2022.04.08
GCPでSparkの代わりにDataflowとBeamSQLを使ってみた
こんにちは。次世代システム研究室のデータストア全般とクラウド(分散処理)を担当している M.K. です。
過去のブログでGCPの分散処理を主にPySparkを使って検証してきました。でもGCPの分散処理はDataflowというものがあって、きっとこちらが本命なんだろうと思いながら触ってこなかったんですが、GCPを使いこなしていくならDataflowをやらないわけにはいかないなと思って、今回はDataflowを検証してみようと思います。
GCPの分散処理の本命?Dataflow
ずいぶん前からHadoopをオンプレミスからやっていて、SparkSQLによる実装がとても使いやすいこともあり、私の中ではビッグデータの分散処理フレームワークといったらSpark/PySparkなんですが、GoogleのDataflowはApache Beamという分散処理フレームワークで扱います(というかDataflowの幾つかの技術をApache Software Foundationに寄贈したのがBeamの始まり)。
このBeam、PySparkに慣れ切ってしまったからか、使ってみるとクセが強め。。
DataflowSQLを調べてみた
最初Beamを一から覚えるのは結構手間だろうなと思って、簡単にできるものがないか調べたら、DataflowSQLなるものがありました。
ただ、DataflowSQLは基本的にGCPのConsoleから扱う感じで、やれることに制限があります。以下の公式ドキュメントが参考になると思います。
GCS上でParquetデータの読み書きが容易にできることを試したかったので、DataflowSQLを使ってそれをやる検証を行おうとしたんですが、どうも現状はGCS上にParquetデータを書き出すことができないみたいです。
DataflowSQLは予め決められたデータソースの入出力しかできなくて、上記のドキュメントにも書いてありますが、出力先はPub/SubのトピックかBigQueryのテーブルしかありません。BigQueryの出力を使うくらいだったら、DataflowSQLを使わなくてもBigQueryの外部テーブルの方が早い気がしたので、今回はDataflowSQLを触るのはやめることにしました。
PythonからFlexテンプレートを使って分散処理を試してみた
Dataflowのテンプレート
それで次に目を付けたのがDataflowのテンプレートです。Dataflowを使う人は大体同じようなデータソースの入出力を行うと思うので、実は毎回一から実装しなくてもいいように大抵のパターンに合わせたテンプレートが用意されていました。
今回やりたかったことに一番近いテンプレートがあったんですが、出力先がBigQueryのテーブルだったので、これも見送りに。
やりたいことに合っているテンプレートがあると入出力のデータソースをパラメータで渡すだけで実装なしに利用することができます。Dataflowはテンプレートを作って使いまわすのが基本のようですね。テンプレートはコンソールやgcloud dataflowコマンドからでも使うことができます。
Parquetデータを読み込んでそのまま書き出す
Flexテンプレート
自分でテンプレートをカスタマイズするやり方を色々調べたところ、Flexテンプレートが推奨となっていたので、今回はこれを使うことにしました。
Flexテンプレートは、Googleのドキュメントによると「パイプラインを Docker イメージとしてパッケージ化し、それらのイメージをプロジェクトの Container Registry または Artifact Registry でステージングします」とあります。つまり、パイプラインの環境をDockerコンテナを使って展開してパイプラインを実行できるようにしたもの、という感じでしょうか。
私が最近ずっと追いかけているテーマが、ビッグデータを分散処理する際のコンピュートノードとストレージノードの完全分離なんですが、処理するときだけDockerコンテナを立ち上げてパイプライン処理をして終わったらコンテナを削除、という形はまさにそのものズバリなので、Flexテンプレートを試すことにしました。
DataflowはSDKを使って書くんですが、JavaとPythonの二つのSDKがあります。今までずっとPySparkを検証してきたこともあり、PythonのSDKを使いました。
だいたい察しが付くと思いますが、Flexテンプレートの検証は、Dockerイメージのビルド含めたApache Beamの環境構築やBeamの実装と、初めてやることのオンパレードになったので、案の定いっぱいハマりました・・。
Dockerファイルの準備
今回の検証はすべてCloud Shellのターミナルから行いました。まず、サンプルのようなものがないと何をしていいかわからないので、Googleが準備しているサンプルを落としてきます。Cloud Shellの自分のアカウントのホームディレクトリ配下(5GB)だけは永続化されて消えないのでここを利用します。適当に作業用ディレクトリを作ってそこで作業します。
mkdir $HOME/work; cd $HOME/work git clone https://github.com/GoogleCloudPlatform/python-docs-samples.git cd python-docs-samples/dataflow/flex-templates # テストサンプル用のstreaming_beamディレクトリをコピー cp -pr streaming_beam beam_parquet cd beam_parquet # 余計なファイルを消しておく rm e2e_test.py streaming_beam.py
次にサンプルのDockerファイルを書き換えます。元のサンプルに書いてあるものはそのまま残して以下のように書き換えました。
# Googleが提供しているPython3.8用のベースイメージを利用
FROM gcr.io/dataflow-templates-base/python38-template-launcher-base
ENV FLEX_TEMPLATE_PYTHON_REQUIREMENTS_FILE="/template/requirements.txt"
# Beamの処理を書いたPythonスクリプトをtest_beam_parquet.pyという名前にしたのでそれを指定
ENV FLEX_TEMPLATE_PYTHON_PY_FILE="/template/test_beam_parquet.py"
COPY . /template
# Python3向けのpipを使うようにpip3と書き換え
#-- Python3系のベースイメージを使っていれば必要ないかも。念のため
# We could get rid of installing libffi-dev and git, or we could leave them.
RUN apt-get update \
&& apt-get install -y libffi-dev git \
&& rm -rf /var/lib/apt/lists/* \
# Upgrade pip and install the requirements.
&& pip3 install --no-cache-dir --upgrade pip \
&& pip3 install --no-cache-dir -r $FLEX_TEMPLATE_PYTHON_REQUIREMENTS_FILE \
# Download the requirements to speed up launching the Dataflow job.
&& pip3 download --no-cache-dir --dest /tmp/dataflow-requirements-cache -r $FLEX_TEMPLATE_PYTHON_REQUIREMENTS_FILE
# Since we already downloaded all the dependencies, there is no need to rebuild everything.
ENV PIP_NO_DEPS=True
なお、Googleが提供しているベースイメージのリポジトリがあるのでここから選ぶことができます。
このDockerファイルでは必要なPythonのモジュールをrequirements.txtに書いているのでそのやり方をそのまま踏襲して、以下の内容にrequirements.txtを書き換えました。今回はバージョン2.36.0のBeam SDKを指定しました。
apache-beam[gcp]==2.36.0
現時点の最新のPython SDKバージョンは2.37.0で、2.37.0のページにはハイライトとしてPython3.9サポートと書いてあります。ただまだ完全ではなさそうな雰囲気があるので、Python3.9サポートを謳っていない一つ前のバージョンを使うことにしました。ちなみにBeam公式ドキュメントのPython SDK Quickstartページの冒頭に、Python3.8までサポートと書いてあります(2022/3/31現在)。
このためDockerのベースイメージもPython3.8向けのものにしました。
なお、Python SDKの様々なバージョンはこちらのページから確認できます。
Parquetデータを準備
Parquetデータを読み込んで書き出すという検証を行うので、予めそのためのデータと書き出し先の場所をGCS上に準備しておきます。
- 準備するデータは自分の検証で毎回お馴染みのアイオワ州のお酒販売のサンプルデータです。
- 以前の検証でGCS上にParquetデータとして作ったものが残っていたのでこれを利用しました(そのとき作ったのはDelta Lakeのテーブルですが実体はParquetデータファイルなのでParquetデータとして扱えます)。
ただ、このデータは日付カラムでパーティショニングされていて(例:gs://xxx/xxx/sale_date=2012-01-03など)、本当はその状態で検証したかったんですが、Beamのparquet I/Oはこうしたパーティショニングに対応してなかったので(一発で読み取れない)、今回はパーティショニングしていないParquetデータを用意することにしました。
GCS上のParquetデータに対して以下のようにBigQueryの外部テーブルを作って、
CREATE EXTERNAL TABLE lakehouse.iowa_liquor_sales` OPTIONS( format="PARQUET", hive_partition_uri_prefix="gs://test-bucket01/lakehouse.db/iowa_liquor_sales/", uris=["gs://test-bucket01/lakehouse.db/iowa_liquor_sales/*.parquet"] );
もう一つ同じカラム定義のBigQueryテーブルも作ります。そうしたら、外部テーブルからBigQueryテーブルにINSERT SELECT文でデータを取り込み、最後にCloud ShellからbqコマンドでParquetデータとしてエクスポートすれば準備完了です(プロダクション環境でデータを圧縮しないで置くことは決してないので、今回の検証でもSnappy圧縮を行っています)。
bq extract \ --location=asia-northeast1 \ --destination_format PARQUET \ --compression SNAPPY \ test-study01:bigq.iowa_liquor_sales \ gs://test-bucket01/non_partitioned/iowa_liquor_sales/data-*.parquet
Beamの処理を書いたPythonスクリプトを作成
次にBeamの処理を書きます。サンプルのstreaming_beam.pyを書き直しました。Parquetデータを読み込んでそのまま書き出すことができたのが以下のコードです。Beamのことを全然知らないところから始めてたくさん調べながら書いたので、正解に辿り着くまでに四苦八苦しました。。
#!/usr/bin/env python3
import argparse
import logging
from typing import List
import pyarrow
import apache_beam as beam
from apache_beam.options.pipeline_options import PipelineOptions
# Defines parquet schema for the output table.
parquet_schema = pyarrow.schema(
[
('invoice_item_number', pyarrow.string()),
('sale_date', pyarrow.date32()),
('store_number', pyarrow.int64()),
('store_name', pyarrow.string()),
('address', pyarrow.string()),
('city', pyarrow.string()),
('zip_code', pyarrow.int64()),
('store_location', pyarrow.string()),
('county_number', pyarrow.int64()),
('county', pyarrow.string()),
('category', pyarrow.string()),
('category_name', pyarrow.string()),
('vendor_number', pyarrow.int64()),
('vendor_name', pyarrow.string()),
('item_number', pyarrow.int64()),
('item_description', pyarrow.string()),
('pack', pyarrow.int64()),
('bottle_volume', pyarrow.int64()),
('state_bottle_cost', pyarrow.string()),
('state_bottle_retail', pyarrow.string()),
('bottles_sold', pyarrow.int64()),
('sale', pyarrow.string()),
('volume_sold_liters', pyarrow.float64()),
('volume_sold_gallons', pyarrow.float64())
]
)
def run(
load_data_path: str,
save_data_path: str,
beam_args: List[str] = None,
) -> None:
"""Build and run the pipeline."""
options = PipelineOptions(beam_args)
load_data_filepattern = load_data_path + '/data-*'
save_date_file_prefix = save_data_path + '/data'
with beam.Pipeline(options=options) as pipeline:
_ = ( pipeline
| 'Read' >> beam.io.parquetio.ReadFromParquet(file_pattern=load_data_filepattern)
| 'Write' >> beam.io.parquetio.WriteToParquet(file_path_prefix=save_date_file_prefix , schema=parquet_schema, codec='snappy', file_name_suffix='.parquet')
)
if __name__ == "__main__":
logging.getLogger().setLevel(logging.INFO)
parser = argparse.ArgumentParser()
parser.add_argument(
"--save_data_path",
help="Output file path at GCS.",
)
parser.add_argument(
"--load_data_path",
help="Input file path at GCS.",
)
args, beam_args = parser.parse_known_args()
run(
load_data_path=args.load_data_path,
save_data_path=args.save_data_path,
beam_args=beam_args,
)
ポイントは、
- Beamのパイプライン処理の書き方
- apache_beam、PipelineOptionsをimportして「with beam.Pipeline(options=options) as pipeline:」というように書きます。
- その中で「_ = ( pipeline ….. )」と書いていますが、これは”pipeline”以降の入力と処理(右辺)を無名の出力(左辺)に渡すという意味合いで、”pipeline”に続けて「|」記号でやりたい処理を好きなだけ書いて繋げます。出力は無名じゃなくても当然できます。
- [Final Output PCollection] = ([Initial Input PCollection] | [First Transform]
| [Second Transform]
| [Third Transform]) - Beam用語で入出力はPCollection、処理はPTransformです。PCollectionはイミュータブルというのが肝です。
- Parquetデータの読み込みと書き出し
- 読み込みはbeam.io.parquetio.ReadFromParquet、書き出しはbeam.io.parquetio.WriteToParquetを使います。
- 最初読み込みにはReadFromParquetBatchedの方を使っていて毎回以下のエラーが出てハマりました・・ 。
- 「pyarrow.lib.ArrowTypeError: Expected bytes, got a ‘pyarrow.lib.ChunkedArray’ object」
- よく調べたら、ReadFromParquetBatchedはpyarrow.tableを返すのに対し、WriteToParquetは辞書型を入力しないといけなくて、それでうまくいきませんでした。ReadFromParquetは辞書型を返すので、こちらを使いました。
- WriteToParquetは面倒なことに引数にスキーマ定義が必要で、しかもpyarrowのスキーマを指定しなくてはいけません。import pyarrowを行って、上記のようなpyarrow.schemaを自分で書いて引数に渡します。ちなみにpyarrowはapache-beam[gcp]をpipインストールすれば一緒にインストールされるので、Dockerファイルに追加で書く必要はありませんでした。
- io.parquetioについては、公式ドキュメントページ(Beam 2.36.0)が参考になります。
- Beamパイプライン処理を実行する際の引数
- 実行時に、読み込み元のParquetデータのパスと、書き出し先のParquetデータのパスを指定できるようにしています。そのため同じ構造のParquetデータであれば、スクリプトを書き直さなくても柔軟に入出力を変えることができます。実行時の引数で渡せるのがFlexテンプレートの良いところですね。
- スキーマ定義も引数として実行時に渡せると、どんなParquetデータでも引数で対応できるようになり便利なので、最終的にはそのような使い方になると思います(今回はそこまでやってません)。
です。
実行時の引数のバリデーションもmetadataファイルに書くことができます。サンプルにあったmetadata.jsonを変数名だけ書き直して使いました。
metadata.json
{
"name": "Beam PARQUET Python flex template",
"description": "beam parquet example for python flex template.",
"parameters": [
{
"name": "load_data_path",
"label": "Input file path at GCS.",
"helpText": "The full path of your input file at GCS.",
"isOptional": true,
"regexes": [
"^gs:\\/\\/[^\\n\\r]+$"
],
"paramType": "GCS_READ_FILE"
},
{
"name": "save_data_path",
"label": "Output file path at GCS.",
"helpText": "The full path of your output file at GCS.",
"isOptional": true,
"regexes": [
"^gs:\\/\\/[^\\n\\r]+$"
],
"paramType": "GCS_WRITE_FILE"
}
]
}
DockerイメージおよびFlexテンプレートのビルド
上記までの準備できていればあとはビルドコマンドを実行するだけです。サンプルがそうなっていたのもありますが、Beamのパイプライン処理を書いたPythonスクリプトもDockerイメージの中に含めているので、スクリプトを書き直したらDockerイメージの再ビルドが必要です。Dockerイメージのタグの名前やmetadataファイルの中身が変わらなければFlexテンプレートの再ビルドは要りません。
# Dockerイメージのタグを指定しビルド export TEMPLATE_IMAGE="gcr.io/$GOOGLE_CLOUD_PROJECT/samples/dataflow/test-beam-parquet:latest" gcloud builds submit --tag $TEMPLATE_IMAGE # Flexテンプレートのパスを指定しビルド export TEMPLATE_PATH="gs://test-bucket01/samples/dataflow/test-beam-parquet.json" gcloud dataflow flex-template build $TEMPLATE_PATH \ --image "$TEMPLATE_IMAGE" \ --sdk-language "PYTHON" \ --metadata-file "metadata.json"
FlexテンプレートによるBeamパイプライン処理の実行
手動実行しますので、gcloud dataflowコマンドから以下のように引数を指定して実行します。プロンプトがすぐに返ってくるので、あとはDataflowのコンソールでジョブの状況を見たり、ログエクスプローラーで状況を確認します。
export REGION="asia-northeast1"
gcloud dataflow flex-template run "test-beam-parquet`date +%Y%m%d-%H%M%S`" \
--template-file-gcs-location "$TEMPLATE_PATH" \
--parameters load_data_path="gs://test-bucket01/non_partitioned/iowa_liquor_sales" \
--parameters save_data_path="gs://test-bucket01/non_partitioned/iowa_liquor_sales_test_beam" \
--region "$REGION"
処理中のジョブの状況はこんな感じでした。準備したParquetデータはそこまで大きくなかったですが(Snappy圧縮して約320MB。プレーンテキストの状態なら約3.3GB)、8個のワーカーが自動スケーリングされて、結局12分くらいかかりました。
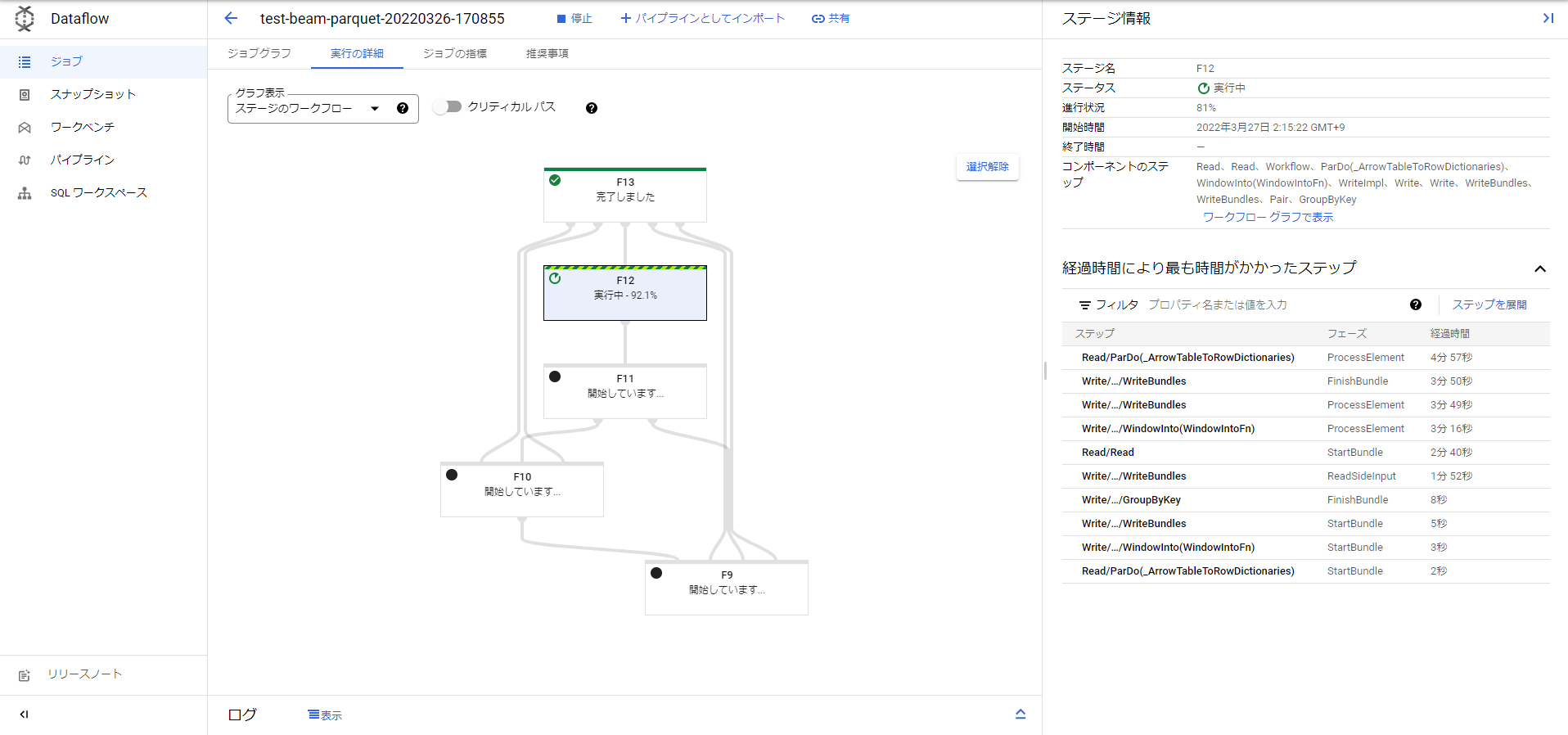
ステージのワークフロー(test_beam_parquet.py)
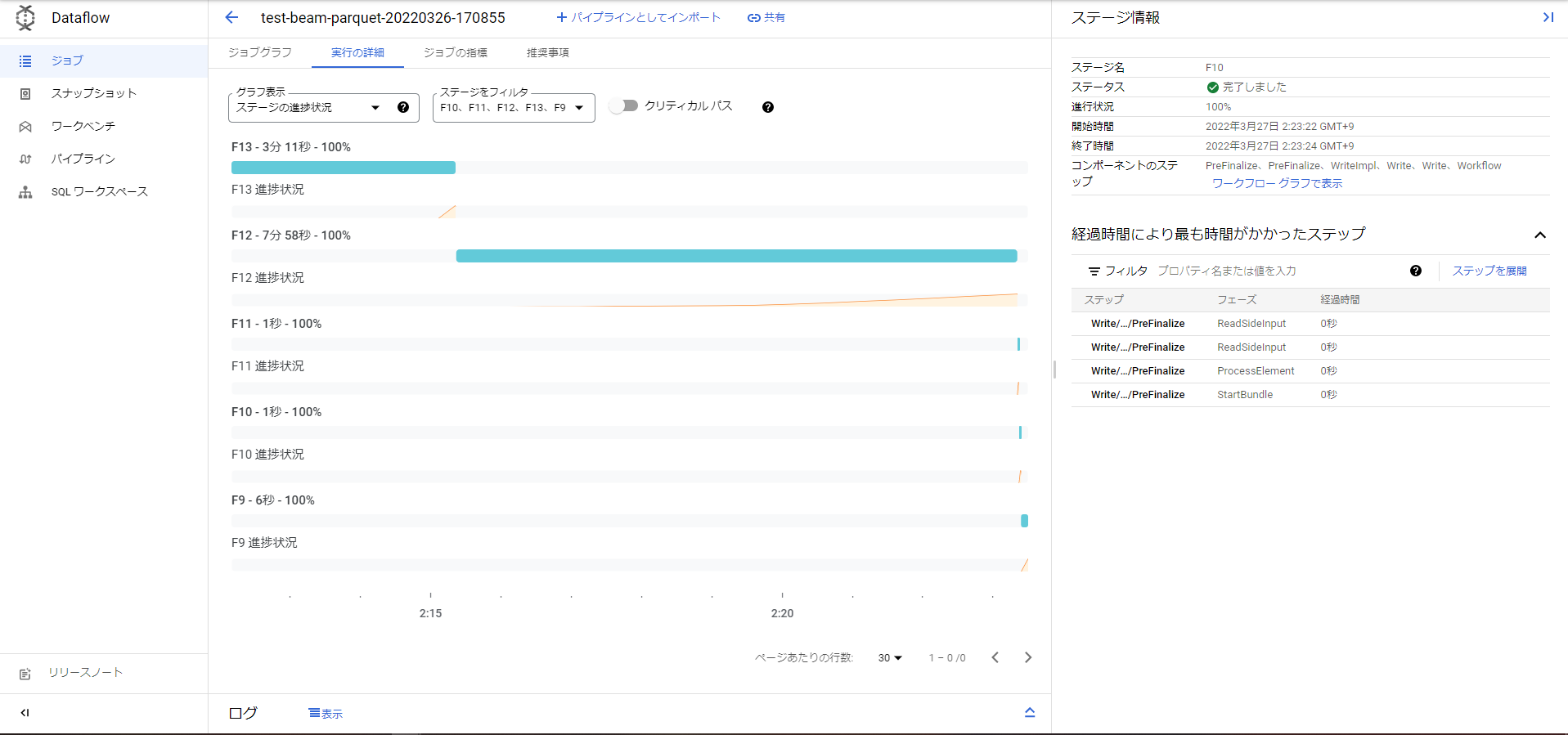
ステージの進捗状況(test_beam_parquet.py)
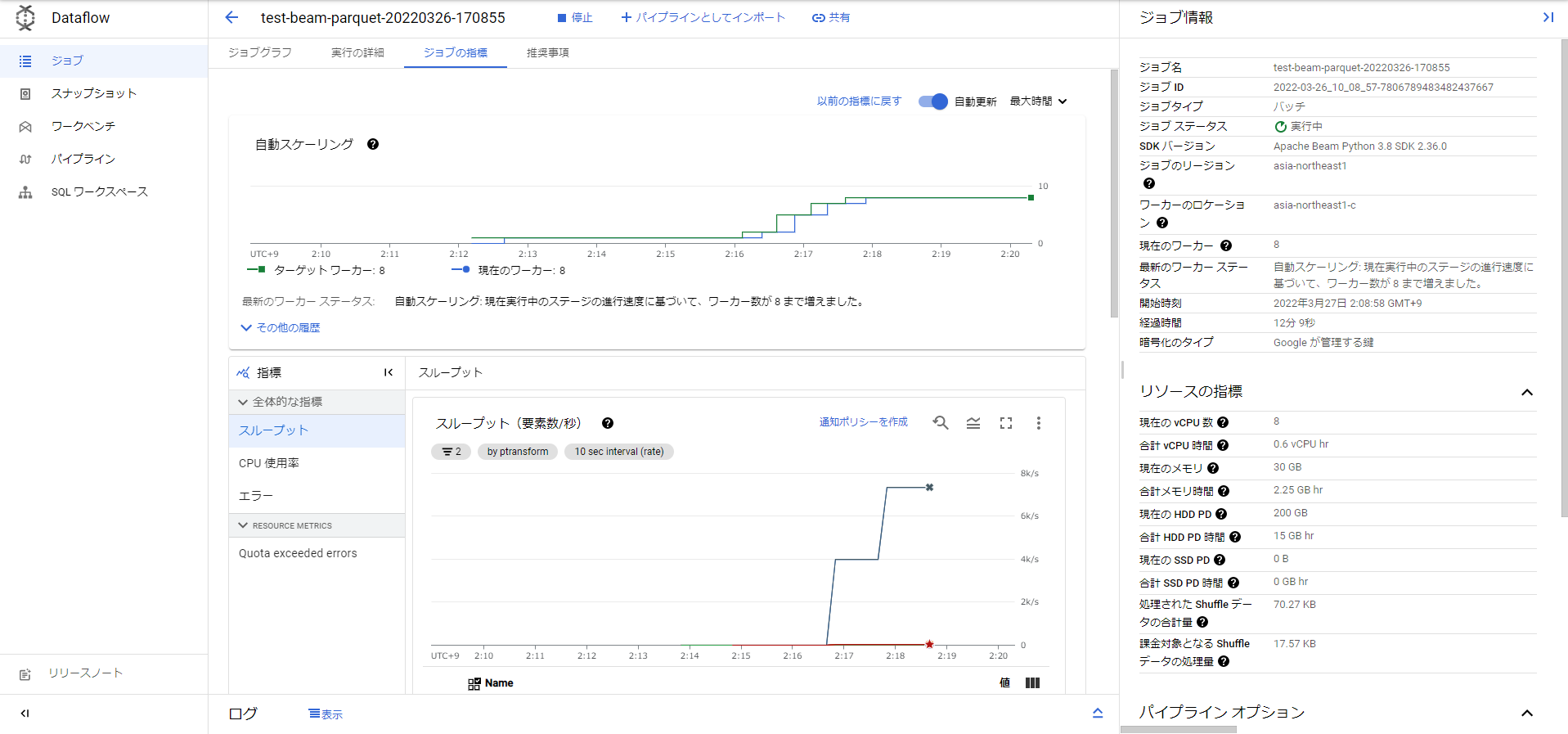
ワーカー自動スケーリング(test_beam_parquet.py)
次にPythonからBeamSQLを使った分散処理を試してみた
BeamSQLをPythonで使うためのDockerイメージ
Parquetデータを読み込んで書き出すという処理がうまくいったら、次は少し加工してデータを増やす処理を試してみました。SparkにはSparkSQLがありますが、BeamにもBeamSQLというのがあるので使いました。
まず先に書いておくと、BeamのPython SDKを使っていますが、BeamSQLはJavaを使うのでJDKをインストールする必要がありました(エラーが出て気が付きますね)。
sql_taxi.pyというサンプルにはJava 8が必須と書いてあるので、DockerイメージにJava8のJDKを入れることにしました。
BeamSQLを試すために書き直したDockerファイルは以下です。
FROM gcr.io/dataflow-templates-base/python38-template-launcher-base
ENV FLEX_TEMPLATE_PYTHON_REQUIREMENTS_FILE="/template/requirements.txt"
# 今回のPythonスクリプトをtest_beam_parquet_large.pyという名前にしたのでそれを指定
ENV FLEX_TEMPLATE_PYTHON_PY_FILE="/template/test_beam_parquet_large.py"
COPY . /template
# We could get rid of installing libffi-dev and git, or we could leave them.
RUN apt-get update \
&& apt-get install -y libffi-dev git software-properties-common \
&& rm -rf /var/lib/apt/lists/* \
# Upgrade pip and install the requirements.
&& pip3 install --no-cache-dir --upgrade pip \
&& pip3 install --no-cache-dir -r $FLEX_TEMPLATE_PYTHON_REQUIREMENTS_FILE \
# Download the requirements to speed up launching the Dataflow job.
&& pip3 download --no-cache-dir --dest /tmp/dataflow-requirements-cache -r $FLEX_TEMPLATE_PYTHON_REQUIREMENTS_FILE
# Since we already downloaded all the dependencies, there is no need to rebuild everything.
ENV PIP_NO_DEPS=True
# Java8のJDKをインストールするため以下を追記
# Install Java8
RUN apt-add-repository 'deb http://security.debian.org/debian-security stretch/updates main' \
&& apt-get update \
&& apt-get install -y openjdk-8-jdk
ENV JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
RUN export JAVA_HOME
このDockerファイルを使ってさっきとは別のDockerイメージのタグを指定してDockerイメージを作っておきます。Dockerイメージのタグが変わったので、Flexテンプレートも別のパスで作り直しておきます。requirements.txtとmetadata.jsonはさっきと同じ内容で良いのでそのまま使いました。
Parquetデータを読み込んで10倍の件数にして並列で書き出す
BeamSQLを何とか使って並列のパイプライン処理を試す
Pythonスクリプトでいろいろな書き方ができますが、当初の目的通りBeamSQLを使った書き方を試しました。その結果、まったくうまくいかず、20数回も試してしまうことに・・・。PythonからParquetデータをBeamSQLで扱うと、スキーマ定義の変換がとても大変ということがわかりました・・。
結局、10倍の件数ではなく、小さいデータでBeamSQLを試して最後に通ったやり方がこちらです。Parquetデータを読み込んだ後、BeamSQLに渡すときにスキーマ定義をNamedTupleで紐づけることが必要で、そのことの理解と書き方が最初さっぱりわからず、過去一くらいハマりました。。
#!/usr/bin/env python3
import argparse
import logging
from typing import List
def run(
load_data_path: str,
save_data_path: str,
beam_args: List[str] = None,
) -> None:
"""Build and run the pipeline."""
import datetime
import pyarrow
import apache_beam as beam
from apache_beam.options.pipeline_options import PipelineOptions
from apache_beam.transforms.sql import SqlTransform
from apache_beam import coders
from typing import NamedTuple, Optional
iowa_liquor_sales = NamedTuple('iowa_liquor_sales',
[
('invoice_item_number', str),
('sale_date', str),
('store_number', int),
('store_name', str),
('address', str),
('city', str),
('zip_code', int),
('store_location', str),
('county_number', int),
('county', str),
('category', str),
('category_name', str),
('vendor_number', int),
('vendor_name', str),
('item_number', int),
('item_description', str),
('pack', int),
('bottle_volume', int),
('state_bottle_cost', str),
('state_bottle_retail', str),
('bottles_sold', int),
('sale', str),
('volume_sold_liters', float),
('volume_sold_gallons', float)
]
)
coders.registry.register_coder(iowa_liquor_sales, coders.row_coder.RowCoder)
query = "SELECT invoice_item_number, sale_date, store_number, store_name, address, city, zip_code, store_location, county_number, county, category, category_name, vendor_number, vendor_name, item_number, item_description, pack, bottle_volume, state_bottle_cost, state_bottle_retail, bottles_sold, sale, volume_sold_liters, volume_sold_gallons FROM PCOLLECTION"
options = PipelineOptions(beam_args)
load_data_filepattern = load_data_path + '/data-*'
save_date_file_prefix_list = []
for i in range(2):
save_date_file_prefix_list.append(save_data_path + '/data' + str(i))
def change_pk(records, add_id):
new_records = records.copy()
new_records["invoice_item_number"]=new_records["invoice_item_number"] + add_id
new_records["sale_date"]=new_records["sale_date"].strftime('%Y-%m-%d')
records_schema = iowa_liquor_sales(**new_records)
return records_schema
with beam.Pipeline(options=options) as pipeline:
records = (pipeline
| 'Read' >> beam.io.parquetio.ReadFromParquet(file_pattern=load_data_filepattern)
)
write0 = (records
| 'ChangePK-0' >> beam.Map(change_pk, add_id="_0").with_output_types(iowa_liquor_sales)
| 'BeamSQL-0' >> SqlTransform(query)
| 'Print-0' >> beam.Map(print)
)
write1 = (records
| 'ChangePK-1' >> beam.Map(change_pk, add_id="_1").with_output_types(iowa_liquor_sales)
| 'BeamSQL-1' >> SqlTransform(query)
| 'Print-1' >> beam.Map(print)
)
if __name__ == "__main__":
logging.getLogger().setLevel(logging.INFO)
parser = argparse.ArgumentParser()
parser.add_argument(
"--save_data_path",
help="Output file path at GCS.",
)
parser.add_argument(
"--load_data_path",
help="Input file path at GCS.",
)
args, beam_args = parser.parse_known_args()
run(
load_data_path=args.load_data_path,
save_data_path=args.save_data_path,
beam_args=beam_args,
)
ParquetデータのWriteはどこ行ったという話ですが、BeamSQLを使った後でまた別の型変換を何かしらの方法でやらないとダメみたいで(そこまでは辿り着きました)、結局検証中にわからなかったので諦めました。型変換やスキーマ定義が何度も必要だったりと、できたところで結局使うことがないので・・。
ポイントとハマったところを書きます。
- Beamパイプラインの並列処理
- Beamのいいところは、一つのPCollectionに対して、複数のPTransform処理を同時に動かす処理を簡潔に書くことができるところです。今回の場合はParquetデータを読み込んだ結果のPCollection(records)を次の入力として、BeamSQLの参照クエリを実行した結果をprintするPTransform処理を同時に二つ動かしています。
- importを書く場所
- サンプルスクリプトを書き直した今回のPythonスクリプトでは、メインの処理はrun関数にあります。今回のようなパイプライン処理の場合は、使うモジュールはrun関数の中でimportをしないとモジュールがないと怒られてしまうので、上記のようにrun関数のところに書くか、「–save_main_session=True」で実行します。
- データ加工の内容とアプローチ
- 行ったデータ加工は、データを増やすにあたりPKの値を重複させたくなかったので、PKの値のうしろに並列処理ごとに別々の数字のIDを付け加えるというものです。
- 当初はBeamSQLでSQLを使って加工しようと思ってましたが、色々とハマったこともあり、関数を書いてbeam.Mapから呼び出す書き方にしました。この時点でBeamSQLを使う理由はないんですが検証のためにあえて使いました。
- change_pkという関数を作り、ReadFromParquetから読み込んだデータ(辞書型)を渡します。関数内でcopy()して、PKカラムの値を書き換えて辞書型を返します。辞書型データをcopy()するのは、並列処理をしたときに一つの処理が書き換えた後のデータを他の処理が参照してしまって狙い通りの値にならないためです(それでも結果的にユニークになりますが)
- PythonでのSqlTransformの使い方
- BeamSQLを使うにはSqlTransformを使うんですが、Pythonから使う場合はこれが大変で・・。
- 「iowa_liquor_sales = NamedTuple(‘iowa_liquor_sales’, … )」という記述と「coders.registry.register_coder(iowa_liquor_sales, coders.row_coder.RowCoder)」という記述がありますが、これはNamedTupleでiowa_liquor_salesというスキーマ定義をして、読み込んだデータ(辞書型)をiowa_liquor_salesに渡してスキーマ定義を紐づけるというものです。
- 日付型のsale_dateカラムをNamedTupleでどう定義づけるかわからなかったので文字列で定義しました。change_pk関数の中に日付カラムを文字列に変換する処理も加えました。
- また、change_pk関数を呼んでいるbeam.Mapに「.with_output_types(iowa_liquor_sales)」を付けました。
- これらのスキーマ定義の紐づけのやり方は、stackoverflowのこちらとこちらなどを参照しました。
- スキーマ定義と紐づけないと「Caused by: org.apache.beam.vendor.guava.v26_0_jre.com.google.common.util.concurrent.UncheckedExecutionException: java.lang.IllegalArgumentException: Unknown Coder URN beam:coder:pickled_python:v1. Known URNs:」のようなエラーで怒られます。
- BeamSQLはJava SDKの実装でできていて、Pythonから使う場合、PythonのシリアライゼーションをJavaがわからないためのようです。逆に言えば、Java SDKを使う場合はもっと簡単にSqlTransformを使えるはずです。
- SqlTransformでのクエリ
- これはとてもシンプルで、SELECT文のFROM句のあとは”PCOLLECTION”と書けばOKです。ちなみにBeamSQLはBeam Calcite SQLとBeam ZetaSQLの二種類から選ぶことができ、デフォルトは前者のCalcite SQLとなっています。今回はZetaSQLは試していません。
BeamSQLを使わずに10倍に件数を増やしてParquetデータを書き出す
最終的に、BeamSQLを使わずに書いたのがこちらです。日付型のsale_dateカラムも余計に変換することなくpyarrowのdate32型を割り当てて、問題なくParquetデータに書き出すことができました。
#!/usr/bin/env python3
import argparse
import logging
from typing import List
def run(
load_data_path: str,
save_data_path: str,
beam_args: List[str] = None,
) -> None:
"""Build and run the pipeline."""
import datetime
import pyarrow
import apache_beam as beam
from apache_beam.options.pipeline_options import PipelineOptions
# Defines parquet schema for the output table.
parquet_schema = pyarrow.schema(
[
('invoice_item_number', pyarrow.string()),
('sale_date', pyarrow.date32()),
('store_number', pyarrow.int64()),
('store_name', pyarrow.string()),
('address', pyarrow.string()),
('city', pyarrow.string()),
('zip_code', pyarrow.int64()),
('store_location', pyarrow.string()),
('county_number', pyarrow.int64()),
('county', pyarrow.string()),
('category', pyarrow.string()),
('category_name', pyarrow.string()),
('vendor_number', pyarrow.int64()),
('vendor_name', pyarrow.string()),
('item_number', pyarrow.int64()),
('item_description', pyarrow.string()),
('pack', pyarrow.int64()),
('bottle_volume', pyarrow.int64()),
('state_bottle_cost', pyarrow.string()),
('state_bottle_retail', pyarrow.string()),
('bottles_sold', pyarrow.int64()),
('sale', pyarrow.string()),
('volume_sold_liters', pyarrow.float64()),
('volume_sold_gallons', pyarrow.float64())
]
)
options = PipelineOptions(beam_args)
load_data_filepattern = load_data_path + '/data-*'
save_date_file_prefix_list = []
for i in range(10):
save_date_file_prefix_list.append(save_data_path + '/data' + str(i))
def change_pk(records, add_id):
new_records = records.copy()
new_records["invoice_item_number"]=new_records["invoice_item_number"] + add_id
return new_records
with beam.Pipeline(options=options) as pipeline:
records = (pipeline
| 'Read' >> beam.io.parquetio.ReadFromParquet(file_pattern=load_data_filepattern)
)
write0 = (records
| 'ChangePK-0' >> beam.Map(change_pk, add_id="_0")
| 'Write-0' >> beam.io.parquetio.WriteToParquet(file_path_prefix=save_date_file_prefix_list[0], schema=parquet_schema, codec='snappy', file_name_suffix='.parquet')
)
write1 = (records
| 'ChangePK-1' >> beam.Map(change_pk, add_id="_1")
| 'Write-1' >> beam.io.parquetio.WriteToParquet(file_path_prefix=save_date_file_prefix_list[1], schema=parquet_schema, codec='snappy', file_name_suffix='.parquet')
)
write2 = (records
| 'ChangePK-2' >> beam.Map(change_pk, add_id="_2")
| 'Write-2' >> beam.io.parquetio.WriteToParquet(file_path_prefix=save_date_file_prefix_list[2], schema=parquet_schema, codec='snappy', file_name_suffix='.parquet')
)
write3 = (records
| 'ChangePK-3' >> beam.Map(change_pk, add_id="_3")
| 'Write-3' >> beam.io.parquetio.WriteToParquet(file_path_prefix=save_date_file_prefix_list[3], schema=parquet_schema, codec='snappy', file_name_suffix='.parquet')
)
write4 = (records
| 'ChangePK-4' >> beam.Map(change_pk, add_id="_4")
| 'Write-4' >> beam.io.parquetio.WriteToParquet(file_path_prefix=save_date_file_prefix_list[4], schema=parquet_schema, codec='snappy', file_name_suffix='.parquet')
)
write5 = (records
| 'ChangePK-5' >> beam.Map(change_pk, add_id="_5")
| 'Write-5' >> beam.io.parquetio.WriteToParquet(file_path_prefix=save_date_file_prefix_list[5], schema=parquet_schema, codec='snappy', file_name_suffix='.parquet')
)
write6 = (records
| 'ChangePK-6' >> beam.Map(change_pk, add_id="_6")
| 'Write-6' >> beam.io.parquetio.WriteToParquet(file_path_prefix=save_date_file_prefix_list[6], schema=parquet_schema, codec='snappy', file_name_suffix='.parquet')
)
write7 = (records
| 'ChangePK-7' >> beam.Map(change_pk, add_id="_7")
| 'Write-7' >> beam.io.parquetio.WriteToParquet(file_path_prefix=save_date_file_prefix_list[7], schema=parquet_schema, codec='snappy', file_name_suffix='.parquet')
)
write8 = (records
| 'ChangePK-8' >> beam.Map(change_pk, add_id="_8")
| 'Write-8' >> beam.io.parquetio.WriteToParquet(file_path_prefix=save_date_file_prefix_list[8], schema=parquet_schema, codec='snappy', file_name_suffix='.parquet')
)
write9 = (records
| 'ChangePK-9' >> beam.Map(change_pk, add_id="_9")
| 'Write-9' >> beam.io.parquetio.WriteToParquet(file_path_prefix=save_date_file_prefix_list[9], schema=parquet_schema, codec='snappy', file_name_suffix='.parquet')
)
if __name__ == "__main__":
logging.getLogger().setLevel(logging.INFO)
parser = argparse.ArgumentParser()
parser.add_argument(
"--save_data_path",
help="Output file path at GCS.",
)
parser.add_argument(
"--load_data_path",
help="Input file path at GCS.",
)
args, beam_args = parser.parse_known_args()
run(
load_data_path=args.load_data_path,
save_data_path=args.save_data_path,
beam_args=beam_args,
)
慣れてくると、今回のような一つの入力に対して並列で同時に書き出す処理はBeamで見やすく書けますね(書き方がわかっていればですが・・)。
ポイントは上述のものに加えて、
- 並列で同時に書き出すため、保存されるデータファイルが処理毎に別名になるようにして上書きされないようにしました。
- ただし、このやり方はファイル分割が適切でなくなる(必要以上にファイルが細かくなる)可能性があります。
です。
処理中のジョブの状況は以下のようになりました。
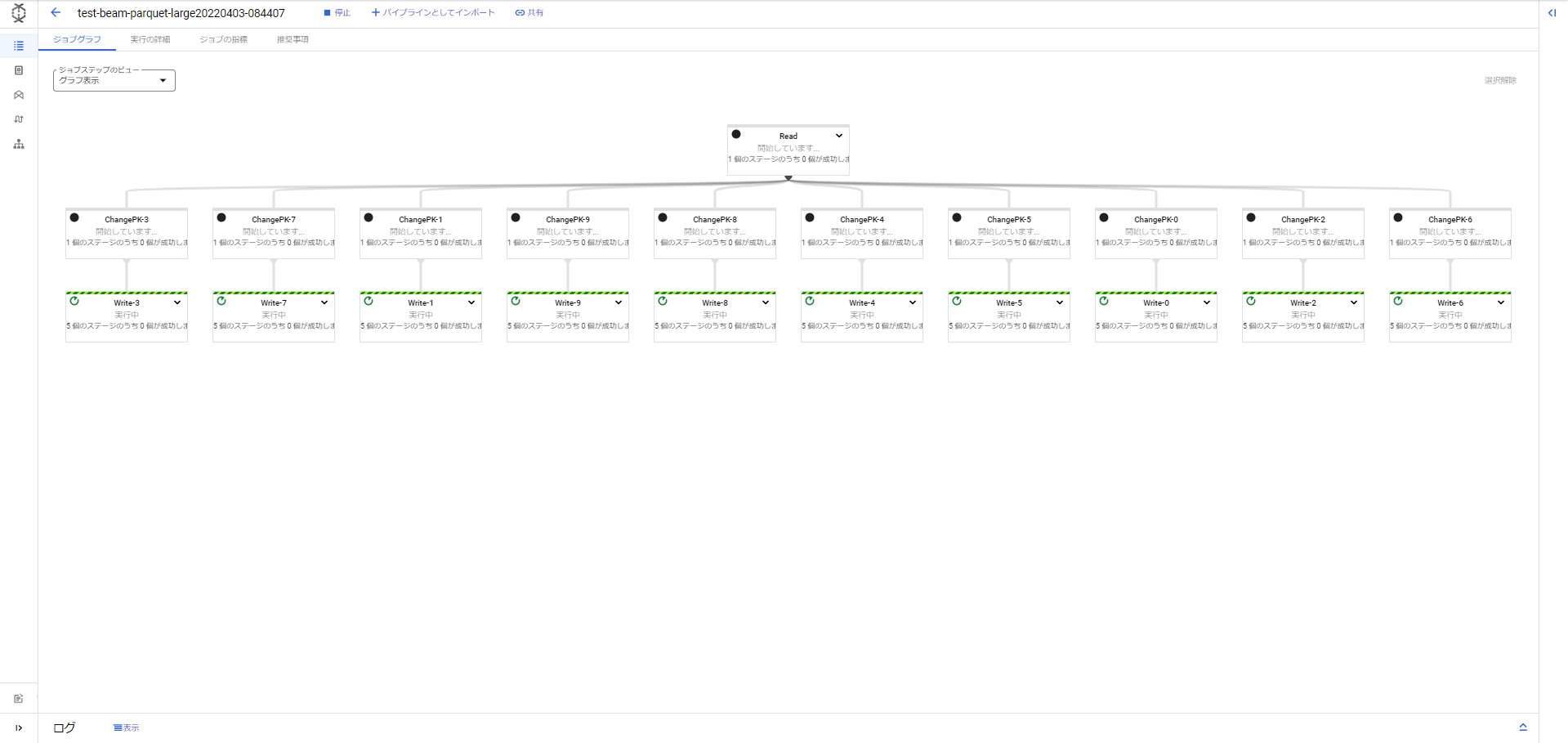
ジョブグラフ(test_beam_parquet_large.py)
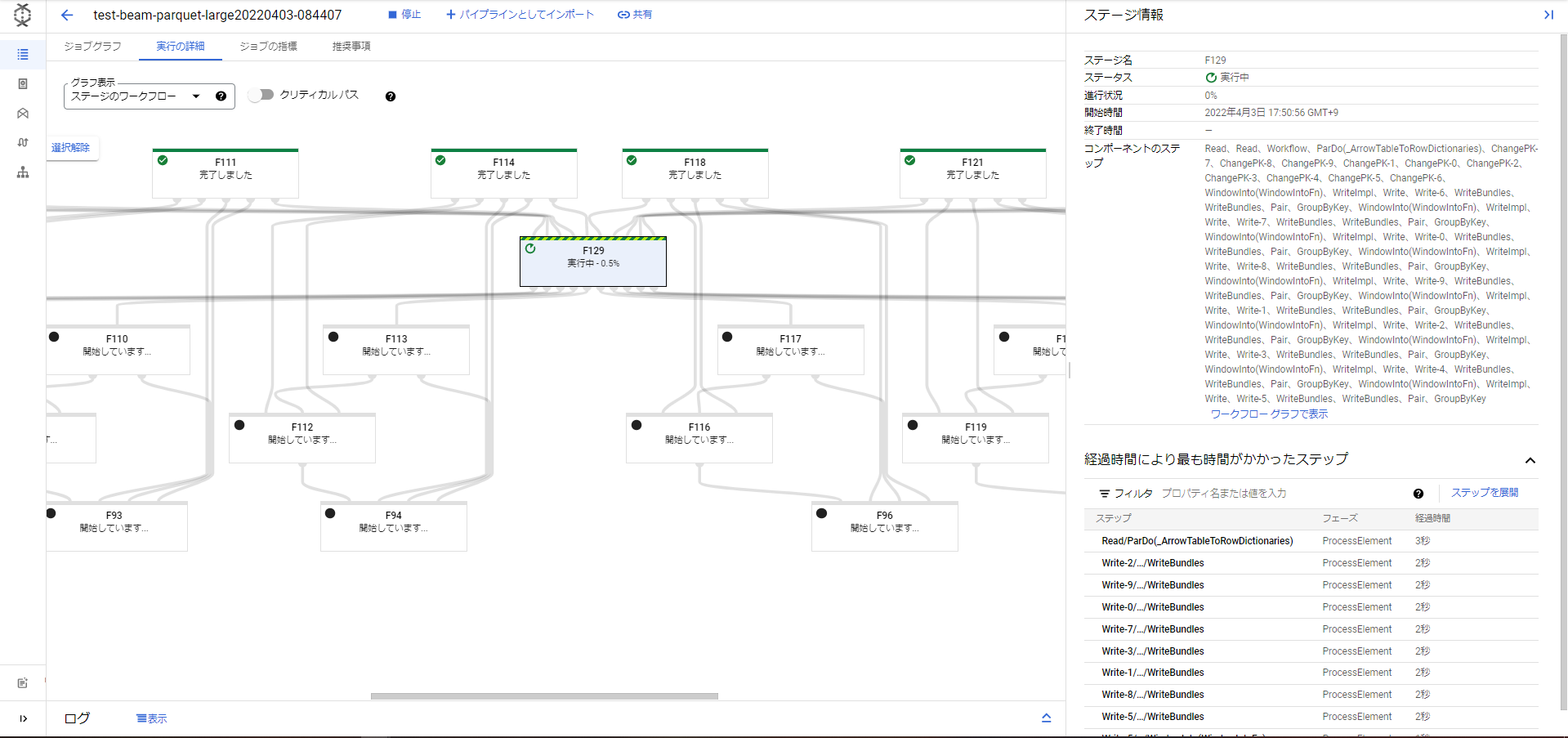
ステージのワークフロー(test_beam_parquet_large.py)
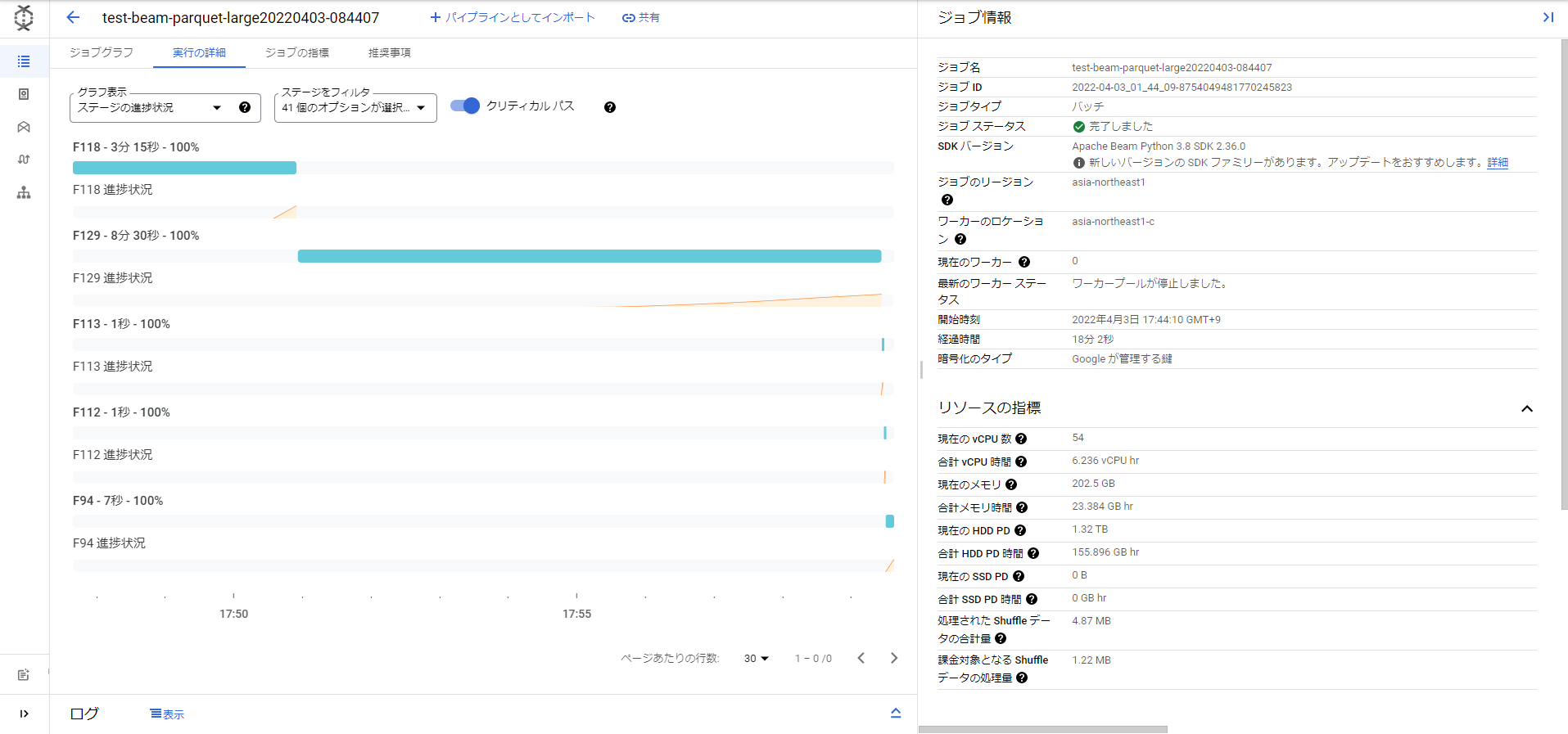
実行の詳細(test_beam_parquet_large.py)
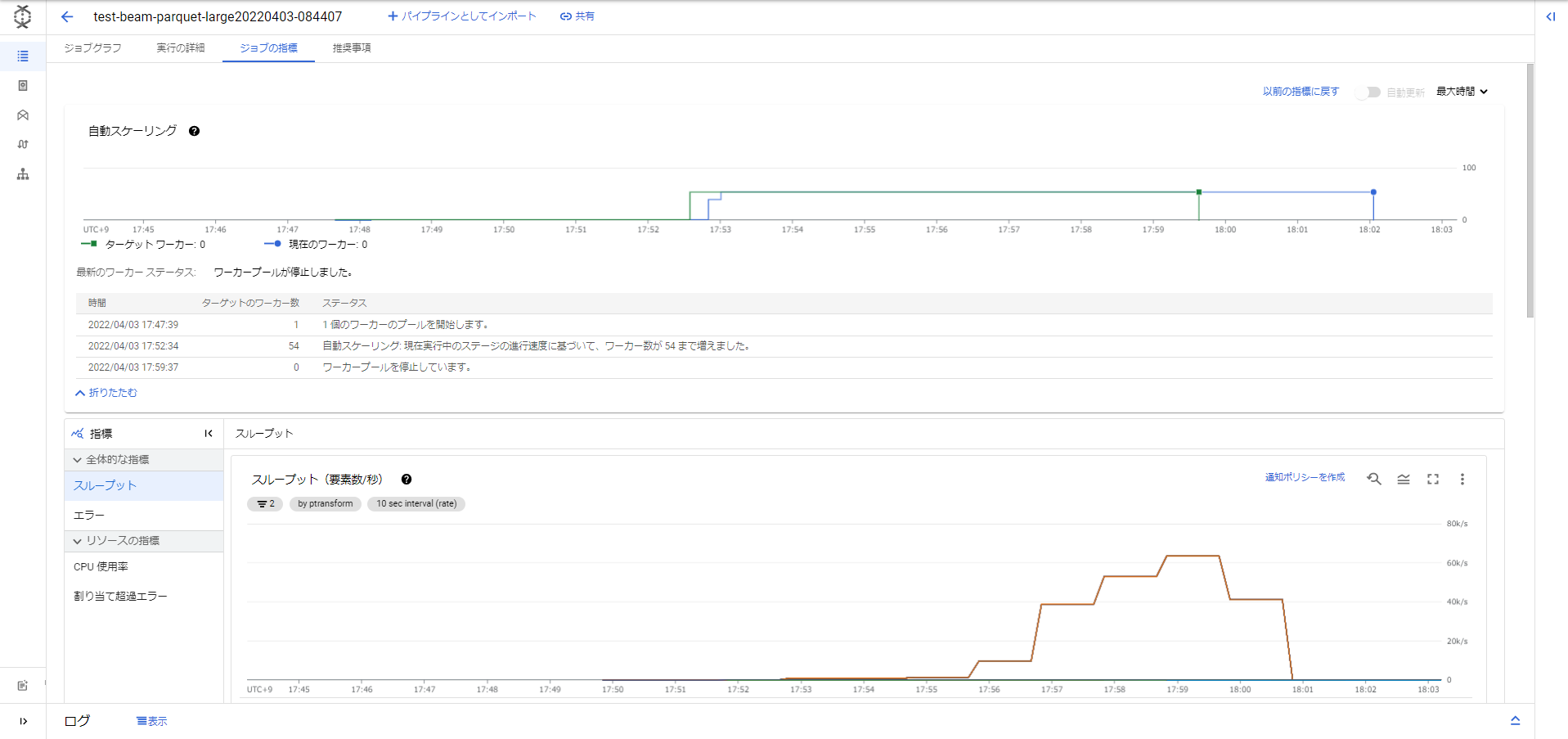
ジョブの指標(test_beam_parquet_large.py)
ワーカー数が54個まで増えたことがわかります。1ワーカーがどんなスペックかという話もありますがそれでも54個は結構増やして処理してくれたなという感じです。先ほどのParquetデータを読み書きするだけの処理で12分ほどだったので、10倍に増やす処理でも実はそこまで時間が増えてないことがわかりました。
やっぱりDataflowは大規模になればなるほどスループットが出て真価を発揮するような気がします。
まとめ
DataflowとBeamSQLを試してわかったことは、
- Python SDKでBeamSQLを使うメリットが今のところあんまりない印象。
- Spark/PySparkにおけるSparkSQLのようにコア技術として統合されているのと違い、Java SDKの実装を呼んでいるだけでしかもまだスムーズにいかないので今後に期待。
- Java SDKであればBeamSQLは便利そう。
- 複数のデータをJOINするならSQLの方がやりやすいのでBeamSQLの出番かも。
- Flexテンプレートを利用したDataflowは扱うデータサイズが小さいときに使っても、処理速度が速くない。
- Dockerイメージをワーカーに展開している分が遅くなるのは理解できますが、それでもSnappy圧縮して約320MBのParquetデータを読み込んで書き出すだけでも12分かかっているので、ちょっと遅い印象(数分か、せめて4-5分?)。
- 逆に巨大ビッグデータになると、自動でワーカーをたくさん増やして処理のスループットが高まるので良さそうです。ただ、ワーカー数がたくさん増えたときの料金は気になるところ。
- ある程度のビッグデータならBigQueryにインポートしてSQLで処理してから、エクスポートした方が圧倒的に速いかもしれない・・(Dataflowに限らない話ですが)。
- Python使うなら、Dataflowより昨年末に発表されたDataproc Serverless for Sparkでいいんじゃないか感。
- 以前検証したブログでβ版のDataproc on GKEを試したんですが、その数か月後にDataproc Serverless for Sparkが発表されてました・・。
- Dataproc Serverless for Sparkがもっとこなれてきたら検証してみようと思います。
最後に
次世代システム研究室では、データサイエンティスト/機械学習エンジニアを募集しています。ビッグデータの解析業務など次世代システム研究室にご興味を持って頂ける方がいらっしゃいましたら、ぜひ 募集職種一覧 からご応募をお願いします。皆さんのご応募をお待ちしています。
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD