2022.10.11
ニュースデータからOpen Information Extraction(OpenIE)で情報抽出し、知識グラフを構築してみた
はじめに
こんにちは、グループ研究開発本部 AI研究開発室のC.Wです。2022年はニュースデータからの知識グラフ構築に心臓を捧げています。
前回と前々回の記事で、ニュースデータからCoreference Resolution + Named Entity Recognition(NER) + Relation Extraction(RE)等のNLP技術を利用して、非構造テキストから知識グラフを構築することを試しました。しかし、原因の詳細は後述しますが、REでニュースデータを処理+知識グラフ構築のアウトプットのクオリティには制限があるのに気づいたので、今日はNER+REのアプローチではなく、Open Information Extractionのアプローチで知識グラフ構築を試しました。
NER+REの懸念
これまではNamed Entity Recognition(NER)+ Relation Extraction(RE)の一元モデルで非構造のテキストデータを構造化のEntity + Relationにしてきましたが、アウトプットのクオリティがなかなか知識までに至るようにはならなかったです。推論になるが、以下の2点の原因が大きく影響しているかと思っている。
1、教師あり学習の実応用問題
「Benchmarkでは高得点をしたが実応用ではうまくいかなかった」、機械学習を応用しようとする時にほぼ必ず遭遇したことのあるお馴染みの問題です。NLP領域では学習データの準備は非常に大変で、直近の論文でも数年前のデータセットをBenchmarkとして学習している傾向があります。その数年前のデータセットでは設計された当初の時期で正確にパフォーマンスを測るため、難易度が比較的低いデータとなり、NLPで行くと簡単な語句がメインで、語句の長さが短いのが特徴です。一般的な解決法は事前学習のモデルを意図的に作った課題向けのデータセットでfine tuningをしてこの問題の克服をしていますが、データセットを作ること自体は非常にtime consumingの作業です。
これまでのNER+REでは論文と同じのBenchmarkデータセットを使って学習したモデルを、いきなりBloombergレベルの英語が不得意でなければ読むこともハードルがあるような文章を入力したので、いいアウトプットは正直あまり期待していなかったが、ここまで解釈性が低かったのは予想外でした。かつ、一般的に別データセットを作ってfine tuningをするが、そのリソースが自分にはないためこの道は不可能でした。
2、学習データのRelationの制限
これはRelation ExtractionやObject Detectionのようなオープンな課題を解決するモデル特有の問題です。教師あり手法で学習するため、何かしらのラベル付けが必須ですが、「何をどれまでラベルをつけたらいいか」の判断により出てくる違うデータセットのバイアスです。例えばNamed Entity RecognitionやObject Detectionでは、どの単語/物をどうラベル付けするかで解像度とかが異なりアウトプットに影響を施します。その一方で、Relation ExtractionはもしN個単語があるとするとNの二乗の関係性が存在していて、その関係性が2単語だけで説明できるとも限らなく、非常にラベル付けがしにくいタスクでもあります。
その前提があるので、REのデータセットは現状データセットごとに独自の関係性を表示するようにラベル付けをしていて、それが意図的に汎用性の高いように設定されて解像度がイマイチ感がある。例えばWebNLGとかはTripletの形式で、単純に3個の単語(か語句)が関係しているを示していて、ACE04とかはORG_AFFとかで違うEntityの関係を示している。この研究の話に戻ると、知識グラフ構築のタスクでは、そういう制限を前提にしてしまうと曖昧な関係のみが見えていて知識というレベルに落とせないことになりうる。
チャレンジ
NER+REの懸念を踏まえ、課題解決により近い方法があるかと色々探りましたが、今回は以下のアプローチで試してみたいと思います。
- 短めのデータを利用
「教師あり学習の実応用問題」の対応となりますが、とりあえず一歩引いて使うデータを学習に使ったデータセットに合わせることにした。 - Open Information Extractionを使う
「学習データのRelationの制限」の対応です。結論から言うと動詞(Verb)を対象として情報抽出していることが多いので、データを知識にする命題には向いているかと思ってます。詳細はこれから説明します。
Open Information Extraction(OpenIE)とは
Open Information ExtractionはRelation Extractionと非常に似た課題です。一言で違いを説明すると、OpenIEは語句に叙述されている単語の全ての関係性を語句内の単語で表示したい課題で、REは語句に入っている名詞の関係性を所定のカテゴリーで判断したい課題だと思っています。なのでOpenIEはOpenの名通り提示されている情報以上のものは判断しなく、Relation Extractionはモデルに基づいた推測が入るとの違いとなります。

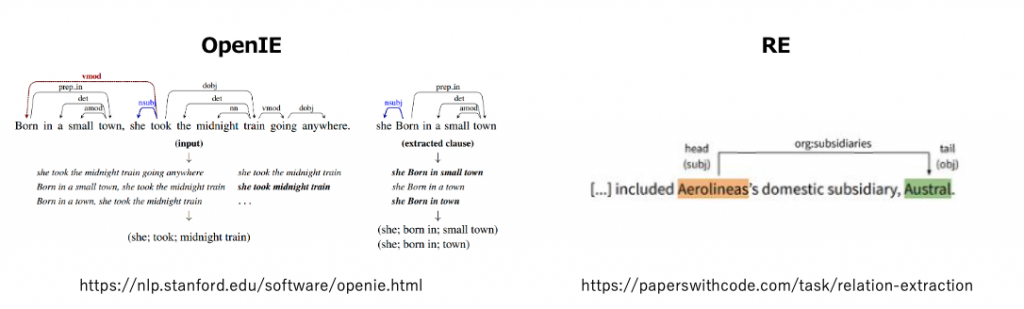
同じNLPの似たようで違う課題ですが、OpenIEが機械学習が流行る前からの古の課題であり、REの方がBenchmarkデータセットが充実した今時の課題と個人的に感じています。歴史的な経緯ついて深堀するつもりはありませんが、OpenIEでのモデルが比較的少ないのと、Benchmarkデータセットも少なくドキュメントが整備されていないので、今回はMLaaSのAllenNLPのサービスを利用して試してみます。
AllenNLP
AllenNLPは AI2(Allen Institute for AI)が提供しているNLP系のMLaaSで、気軽に色んなNLPタスクを試せるいいプラットフォームです。こちらのurl: https://demo.allennlp.org/ から色々デモで試すことができて、pythonのライブラリも使いやすく整備されています。ただ、非常に残念ながらこのブログを執筆している間に今年の12月までにサービス停止をするとのニュースが出たので、興味のある方は早めにお試しください。
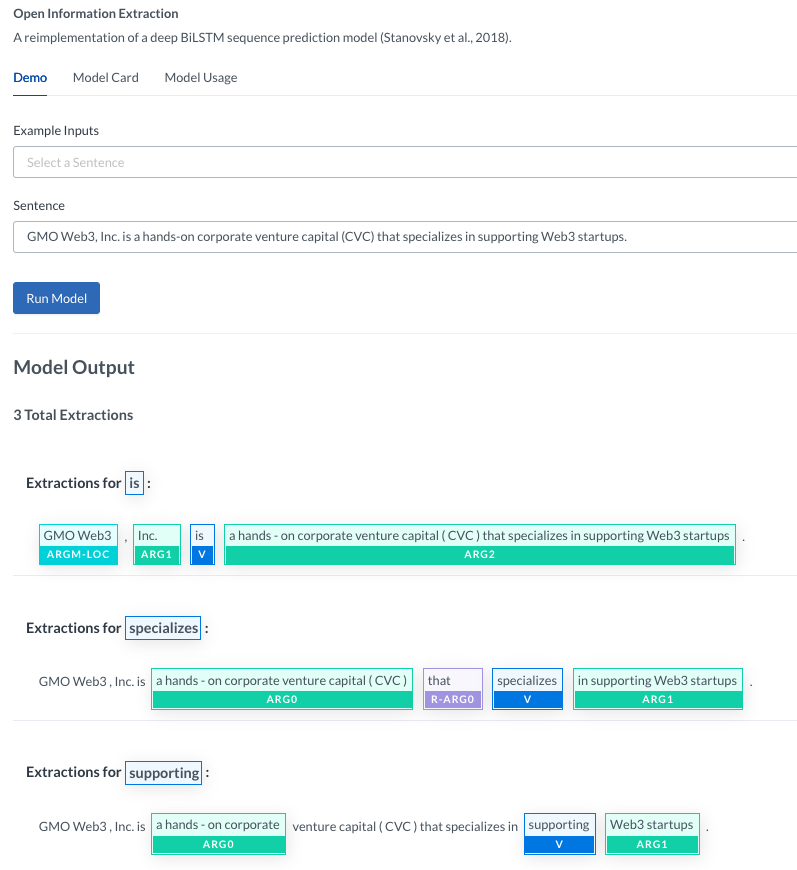
(例)OpenIEを下記のように軽くデモできます:
データ
短めのデータを利用した方が効果が良いのではないかと言う視点でデータを考え直しました。これまではNewsAPIからデータの取得をしていて、デフォルトで記事のスニペットしか取得できず今まではクローラーで全文を取得しているのですが、全文を短文で学習したモデルに放り投げていることが問題だと思いました。そこから短文に切り離そうとしても、記事の中の有意義な語句でも前後依存することが多く、区切りがしにくい問題があります。そこで調査をしたのですが、経済ドメイン特化のMarketauxというサービスが見つかりました。
Marketauxは同じくAPIでニュースデータの取得ができるサービスですが、Marketauxでは経済/ファイナンス系に特化していて、上場の銘柄コードを対象に検索することができます。レスポンス内には同じくスニペット表示になっていますが、銘柄コードを指定するとこの記事がこの銘柄と関わると思う判断の語句もリターンしてくれます。なので知識グラフに使われるEntuity(銘柄コード)とその近隣の関係(判断の語句)が含まれているので、知識グラフ構築の課題に使いやすいのではないかと思い試してみました。NewsAPIと同じくDailyの無料枠があり、さらにsentiment scoreなどの情報量も含まれていることから経済系のNLP分析には持ってこいではないかと思うのでおすすめです。
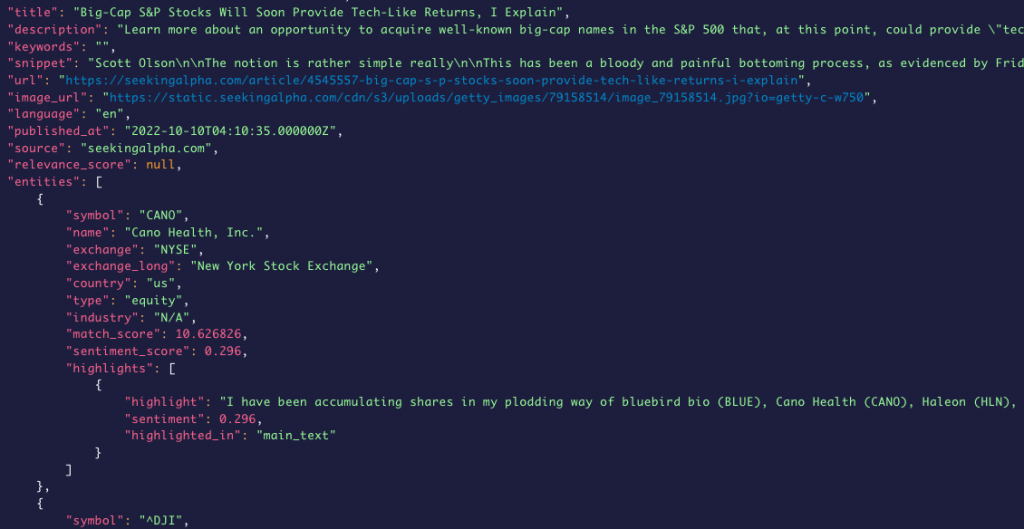
直近のイベントに合わせてイベント前後で何か傾向が見れるかを調査したいので、取得データもイベントベースで取得しました。具体的には、電気自動車のテスラ(NASDAQ: TSLA)の3Qの出荷台数が予想を下回るニュースについて、ニュース発表の前後での知識グラフでは違いがあるかを調査してみたいです。故に、以下のパラメータを使ってデータを取得しています。
url = 'https://api.marketaux.com/v1/news/all'
symbol = 'TSLA'
search = 'deliver | delivery | logisitcs | shipment | logistical'
filter_entities = 'true'
params_before_event = {
'symbols':symbol
,'search':search
,'filter_entities':filter_entities
,'published_before':'2022-10-02T12:00:00'
,'published_after':'2022-07-03T12:00:00'
,'api_token':api_token
}
params_after_event = {
'symbols':symbol
,'search':search
,'filter_entities':filter_entities
,'published_before':'2022-10-09T12:00:00'
,'published_after':'2022-10-02T12:00:00'
,'api_token':api_token
}
実践
API取得データ整理
今回は短文に集中するため、取得されたデータの記事ごとの情報はあまり使わなく、APIレスポンスのentitiesのhighlightごとのデータの取得をする。
print(data[0]) # 取得した生データ例
"""
{'uuid': '9bdd18cc-feb6-46e6-b325-a6b3805308c0',
'title': 'Former Tesla CFO joins drone delivery startup Zipline',
'description': "Former Tesla CFO Deepak Ahuja will join Zipline's leadership team and act as the company's CBO and CFO.",
'keywords': 'Internet, Enterprise, Technology, Tesla Inc, business news',
'snippet': 'Deepak Ahuja, Tesla CFO (left) and Elon Musk, Tesla founder and CEO (right), at the Nasdaq opening bell ceremony for the Tesla initial public offering on Tuesda...',
'url': 'https://www.cnbc.com/2022/09/09/former-tesla-cfo-joins-drone-delivery-startup-zipline.html',
'image_url': 'https://image.cnbcfm.com/api/v1/image/105174943-1662753477576-deep.jpg?v=1662753501&w=1920&h=1080',
'language': 'en',
'published_at': '2022-09-09T20:41:04.000000Z',
'source': 'cnbc.com',
'relevance_score': 22.002392,
'entities': [{'symbol': 'TSLA',
'name': 'Tesla, Inc.',
'exchange': 'NASDAQ',
'exchange_long': 'NASDAQ Stock Exchange',
'country': 'us',
'type': 'equity',
'industry': 'Consumer Cyclical',
'match_score': 30.232136,
'sentiment_score': 0.239167,
'highlights': [{'highlight': "Deepak Ahuja, <em>Tesla</em> CFO (left) and Elon Musk, <em>Tesla</em> founder and CEO (right), at the Nasdaq opening bell ceremony for the <em>Tesla</em> initial public offering on Tuesday, June 29, 2010.\n\nFormer <em>Tesla</em> CFO Deepak Ahuja will join Zipline's leadership team as the company's chief business officer and CFO, Zipline announced Friday.",
'sentiment': 0.296,
'highlighted_in': 'main_text'},
{'highlight': 'Ahuja served as the CFO of <em>Tesla</em> from March 2017 to March 2019, but he first joined the company in 2008. He was with <em>Tesla</em> when it went public in 2010 and briefly left in the company 2015.\n\nAhuja will join Zipline on Sept. 30.',
'sentiment': 0.4215,
'highlighted_in': 'main_text'},
{'highlight': 'Former <em>Tesla</em> CFO joins drone delivery startup Zipline',
'sentiment': 0,
'highlighted_in': 'title'}]}],
'similar': []}
"""
highlighter = pd.DataFrame([(x['published_at'], x['uuid'], y['highlight'],y['sentiment']) for x in data for y in x['entities'][0]['highlights']])\
.assign(timestamp = lambda x: pd.to_datetime(x[0]))\
.assign(uuid = lambda x: x[1])\
.assign(highlight = lambda x: x[2].str.replace('</em>','').str.replace('<em>','').str.replace('\n',' '))\
.assign(sentiment_score = lambda x: x[3])\
.assign(week = lambda x: x['timestamp'].dt.strftime('%YW%W'))\
.assign(ymd = lambda x: x['timestamp'].dt.strftime('%Y%m%d'))\
.assign(event = lambda x: (x['timestamp'] > '2022-10-02T12:00:00').apply(lambda y: 'after' if y else 'before'))\
.drop(columns=[0,1,2,3])

それをベースに、AllenNLPのopenIEモデルで出力を下記のように処理して行くと、ひとまずは短文→Open Informationとの変換ができます。
from allennlp.predictors.predictor import Predictor
import allennlp_models.tagging
def openie_inference(res):
words = res['words']
inferences = []
for v in res['verbs']:
inference = {}
for t,w in zip(v['tags'], words):
if t=='O': continue
t = t.split('-')[1]
if t in inference.keys():
inference[t] += f' {w}'
else:
inference[t] = w
inferences.append(inference)
return inferences
predictor = Predictor.from_path("https://storage.googleapis.com/allennlp-public-models/openie-model.2020.03.26.tar.gz")
ie = []
for _,r in tqdm(highlighter.iterrows(), total=highlighter.shape[0]):
res = predictor.predict(r['highlight'])
info = openie_inference(res)
ie += [x|{'ymd':r['ymd'], 'sentiment_score':r['sentiment_score']} for x in info]
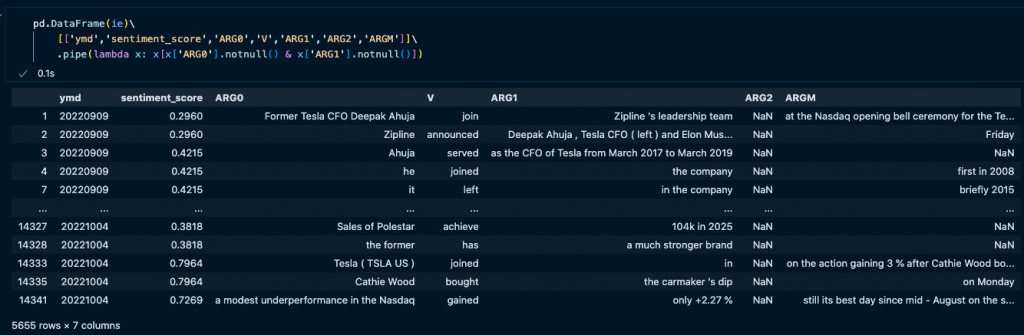
見るからにノイズらしきものが大量に入っていますが、ひとまずは初歩的な探索としてこのまま ARG0 – V – ARG1でグラフ作成を試します。
結果
同じくneo4jに落とし込み可視化を見てみました。ざっくりな同じく何か見えそうな状況になっています。nodeの群もうまくいくつかに分かれています。さらに関係性の視点から見ると、node間の関係性が動詞に定義されて、表現力は以前より豊富になっていると感じられます。ただ、細かくnodeを除くと単語ならぬ語句が大量に入っていて、解釈性がNER+REの結果より劣ることが見られている。
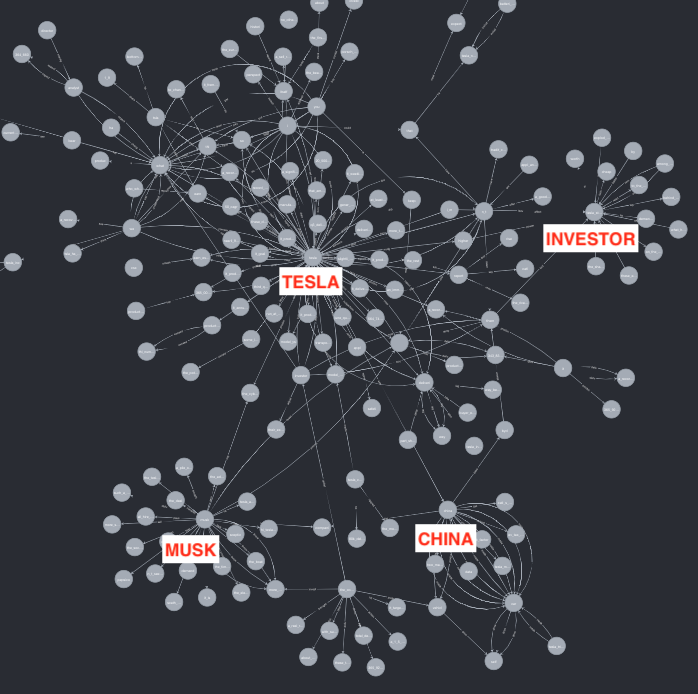
そこで、TSLAの出荷台数が予想を下回るニュース発表の前後の知識グラフを比較してみた。以下の通りニュース発表後では”Delivery”と関係のnodeの中には予想下回りや不足等な情報が捉えています。ただ残念ながら、そのような単語をニュース発表前で捉えることはできなく、直接何かしらのニュースから情報を捉えることは難しそうなタスクでした。

しかしこれ以上の解析を進めるには、やはりnode等の前処理が必要になってきます。特にOpenIEではアウトプットが単語に限らず、語句が基本でnode(ARG)として扱われているので、neo4jのグラフに落とし込んでもCypherクエリでどうこうして解析はしづらいと感じています。解釈性をよくするには、人工知能ではなく地味に作業する工人知能の方が必要ではないのかとも思っていますが、もう少し自動化で情報抽出できるかこれからもっと試してみたいと思います。
まとめ
今回はOpenIEを利用してテキストデータから知識グラフ構築の再現をしました。OpenIEの利用で関係性不足問題を少し解決できたと感じていますが、有意義な知識グラフまでにはやはり道は遠いと改めて感じています。nodeの表示情報を処理するとさらに情報が出てくるのではないかとも感じるので、これからも深めていきたいです!
最後に
グループ研究開発本部 AI研究開発室では、データサイエンティスト/機械学習エンジニアを募集しています。ビッグデータの解析業務などAI研究開発室にご興味を持って頂ける方がいらっしゃいましたら、ぜひ 募集職種一覧 からご応募をお願いします。皆さんのご応募をお待ちしています。
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD