2021.07.05
NFT関連技術 − IPFSのデータストアにAmazon S3を使う
こんにちは。F.S.です。
今回は2021年初から市場を賑わしているNFT(Non-Fungible Token)と関連の強い技術であるIPFSのトピックとして、データストアにAmazon S3を使う方法を紹介します。
1.結論
コンテンツデータをAmazon S3にストアするIPFSノードを立てるポイントは下記の通りとなります。
- 公式のプラグイン go-ds-s3 を使う
- go-ipfs本体にプラグインを組み込んでビルドするのが確実
- コンテンツのブロックデータを格納する領域のみS3を使うように設定する
概ね go-ds-s3 のREADMEにある手順の通り実施することで動作します。
2.IPFSの概要
IPFS(Interplanetary File System)はP2P型のハイパーメディアプロトコルで、非中央集権的な分散ファイルシステムです。
2-1.特徴
IPFSのデータを取り出すには、次の例のようにコンテンツデータのハッシュを指定してデータを取得します。
ipfs://ipfs/QmT78zSuBmuS4z925WZfrqQ1qHaJ56DQaTfyMUF7F8ff5o
※IPFSプロトコル(ipfs://)は通常のWebブラウザでは利用できず、第三者が提供するHTTPゲートウェイを通じてWebブラウザからアクセスすることができます。
データの内容が同じであれば、いつ誰が追加したデータでも同じハッシュになります。
HTTPと比較して考えるとその特徴がわかりやすいです。
- HTTP
- クライアントサーバ(中央集権型)
- ロケーション指向
- URLから特定のサーバにアクセスしてデータを問い合わせる
- その場所にホストされているデータは変更可能
- IPFS
- P2P(自律分散型)
- コンテンツ指向
- コンテンツハッシュを使ってネットワークにデータを問い合わせる(どこで誰がデータを持っているかを気にすることはない)
- そのハッシュでアクセスするデータは常に同じもの(変更不可能)
2-2.NFTとの親和性
NFTはブロックチェーン上のユニークなトークンです。デジタルコンテンツをNFT化するという表現が使われたりしますが、コンテンツの権利をトークンで表すことで、ブロックチェーン上でその権利を取引することができるようになります。
この際、トークンはブロックチェーンに記録されますが、そのトークンに紐づくコンテンツデータはブロックチェーンに記録されません。ブロックチェーンに記録するのはトークンに紐づくデータへの参照(URL)のみになります。
このデータ参照に中央集権管理のURLの代わりにIPFSを用いる手法が採られるケースが増えています。それには前述の特徴にもある通り、次の理由があると考えられます。
- コンテンツハッシュがURLになるため、トークンに紐づくコンテンツデータが改竄されないことが言える
- 中央の管理者がなくなってもコンテンツはネットワークに残る(ただし、参照頻度が低いデータはネットワークから消える場合がある)
3.IPFS+S3のセットアップ
https://github.com/ipfs/go-ds-s3
こちらにしたがってセットアップします。
3-1.go-ipfsのビルド
プラグインは利用するgo-ipfs本体のビルドと同じgoバージョンでビルドする必要があり、正しくインストールするのが難しい場合があるためgo-ipfsにプラグイン機能を組み込んで一緒にビルドする方法が推奨されています。
※筆者はgoスキルが貧弱なためか、goバージョンを合わせてビルドしたプラグインを設置してもバージョンエラーで怒られて一向にうまくいきませんでした。
本体組み込みビルドはREADME記載の通りでOKです
# We use go modules for everything. > export GO111MODULE=on # Clone go-ipfs. > git clone https://github.com/ipfs/go-ipfs > cd go-ipfs # Pull in the datastore plugin (you can specify a version other than latest if you'd like). > go get github.com/ipfs/go-ds-s3@latest # Add the plugin to the preload list. > echo "s3ds github.com/ipfs/go-ds-s3/plugin 0" >> plugin/loader/preload_list # Rebuild go-ipfs with the plugin > make build # (Optionally) install go-ipfs > make install
go-ipfsをdockerで動かしたい場合は、go-ipfsのDockerfileを編集します。
go-ipfs v0.9.0であれば24行目からのビルド実行箇所にプラグインのプリロードを追加します。
# Build the thing. # Also: fix getting HEAD commit hash via git rev-parse. RUN cd $SRC_DIR \ && mkdir -p .git/objects \ # 以下3行を追加 && export GO111MODULE=on \ && go get github.com/ipfs/go-ds-s3@latest \ && echo "s3ds github.com/ipfs/go-ds-s3/plugin 0" >> plugin/loader/preload_list \ && make build GOTAGS=openssl IPFS_PLUGINS=$IPFS_PLUGINS
3-2.設定ファイルの編集
ipfs init を実施すると、$IPFS_PATH(デフォルトは~/.ipfs)にconfigファイルが生成されます。このconfigを編集してデータストアにS3を使うようにします。
デフォルトではDatastore設定は以下のようになっています。
"Datastore": {
"BloomFilterSize": 0,
"GCPeriod": "1h",
"HashOnRead": false,
"Spec": {
"mounts": [
{
"child": {
"path": "blocks",
"shardFunc": "/repo/flatfs/shard/v1/next-to-last/2",
"sync": true,
"type": "flatfs"
},
"mountpoint": "/blocks",
"prefix": "flatfs.datastore",
"type": "measure"
},
{
"child": {
"compression": "none",
"path": "datastore",
"type": "levelds"
},
"mountpoint": "/",
"prefix": "leveldb.datastore",
"type": "measure"
}
],
"type": "mount"
},
"StorageGCWatermark": 90,
"StorageMax": "10GB"
},
IPFSのコンテンツデータ(256KB毎のブロックに分割されたデータ)はマウントポイント /blocks に格納されます。デフォルトではOSのファイルシステム(flatfs)が使われます。
この /blocks マウント設定を次のように差し替えます。バケット名 “ipfs” の “blocks” ディレクトリを使うという例です。
"Spec": {
"mounts": [
{
"child": {
"type": "s3ds"
"region": "ap-northeast-1",
"bucket": "ipfs",
"rootDirectory": "blocks",
"accessKey": "",
"secretKey": "",
"regionEndpoint": "http://127.0.0.1:9000",
"S3ForcePathStyle": true
},
"mountpoint": "/blocks",
"prefix": "s3.datastore",
"type": "measure"
},
上記は実際のS3の代わりにMinIOなどのS3互換プロバイダーをローカルで使用する場合の例で、regionEndpoint, S3ForcePathStyleを追加で設定しています。S3を使う場合はこの二つは不要です。
また、config の他に datastore_spec ファイルがあり、こちらも下記の内容に差し替えが必要です。ipfs起動時に、ここに記載されるデータストアのスペックとconfigの内容が一致するかチェックされるようです。
{"mounts":[{"bucket":"ipfs","mountpoint":"/blocks","region":"ap-northeast-1","rootDirectory":"blocks"},{"mountpoint":"/","path":"datastore","type":"levelds"}],"type":"mount"}
(補足)GCについて
IPFSではノードに残しておきたいデータにはpinをつけて消えないようにする仕組みがあります。ノードでGCを実行すると、pinがないデータは削除対象となります。
daemon起動の際に --enable-gc オプションをつけるとGCの定期実行が有効になりますが、Datastore設定のGCに関するもの(GCPeriod, StorageGCWatermark, StorageMax)はその場合のみに使用されます。GCを手動実行する場合はこれらの設定値は全く参照されません。
3-3.実行確認
CLIで適当な動画ファイルを追加してみます
% ipfs add IMG_3049.m4v added QmWD5fKtkxsyZGuwmuckt4jrrHMkn8m143BmTER1paKc8Z IMG_3049.m4v 13.45 MiB / 13.45 MiB [===========================================================================================================================================================================] 100.00%
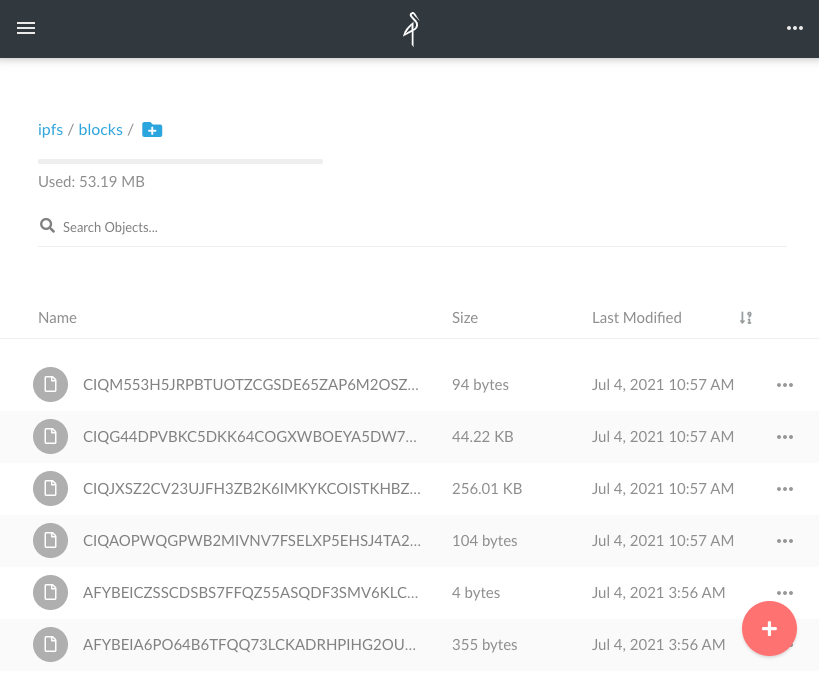
ローカルのMinIO Browserでバケットを見てみると、ブロックデータが格納されているのがわかります。
外部のHTTPゲートウェイ(ipfs.io)経由でIPFSネットワークから追加したコンテンツを参照してみます。
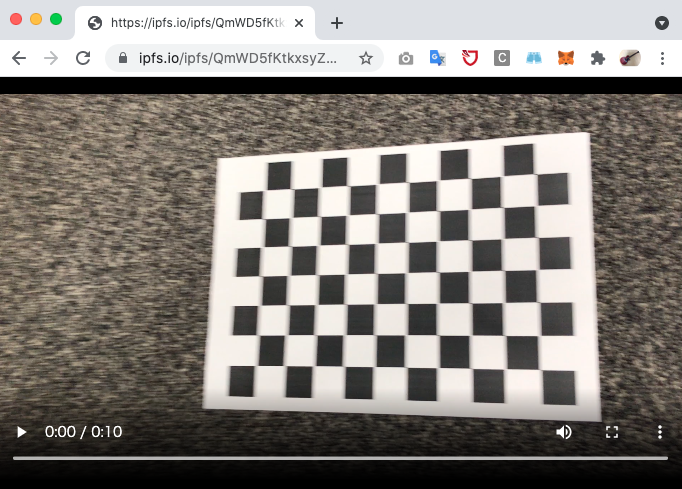
無事にネットワークにコンテンツが伝播することが確認できました。
4.最後に
今回の検証でIPFSのコンテンツデータストレージにAmazon S3(相当のストレージ)を使用することができることがわかりました。
クラウドを利用している場合はコンテンツデータは大抵S3のようなオブジェクトストレージに格納するのが一般的かと思います。S3に格納したデータをIPFSにも追加するというようなケースがあると思いますが、IPFSのデータ形式(ブロックデータ)でS3にデータを格納し、IPFSプロトコルでも、HTTPプロトコルでも取り出せるように(HTTPゲートウェイを通して)するという方法を検討しても良いかもしれません。
それでは、また。
次世代システム研究室では、アプリケーション開発や設計を行うアーキテクトを募集しています。アプリケーション開発者の方、次世代システム研究室にご興味を持って頂ける方がいらっしゃいましたら、ぜひ 募集職種一覧 からご応募をお願いします。
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD