2022.10.11
次世代生成モデル、Diffusion Modelの紹介
こんにちは。次世代システム研究室のA.Z.です。
今回は最近話題になっている、確率モデル+深層ニューラルネットワーク(統合モデル)の一つのdiffusionモデルについて紹介したいと思います。
はじめに
すでに、ご存知の方が多いかもしれませんが、最近話題になっている生成用の機械学習モデル、Stable DiffusionやDall-Eなど、性能が高い生成アルゴリズムやシステムにDiffusionモデルというコンセプトが採用されています。生成モデルとモデルといえば、最初に一番良く知られているのはGAN(Generative Adversarial Network)ですが、その後、他の有名な手法Variational Auto Encoder(VAE)も出てきました。Diffusion modelはVAEと同じく、確率グラフィカルモデル(Probabilistic Graphical Model)と深層ニューラルネットワークの技術を組み合わせをし、hybrid modelの一つです。また、VAEとdiffusion modelは以下の部分が似いていて、diffusion modelはVAEの発展形のモデルとしてよく言われています。
- 生成プロセスは学習した分布から潜在変数をsamplingし、ニューラルネットワーク上に変化させ、という生成プロセス
- モデルのloss関数の計算方法はにいています(Variational Inference, Reparameterization Tricksなど)。
Diffusion modelについて
Diffusion Modelとは一言いうと、まず少しずつもの壊して、その壊れた状態から復元するというコンセプトです。具体的に、オリジナルデータに対して、各ステップ tに対して、少しずつGaussian Noiseを入れて(Forward process)、T ステップまで行います。Tは大きいければ、最終的にXTは完全にgausian 分布になり、そこから、少しずつnoiseを取り除いて、もとの画像を戻すという学習を行います。
Forward Process:
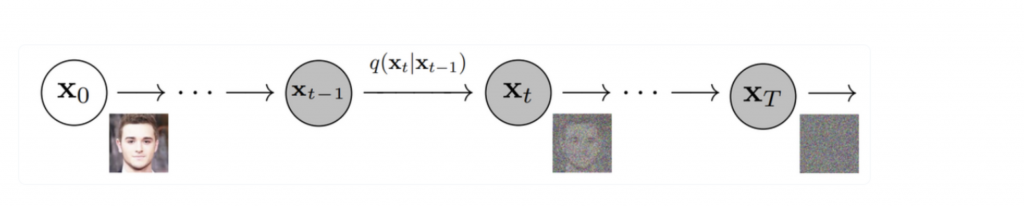
引用:https://lilianweng.github.io/posts/2021-07-11-diffusion-models/
Reverse Process:

引用: https://lilianweng.github.io/posts/2021-07-11-diffusion-models/
Forward processは基本的にgaussian分布からnoiseを適用し、そして、Reverse processsで、少しずつ加えたnoiseを取り除いてい、各ステップで、元のデータを戻すパラメータを学習する。学習が完了すれば、完全なrandom noiseから、データ生成することができます。
次は各重要な部分をかんたんにに詳しい内容とコードを説明します。
今回は基本的に以下のsampleコードをベースにかんたんにし
https://keras.io/examples/generative/ddim/
元の論文:
DENOISING DIFFUSION IMPLICIT MODELS (J.Song, et.al 2020)
https://arxiv.org/pdf/2010.02502.pdf
いくつか元の論文や実装が異なる部分がありますが、基本的にコンセプトや処理のアイデアは同じで、実装のときの入門としてはわかりやすいと思います。
Forward Process
元のデータ(x0)は少しいずつGausian Noiseを加えて、最終的にXTにするのは基本的に以下の式で、定義されます。
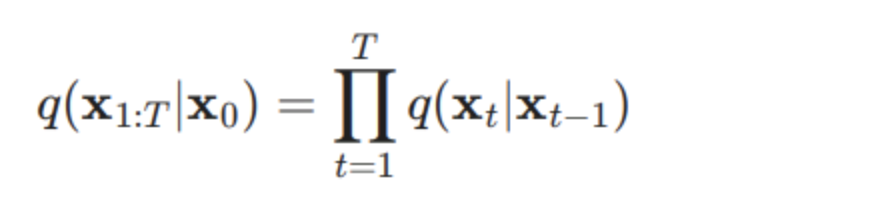
tのときにxの値(xt)は基本的に前のt-1の値に依存します。t-1の値から、以下の式でgaussian noiseに加えます。
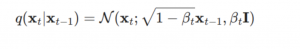
上記の式は各ステップのβが違う値として、設定必要です。基本的に、各ステップで、βの値が徐々に大きなれば良いですが、普通のdiffusionモデルではβの値はモデルで学習させることが多いですが、参考した実装のコードは以下の関数として定義されます。なので、tの値によって、すぐに計算できて、推論時に、自由にstepのサイスや値を変更できます。
def sinusoidal_embedding(x):
embedding_min_frequency = 1.0
frequencies = tf.exp(
tf.linspace(
tf.math.log(embedding_min_frequency),
tf.math.log(embedding_max_frequency),
embedding_dims // 2,
)
)
angular_speeds = 2.0 * math.pi * frequencies
embeddings = tf.concat(
[tf.sin(angular_speeds * x), tf.cos(angular_speeds * x)], axis=3
)
return embeddings
def get_network(image_size, widths, block_depth):
noisy_images = keras.Input(shape=(image_size, image_size, 3))
noise_variances = keras.Input(shape=(1, 1, 1))
e = layers.Lambda(sinusoidal_embedding)(noise_variances)
.....
そして、Forward processはかんたんに、元のデータに、計算したnoiseに追加するだけです。このおかげで、stepごとのnoiseパラメータが学習が不要になり、全体のアーキテクチャがシンプルになります。
#sample uniform random diffusion times
diffusion_times = tf.random.uniform(
shape=(batch_size, 1, 1, 1), minval=0.0, maxval=1.0
)
noise_rates, signal_rates = self.diffusion_schedule(diffusion_times)
# mix the images with noises accordingly
noisy_images = signal_rates * images + noise_rates * noises
Reverse Process
Reverse Processは元の論文はかなり複雑ですが、今回のsampleコードではかなりsimpleになり、基本的にnoiseが加えたデータに対して、作成したネットワーク構造で、逆予測し、予測データ(画像)と予測noiseを分解し、徐々に元のデータと近づくような処理を行います。
with tf.GradientTape() as tape:
# train the network to separate noisy images to their components
pred_noises, pred_images = self.denoise(
noisy_images, noise_rates, signal_rates, training=True
)
noise_loss = self.loss(noises, pred_noises) # used for training
image_loss = self.loss(images, pred_images) # only used as metric
gradients = tape.gradient(noise_loss, self.network.trainable_weights)
self.optimizer.apply_gradients(zip(gradients, self.network.trainable_weights))
self.noise_loss_tracker.update_state(noise_loss)
self.image_loss_tracker.update_state(image_loss)
def denoise(self, noisy_images, noise_rates, signal_rates, training):
# the exponential moving average weights are used at evaluation
if training:
network = self.network
else:
network = self.ema_network
# predict noise component and calculate the image component using it
pred_noises = network([noisy_images, noise_rates**2], training=training)
pred_images = (noisy_images - noise_rates * pred_noises) / signal_rates
return pred_noises, pred_images
画像生成の例
基本的に、画像生成するコードは生成できます。
def diffusion_schedule(diffusion_times, min_signal_rate, max_signal_rate):
start_angle = tf.acos(max_signal_rate)
end_angle = tf.acos(min_signal_rate)
diffusion_angles = start_angle + diffusion_times * (end_angle - start_angle)
signal_rates = tf.cos(diffusion_angles)
noise_rates = tf.sin(diffusion_angles)
return noise_rates, signal_rates
def generate_images(diffusion_steps, stochasticity, min_signal_rate, max_signal_rate):
step_size = 1.0 / diffusion_steps
initial_noise = tf.random.normal(shape=(num_images, image_size, image_size, 3))
# reverse diffusion
noisy_images = initial_noise
for step in range(diffusion_steps):
diffusion_times = tf.ones((num_images, 1, 1, 1)) - step * step_size
next_diffusion_times = diffusion_times - step_size
noise_rates, signal_rates = diffusion_schedule(diffusion_times, min_signal_rate, max_signal_rate)
next_noise_rates, next_signal_rates = diffusion_schedule(next_diffusion_times, min_signal_rate, max_signal_rate)
sample_noises = tf.random.normal(shape=(num_images, image_size, image_size, 3))
sample_noise_rates = stochasticity * (1.0 - (signal_rates / next_signal_rates) ** 2) ** 0.5 * (
next_noise_rates / noise_rates)
pred_noises, pred_images = model([noisy_images, noise_rates, signal_rates])
noisy_images = (
next_signal_rates * pred_images
+ (next_noise_rates ** 2 - sample_noise_rates ** 2) ** 0.5 * pred_noises
+ sample_noise_rates * sample_noises
)
# denormalize
data_mean = tf.constant([[[[0.4705, 0.3943, 0.3033]]]])
data_std_dev = tf.constant([[[[0.2892, 0.2364, 0.2680]]]])
generated_images = data_mean + pred_images * data_std_dev
generated_images = tf.clip_by_value(generated_images, 0.0, 1.0)
# make grid
generated_images = tf.image.resize(generated_images, (plot_image_size, plot_image_size), method="nearest")
generated_images = tf.reshape(generated_images, (num_rows, num_cols, plot_image_size, plot_image_size, 3))
generated_images = tf.transpose(generated_images, (0, 2, 1, 3, 4))
generated_images = tf.reshape(generated_images, (num_rows * plot_image_size, num_cols * plot_image_size, 3))
return generated_images.numpy()
以下のコードで、画像生成するために、最初の値(noise)が完全にランダムになって、その後、花の形にきれいに生成されることわかります。
<code>initial_noise = tf.random.normal(shape=(num_images, image_size, image_size, <span class="hljs-number">3</span>))</code>
各step数の生成する画像の質の比較は以下です。
diffusion step=1

diffusion step=10

diffusion step=80

まとめ
今回、確率モデル+ニューラルネットワーク(hybrid model)の一つ、Diffusionモデルを紹介しました。直近は生成モデルとしてはかなり精度が良くて、AIの分野でも注目度が高いです。実サービスでは、基本的に表形式のデータが多いため、普通の使い方(生成モデル)に比べて、工夫が必要だと思います。また、Diffusionモデル自体は元になるネットワークの構造が自由に設定できるので、色んなデータ形式のお応用も今後増えて行くではないかと思います。
最後に
グループ研究開発本部 AI研究開発室では、データサイエンティスト/機械学習エンジニアを募集しています。ビッグデータの解析業務などAI研究開発室にご興味を持って頂ける方がいらっしゃいましたら、ぜひ 募集職種一覧 からご応募をお願いします。皆さんのご応募をお待ちしています。
参考:
https://lilianweng.github.io/posts/2021-07-11-diffusion-models/
https://arxiv.org/pdf/2006.11239v2.pdf
https://arxiv.org/pdf/2112.10752.pdf
https://github.com/CompVis/stable-diffusion
https://paperswithcode.com/paper/denoising-diffusion-probabilistic-models
https://github.com/divamgupta/stable-diffusion-tensorflow
https://github.com/hojonathanho/diffusion
https://towardsdatascience.com/diffusion-models-made-easy-8414298ce4da
https://medium.com/@vedantjumle/image-generation-with-diffusion-models-using-keras-and-tensorflow-9f60aae72ac
https://keras.io/examples/generative/ddim/
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD