2021.07.05
クッキーのないネット広告世界に向き合いたい:知識の蒸留による自然言語処理編
こんにちは。次世代システム研究室のK.S.(女性、外国人)です。
今回(2021Q2)はクッキーレス(cookieless)時代のインターネット広告に向き合うため、知識の蒸留の関連技術を勉強し、自然言語処理に基づいてユーザーのクリック率を予測することについて試してみたことを共有します。
まず、インターネット広告とは何かを説明しながら、クッキーとは何か、クッキーがなくなるとインターネット広告にどのような影響があるのかを共有します。次に、クッキーを使わなくても、自然言語処理の活用で、うまく広告を表示できないかを検討します。そして、実用のため精度を保ったまま軽量なモデルを作成する方法の一つにある知識の蒸留を紹介します。最後に、実装の例として、ユーザーに推奨したニュースをどれくらいクリックしてくれるかを評価します。直接のクリック予測ではなく、特徴量(情報)として使う可能性もありますので、ニュース記事の分類も評価します。
TL;DR(要約)
- cookielessと言っても、3rd party cookieがなくなりますが、完全にcookieがなくなるわけではありません。が、今回のブログでは最悪の場合を考えて、完全にクッキーがない状況で遊んでみます。
- 知識の蒸留とは学習済みの複雑なモデルから知識を蒸留し、高精度で軽量なモデルに生かすことです。
- 実験結果による、テキスト情報のみを用いてのクリック予測は厳しいですが、テキスト分類の精度向上はまだ期待できそうです。また、単語の選び方もクリック確率に影響がありそうで、予測モデルへの活用を考えてみたいです。
1. インターネット広告とは
インターネット広告はインターネットを通して、ウェブサイト、メール、スマートフォンのアプリなどを利用し、企業の製品やサービスを掲載しながら、宣伝活動を行うことです。広告方法はリスティング、ディスプレイ、ネイティブ、アフィリエイト、SNSなど、沢山ありますが、今回はその一つであるディスプレイ広告について話します。
ディスプレイ広告は各媒体が提携しているポータルサイトの広告場所に表示される画像やテキストの広告です。ちなみに、ポータルは正門という意味で、ポータルサイト(portal site)は利用者がインターネットに接続したとき、一番初めにアクセスするウェブサイトということです。それでは、サイトに表示されたものはどのようにお金になるのでしょうか。
ディスプレイ広告の収益は課金形態になります。課金方法は主に2パターンあり、CPC(Click Per Cost)と CPM(Cost Per Mille)です。CPCはクリック単価で、広告を1回クリックした際に発生する費用に対する課金方法です。課金の価格はクリック数(クリックされた回数)になります。クリック率が低いほど、1クリックあたりの単価も低くなります。CPMはインプレッション単価で、インプレッション数(広告が表示された回数)に対する課金方法です。課金の価格は広告が1,000回表示される度に料金が発生します。広告が表示される際に広告が発生するタイプの広告です。広告主と広告掲載媒体との契約になり、ユーザーがその広告を何回クリックするかは費用に影響ないので、ブランディングなどの目的にも使われます。
また、広告出稿の費用効果を高めるため、DSP(Demand-Side Platform)サービスが使われています。DSPは広告主が用意するプラットフォームです。ちなみに、広告枠をなるべく高く買ってもらいたい媒体側のためのプラットフォームはSSP(Supply-Side Platform)と呼ばれています。DSPでは、広告がリアルタイムに入札され、落札後に特定のユーザーに向けて広告が配信されます。この時、ターゲットユーザーの情報(性別、年齢、居住地、興味、配信先サイト、曜日時間など)の条件に合わせて、広告が配信されるので、効果的と考えられます。
DSPには様々な機能がありますが、一つの効果的な機能はリターゲティング(リマーケティング)です。これはサイトを訪問したユーザーに対して、そのサイトで見た商品などに興味が高いことを仮定し、見た商品などの広告を配信する情報です。この方法は効果的ですが、同じ広告を何度も表示していると逆効果になる可能性があります。
それでは、本記事の課題です。DSPが利用しているユーザーの情報はクッキー(cookie)です。最近、個人情報保護の視点から、あるクッキー情報が使えなくなっていくようですので、広告の効果が薄くなる可能性が出てきます。それは、どのような感じなのかを紹介したいと思います。
クッキーとクッキーレス時代
クッキー(cookie)はウェブサイト(website)を訪問したユーザーの情報を一時的に保存しておくための仕組みです(美味しく食べるクッキーではありません、笑)。
cookieはユーザーが、あるwebsiteを訪ねた時に、ユーザー情報が使っていたweb browser(Apple Safari, Google Chrome, Microsoft Edge, Mozilla Firefoxなど)に保存されたデータです。主に、二つのタイプがあり、1stと3rd party cookiesです。1st party cookiesは直接訪問しているwebsiteから、発行されるcookiesです。3rd party cookiesは訪問しているwebsiteと異なるwebsiteから発行されるcookieで、主に、広告(リターゲッティングなど)で使われているものです。ちなみに、2nd party cookieは1st partyの会社から他の会社に転送されたcookiesです。
近年、個人情報保護の視点から、Apple Safariでは2020年3月から、3rd party cookieをdefaultで完全にブロックしています。Google Chromeも2022年を目処に利用制限すると表明しましたが、この記事を書いている途中で廃止が2023年に延期されることが発表されました。そうなると、リターゲティングで利用している情報がなくなるというわけですし、クリック率にも影響を与える可能性があります。
繰り返しますが、3rd party cookieはなくなりますが、1st party cookieはまだ使えるようですでの、全てのcookiesがなくなるわけではありません。ちなみに、対策案として、FLoC(Federated Learning of Cohorts)というgoogleの3rd party cookieに代わる技術やIM-DMP(Intimate Merger-Data Management Platform)という3rd party dataの一部分はオフラインのデータを紐づけて、1st party cookieと掛け合わせるようなプラットフォームなども注目されているようです。
2. CTR予測モデルと自然言語処理
CTR予測モデル
上記に説明したCPC(クリック単価)による、クリック率(Click-Through Rate, CTR)が高いほど、1クリックあたりの単価も高くなります。そこで、よりCTRを高めるための様々な機械学習モデルが開発されています。基本的に、モデルに使われている特徴量(情報)は主に3つあり、ユーザー情報、広告情報、媒体情報です。ユーザー情報は性別、興味、配信サイトなど主にクッキーから取得した情報です。広告の情報はバナー広告の場所、広告主、広告画像、広告カテゴリ、広告テキストです。媒体の情報はURL、遷移元、枠(サイト内で広告を入れるスペース)です。それらの情報を利用し、機械学習モデルを作成します。モデルでCTR予測しながら、入札を行います。
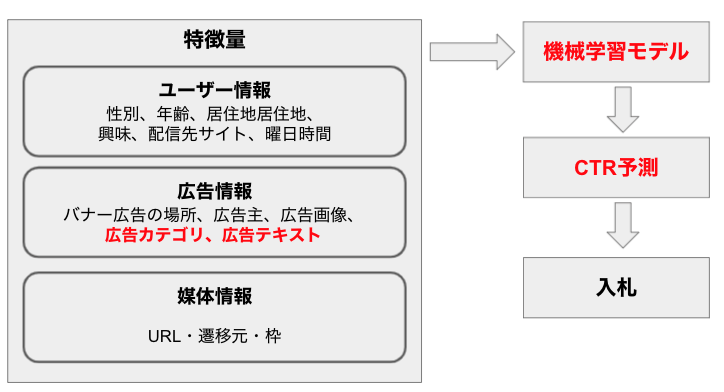
上述したように、将来は一番重要なユーザー情報のクッキーはある部分がなくなっていきますが、今回のブログでは最悪の場合を考えて、完全にクッキーがない状況で遊んでみます。クッキーの代替案として、広告情報の活用を高めることができないかを試したいと思います。注目したいのは広告カテゴリと広告テキストですので、自然言語処理の技術周りを検討します。
自然言語処理(Natural Language Processing, NLP)
自然言語処理(Natural Language Processing, NLP)はコンピュータに言語を理解と処理させる一連の技術です。コンピュータが言語を処理できたら、翻訳、テキスト分類、文法訂正、感情分析、などに適用することも可能です。よりテキスト分類や処理ができたら、広告にどのようなテキストを記載することで、よりクリック率を高めることができるのかを推測できるようになるかもしれません。
自然言語処理にとって、重要な技術といえば、分散表現(Distributed Representation)だと思います。コンピュータは単語の意味がわからないので、コンピュータに言語を理解させるため数字に変換する必要があります。かつ、単語は沢山あり、単語と単語の意味や関係性があります。そこで、分散表現は単語を低次元の実数値ベクトルで表す表現です。有名な例ですが、単語を実数値ベクトルに変換することで、「King – Man + Woman = Queen」と表現することが可能になります。
分散表現の技術は沢山あります。
- 単語分散表現
- 文脈依存なし:Word2Vec, FastText, GloVe(Global Vectors)
- 文脈依存あり:ELMo, BERT, GPT
- 文書分散表現
- 教師なし:Doc2Vec
- 教師あり:SentenceBERT
最新の流行技術といえば、BERT(Bidirectional Encoder Representations from Transformers)とBERTの発展版、GPT3(Generative Pre-trained Transformer 3)なのではないかと思います。自然言語処理モデルはより人間らしく、精度もどんどん高まってきています。一方、モデルが複雑になり、サイズも大きく、計算コストも高くなって、処理速度が遅くなり、扱いにくくなってきました。そして、この課題に対処するため、知識の蒸留が生まれました。
3. 知識の蒸留(Knowledge Distillation, KD)
知識の蒸留(Knowledge Distillation, KD)は学習済みの複雑なモデルからの知識を蒸留し、軽量なモデルに生かすという技術です。そうすることで、ある程度の精度を保ったままで処理速度が早くなった軽量なモデルを作成することができ、機械学習モデルをスマートフォンやエッジデバイスなどで利用することも実用化も期待できます。元のアイデアは2006年にモデル圧縮の論文が提案され、2015年にGoogle社でGeoffrey Hinton先生とOriol VinyalsさんとJeff Deanさんから知識の蒸留の論文が提案されました。その後、様々な分野に適用され、2019年に、DistilBERTといった自然言語処理モデルの軽量版が発表され、2020年に、CTR予測に適応した論文も発表されました。
具体的に、知識の蒸留は教師モデル(teacher model)と生徒モデル(student model)を利用します。教師モデルは精度が高いですが、サイズも計算コストも大きいです。一方、生徒モデルは精度が低いですが、サイズも計算コストも小さいです。モデルの実用化のため、サイズが軽く、計算コストも低く、精度が高いのが望ましいです。そのため、知識の蒸留は、教師モデルの知識を学んで、生徒モデルに活かします。また、モデルが軽くなるだけではなくて、沢山の教師から、知識を学ぶことで、精度向上面も考えられます。
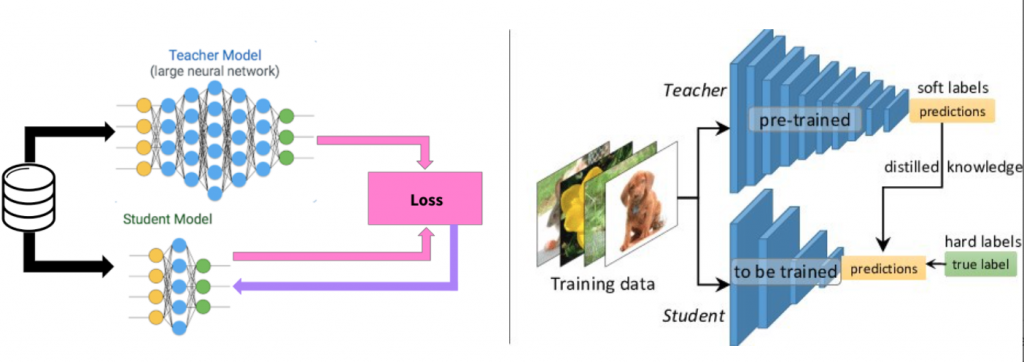 参考:https://towardsdatascience.com/knowledge-distillation-simplified-dd4973dbc764
参考:https://towardsdatascience.com/knowledge-distillation-simplified-dd4973dbc764それでは、どうやって教師モデルから、生徒モデルに知識を蒸留するのかを説明します。主なポイントは二つあります。
- Softmax with temperature
- ニューラルネットワークといった機械学習モデルの表現力を増やすため、活性化関数が利用されます。よく使われている関数の一つはsoftmax関数です。softmax(正規化指数関数、Normalised exponential function)は複数の出力の合計が1.0(100%)になるように変換し、出力値を確率分布(probability distribution, qi)の範囲で、0.0-1.0の値を返します。知識の蒸留は教師と生徒の出力に、Logits(確率をマッピングする関数で、softmax関数に通る前のニューラルネットワークの出力レイヤーのzi関数の値)をsoftmax関数に温度パラメータ (T) で割った値を入力します。そうすると、温度の値が高いほど、softmax関数を滑らかにすることが可能になります。高い温度付けsoftmax関数は二つのモデルがどれくらい似ているかを定量的に扱うことができます。結果、教師モデルと生徒モデルを効率よく情報を引き渡しできるようになります。ちなみに、温度を低くすると、高い確率を重視することも可能になります。
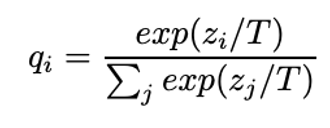
- KL Divergence(Kullback-Leibler Divergence)
- KL Divergenceは教師と生徒の出力の確率分布がどの程度似ているかを表す尺度で、損失として使われます。簡単な数式を書くと、KL Divergence = Cross-Entropy(予測の確率分布:生徒) − Entropy(正解の確率分布:教師)になります。
知識の蒸留は様々な手法が展開されています。最近、adaptive multi-teacher multi-levelも提案されました。単純に、教師から生徒へ知識を蒸留するのではなく、何段階かの知識を複数の教師から生徒に蒸留します。よって、より高い精度を期待することもできます。
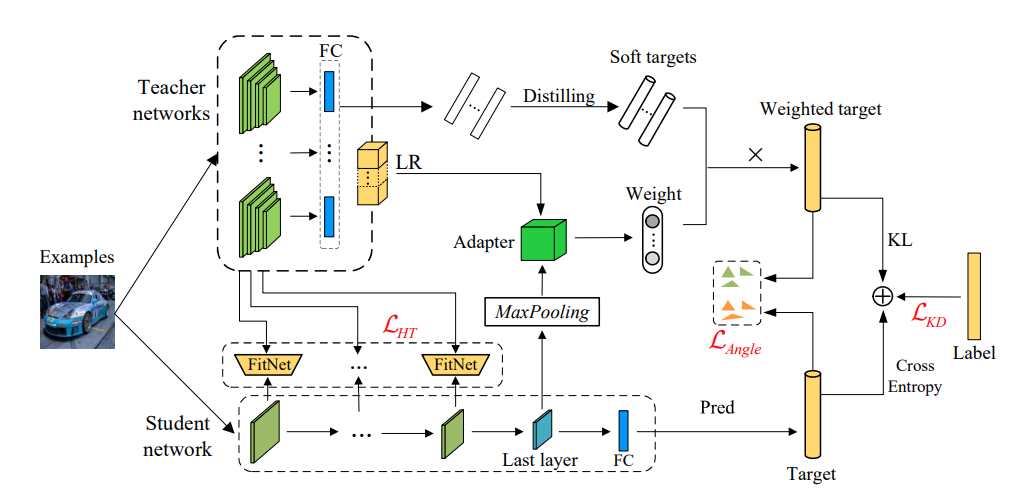 参考:https://arxiv.org/pdf/2103.04062.pdf
参考:https://arxiv.org/pdf/2103.04062.pdfまた、今回、関係があるCTR予測も使われています。ただ、この論文はユーザー情報も利用しました。今回のブログはこの論文と似たような手法で、自然言語処理のみで試してみたいと思います。
4. 実装
いよいよ、実装です。
やりたいことは知識の蒸留を使って、いくつかのNLPモデルを組み合わせて、モデルを作成し、精度を保つことができるかを試します。まず、標準として、①テキストを分類してみます。そして、今回の課題で、②テキストからCTRを予測できないかをチャレンジしてみます 。詳細のコードはgithubを参考にしてください。
実装環境とデータ
実装環境
GPU環境はGoogle Colaboratoryを利用し、実装はPyTorchベースにしました。また、今回の実装前提になりますが、torchtextはバージョンによって、modulesの内容が大きく変更されています。最初Google Colaboratoryでバージョン0.9.1を使っていましたが、実装の途中で0.10.0なって、コードが動かなかったりしました。一応、もっと古いバージョンはlegacy modulesとしてまだ使えますので、今回はそれを使って検証しました。参考のため、古いバージョンのmigrationのリンクも貼っておきます。
データセット
データセットはMicrosoft社が提供しているニュース推奨のデータを利用しました。データをダウンロードし、今回使いたい部分をJupyter notebookで処理しました。
データ中身の確認
それでは、データがどのようなものなのかを軽く探索してみます。ニュース関連情報は主なファイルが二つあり、ニュース(news)と挙動(behaviors)です。newsはID、category(分類)、title(タイトル)などの情報が含まれます。挙動はuser_id, time(時間)、history(以前にクリックしたニュース)、impressions(ユーザーが広告を見た情報:その中に、クリックあり=1、クリックなし=0)です。

データ選択
データの中身にはクッキーのような情報も入っていますが、それを使わないように処理しました。利用したのはtitleとimpressions(又はcategory)だけです。また、categoryやclickは使いやすくするために、少しフォーマットを加工しました。データ処理の詳細コードはgithubにあります。
処理したデータの中、categoryごとにどれくらいクリックされるかを可視化してみました。下記の図によると、一番クリック率が高いkids categoryでも1%以下しかクリックしてくれませんね。
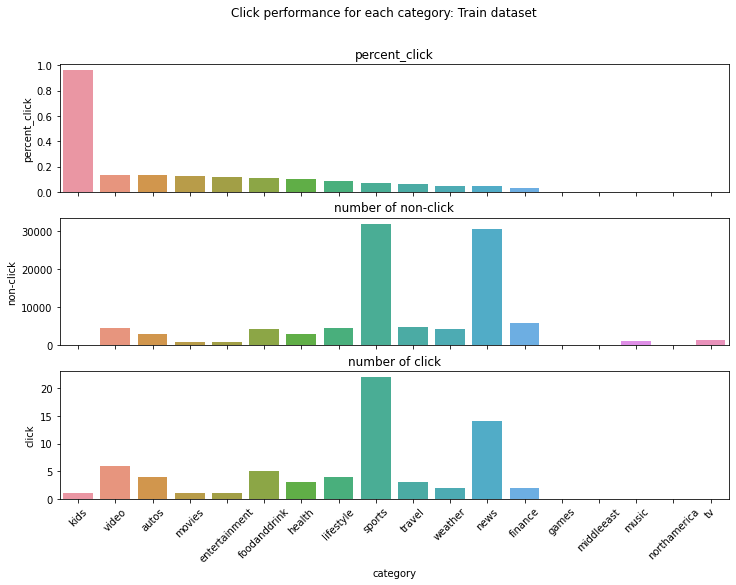
今回の実験の学習データでは、クリックの有無と同じようにデータフォーマットを作成したいので、この中から、二つの種類だけを選択しました。かつ、データサイズは片寄りが欲しいので、比較的データ量が少ないmovies(815件、クリック率 0.1227)とデータ量が多いsports(32,020件、クリック率 0.0687)を利用しました。
それでは、選んだデータをもう少し詳細に見てみます。そのため、少しテキストを処理しました。句読点や括弧などを除外し、テキストの長さや単語数を集計しました。下記の結果によると、平均的には、テキストの長さは62、単語数は10で、最大でも、長さは238、単語数は39でした。
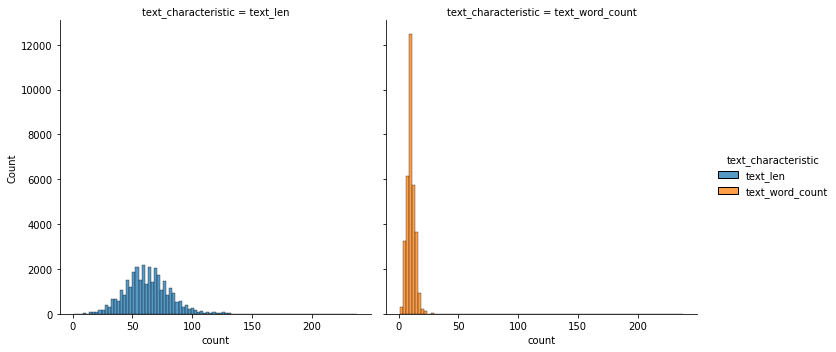
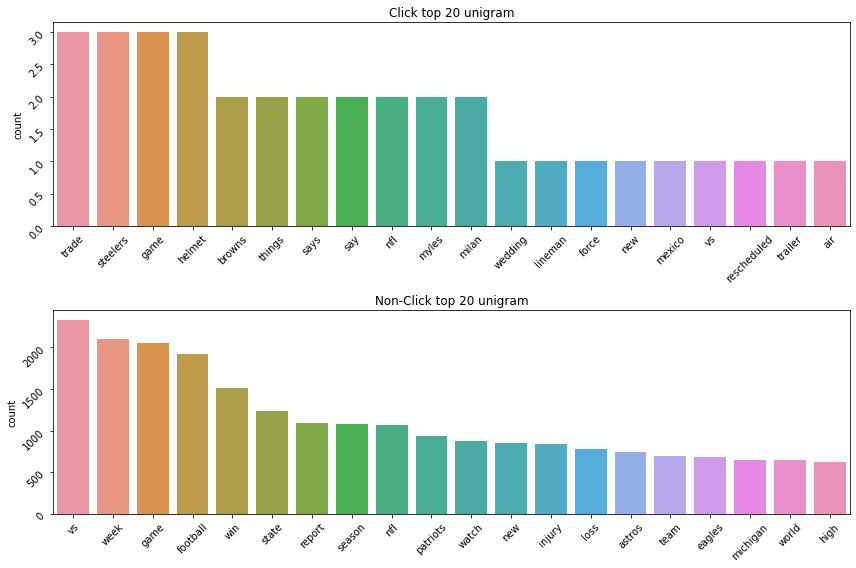
また、どんな単語が多かったのか、クリックされる時の特別な単語があるのか、少し確認したかったので、クリック有り無しの単語回数を可視化してみました。結果を見ると、「この単語だったら、クリックするぞ」のような強い特徴量はなかったような気がします。にもかかわらず、個人的な直感では、一般的な単語はクリックされずに、驚くや特別な単語はクリックされているような気がします。例えば、footballはクリックなし、nflはクリックありの方でした。また、gameはどちらの方にも入っていましたが、vsやweekはクリックなしで、tradeやsteelersはクリックありでした。なので、単語の選び方によって、クリック率を上げることを少し期待しています。また、ニュースのデータセットの特徴かもしれませんが、あまり感情的な単語が出ていない気がします。これは、ディスプレイ広告と少し違うと感じています。
モデル
学習済みモデル3つとKnowledge Distillation(KD)モデルを試してみました。
学習済みモデル
学習済みモデルはGloVe、LSTM、DistilBERTを試しました。tokenizerはbasic_english, spacy, distilbert-base-uncasedを使いました。それぞれのモデルに利用したパラメータは感覚的に設定し、チューニングはしていません。ですので、結果は参考程度でお願いします。ちょっと適当ですみません。
Knowledge Distillation (KD)モデル
Knowledge Distillation (KD)モデルについて、生徒は小さいモデル(GloVe)を使用し、教師はLSTMとDistilBERTを利用しました。
上記に説明したように、温度付きsoftmaxとKL divergenceの使い方は下記のようなコードになります。
def distillation_loss(out_student, labels, logits_teachers, temp, alpha=0.7):
distil_loss = nn.KLDivLoss()(F.log_softmax(out_student/temp), logits_teachers) * (
temp*temp * 2.0 * alpha) + F.cross_entropy(out_student, labels) * (1. - alpha)
return distil_loss
また、学習は下記の感じです。詳細はgithubにあります。細かく言うと、今回の学習は学習(train)しながら、検証(validation)し、validationで一番いい精度を選ぶやり方ではなく、学習データをまるごと使って、最後の学習回数(epoch)のパラメータをモデルにしました。個人的には、loss値が安定的に、下がってくれれば、わざと細かいところで選ばなくてもいいかなと思います。
def train_multi_teachers_kd(st_model, teacher_models, device, train_iter, num_epochs=10, model_path="/", model_name="kd"):
temp = 20.0
lr = 0.01
optimizer = optim.Adam(st_model.parameters(), lr=lr)
optimizer_sgd = optim.SGD(st_model.parameters(), lr=lr, momentum=0.9, weight_decay=5e-4)
lr_scheduler = optim.lr_scheduler.MultiStepLR(optimizer_sgd, milestones=[100, 150])
start = time.time()
for epoch in range(num_epochs):
lr_scheduler.step()
# switch to train mode
st_model = st_model.to(device)
st_model.train()
all_loss = 0
for i, batch in enumerate(train_iter):
target = batch.label.to(device)
target = torch.tensor(target, dtype=torch.long)
input = batch.text[0].to(device)
input_lengths = batch.text[1].to(device)
# compute student outputs
output = st_model(input, input_lengths)
# print("st_output", output)
te_scores_list = []
for j, te in enumerate(teacher_models):
te.to(device)
te.eval()
with torch.no_grad():
t_output = te(input, input_lengths)
t_output = t_output.float()
t_output = F.softmax(t_output/temp) # softmax with temperature
te_scores_list.append(t_output)
te_scores_Tensor = torch.stack(te_scores_list, dim=1)
mean_logits = avg_logits(te_scores_Tensor)
kd_loss = 0
st_model.zero_grad() # optimizer_sgd.zero_grad() # st_model.zero_grad()
# compute gradient and do SGD step
kd_loss = distillation_loss(output, target, mean_logits, temp=temp, alpha=0.7)
batch_loss = kd_loss
batch_loss.backward(retain_graph=True)
optimizer_sgd.step()
output = output.float()
batch_loss = batch_loss.float()
all_loss += batch_loss.item()
print("epoch: ", epoch, "\t" , "loss: ", all_loss)
end = time.time()
print ("time : ", end - start)
# save model
model_filename = model_path + model_name + ".pth"
torch.save(st_model.state_dict(), model_filename)
# release GPU memory
torch.cuda.empty_cache()
return st_model, device
検証結果
結論から言うと、カテゴリ分類は予想通り、分類することができていますが、CTR予測には厳しかったです。
今回のデータは不均等のため、検証の判断はROC AUC scoreを利用しました。Accuracyを使うと、99.9%以上のクリックなしの結果ばかりが揃って、ほぼ100%に近い値が出てしまって、クリックありの正しさを正しく判断できなくなります。/p>
カテゴリ分類の結果
学習済みモデルが優秀で、世の中にも沢山出ている結果と似たように、カテゴリ分類することができました。実装してみた知識の蒸留モデルも問題なく、分類できました。
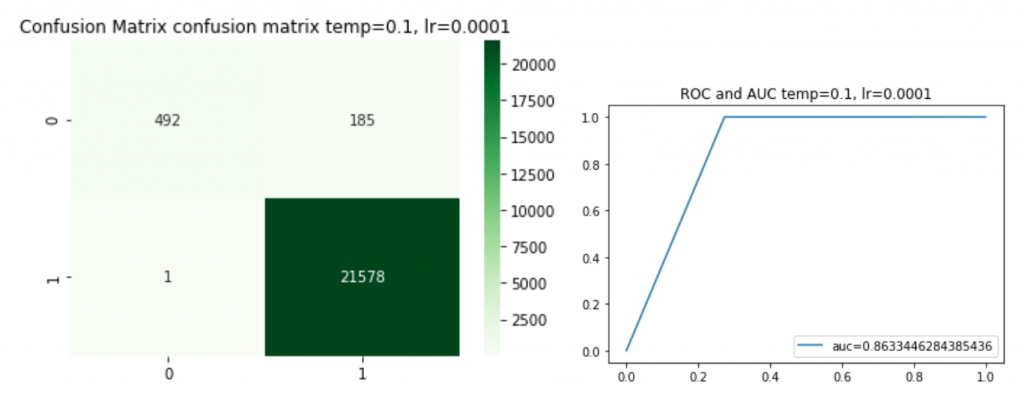
KDの場合はいくつかの温度(T)も試してみました。そのため、学習のlearning rate(lr) も調整しました。モデルKDはlr=0.01, モデルKD2はlr=0.0001です。今回の結果では、温度を下げることで、精度が良くなってきました。

また、実装してみたKD2(T=0.1)の予測結果はどんな感じなのか、confusion matrixも確認しました。
CTR予測の結果
今回のクリック予測については、結果は見せられないほどの失敗でした。学習ROC AUC scoreはどのモデルでも100%に近く、テストは50%になり、overfittingでした。今後の課題のため、なぜ、こんなことが起こったのかを軽く確認してみました。
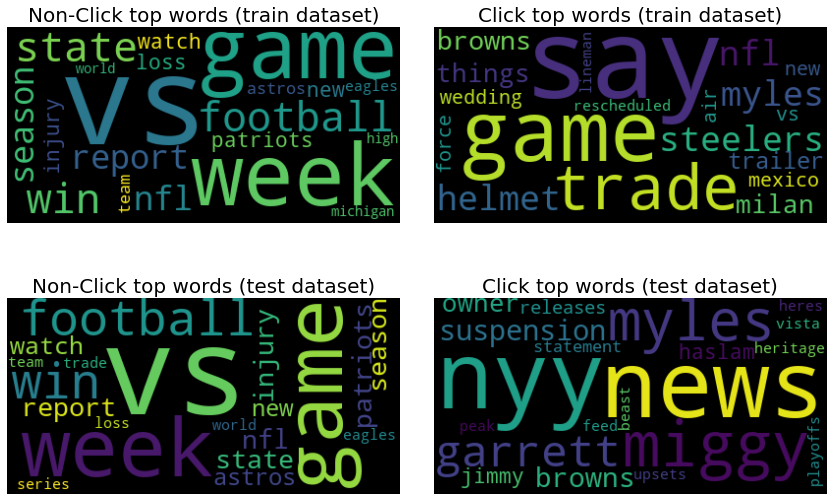
学習とテストのデータセット(クリックの有無の記事)に多く入っている単語のWord Cloudの結果です。左はクリックされなかった、右はクリックされたものです。上は学習データセット、下は予測したいテストデータセットです。予想内なのですが、学習とテストセットの中に、クリックされた文章に入っている単語はなかなか被っていません。学習のときに、tradeやhelmetやsteelersがクリックされましたが、テストのときに、これらの単語が出ていませんでした。一方、テストデータから、クリックありで学習されていない単語(garrettやmiggyやsuspension)が出て、機械がそれらの特別単語として把握することができませんでした。これは、よりクリック予測精度を高めるため、特別な特徴量を作らないと厳しいのではないかと思います。
5. まとめと考察
今回はNLPと知識の蒸留を勉強しながら、実装してみました。テキスト分類は問題なく、予測できましたが、テキスト情報のみを用いてのクリック予測は厳しかったです。しかし、単語の使い方は特徴量としてのきっかけになったので、どうにか今後に活かせないかと考えてみたいです。
最後に
次世代システム研究室では、ビッグデータ解析プラットホームの設計・開発を行うアーキテクトとデータサイエンティストを募集しています。興味を持って頂ける方がいらっしゃいましたら、ぜひ 募集職種一覧からご応募をお願いします。
一緒に勉強しながら楽しく働きたい方のご応募をお待ちしております。
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD