2021.10.03
クッキーのないネット広告世界に向き合いたい:固有表現抽出と知識グラフ編
こんにちは。次世代システム研究室のK.S.(女性、外国人)です。
今回(2021Q3)は前回の「クッキーレス(cookieless)時代のインターネット広告に向き合いたい:知識の蒸留による自然言語処理編」で気になった課題(見たことない単語や特別な単語の予測)を理解しようとする話です。
前回はインターネット広告のクッキーレス課題を紹介し、知識の蒸留などの技術で自然言語処理に基づいてユーザーのクリック率を予測をしてみましたが、テキスト情報のみを用いてのクリック予測は厳しいという結果でした。そして、探索的データ解析(Exploratory Data Analysis, EDA)の結果によると、その原因の一つは単語の選び方です。学習モデルにはクリックされた単語や文章を学習させましたが、学習データセットでクリックされた単語がテストデータセットには現れないことがあったのです。かつ、クリックされた単語は特別な単語のように見えたので、それはどのような単語なのか、クリックに影響があるかどうかを今回のブログで確認したいと思います。
というわけで、今回は直接のクリック予測ではなく、原点に戻って、単語でより多くの特徴量(情報)をどれくらい作成できるかを検証したいと思います。技術的には固有表現抽出(Named Entity Recognition; NER)と知識グラフ(Knowledge Graph)の周りを紹介します。
インターネット広告(クッキーレスやCTRなど)の詳細説明については前回のブログを参考にしてください。
1. 固有表現抽出(Named Entity Recognition; NER)とは
固有表現(Named Entity)は人名、地名、組職名といった固有名詞や、日付、時間などに関する表現です。固有表現抽出(Named Entity Recognition; NER)は、固有表現をテキストから抜き出す自然言語処理技術の一つです。
NERはどういう感じなのかを例を出して説明します。例えば、この「Pochama went to Ooyama.」の文章では、NERは①この文章の中にある固有表現を検出し、PochamaとOoyamaを抜き出します。それから、②それらの固有表現を分類し、「Pochama」は人名で、「Ooyama」は地名と抽出します。そうすることで、文章に入っている固有表現はどんな単語なのかがわかるようになります。
NERのための有名な open-source librariesは NLTK, SpaCy, Stanford NERです。
簡単に、NERで、この「Apple employees eat apple and Apple at Apple」文章を分類してみます。Appleは会社名でもあり、果物という意味でもあります。NLTKを使った分類結果は下記になります。左から、順番にみてみると、最初のAppleはちゃんと固有表現として検出されましたが、場所(GPE)として、認識されます。次は、簡単で小文字appleは名詞(NN)として検出できました。三つ目のAppleは人の固有表現として検出。おそらく、andの後についている最初の文字が大文字なので、人名と思われたのでしょう。最後はきちんと会社名の固有表現として特定できました。atの後にあるのが強いのではないかと思います。この文章は難しいところもありますが、ある程度、分類できているようです。

一般的なやり方を紹介しましたが、深層学習のBERTなどを利用することも可能です。簡単に、同じ文章でtransformersモデルを試してみました。結果は微妙に違います。bert -base-NERモデルですと、最初の文字が大文字になっているAppleは会社名(B-ORG)として特定されました。

今回は、クリックされた固有表現(エンティティ)が次にクリックされる単語に関連があるかどうかを見てみたいです。
2. 知識グラフ(Knowledge Graph)とは
知識グラフ(Knowledge graph)は様々な知識をグラフにまとめて可視化するものです。知識グラフは三つの要素「①データベース(Resource Description Framework; RDF)、②グラフ、③知識ベース」で構成されます。①を利用し構造化クエリでデータを探索し、②でネットワークを可視化します。そうすると、③でデータを解釈し、新しく事実を推測することが可能です。
まず、①データベース(Resource Description Framework; RDF)を説明します。RDFはWWW上でメタデータ「データに関する付帯情報(タイトル、著者、Webページの更新日など)」を表現するための言語です。階層構造で記述するテキストファイルというイメージで、固有表現(entity、エンティティ)、属性(Attribute)、リレーションシップ(Relationship)で構成されます。エンティティは上記に説明した固有表現抽出(NER)の対象です。属性はエンティティの詳細です。例えば、エンティティが人の場合、属性は名前や年齢などになります。リレーションシップはエンティティを繋ぐ関係性です。
次に、②グラフはRDFに保存されているエンティティの関係をネットワークグラフで表見するものです。例えば、RDFからのエンティティの人名はポッチャマとマナフィがあり、地名は大山と石垣島があります。その中に、ポッチャマと大山の関係性があり、マナフィと石垣島の関係性があります。なので、下記のようなグラフを可視化することができます。用語では、ポッチャマと大山はnodeで、関係性の線をedgeと言います。また、nodeの種類はポッチャマから大山に繋ぐので、ポッチャマはsource、大山はtargetと言います。
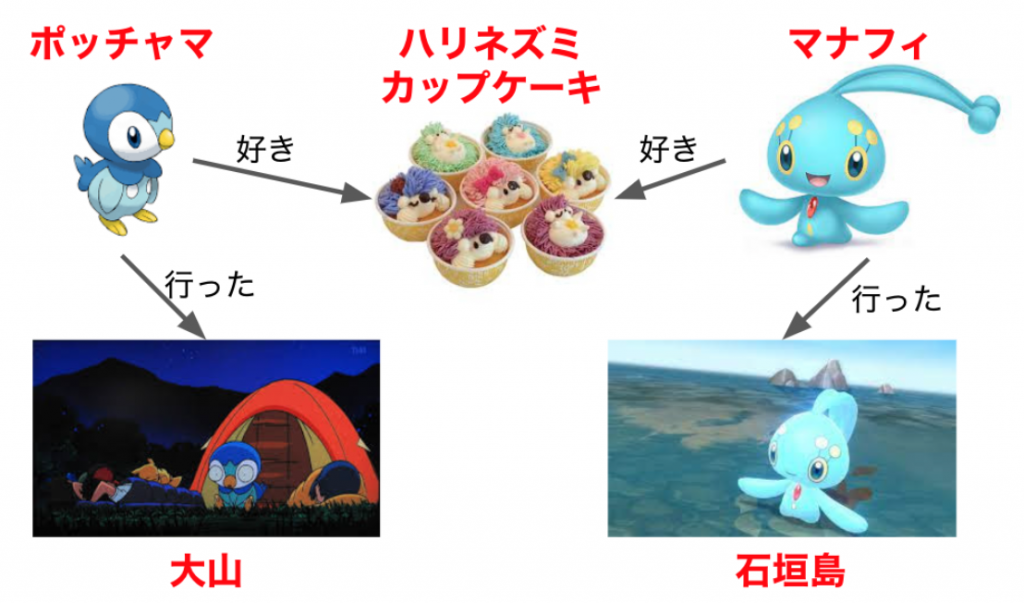
最後に、③知識ベースは上記のグラフの知識を解釈することです。ポッチャマと大山のエンティティは人名と地名で、グラフによるこの二つの関係性があることもわかります。そうすると、ポッチャマは大山に行ったことがあると知識ベースで推測することできます。また、ハリネズミカップケーキは食べ物ですので、ポッチャマはハリネズミカップケーキに「行った」ではなくて、「食べた」ことがあるや「好き」ということが推測可能です。
今回はニュースの記事から、このようなエンティティや知識の関係で、クリックに影響があるかどうかを見てみたいと思います。
3. 実装
いよいよ、実装です。
やりたいことは二つで、①クリックされたカテゴリに順番があるかを可視化してみることと、②クリックされた文章からエンティティを抽出し、知識グラフを可視化してみることです。
3.1. 実装環境とデータ処理
実装環境
GPU環境はGoogle Colaboratoryを利用ました。
データセット
データセットはMicrosoft社が提供しているニュース推奨のデータを利用しました。データをダウンロードし、今回使いたい部分を処理しました。データの中身や利用部分については前のブログを参考にしてください。
データ処理
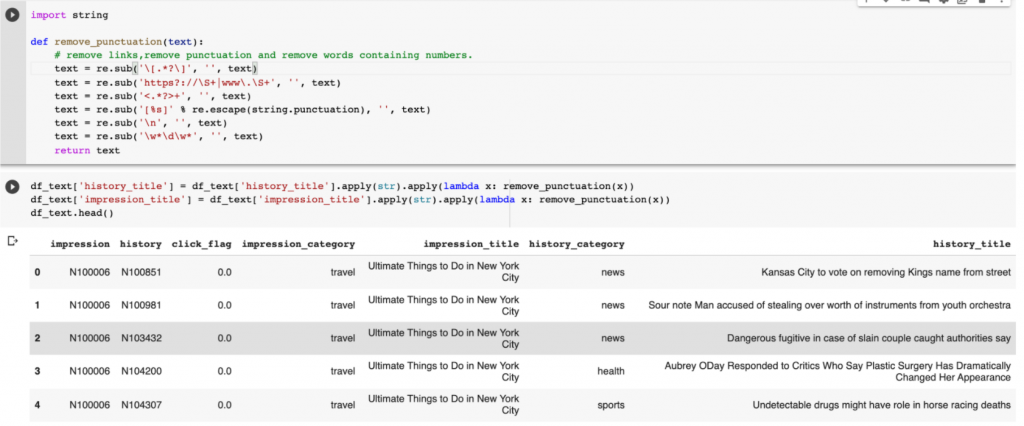
データはニュース関連情報で主なファイルが二つあり、ニュース(news)と行動(behaviors)です。newsはID、category(分類)、title(タイトル)などの情報が含まれます。行動はuser_id, time(時間)、history(以前にクリックしたニュース)、impressions(ユーザーが広告を見た印象:その中に、クリックあり=1、クリックなし=0)です。その二つのファイルから、今回欲しい情報を整理し、テキストも少し綺麗にしました。処理したデータフレームは下記のようになります。impressionとhistoryのclick_flag、category、titleを一行ずつ、表示しました。また、データ量が多かったため、今回は、50ユーザーの履歴に制限しました。
3.2. クリックのカテゴリに順番があるかを見てみたい
ここでは、クリックのカテゴリを知識グラフで可視化し、クリックの順番があるかどうかをみてみます。期待としては、もしカテゴリに順番があれば、推奨の特徴量で役に立つように組み合わせたいです。
検証は、処理されたデータフレームを使って、sourceとtargetとedgeを設定します。事前にクリックした記事のカテゴリー(history_category)から、次のカテゴリーを見たときに(impression_category)、どんなカテゴリーであれば、クリックするだろうと判断できるかを知識グラフとして可視化します。設定は下記のイメージです。
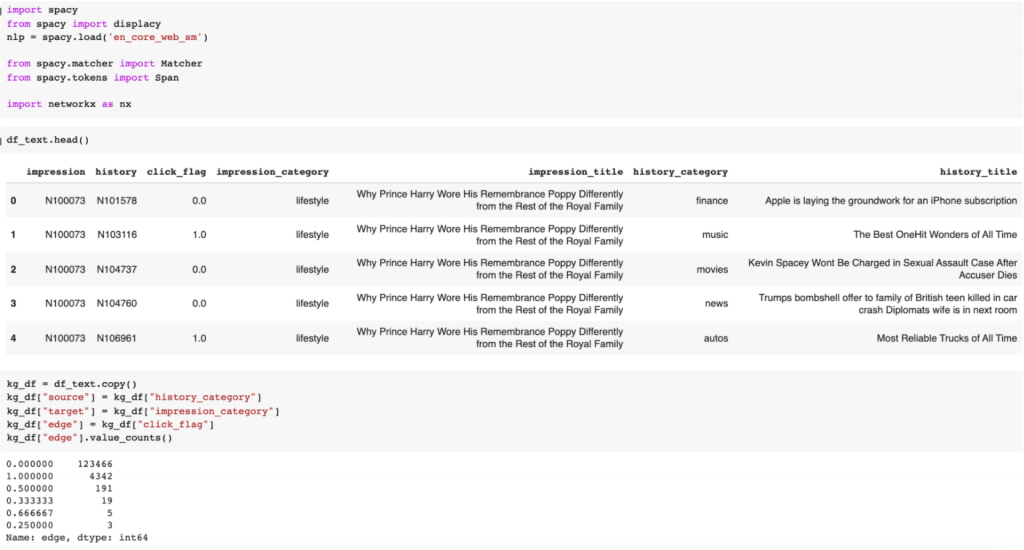
次に、カテゴリー情報から、知識グラフを作成します。実装は下記のようなコードになります。
def create_direct_graph(kg_df):
edge_list = [1.0, 0.0]
title_list = ["click", "non-click"]
fig = plt.figure(figsize=(20,10))
for i in range(2):
ax = plt.subplot(1,2,i+1)
df_plot = kg_df[kg_df['edge']==edge_list[i]].head(10000)
G=nx.from_pandas_edgelist(df_plot, "source", "target",
edge_attr=True, create_using=nx.MultiDiGraph())
pos = nx.spring_layout(G)
nx.draw(G, with_labels=True, node_color='skyblue',
edge_cmap=plt.cm.Blues, pos = pos, arrowsize=10,
node_size=3000)
title = title_list[i]
plt.title(title, fontsize=16)
plt.suptitle("Category relationship for click and non-click cases", fontsize=20)
plt.show()
return
結果は下記で、左はクリックあり、右はクリックなしの知識グラフです。少し見にくいですが、目立つのは「weather」だと思います。他のカテゴリーを見た後に、天気の記事をクリックしたようですが、天気を見た後は他の記事をクリックしなかったようです。今回、データを絞って実験したため、集計したデータに過剰適合(overfitting)した可能性が高いですが、個人的には納得感もあります。よく考えたら、私自身もニュースを読んで、最後に明日の天気はどうかなあとクリックしたりしています。

3.3. クリックされた単語の関連性を見てみたい
ここでは、クリックされた文章からエンティティを抽出し、知識グラフの可視化で、単語の関連性はどのような感じなのかを見てみます。
エンティティ抽出
処理したデータフレームから、impression_titleとhistory_titleから、エンティティを抽出しました。実装は下記のようなコードになります。
def identify_entities_and_label_words(df_texts, id="impression", title="impression_title"):
category = id + "_category"
df_texts = df_texts[[id, title, category, "click_flag"]].groupby([id, title, category]).mean().reset_index()
df_list = []
for lines, sentence in enumerate(df_texts[title]):
# tokenize words and get entities
token = nltk.word_tokenize(sentence)
token_tag = nltk.pos_tag(token)
entities_flag_list = []
chunk_list = []
for chunk in nltk.ne_chunk(token_tag):
if hasattr(chunk, 'label'):
entities_flag = 1
chunk_flag_list = []
for i in range(len(chunk)):
chunk_flag_list.append(chunk[i][0])
chunk_flag = ' '.join(chunk_flag_list)
else:
entities_flag = 0
chunk_flag = chunk[0]
chunk_list.append(chunk_flag)
entities_flag_list.append(entities_flag)
# get labels ID
labels = []
for item in chunk_list:
labels.append(df_texts[id][lines])
# combine data to df
df_labels = pd.DataFrame(labels, columns=[id]).reset_index()
df_entities = pd.DataFrame(zip(chunk_list, entities_flag_list), columns=["chunk_list", "entities_flag"]).reset_index()
df_labels.set_index("index", inplace=True)
df_entities.set_index("index", inplace=True)
df_combine = df_labels.join(df_entities, how='left')
df_list.append( df_combine )
df_select_words = pd.concat(df_list, ignore_index=True)
# select only entities
df_select_words = df_select_words[df_select_words["entities_flag"]==1.0]
return df_select_words
コード通り、エンティティとして、検出されない単語は抜くことにしました。結果は下記のようなイメージです。ニュースの文章は単語の最初の文字は大文字が多く、たまにエンティティとして検出されてしまいます。上記のAppleの例と似たような問題がまだ残っていますが、そのまま使います。
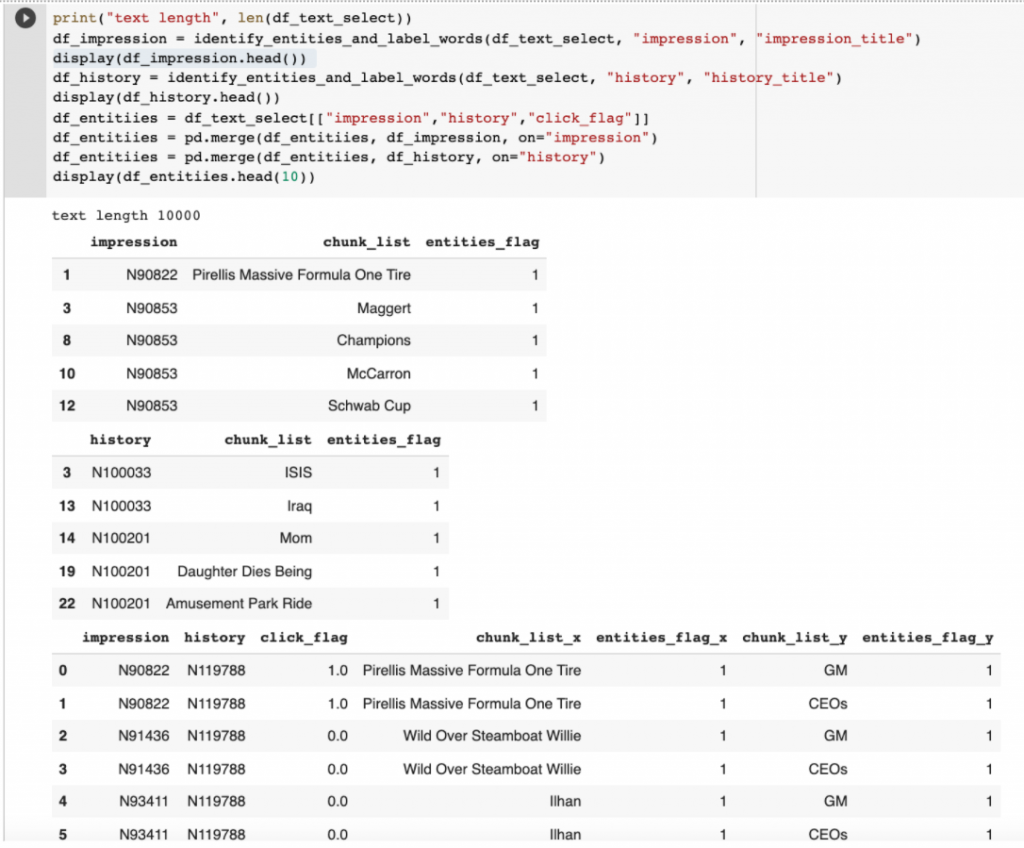
知識グラフ
まず、エンティティーを処理したデータフレームを使って、sourceとtargetとedgeを設定します。事前にクリックした記事に入っているエンティティー(chunk_list_x)から、次の記事のエンティティーを見たときに(chunk_list_y)、どんな単語だったら、クリックするだろうとわかるのかを知識グラフで可視化します。設定は下記のイメージです。
実装は下記のようなコードになります。単語の量が多かったため、少し絞ってプロットしました。
def create_direct_graph_select_word(kg_df, word=""):
kg_df = kg_df[(kg_df["source"]==word) | (kg_df["target"]==word)]
edge_list = [1.0, 0.0]
title_list = ["click", "non-click"]
fig = plt.figure(figsize=(20,10))
for i in range(2):
ax = plt.subplot(1,2,i+1)
df_plot = kg_df[kg_df['edge']==edge_list[i]].head(20)
G=nx.from_pandas_edgelist(df_plot, "source", "target",
edge_attr=True, create_using=nx.MultiDiGraph())
pos = nx.spring_layout(G)
nx.draw(G, with_labels=True, node_color='skyblue',
edge_cmap=plt.cm.Blues, pos = pos, arrowsize=10,
node_size=3000)
title = title_list[i]
plt.title(title, fontsize=16)
main_title = "Entities relationship for click and non-click cases: {}".format(word)
plt.suptitle(main_title, fontsize=20)
plt.show()
return
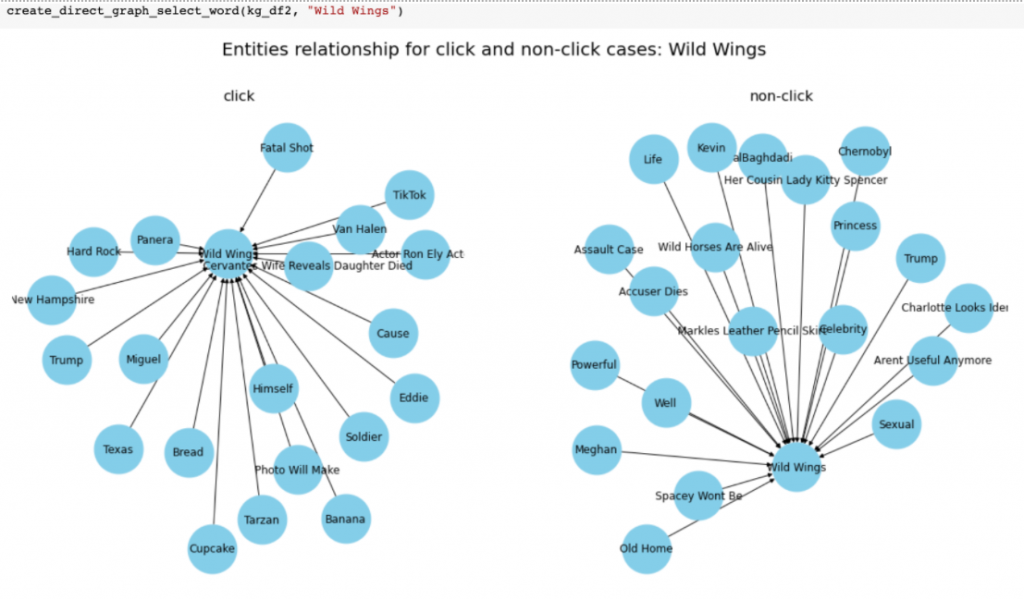
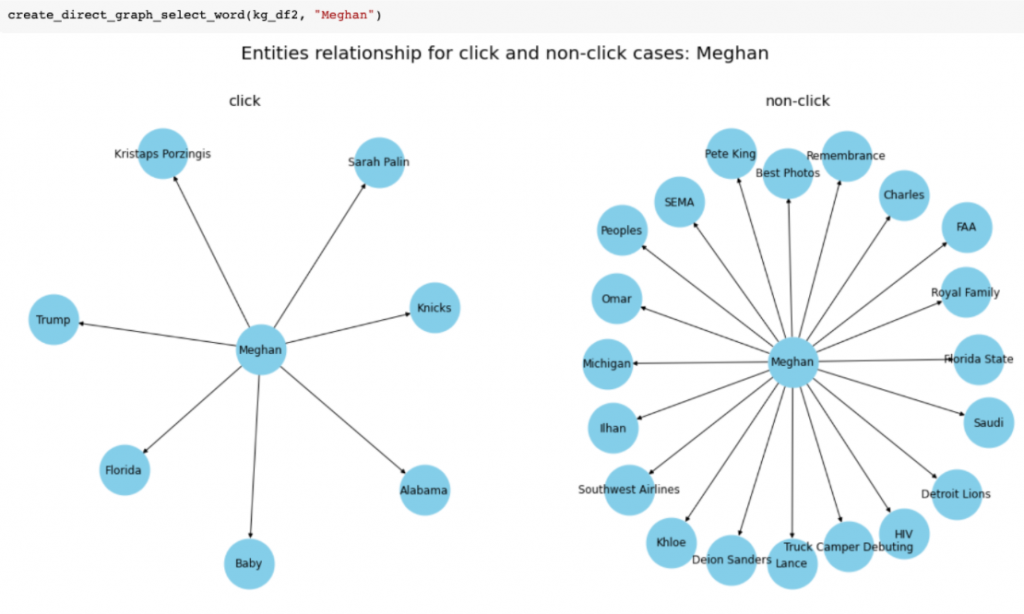
結果は二つのエンティティ(Wild WingsとMeghan)をプロットしてみました。左はクリックあり、右はクリックなしです。
では、Wild Wings(アメリカのファミレス)の結果を軽く解釈してみましょう。クリックされた記事の中に、BananaやBreadと行った食べ物がある記事をクリック後にはWild Wingsがクリックされたり、Hard Rockといったレストランのクリック後にも、クリックされました。関連がある単語の繋がりがありそうなことがわかります。ただ、Trumpクリック後にもクリックされたので、解釈しにくい部分も発生しました。一方、クリックされない記事の中にある単語をみてみると、どの単語でもWild Wingsに関係がなさそうです。なので、個人的にはうまく、関連のエンティティを学習できれば、より推奨特徴量を作れるのではないかとふと思いました。
もう一つのMeghanの結果を軽く解釈してみます。Meghanのクリック後に、「Baby, Trump, Sarah Palin, Kristaps Porzingis」がクリックされましたが、「Michigan, Saudi」のような地名は出てもクリックされませんでした。これはどういう関係なのか一目でわかりにくいですが、単純な解釈ですと、人に興味があって、様々な有名人をクリックしたりしたのでしょうか。女性はこういう傾向がありますよね。人間の考えで、どうやってうまく特徴量を作成できるかはまだ課題です。
4. まとめと考察
今回はエンティティと知識グラフを紹介しました。クッキーレスに直接繋がるアウトプットではありませんが、少しヒントをもらった気がします。クリックされたカテゴリに順番の傾向が少し見られたり、クリックされたエンティティの関連性も少し見られました。単語の使い方は役に立つ可能性が出てきましたが、実用的になるにはもっと深く検証が必要だと思います。
最後に
次世代システム研究室では、ビッグデータ解析プラットホームの設計・開発を行うアーキテクトとデータサイエンティストを募集しています。興味を持って頂ける方がいらっしゃいましたら、ぜひ 募集職種一覧からご応募をお願いします。
一緒に勉強しながら楽しく働きたい方のご応募をお待ちしております。
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD





