニア心なのかなと。
一応API v1にはuserEventを取得するものはあるのですが、RetailsAPIに移行したv2ではそれもなくなっており、なかなか取得が難しいと感じていました。
(v1自体はomitされておらずまだ使えるようではありますが)
そこで今回はRecommendations AIを利用しつつ、Feature Store/BQを組み合わせてクラウドネイティブな基盤例をちょっと考えて見たので、ご紹介いたします
フルマネージドサービス + Feast(onK8S)で構築するレコメンドサービス基盤
ここではReccomendations AIに投入すると同時にBQ + Feature Storeに格納してみます
Trackerに送信されたユーザイベントをそれぞれ用のQueue(Pub/Sub)に投入することによって、障害対応などを分離して考えられるようにしています
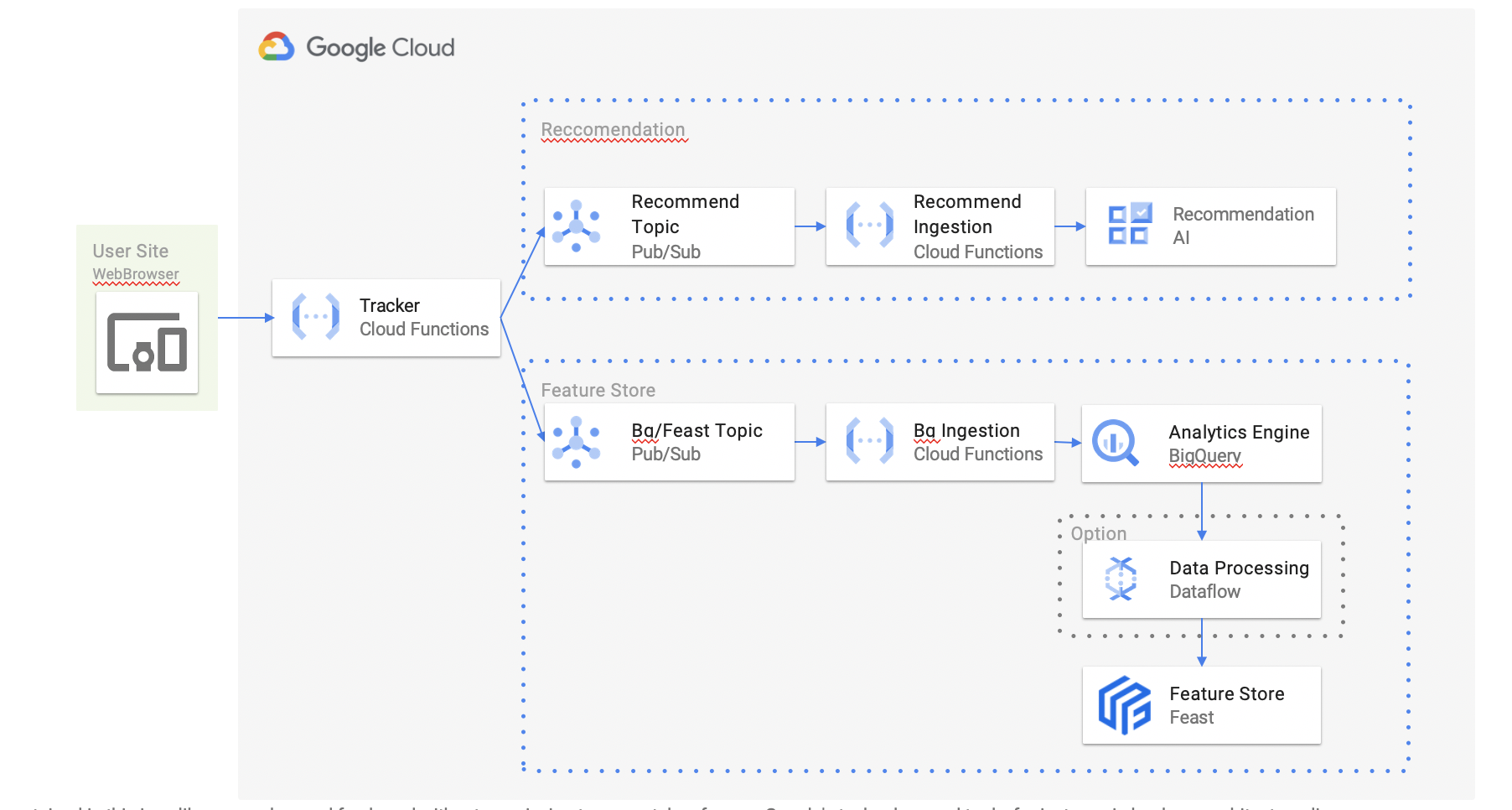
環境構築
Feast on GKE
GCPにはFeature Storeサービスがまだ現時点ではないため、ここではFeastを構築することにします。
Feast自体は色々な構築の仕方があるのですが、今回はクラウドネイティブっぽくGKEを利用しています
まずGKEクラスタを作成します
gcloud container clusters create feast-cluster \
--machine-type n1-standard-1 \
--num-nodes 3 \
--zone us-central1-a \
--scopes=bigquery,storage-rw,compute-ro
次にローカルのkubectlでGKEクラスタに接続するため認証情報を取得します
gcloud container clusters get-credentials feast-cluster --zone us-central1-a kubectl create secret generic feast-gcp-service-account --from-file=./service_account.json
もし複数K8S環境を利用している場合はkubectxを使うと便利です
これで複数環境を意識せずに利用することが出来ます
brew install kubectx kubectx gke_[PROJECT_ID]_[REGION]_[CLUSTER_NAME]
これでサーバ上とローカルの環境は完了になりますので、次にFeastをInstallしましょう。
Feastは非常に新設でTerraformなどのインストールスクリプトが大量に用意されています
ここではその中でHelmを使ったインストール方法を選択してみました
まずはhelm自体をInstallします
brew install kubernetes-helm
次にfeast用のrepoを登録します
helm repo add feast-charts https://feast-charts.storage.googleapis.com helm repo update
その後で内部利用されるpostgresql設定をした上で、
kubectl create secret generic feast-postgresql --from-literal=postgresql-password=password
最後にfeastをhelm経由でインストールすれば終わりです
helm install feast-release feast-charts/feast
一定時間経過後podsを確認すると関連pods出来ているのが分かります。
Jupyterも立ち上がっているので、そこから色々試すことも出来ますね
kubectl get pods NAME READY STATUS RESTARTS AGE feast-release-feast-core-bf9f5486-j5qw9 1/1 Running 4 21h feast-release-feast-jobservice-669ddd4d96-q6j46 1/1 Running 0 21h feast-release-feast-jupyter-86f657cb97-9q5pf 1/1 Running 0 21h feast-release-feast-online-serving-85f7fd6d58-v9wh2 1/1 Running 2 21h feast-release-grafana-d97bdf9cd-qlcqz 1/1 Running 0 21h feast-release-kafka-0 1/1 Running 0 21h feast-release-kube-state-metrics-58c65f9d79-4ln9g 1/1 Running 0 21h feast-release-postgresql-0 1/1 Running 0 21h feast-release-prometheus-alertmanager-587f984dd-4gbdz 2/2 Running 0 21h feast-release-prometheus-node-exporter-5zm95 1/1 Running 0 21h feast-release-prometheus-node-exporter-86nq5 1/1 Running 0 21h feast-release-prometheus-node-exporter-8mpb7 1/1 Running 0 21h feast-release-prometheus-pushgateway-78fbb846c-bx5h4 1/1 Running 0 21h feast-release-prometheus-server-866c8f7b9-p5tvw 2/2 Running 0 21h feast-release-prometheus-statsd-exporter-858447655b-hmrlp 1/1 Running 0 21h feast-release-redis-master-0 1/1 Running 0 21h feast-release-redis-slave-0 1/1 Running 0 21h feast-release-redis-slave-1 1/1 Running 0 21h feast-release-zookeeper-0 1/1 Running 0 21h
その他
それ以外は関連する機能を随時登録します。
今回はPub/Subのトピックだけを事前に作成すればよいかと思います
gcloud pubsub topics create TobqToFeaset gcloud pubsub topics create ToRecommend
各種機能概要
WebBrowser
ブラウザ側には通常の場合RecommendationsAIのJavaScripitピクセルを配置することになりますが、今回はBQ/Feastにもデータ送信したいのでこれを取得する必要があります。
やり方は複数あると思います。例えば公式のJavaScriptピクセルを改造して、複数宛先に飛ばしていいかもしれません。
今回は簡単のため、非表示のimgタグを置いてこれをTrackerと想定することにしましょう。
例えばこんな感じですかね。もちろんをこれを作成するJavascriptライブラリは必要ですが、ここでは方法だけを提示し、省略します。
<IMG SRC="https://hoge.com/send?event=detail_page&product_id=111..." style="display:none" ALT="">
Tracker
Tracker側では先程のイメージタグからの送信を受け取って、これをPub/Subに投入します。
今回はCloud Functionsの利用を想定しています。
当然大量のリクエストがあるので、自動でスケールし、且つ状態を持たないFunctionsが最も良いかという判断です。
上でのGKEを使っているので同じK8SベースのCloudRunという選択肢も悪くないのかもしれません
コード例は以下のような感じになるかと思います。
受け取ったメッセージを2つのPub/Subに送信しています
def get_args(request, name):
request_json = request.get_json(silent=True)
request_args = request.args
if request_json and name in request_json:
return request_json[name]
elif request_args and 'name' in request_args:
return request_args[name]
else:
return ''
def push_to_bq_and_recommend(request):
from google.oauth2 import service_account
info = json.load(open("./service_account.json"))
credentials = service_account.Credentials.from_service_account_info(info)
# Cloud Pub/SubのTopic準備
publisher = pubsub_v1.PublisherClient(credentials=credentials)
topic_bq = publisher.topic_path(project_id, 'TobqToFeaset')
topic_recommend = publisher.topic_path(project_id, 'ToRecommend')
# 送信データを作成
message = {"eventType": get_args('event'), "product_id": get_args('product_id'), "user_id": get_args('user_id')}
message = json.dumps(message)
# トピック送信
future_bq = publisher.publish(
topic_bq, data=now.encode("utf-8"), user_info=message
)
future_rec = publisher.publish(
topic_recommend, data=now.encode("utf-8"), user_info=message
)
Recommendation Ingestion
送信されたイベントデータはRecommendationsAIに渡さなければ当然いけません。
今回はブラウザ側から直接送信しませんでしたが、任意のタイミングでAPIを叩くことで、データ登録することが可能であるため今回はそちらの方法を利用します
例えば以下のようなPOSTをFunctinsから送信することでこれが可能であります。
Trackerから直接送信するという手もあるのですが、その場合POSTが失敗した場合のエラーハンドリングがかなり煩雑になるため一回Pub/Subに送信しています。
これによりエラー発生時はReQueuingなどで対応することができ、運用がシンプルになることを狙っています
import requests
user_events_url = "https://retail.googleapis.com/v2/projects/[PROJECT_ID]/locations/global/catalogs/default_catalog/userEvents:write"
response = requests.post(user_events_url,
data={"visorId": visitor_id, 'eventTime': eventTime, "event_type": event_type, "productDetails":["product":{"id":product_id}]})
BQ Ingestion/Feast
あとは2股に別れたBQ/Feastにデータを登録すれば完了です。
BQへの登録は一番手っ取り早い方法は来たたびにInsertする方法ですね
rows_to_insert = [
{u"visorId": visitor_id, u"event_type": event_type, u"productDetails":[u"product":{u"id":product_id}]},
]
res = bigquery_.Client(project=PROJECT_ID).insert_rows_json(table_id, rows_to_insert)
ただしBQのInsert処理はストリーム処理となります。
これは「InsertしてからBQ上でデータが反映されるまでに一定時間の経過が必要」な処理であることを注意する必要があります。
長い場合は時間単位でかかることもあります。これによってFeastへのIngestion時の差分処理に影響を与える可能性もあるので注意してください。
ファイルをGCSに上げ、そこからImportする方法であれば即時反映になるため問題がある場合はこちらを利用してもよいかと思います
あとはFeast側にBQからInsertすればOKです
Feastの詳しい説明は別メンバが記載する予定ですので、詳細はそちらを御覧ください。
BigQuerySourceというものが用意されているのでこれを利用すればBQからのIngestionは容易ではあります
event_source = BigQuerySource(
table_ref="PROJECT_ID.DATASET.user_event",
event_timestamp_column="eventTime",
created_timestamp_column="eventTime",
)
なぜFeast?
ちなみにFeature Storeというのを初めて聞いた方は「なぜBQだけじゃ駄目なの?」という疑問も持たれるかもしれません。
私は以下の2つの理由でFeature Storeを使った方が便利なのかなと思っています。
1. データ統合の観点
- 複数モデルを運用している場合は、それごとにデータをバラバラに持つと管理が煩雑
- また各モデルがどの時点の、どのデータを利用しているかわかりにくい
- Feature Storeを利用することにより、データの場所・取り出し方法が統一化され、いろいろなモデル間で統率が取れる
2. 前処理の効率化
- モデルトレーニングごとに前処理を実施することが多いが、本来は一回でいいはず
- Feature Storeに(Dataflowなどで加工した)前処理後の特徴量を管理することで、前処理の効率化が図れる
- また複数モデルで利用している前処理を把握でき、新しいFeatureEngineeringの発見にもなる
上記アーキテクチャはフルマネージドを利用しながら、Feature Storeを利用し、他の複数モデルの効果を高める一つの案であると思います。
AI時代が加速すれば複数モデル運用は当たり前となりますし、いろいろなサービスを利用しつつもFeature Storeなど特徴量をいかに効率的に管理するかの視点は忘れないようにしたいものです。
次世システム研究室では、ビッグデータ解析プラットホームの設計・開発を行うアーキテクトとデータサイエンティストを募集しています。興味を持って頂ける方がいらっしゃいましたら、ぜひ 募集職種一覧からご応募をお願いします。
一緒に勉強しながら楽しく働きたい方のご応募をお待ちしております。
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD





