2021.10.08
β版のDataproc on GKE (Google Kubernetes Engine) でSparkを検証してみた~ついでにBigQueryのコストも調査
こんにちは。次世代システム研究室のデータベース と Hadoop を担当している M.K. です。
今回は前回のブログで今後の課題にしていた、KubernetesでSpark (PySpark)を使う検証を行ってみました。最初Kubernetesのコンテナイメージを自作するしかないのかなと思ってましたが、クラウドならやっぱりマネージドの機能だよねということで色々調べたら、KubernetesクラスターにDataprocクラスターを展開してSparkジョブを送信できるβ版の機能がGCP (Google Cloud Platrofm)にあることがわかり、それを検証することにしました。
ただこの機能はβ版ということもあってか、用意されたDataprocのイメージのHadoopやSparkのバージョンがどちらも2系で古かったです。最新の3系で検証してみたかったと思いつつ、今回は目をつぶりました。
それから、Sparkジョブが処理したデータをBigQueryで読めるようにしたときのコストもついでに調査してみました。
目次
やりたいこと
実現したいことは、ストレージノードとコンピュートノードの完全分離です。前回の検証では最小限のDataprocクラスター(Hadoopクラスター)を立てて、処理に応じてセカンダリワーカーを増やすというような構成でした。今回はβ版のDataproc on GKE(Google Kubernetes Engine)を使うことで完全分離に近い形を検証します。sparkのジョブを実行するときだけGKE上にDataprocのコンピュートノードが展開され、ジョブが終わるとコンピュートノードが回収される、というような流れです。
Sparkのセッションを作る度にテーブルを定義するのは手間なので、簡単にテーブル定義を統合的に管理してくれるDataprocのメタストアとの連携も試します。
また、Sparkで処理した結果のデータをGCSにParquetフォーマットで置きBigQueryの外部テーブルとするのと、BigQueryに直接読み込んだネイティブテーブルにするので、どれくらいコストが変わるかも簡単に検証します。
GKEクラスターとGKE用のDataprocクラスターを構築
先ずはともかくGKEクラスターを作成して、それからGKE用のDataprocクラスターを作成します。
GKEクラスターを作る
今回の構成についてはGoogleのドキュメントにやり方が書いてありますので、それに従って行います。ドキュメントに書いてあるように、Google Cloud Dataproc Service Agentに「Kubernetes Engine 管理者」のIAMロールの権限を先に付与しておきます。
- IAM管理と管理
- IAM
- (「Google 提供のロール付与を含みます」をチェックして)service-{プロジェクト番号}@dataproc-accounts.iam.gserviceaccount.comを編集
- IAM
GKEだけでも一つの大きな技術テーマで学ぶことが多いものなので、やっぱり色々ハマりました・・・。GKEクラスターを作るところでも何度もエラーが出たのと、GKEクラスター作成後にDataprocクラスターを作ってジョブ送信したときにエラーが出たり狙い通りにいかなかったりして、結局かなりの回数を一から作り直すはめに。。
そして最終的には以下のように作成しています。β版機能なので、gloud betaコマンドを利用しています。gcloudコマンドはすべてCloud Shellを利用しました。
GKE_CLUSTER=dataproc-gke-cluster01
GCE_ZONE=asia-northeast1-a
gcloud beta container clusters create "${GKE_CLUSTER}" \
--scopes=cloud-platform \
--workload-metadata=GCE_METADATA \
--zone="${GCE_ZONE}" \
--node-locations="${GCE_ZONE}" \
--num-nodes=5 --preemptible \
--machine-type=n1-standard-4 \
--no-enable-ip-alias
GKEクラスター作成に関する補足
Googleのドキュメントの例では、–regionを指定していますが、これを指定するとデフォルトではマルチゾーンのリージョンクラスター作成になります。最初はこのことを知らなかったので、–regionsを指定した上で–num-nodesを2にしたら、GKEクラスターのdefault-poolが6ノードになっていて何故なのかわかりませんでした。6ノードになった理由はマルチゾーンはデフォルトでは3つのゾーンを使い、–num-nodesに指定した値×ゾーン数、となるためです。
GKEのオートスケールは5種類あって(参考記事)、やりたいことを実現するには最終的にはノード自動プロビジョニング(NAP)になると思いますが、いきなり深くまで首を突っ込むと沼にハマるので、、今回はNAPは使っていません。
※オートスケールの種類はGKEクラスタの運用モードがStandardの場合にクラスタ構築時に指定しますが、実は完全マネージドなAutopilotという運用モードもあり、Autopilotにするとユーザーはクラスタ構築時も運用中も何も考えることなく、ワークロードの状況にあわせてオートスケールしてくれます。とても楽ちんですが、自分たちの環境に常にベストな選択はしないだろうということと、マネージドになればなるほどコストが高くつくものなので、Autopilotはあくまで選択肢の一つなんだろうと思います。
今回はシンプルにStandardの運用モードで、ゾーンクラスターのGKEクラスターを作成することにしました。
メタストア連携してGKE用のDataprocクラスターを作る
GKEクラスターを作成できたら、次にGKE用のDataprocクラスターを作成します。メタストア連携してDataprocクラスターを作るため、先にDataprocのメタストアを以下の設定で作成しておきます。
| Dataproc Metastore | |
|---|---|
| サービス名: | dataproc-metastore01 |
| Data location: | asia-northeast1 |
| Metastore version: | 2.3.6 |
| Release channel: | Stable |
| Service tier: | Developer |
| ネットワーク: | default |
結論を先に言うと、GKEクラスターの作成以上にメタストア連携にどハマりし、、、メタストア連携を通してやりたかったことは今回見送りました。。メタストアを指定してGKE用のDataprocクラスターを作成すること自体は成功しますが、Sparkのジョブを送信したときに一度目はテーブル作成できても、二度目のジョブ送信時に新たなSparkセッションで処理しようとすると、メタストアに格納されたはずのテーブル定義の情報が取得できませんでした。
GKE用DataprocイメージのHadoopやSparkのバージョンが2系ということもあり、メタストアのバージョンを2.3.6にしていましたが、それでうまくいかなかったのでひとつ前の2.2.0でも試しましたがやっぱりダメでした。
結局、GKE用のDataprocクラスターは以下のように作成しました。
GKE_CLUSTER=dataproc-gke-cluster01
GCE_REGION=asia-northeast1
GCE_ZONE=asia-northeast1-a
DATAPROC_CLUSTER=dataproc-cluster02
DATAPROC_METASTORE=projects/{プロジェクトID}/locations/asia-northeast1/services/dataproc-metastore01
VERSION=1.4.27-beta
BUCKET=z-bucket02
gcloud beta dataproc clusters create "${DATAPROC_CLUSTER}" \
--gke-cluster="${GKE_CLUSTER}" \
--region="${GCE_REGION}" \
--zone="${GCE_ZONE}" \
--image-version="${VERSION}" \
--dataproc-metastore="${DATAPROC_METASTORE}" \
--bucket="${BUCKET}"
–bucketにはDataprocクラスターが使うGCS (Google Cloud Storage)のパスを指定します。今回の検証では、データの置き場所としてz-bucket02というGCSの場所を使ったので、そこを指定しています。
Dataproc on GKEでSparkジョブを送信
GKEクラスターとGKE用のDataprocクラスターを作ったら、いよいよジョブを送信して処理を試してみます。SparkジョブはいつものようにPySparkを利用して書きました。
メタストア連携してテーブルを作成
前述したとおり、結果的にはメタストア連携がうまくいかなかったんですが、まずやったのはテーブル作成です。前回のブログで作成したいつものお酒販売データを使いました。Parquetフォーマットですでに作成していたので、そのデータを今回の環境のGCSにアップロードしました。
最初、外部テーブルを定義してメタストアに格納することを考えて、以下のcreate_external_table.pyを先ほど作成したGKE用のDataprocクラスターに送信してみました。
# create_external_table.py
from pyspark import SparkContext
from pyspark.sql import Column, DataFrame, SparkSession, SQLContext, functions
from pyspark.sql.functions import *
from pyspark.sql.types import *
from py4j.java_collections import MapConverter
import sys
spark = SparkSession \
.builder \
.appName("create_iowa_liquor_sales_parquet") \
.enableHiveSupport() \
.getOrCreate()
ddl = """
CREATE EXTERNAL TABLE iowa_liquor_sales_parquet (
invoice_item_number STRING,
sale_date DATE,
store_number INTEGER,
store_name STRING,
address STRING,
city STRING,
zip_code INTEGER,
store_location STRING,
county_number INTEGER,
county STRING,
category STRING,
category_name STRING,
vendor_number INTEGER,
vendor_name STRING,
item_number INTEGER,
item_description STRING,
pack INTEGER,
bottle_volume INTEGER,
state_bottle_cost STRING,
state_bottle_retail STRING,
bottles_sold INTEGER,
sale STRING,
volume_sold_liters FLOAT,
volume_sold_gallons FLOAT
)
STORED AS PARQUET
LOCATION 'gs://z-bucket02/parquet_table/iowa_liquor_sales'
"""
spark.sql(ddl)
spark.stop()
ジョブ送信したところ、メタストア連携以前に権限回りで散々怒られました・・・。結局、ログインしているユーザーや各種サービスアカウントに片っ端から「ストレージ管理者」と「Compute管理者」を付与して、ひとまず権限回りは解決させました。本当はしっかり権限管理をしないといけませんが、Googleの権限管理のIAMは非常に複雑でこれだけで相当時間を食うのでいつか時が来たらやることにしました。
権限回りが解決してからはcreate_external_table.pyの送信に成功したので喜んでいたんですが、その後別のジョブでiowa_liquor_sales_parquetテーブルを参照しようとしても、何度やってもテーブルがないと怒られます。SparkSQLのメタデータはデフォルトではDerbyというデータベースに書かれますが、分散処理した場合は別のジョブがそのDerbyの情報を取得できません。GKE用のDataprocクラスターを作成するときに、メタストアを指定してエラー出ずに作成できているものの、どうもログを見るとDerbyを使っているように見えます。
Derbyを使わずメタストアを使うように、ジョブ送信時のパラメータを色々試したり、上述のように別バージョンのメタストアやDataprocクラスターを作り直したりしたんですが、やっぱりダメでした。。
ジョブ送信で試したパラメータは以下のようなものです。
# ジョブ送信の主な例
## 変数はGKE用のDataprocクラスター作成時と同じ値
## select_table.pyはSELECT count(*) FROM iowa_liquor_sales_parquetを実行するジョブ
gcloud dataproc jobs submit pyspark \
--cluster="${DATAPROC_CLUSTER}" select_table.py \
--region="${GCE_REGION}"
gcloud dataproc jobs submit pyspark \
--cluster="${DATAPROC_CLUSTER}" select_table.py \
--region="${GCE_REGION}" \
-- \
--conf "hive.user.install.directory=gs://z-bucket02/google-cloud-dataproc-metainfo/xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx/hive/user-install-dir" \
--conf "hive.metastore.uris=thrift://XX.XX.XX.XX:9083" \
--conf "hive.metastore.warehouse.dir=gs://gcs-bucket-dataproc-metastore01-xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxx/hive-warehouse"
gcloud dataproc jobs submit pyspark \
--cluster="${DATAPROC_CLUSTER}" select_table.py \
--region="${GCE_REGION}" \
--properties="spark.sql.warehouse.dir=gs://gcs-bucket-dataproc-metastore01-xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxx/hive-warehouse,spark.hadoop.hive.metastore.uris=thrift://XX.XX.XX.XX:9083"
通常のDataprocクラスターであれば前回検証したように特別な指定なくメタストア連携できるので、やっぱりβ版のGKE用Dataprocクラスターが対応していない気がします。恐らく、マネージドのメタストアが対応していないか、GKE用DataprocのコンテナイメージのSpark設定が対応していないかと思うんですが、真相はちょっとよくわかりませんでした。。
マネージドのメタストアを謳っておいて、Dataproc on GKEでは使えないとなると使い勝手が悪いので、β版から安定板になるときは簡単に連携できるようになるはず。ということで深追いするのは今回は辞めました。
Sparkで大きなデータを作成
ParquetフォーマットのデータはSparkで直接テーブルのようにDaraframeに読み込めるため、メタストア連携しないのであれば外部テーブルを作る意味はあまりないので作っていません。検証のために、もっと大きなデータを格納するための別テーブルを作りました。
CREATE TABLE iowa_liquor_sales_large ( invoice_item_number STRING, sale_date DATE, store_number INTEGER, store_name STRING, address STRING, city STRING, zip_code INTEGER, store_location STRING, county_number INTEGER, county STRING, category STRING, category_name STRING, vendor_number INTEGER, vendor_name STRING, item_number INTEGER, item_description STRING, pack INTEGER, bottle_volume INTEGER, state_bottle_cost STRING, state_bottle_retail STRING, bottles_sold INTEGER, sale STRING, volume_sold_liters FLOAT, volume_sold_gallons FLOAT ) USING parquet PARTITIONED BY (sale_date) LOCATION 'gs://z-bucket02/parquet_table/iowa_liquor_sales_large'
外部テーブルを作った時のようにiowa_liquor_sales_largeテーブルを作成します。
from pyspark import SparkContext
from pyspark.sql import Column, DataFrame, SparkSession, SQLContext, functions
from pyspark.sql.functions import *
from pyspark.sql.types import *
from py4j.java_collections import MapConverter
import sys
spark = SparkSession \
.builder \
.appName("iowa_liquor_sales_large") \
.enableHiveSupport() \
.getOrCreate()
df1 = spark.read.parquet("gs://z-bucket02/parquet_table/iowa_liquor_sales")
df1.createOrReplaceTempView("iowa_liquor_sales_parquet")
df2 = spark.read.parquet("gs://z-bucket02/parquet_table/iowa_liquor_sales_large")
df2.createOrReplaceTempView("iowa_liquor_sales_large")
# INSERT 1回目
dml = """
INSERT INTO iowa_liquor_sales_large SELECT
concat(invoice_item_number, '__1') AS invoice_item_number ,
store_number,
store_name,
address,
city,
zip_code,
store_location,
county_number,
county,
category,
category_name,
vendor_number,
vendor_name,
item_number,
item_description,
pack,
bottle_volume,
state_bottle_cost,
state_bottle_retail,
bottles_sold,
sale,
volume_sold_liters,
volume_sold_gallons,
sale_date
FROM iowa_liquor_sales_parquet
"""
spark.sql(dml)
##### 省略(INSERT2~7回目の内容は割愛) #####
# INSERT 8回目
dml = """
INSERT INTO iowa_liquor_sales_large SELECT
concat(invoice_item_number, '__8') AS invoice_item_number ,
store_number,
store_name,
address,
city,
zip_code,
store_location,
county_number,
county,
category,
category_name,
vendor_number,
vendor_name,
item_number,
item_description,
pack,
bottle_volume,
state_bottle_cost,
state_bottle_retail,
bottles_sold,
sale,
volume_sold_liters,
volume_sold_gallons,
sale_date
FROM iowa_liquor_sales_parquet
"""
spark.sql(dml)
spark.stop()
iowa_liquor_sales_largeテーブルを作ったら、INSERTをどんどん繰り返します。主キー相当のカラム値に重複が入らないように少し加工してINSERTを8回行いました。さらにデータを大きくするため、上記のPythonファイルには書いていませんが、主キーが重複しないように自分自身を倍にするINSERT文を2回繰り返しています。
件数のカウントと処理速度のチューニング
INSERTが終わったところで試しに件数カウントを行ったんですが、以下のようにdriver-memory、num-executors、executor-memoryを色々指定しても全然処理が速くならず、こちらの意図どおりにSparkの分散処理ができませんでした。
# 件数カウントのジョブ送信の例
## 変数はGKE用のDataprocクラスター作成時と同じ値
## select_table_large.pyはSELECT count(*) FROM iowa_liquor_sales_largeを実行するジョブ
gcloud dataproc jobs submit pyspark \
--cluster="${DATAPROC_CLUSTER}" select_table_large.py \
--region="${GCE_REGION}" \
-- --driver-memory=2G --num-executors=5 --executor-memory=4G
gcloud dataproc jobs submit pyspark \
--cluster="${DATAPROC_CLUSTER}" select_table_large.py \
--region="${GCE_REGION}" \
--properties="driver-memory=2G,num-executors=10,executor-memory=2G"
色々調べたら、このあたりのパラメータを指定して意図通りに処理させるには、spark.dynamicAllocation.enabled=falseが必要ということがわかったので、spark~という名前のパラメータに全部寄せて、以下のようにつけて試したら、一気に速くなりました!
# 件数カウントのジョブ送信のチューニング
gcloud dataproc jobs submit pyspark \
--cluster="${DATAPROC_CLUSTER}" select_table_large.py \
--region="${GCE_REGION}" \
--properties="spark.dynamicAllocation.enabled=false,spark.driver.memory=2G,spark.executor.instances=20,spark.executor.memory=2G"
上記の結果、約4億件、Parquetフォーマット+Snappy圧縮で10GB(実際は100GB以上)のテーブルの件数カウントが7分ほどになり、5倍~10倍くらい速くなりました。
)
# 結果 +---------+ |count(1) | +---------+ |402893728| +---------+ # ログ抜粋 status: state: DONE stateStartTime: '2021-09-26T01:09:40.264504Z' statusHistory: - state: PENDING stateStartTime: '2021-09-26T01:02:43.890554Z' - state: SETUP_DONE stateStartTime: '2021-09-26T01:02:43.933806Z' - details: Agent reported job success state: RUNNING stateStartTime: '2021-09-26T01:02:43.964501Z' # データサイズ gsutil -m du -sh gs://z-bucket02/parquet_table/iowa_liquor_sales_large 9.56 GiB gs://z-bucket02/parquet_table/iowa_liquor_sales_large
このときのGKEのリソース利用状況はこちら。
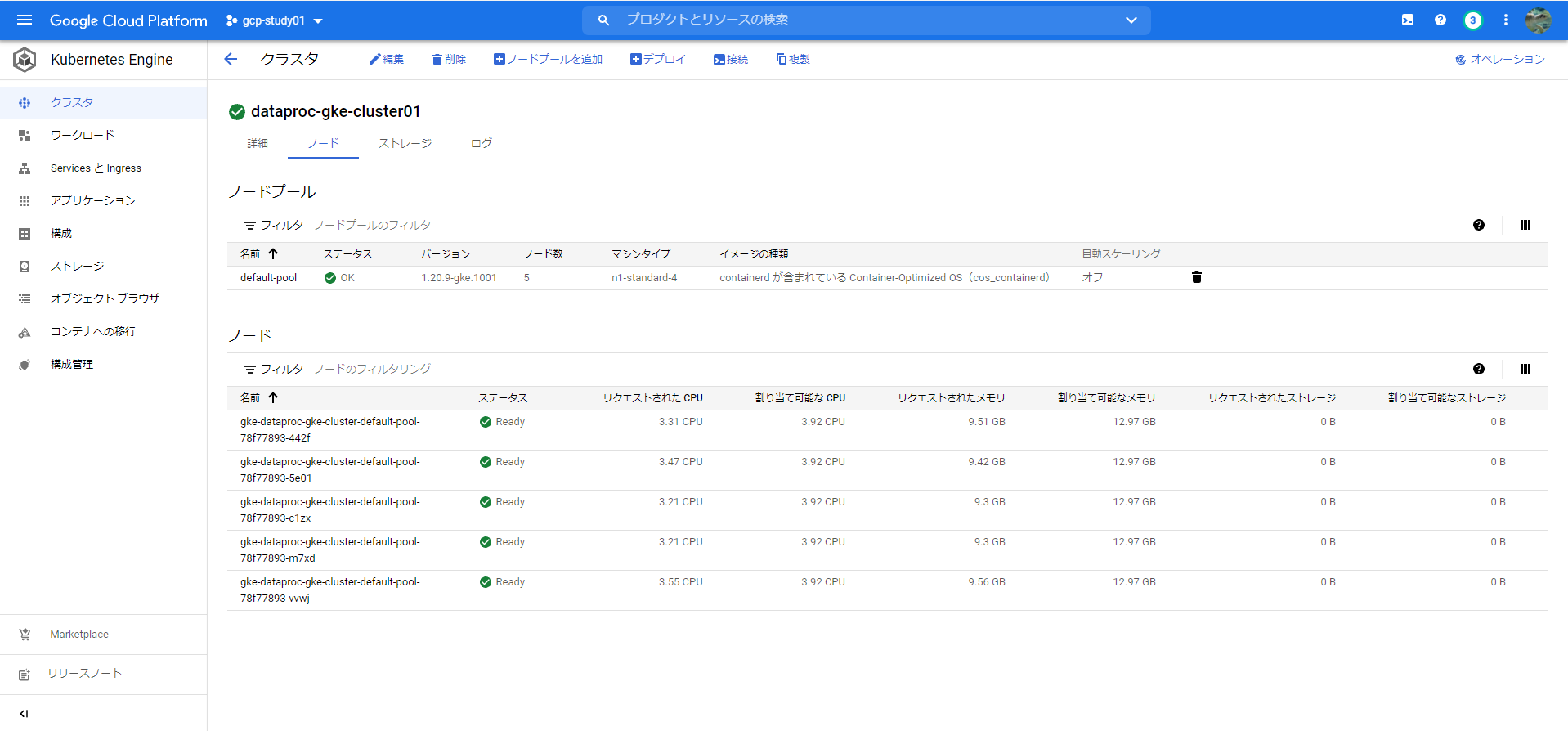
GKEクラスターを5ノードで構築しましたがフルリソースに近いリソースを使っていることがわかります。
通常のDataprocクラスターでは処理してないときもStorage PD CapacityのSKUコストが結構かかる印象ですが、GKE用のDataprocクラスターではそういうことはなく、メインのコストはコンピュートノードのリソース消費で、より処理量に応じたコストになりました。メタストア連携がまだ安定してないですが、ただDataprocのメタストアが一番コストがかかるので、処理量に応じたコストにこだわるなら自前でHiveメタストアを低コスト構成で構築するのもありと思います。
BigQueryを使うときのコストを計算
Dataproc on GKEでのジョブ送信を検証できたところで、ずっと気になっていたBigQueryを使う時のコストについても計算してみました。具体的には、データをGCSに置いて外部テーブルとしてBigQueryを使うときと、データを最初からBigQueryに読み込んで使うのと、どちらがコストがかからないか、です。
BigQueryの外部テーブルとマネージドテーブルを作成
まずBigQueryで外部テーブルとネイティブテーブルを作ります。特に深い意味はないですが、テーブル名は同じにしてデータセット(スキーマ)を分けました。外部テーブル用のデータセットをzdb、ネイティブテーブル用のデータセットをbqdbとしてます。どちらもロケーションはasia-northeast1です。
外部テーブルの方はBigQueryのコンソールから以下のように作りました。
| ■外部テーブル | |
|---|---|
| ソース | |
| テーブルの作成元: | Google Cloud Storage |
| GCSバケットからファイルを選択: | z-bucket02/parquet_table/iowa_liquor_sales_large/*.parquet |
| ファイル形式: | Parquet |
| ソースデータパーティショニング: | →チェックする |
| ソースURIの接頭辞を選択: | gs://z-bucket02/parquet_table/iowa_liquor_sales_large |
| パーティション推論モード: | 独自推定 →チェックする |
| +フィールドを追加 →押す | 名前 →sale_date、型 →DATE |
| 送信先 | |
| プロジェクト名: | gcp-study01 |
| データセット名: | zdb |
| テーブルタイプ: | 外部テーブル |
| テーブル名: | iowa_liquor_sales_large |
ネイティブテーブルはコンソールからDDLを投げて作りました。
CREATE TABLE bqdb.iowa_liquor_sales_large ( invoice_item_number STRING, sale_date DATE, store_number INT64, store_name STRING, address STRING, city STRING, zip_code INT64, store_location STRING, county_number INT64, county STRING, category STRING, category_name STRING, vendor_number INT64, vendor_name STRING, item_number INT64, item_description STRING, pack INT64, bottle_volume INT64, state_bottle_cost STRING, state_bottle_retail STRING, bottles_sold INT64, sale STRING, volume_sold_liters FLOAT64, volume_sold_gallons FLOAT64 ) PARTITION BY (sale_date)
ネイティブテーブルを作ったらデータをロードします。bqコマンドを使いました。
bq --location=asia-northeast1 load \
--source_format=PARQUET \
--hive_partitioning_mode=CUSTOM \
--hive_partitioning_source_uri_prefix="gs://z-bucket02/parquet_table/iowa_liquor_sales_large/{sale_date:DATE}" \
bqdb.iowa_liquor_sales_large \
gs://z-bucket02/parquet_table/iowa_liquor_sales_large/*.parquet
注意点として、GCSに上げたParquetのテーブルデータはsale_dateで日付のパーティショニング済みなので、hive_partitioningのパラメータをちゃんと指定しないと、sale_dataがNULLになってクエリがうまく投げられません。最初それがわからず、指定の仕方もわからなかったのでちょっとハマりました。
ネイティブテーブルの詳細を見ると、データサイズ122GBほどになっていました。Snappy圧縮のParquetフォーマットで10GB弱でしたが、実際はこれくらいのサイズということになります。
| 表のサイズ: | 121.72 GB |
| 行数: | 402,893,728 |
BigQueryのクエリとストレージのコスト計算
BigQueryのテーブルを作成したら、クエリを試してみます。最初は外部テーブルから。
SELECT invoice_item_number, count(*) FROM `zdb.iowa_liquor_sales_large` GROUP BY invoice_item_number HAVING count(*) > 1
| 所要時間: | 8.4 秒 |
| 処理されたバイト数: | 7.37 GB |
| 課金されるバイト数: | 7.37 GB |
処理されたバイト数と課金されるバイト数が同じ7.4GBほどでした。外部テーブルで9秒以内に返ってくるので、SQLで処理できる内容なら圧倒的なスピードですね。
連続してクエリを投げます。
SELECT count(*) FROM `zdb.iowa_liquor_sales_large`
| 所要時間: | 7.2 秒 |
| 処理されたバイト数: | 0 B |
| 課金されるバイト数: | 0 B |
カラムを指定せず件数をカウントするだけのお馴染みのクエリですが、BigQueryではこのクエリはバイト数や課金されるバイト数が0Bになることがわかります。つまり無料ですね。
次にネイティブテーブルにクエリをします。
SELECT invoice_item_number, count(*) FROM `bqdb.iowa_liquor_sales_large` GROUP BY invoice_item_number HAVING count(*) > 1
| 所要時間: | 6.2 秒 |
| 処理されたバイト数: | 7.37 GB |
| 課金されるバイト数: | 7.37 GB |
ネイティブテーブルにも連続してクエリを投げました。
SELECT count(*) FROM `bqdb.iowa_liquor_sales_large`
| 所要時間: | 2.4 秒 |
| 処理されたバイト数: | 0 B |
| 課金されるバイト数: | 0 B |
クエリをたくさん投げて実行時間の平均を取っているわけではないですが、幾らかネイティブテーブルの方が早い印象です。単純な全件カウントはだいぶ速そうです。
クエリを試して課金されるバイト数がわかったところで、今度はストレージのコストとあわせて料金計算をしてみます。GCPには簡単な料金計算ツールが用意されているのでそれを利用しました。ただ、BigQueryはクエリやストレージの条件によってここまでは無料というのがたくさんあり、コストの全体像を把握するのは非常に複雑です。なので今回は非常に大雑把に比較します。
クエリのコスト計算結果
GCSへの外部テーブルもネイティブテーブルも課金されるバイト数が同じだったので、コスト計算ツール上は課金されるバイト数しか入力がなく、意外にも同じコストになりました。
クエリだけのコストを計算するときは、料金計算ツールでBIGQUERYを選択し、Storega Pricingの箇所はすべて0を入力し、Query Pricingの箇所に課金されるバイト数を入力します。課金されるバイト数には上記のHAVING句付きSELECT文の7.4GBを入れました。ただ、BigQueryは月間1TBまでは無料なので、このクエリを1000回投げたことにして計算しました(課金されるバイト数が7400GB)。
| iowa_liquor_sales_large | |
|---|---|
| Location: | Tokyo |
| Active Storage: | 0 GiB |
| Long-termStorage: | 0 GiB |
| Queries: | 7.227 TB |
| Total Estimated Cost: JPY 4,108.97 per 1 month |
ストレージのコスト計算結果
ストレージのコストはBigQueryとGCSで別々に計算します。先ずBigQueryのネイティブテーブルから。
| bqdb.iowa_liquor_sales_large | |
|---|---|
| Location: | Tokyo |
| Active Storage: | 122 GiB |
| Long-termStorage: | 0 GiB |
| Queries: | 0 TB |
| Total Estimated Cost: JPY 283.32 per 1 month |
iowa_liquor_sales_largeテーブルはBigQuery上のサイズは122GBほどなので、これをActive Storageに入力して計算しました。結果、このサイズだとBigQueryのストレージは月間300円弱ということになりました。
次に外部テーブル、つまりGCSのコスト計算をします。
GCS上のiowa_liquor_sales_largeテーブルはSnappy圧縮のParquetフォーマットで9.6GBほどなので、料金計算ツールでCLOUD STORAGEにして、ストレージ総量に9.6GBを入力します。GCSの料金計算はちょっとややこしくて、ClassAおよびClassBに分けられたGCSデータに対する操作の数量の入力が必要になります。データ操作に対しても課金されるため操作0で見積もっては明らかにBigQueryとの比較において不公平になると思うので、仮にClassAとClassBの操作が両方とも月に1万回あったとして計算しました。
| 1x Standard Storage | |
|---|---|
| Location: | Tokyo |
| Total Amount of Storage: | 9.6 GiB |
| Class A operations: | 0.01 million |
| Class B operations: | 0.01 million |
| Egress – Data moves within the same location: | 0 GiB |
| Always Free usage included: | No |
| Total Estimated Cost: JPY 30.22 per 1 month |
結果、月間30円ほどになりました。ClassAとClassBの操作が両方とも月に10万回だったとして計算しても月間84円ほどでした。
コストの比較結果
外部テーブルとネイティブテーブルは、Snappy圧縮のParquetフォーマットのデータであれば、クエリコストとストレージコストの両方を見ると、GCSに置いて外部テーブルとして利用した方が安くすみそうです。今回のケースでは、クエリコストが同じになり、ストレージコストがGCSの方が安くなる分そのまま差になりました。
クエリがネストや結合を多用するなど複雑だった場合や、データサイズがTB規模のようにずっと巨大だった場合に、クエリの実行時間やコストがどうなるかはさらに調べないといけませんが、少なくとも100GB級のデータであれば、Snappy圧縮のParquetフォーマットをGCSに置いて外部テーブルにした方が、ある程度クエリの処理速度も担保してコストも安くすませられそうという結果になりました。
まとめ
今回の検証目的は、Dataproc on GKEを使ったストレージノードとコンピュートノードのより完全に近い分離でしたが、比較的簡単にやることができました。Dataproc on GKEが早く安定板になると良いですね。Spark回りのKubernetesのコンテナイメージの管理をGCPでやってくれることになるので、使う方はGKEクラスターの設定と運用だけに注力できるのも良いポイントです。
ストレージノードとコンピュートノードの分離は結局のところコストを抑えるための構成なので、自分が想定していたとおり、以下のような構成でそれに近づきそうです。
- ParquetフォーマットでテーブルデータをGCSに格納
- Dataprocのメタストア連携するなどSparkで利用するテーブル定義を統合管理
- GCSへの外部テーブルとしてBigQueryを利用
- ※頻繁に利用するレイテンシー重視のテーブルがあればBigQueryのネイティブテーブルを別途作るのもあり
- Dataproc on GKEを使って簡単にSparkの分散処理し、リソースを使った分だけ主に課金
- ※安定版か、他にもっと良いSpark on Kubernetesができるマネージドサービスが出てきたらそれを利用
今後の課題
- GKEのオートスケールをノード自動プロビジョニング(NAP)にしたり、運用モードをAutopilotにして試す
- (安定版を待って?)Dataprocのメタストア連携をやる、もしくは自前のHiveメタストア構築を一回やってみる
- TB規模のテーブルを用意して複雑なクエリを投げた時の、BigQueryの外部テーブルとネイティブテーブルのコストを計算
- 今回のような構成時のIAM管理をもっとしっかり設計
このあたりでしょうか。GKEはまさにGCPの真骨頂といえるサービスと思うので、今後もGKE回りは色々試していきたいと思っています。
最後に
次世代システム研究室では、データサイエンティスト/機械学習エンジニアを募集しています。ビッグデータの解析業務など次世代システム研究室にご興味を持って頂ける方がいらっしゃいましたら、ぜひ 募集職種一覧 からご応募をお願いします。皆さんのご応募をお待ちしています。
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD




