2024.07.05
データサイエンティストが1からAIシステムを作った上で学んだこと
TL;DR
・AWS CDKを使いIaCを実現した。CDKテンプレートの作成にあたり、CloudFormationのIaC Generatorが便利だった。
・コーナーケース含め、ハマったことや解決策が書いてあります。
2. 作ったもの
3. ハマったことや解決策
4. まとめ
はじめに
こんにちは。グループ研究開発本部 AI研究開発室のS.Y.です。
グループ研究開発本部はGMOインターネットグループのグループ会社の技術支援を行う組織で、システムエンジニアリングがメインの次世代システム研究室と、データ分析・機械学習モデル開発などデータを価値に変えるお仕事がメインのAI研究開発室に別れています。
今年に入ってからグループ研究開発本部として、とあるグループ会社の社内向けAIツールを作る案件があり、フロント/バックエンドの開発として次世代システム研究室から数名、AI機能のPoC・実装開発としてAI研究開発室から筆者が参加しました。
今回のAI機能開発の要件はざっくりとこんな感じです。
・AI機能はマイクロサービスなAPIとして提供し、システムから呼び出して使う。サーバーレスサービスで実現する。
・構成管理はAWS CDKを使い、IaCとして管理する。
このシステムは最終的にグループ会社に納品し、以降は先方で保守運用を行うことになるため、機能要件やシステム要件を満たすことはもちろん、保守運用を見据えた構成管理の仕組みもきちんと作ることが求められました。
ちなみに筆者の属性はこんな感じです。
・システム構築は今回が初めて。(システム的な業務経験は、機械学習モデルの保守・改善やETLくらい)
・基本的にGoogle Cloudを触ってきた。
…見頃にオーバーラップしていませんね。
AI機能自体はサーバーレスなバッチ処理のような仕組みで、コアロジックだけならGoogle Colaboratory上で雑に動作再現できる程度の規模なのですが、そのロジックをきちんとした「システム」に組み込むとなると、データサイエンティストの筆者としてはだいぶ(だいぶ)苦労しました。
ただ近年AIがn度目の盛り上がりを見せていますし、各クラウドベンダーのAPIを使って簡単にAIの結果を取得できるようにもなってきていますので、データサイエンティストも「AIをパッと試して、いけそうならAIを組み込んだマイクロサービスをサッと作る」という芸当ができた方が武器が増えていいかなとも思いました。
今回せっかく色々苦労したので、ハマったこと・解決策・反省点なんかを雑記程度にまとめておこうと思います。
AI研の人はこんなこともやってるんだな、という気持ちで読んでいただけると幸いです。
作ったもの
実際のモノは載せられないので概要だけ。
次の章でハマった点や工夫したことなんかを書きます。
システム
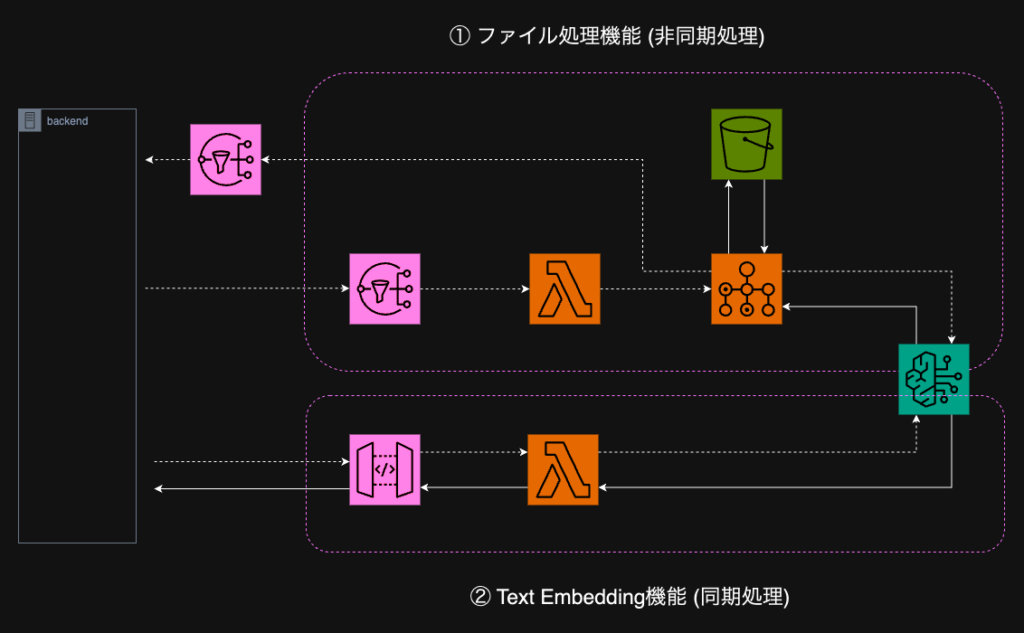
テキストの埋め込み表現(Embedding)を取得するシステムです。
2種類の機能を、それぞれAPIとして作りました。どちらもAWS Bedrock経由でCohere Embeddingモデルを使い、テキストのEmbeddingベクトルを取得するのがコアです。
- ファイル処理機能:
- 入力: 入力元のCSVのパス(S3)、出力先のパス(S3)、処理したいカラム名
- 処理: 入力のCSVをロードしてきて、指定したカラムについてEmbeddingベクトルを計算し、新しいカラムとして追加。
- 出力: カラムが追加されたCSVをS3に格納、SNSトピックに完了通知
- Text Embedding機能
- 入力: Embeddingを計算したいテキスト
- 処理: 入力に対してEmbeddingを計算
- 出力: Embeddingベクトル
非同期で構わないので大量のテキストを処理したい場合はファイル処理機能、1つのテキストに対してリアルタイムでEmbeddingを取得したい場合はText Embedding機能、といった使い分けです。
ファイル処理機能のポイントとしては、「ある程度処理時間がかかることは分かっているのでセッションを維持するような同期処理である必要はないが、処理済みのファイルをバックエンドの方でなるべく早く取り込みたいので、処理が完了次第通知してほしい」という要件を反映してこのような構成になっています。
CDKテンプレート
上記システムのリソースやそこに割り当てるロールなどをIaCとして管理するようにしました。
AWSにはCloud Formationという構成管理サービスがあり、yamlやjson形式で記述されたテンプレートに従ってAWSリソースを作成したり更新したりしてくれます。
AWSTemplateFormatVersion: "2010-09-09"
Description: A sample template
Resources:
MyEC2Instance: #An inline comment
Type: "AWS::EC2::Instance"
Properties:
ImageId: "ami-0ff8a91507f77f867" #Another comment -- This is a Linux AMI
InstanceType: t2.micro
KeyName: testkey
BlockDeviceMappings:
-
DeviceName: /dev/sdm
Ebs:
VolumeType: io1
Iops: 200
DeleteOnTermination: false
VolumeSize: 20
上記の例ではyamlテンプレートでEC2インスタンスを定義しています。
こんな感じでひたすら素のyamlを書いてもいいですが、AWS CDKを使うと比較的楽にテンプレートを作れます。
AWS CDKではpythonやtypescriptなどのプログラミング言語のクラスとして各リソースを定義します。そこからCloud Formationのテンプレートを生成したりデプロイしたりをコマンド一つでやってくれます。
from aws_cdk import (
Stack,
# Import Lambda L2 construct
aws_lambda as _lambda,
)
# ...
class CdkHelloWorldStack(Stack):
def __init__(self, scope: Construct, construct_id: str, **kwargs) -> None:
super().__init__(scope, construct_id, **kwargs)
# Define the Lambda function resource
hello_world_function = _lambda.Function(
self,
"HelloWorldFunction",
runtime = _lambda.Runtime.NODEJS_20_X, # Choose any supported Node.js runtime
code = _lambda.Code.from_asset("lambda"), # Points to the lambda directory
handler = "hello.handler", # Points to the 'hello' file in the lambda directory
)
プログラミング言語で書くことでエディタのlinterが使えたり、環境に応じたconfig切り替えが簡単に実現できたりします。
ハマったことや解決策
上記が最終的なアウトプットですが、これを実現するまでに紆余曲折ありました。
技術的なものもあれば要件すり合わせのような上流なものもありますが、特に分けずに書いていきます。
システム
問題: サーバーレスではPoCの環境を再現できない
今回の開発ですが、最初にEmbeddingを使ったアイデアがうまくいきそうかのPoCから行いました。
PoCではEmbeddingモデルはhuggingfaceにあるMultilingual E5、実行環境はGoogle ColaboratoryのGPUインスタンスを使いました。PoCの結果、精度や大量のテキストに対するパフォーマンスは申し分なかったです。
問題は、AWSでGPUインスタンスをオンデマンドで利用できるサーバーレスサービスがないことでした。GPUを使わない推論では今回のパフォーマンス要件を満たせなかったので、なんとかしなければいけませんでした。
解決策
改めて検証した結果、AWS BedrockからCohereのEmbeddingモデルを使えば精度・パフォーマンス共に要件を満たせることがわかったので、そうしました。(本稿の執筆時点ではBedrockではE5モデルは提供されていなかったです。)
反省点
PoCを行った環境が、本番で再現できるかを予め確認する。
特にOS, 各種ライブラリのバージョン, CPUやメモリなどのリソースが同じものが使えるか確認しましょう。
問題: Bedrockのrate limitに引っかかる
ファイル処理のリクエストが同時に複数投げられるとBedrockの2000rpmというrate limitに引っかかることがありました。体感4, 5個くらいのCSVを同時に処理していると発生する感じがしました。
解決策
根本解決ではないですが、SQSを使ってリクエストをキューに溜めて直列でCSVを処理するようにして、一旦は解決しました。
根本解決ではないが解決とは何かというと、「今回の構成だとたまたま上手くlimit内に収まるようになる」ということです。
今回はpandasのmap関数からBedrockのAPIを呼んでいるのですが、そのパフォーマンスが大体10~15rps即ち~1000rpmなので、複数のCSVを同時に処理しなければ2000rpmの上限には引っかからないのです。
もしmap関数を並列処理するように工夫したりすると、並列度にも寄りますがlimitに達します。
あと今後map関数やBedrock API自体のパフォーマンスが上がるとlimitに引っかかるようになる可能性もあります。
上でも書きましたが今はたまたま安定しているだけ、という状況なので今後さらになんとかしていかないといけませんね。。。
あと普通に並列で処理できた方が良い。。。
反省点
使用するサービスのquotaはちゃんと確認しておく。
特にサーバーレスサービスはポンポン立てられて便利だが、同時実行数や単位時間あたりの制限などを必ず確認する。
問題: Lambdaがtimeout(15min)する
最初の技術選定時点では、リクエストされるCSVは15分で十分処理できる大きさだという想定でだったので、メインロジックはLambdaで実行することに決めていました。(というかLambdaくらいしかサーバーレスサービスを知らなかった)
開発の途中から巨大なファイルが投下されることも十分あり得るということが分かりました。
なので上記のrate limitの問題と合わせて、タイムアウトのない形で処理を実現する必要が改めて出てきました。
解決策
データ処理部分はtimeoutがないAWS Batchで行うようにしました。
BatchはSNSから直接呼び出すことはできないので、SNS → Lambda → Batchという構成になりました。LambdaはBatchジョブをsubmitし、すぐに終了します。
またBatchにあるFIFOなジョブキューを使うことで、前述のSQSを用いた場合のようにrate limitに引っかからない程度のrpmでBedrockにリクエストを投げられます。
反省点
データ量や処理時間の上限を想定できないデータ処理にLambdaを使おうとしない。
要件や想定されるケースは十二分に確認しておく。
CDK
問題: CDKを使うとはいえ、テンプレートをスクラッチで書くのはしんどい
タイトル通りですが、リソースを一つずつ書いていくのはやはりしんどいです。
解決策
AWS CloudFormationのIaC Generatorを使いました。
これは既にプロビジョニングされているAWSリソースからCloudFormationテンプレートを作成する機能です。
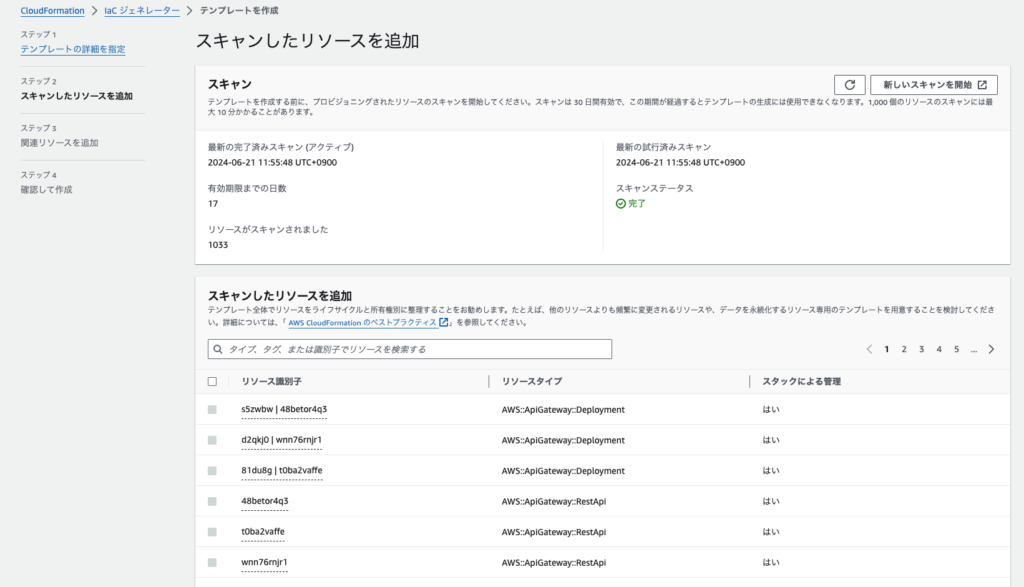
↑こんな感じでスキャンしたリソースの一覧からテンプレートに起こしたいものを選択できます。
一般的に開発初期からIaCテンプレートを作ることは珍しく、最初はマネジメントコンソールから直接リソースを作成し、個別に試したりそれらをつなぎ込んだりしていくのではないでしょうか。そうやって出来上がったリソース群を改めてテンプレートに写経する必要なく、直接テンプレートを生成できるのは便利ですね。
問題: 同じAWSアカウントで複数のCDK appを管理する際にハマった
これはだいぶコーナーケースだと思います。
今回、AWSには筆者が担当したAI周りのリソース群とシステム側のリソース群があるわけですが、それらを個別のCDK appとして管理することになりました。具体的にいうと、別々のリポジトリにそれぞれCDKのアプリケーションファイル(app.py, app.ts)が存在していて、それらのdeployが一つのAWSアカウントに対して行われる、という状況です。
こういう状況で、普通にcdk bootstrapしようとすると競合しているような挙動でエラーとなりました。
原因としてはbootstrapで作成しようとしているものが名前衝突を起こしています。具体的に衝突している部分は2種類あって、これは同時に発生することが多いと思います。
- deploy stack名
- bootstrap qualifier
前提として、CloudFormationは論理的に関連のあるリソース群をstackという単位で管理します。そしてcdkではdeployをする前にまずcdk bootstrapします。bootstrapは何をしているかというと、deploy stackと呼ばれるstackを作成していて、ここに含まれるS3バケットやIAM Roleなどのリソースを使って、以降のdeployが行われます。
そしてcdk bootstrapはデフォルトでCDKToolkitという名前のdeploy stackを作成します。また、作成されるリソースにはデフォルトでhnb659fdsというqualifier(修飾子)が付けられます。
ここで、デフォルト設定で作成されたcdk appがある状態で別のcdk appをデフォルト設定でbootstrapしようとすると、既にそのstackやリソースが存在しているのでエラーとなるわけですね。
解決策
cdk appで用いるdeploy stack名やqualifierを明示するようにしました。
cdk.jsonに下記を追記します。
"toolkitStackName": "MyDeployStackName",
"context": {
"@aws-cdk/core:bootstrapQualifier": "MyQualifier"
}
bootstrapではオプションを指定します。
cdk bootstrap --toolkit-stack-name MyDeployStackName --qualifier MyQualifier
反省点?
やはり各stackを一つのcdk appで管理するのが一番シンプルですが、今回の場合はどうすればよかったでしょう?
こういった問題を予防する銀の弾丸はありませんが、IaCやCI/CD系のツールは使い方だけでなく、それを複数の開発者が使う際に起こりうること、も想定できればよかったかもしれません。
まとめ
各章で書いた反省点をGeminiに突っ込んで、全体総括してもらいました。

さいごに
グループ研究開発本部 AI研究開発室では、データサイエンティスト/機械学習エンジニアを募集しています。ビッグデータの解析業務などAI研究開発室にご興味を持って頂ける方がいらっしゃいましたら、ぜひ 募集職種一覧 からご応募をお願いします。皆さんのご応募をお待ちしています。
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD