「結局、顧客分析って何?」DSから見た顧客分析
ご覧頂きありがとうございます。グループ研究開発本部 AI 研究開発室の N.M.と申します。
データサイエンティストとしてさまざまなデータに囲まれている中で、どのサービスに対しても共通して存在するものとして「顧客」があります。やはりサービスをよくしていくためにはこの「顧客」を分析して、どのようなキャンペーン施策をうつのがいいか、どのような機能を開発するべきかなど、さまざまな観点からインサイトを得ることが重要だと思います。
しかしながらこの「顧客分析」という単語は、キャッチーなフレーズなだけあって非常に便利に使われており、「顧客分析をしたい」というとても抽象的なワードに対して具体的にはどのようなプロセスを経るべきか、どのようにデータサイエンスと結びつければ良いのかということに関しては情報が錯綜しており、結局「サービスによって顧客分析は異なるため、一概には言えない」と結論づけられてしまいます。(もちろんその通りではあるのですが…)
今回のブログでは、顧客分析とはどういうものと考えるべきなのか、顧客を分析するということはなぜ必要であって、データサイエンティストとしてどのようなアプローチを取って課題を解決することができるのかについて、データ解析を仕事をし始めてからおおよそ 1 年ほどというひよっこデータサイエンティストなりに考えていきたいと思います。
TL;DR
- データサイエンティストにとっての顧客分析は顧客の属性・行動・感情の 3 種類の情報を整理して数字に落とし込んで観測し、施策へ還元できる顧客に関する仮説・インサイトを得ること(とする)
- データサイエンティストが得意とする統計・機械学習による定量的なアプローチに定性的な知見をロジックで繋げ合わせることで意思決定をサポートすることが目的であり目標
- ChatGPT を始めとした LLM 応用分野のめざましい進歩により、顧客の感情データからより深いインサイトを得られるようになるかもしれない(今後に期待)
目次
顧客分析とは?
かなり大きなセクションのタイトルですが、ここではデータサイエンティストにおける顧客分析とは何なのかを整理していきます。結論、以下のように考えています。顧客分析 = 顧客の属性・行動・感情の 3 種類の情報を整理して数字に落とし込んで観測し、顧客に関する仮説・洞見を得て施策へ還元すること
顧客の属性データは、その顧客の持つ情報のうち、顧客ごとに特有の情報を数値や文字列、あるいはカテゴリカルな値に変換したものをイメージしています。最もわかりやすい属性データとして性別・住所・職業などの個人情報が上げられ、特定顧客に対してアクションをとることの他にも、共通の属性を持つ顧客をグループとして扱って、例外の生まれやすい個人のような一顧客でもなく、情報が抜け落ちる顧客全体でもない、分析しやすい粒度の顧客群を作ることもできます。
顧客の行動データは、属性に対してサービスを通してアクションを起こしたイベントの時系列データをイメージしています。例えば、「ある顧客が 2 月 2 日の夜に、スーパーで豆を購入した」という記録や、「漫画アプリで流れていた 99%の人がクリアできないゲームの広告動画からアプリをインストールした」などの記録になります。これらのデータは「購入」や「登録」といったサービスに対して何かしらの重要なアクション(コンバージョン)が生じたかどうかを確認するための重要なものであり、また、この顧客は過去に何回アクションを起こしたか、今月も継続してサービスを利用したかといったように集計して属性データにすることも可能です。
そして顧客の感情データは、行動に表れない or 表れづらい、かつデータの定量化の難しい、サービスに対する様々な情報をイメージしています。属性データのように扱いやすくもなく、行動データのように重要なアクションが関わるものでもありませんが、より深く顧客を知るためには、顕在化している情報だけではなく裏側に隠れているサービスに対するイメージや印象をマイニングすることでより深いインサイトが得られることがあります。当然、アンケートをとったりキャンペーンを実施するなどによって分析のしやすい属性データや行動データに落とし込むことが理想ではありますが、SNS を中心としたサービスに対する印象・イメージを集約するといったニーズもあります。
これらのデータによって、過去どのような顧客がどのようにサービスを利用してきたかを定量的に測定し、新たな機能や施策などのサービスの今後の方向性を決める意思決定の手伝いをするための分析が顧客分析ということだと考えています。回帰分析などによって今後の顧客の行動を予測した統計量を出すということは可能ですが、あくまでも過去のデータに基づいたもので、顧客、すなわち人間を相手にする分析のため、外部要因などで顧客の傾向が大きく変わるとも言い切れません。そのため、定量的なデータだけではなくサービス関連のドメイン知識・類似・競合サービスの状況など定性的な知見とをロジックで繋ぎ合わせて意思決定をする、ということが理想の顧客分析になります。
冒頭で「データサイエンティストにおける顧客分析」と前置きした理由としてはここにあります。よく顧客分析と検索するとマーケティング関連のページが出てきますが、ドメイン知識や顧客への直接的なアプローチによるリアクションを初めとした定性的な知見のスペシャリストがマーケターや企画、UX デザイナーといった職だと考えており、この多くの職の方とのコラボレーションによって意思決定をすることが理想と考えられます。データドリブンマーケティングといったキーワードもあるほどマーケターに定量的な視点が重視されている場合もありますが、その定量的な視点をサポートするのがデータサイエンティストではないかと考えています。データサイエンティストにもビジネススキル・ドメイン知識は必須で、それらがなければゴールの見えない分析をしてしまう可能性があると言えますが、マーケター・UX デザイナーのレベルまで理解し、取ってかわることができるかと言われればそんなことはないので、あくまで顧客を定量データに落とし込んだ上でそこから意思決定のサポートをすることがデータサイエンティストにおける「顧客分析」ではないかと思っています。もちろん定量的なデータを見つつ定性的かつクリエイティブな視点を含めた上で施策立案…と全ての工程を踏むことができるスーパーデータサイエンティストが最強ではあります。ぜひ一緒にお仕事をさせていただきたいので、募集職種一覧からのご応募をお待ちしております。
顧客分析の課題と手法の関係性
これも非常に大きなセクションのタイトルで不安になりながら書いていますが、このセクションでは顧客分析の名の下に上記の定義に沿ってどのような課題をどのようにデータ駆動で解決していくかを整理します。本記事では、以下の 4 つをメインで取り扱っていきます。- 顧客を観察する → 指標設計
- 顧客を獲得する → 顧客セグメンテーション/クラスタリング
- 顧客を離脱させない → 生存時間分析
- 顧客の心情を推察する → 感情分析
顧客観察のための指標設計
まず初めに、顧客がどのような挙動をしているのか確認できなければデータを用いての顧客分析はできません。提供しているサービスが何人に使用され、結果としていくら収益を得ているかといった情報を確実に捉えるようにするためには、日々観察する指標を設計してそれを可視化・レポーティングできる環境を整える必要があります。そのため、先ほど述べた必要な属性データや行動データ、感情データが手に入ることを前提として、それらを観測可能な形に集約します。例えば、- MAU(monthly active user, ある月にアクティブだったユーザー)
- ARPU (Average Revenue Per User, 顧客一人あたりの平均収益)
- CPM (Cost Per Mille, 広告 1000 回表示(インプレッション)あたりに発生するコスト)
- …
一つ目は指標の数を増やしすぎないことです。データがあればその分上述のような様々な統計量を作ることはできます。しかしながら、多種多様な指標を作成したとしてもその全てが必ずしも重要とは限りません。
指標を整理する上で、
- KGI(Key Goal Indicator, 売り上げ 10 兆円のような最終目標地点)からツリー状に指標を分解し、KPI(Key Performance Indicator) として追跡する
- OKR(Objective and Key Result)の形式で Objective(1 年以内に新規顧客を現在の 10%増にさせるといった目標) を設定し、結果を計測するための Key Result として評価する
もう一つは定義を確実に決定することです。マーケティング界隈の重要指標として LTV(LifeTime Value, 顧客生涯価値)という指標があります。言葉の意味としては、顧客がサービスを利用し始めてから離脱するまでの間にもたらす利益を示すものですが、例えば、CAC を顧客獲得費用(Customer Acquisition Cost)、\(\rm{M_n}\)を\(\rm{n}\)期のある顧客による粗利益、\(\rm{C_n}\)を\(\rm{n}\)期の該当顧客に対するマーケティングなどによるコスト、\(\rm{p}\)を該当顧客の継続確率、r を割引率として、ある一人の顧客に対する LTV を、
$$ \rm{LTV} = – \rm{CAC} + \sum_n \frac{(M_n – C_n) p^{n}}{(1+r)^n} $$
のように定義する場合があります。また、\(S\)を一回あたりの購買額、\(F\)を購買頻度、\(R\)を継続期間として、単に
$$ \rm{LTV} = \it{S} \cdot \it{F} \cdot \it{R} $$
として定義される場合もあります。これらは双方ともに LTV として定義されていたものですが、当然イコールではありません。ではどちらが正しいのか、というと「顧客生涯価値」という単語からするとどちらも正しいと言わざるを得ないと思います。より正確に値を求めたい場合は上式の方が良いでしょうし、顧客の獲得コストが正確に見積れない場合は下式の計算方法の方が良いでしょうし、後述するセグメントのような顧客を群で考えた場合は単純に平均をとって良いのかなどさらに考慮する要素が増えます。
ここで重要なのは LTV の定義はこうだから…と議論するのではなく、この定義であれば計算・理解・観察しやすいかつ求めているものを充分正確にに表現できているからこれを LTV とする、という考え方をすべきということです。指標の名前だけ独り歩きさせず、しっかりとビジネスサイドとこのように定義するという合意をとった上で進める
この指標設計に関しては、今回挙げている顧客分析の手法において、データサイエンティストのビジネススキルが最も試される課題だと思っています。データサイエンティストにはビジネススキルも強く要求されますが、いかに事業部門の求めるものを、観測可能な形にすり合わせながら良い温度感で設計することができるかが重要視されるため、細かくビジネスサイドの要望をヒアリングしながら進めていく必要があります。
顧客獲得のための顧客セグメンテーション/クラスタリング
サービスを大きくするためには新規顧客の存在が重要です。「新規顧客を獲得する」という観点では未開拓の顧客のうち、収益性の高い顧客を獲得したいというモチベーションがあります。基本的には新規顧客のプロファイルは分かりませんが、既存の顧客の中で収益性の高い顧客の属性や行動がわかれば、そのプロファイルと似通った特徴を持つ顧客にアクションを取ることで収益性の高い新規顧客を獲得することが期待できます。そこで、顧客を属性データにによってセグメントやクラスタに分けることで前述のような指標経由で評価し、ターゲットにしたい顧客を深ぼっていきます。これを顧客セグメンテーション、あるいは顧客クラスタリングと言います。セグメンテーションとクラスタリングの違いに関しては、セグメンテーションには特定の属性情報で分けたグループ、クラスタリングは教師なし学習ベースで複数の属性情報を組み合わせた結果生じたグループというような文脈の違いはあるように感じますが、目的としては同一です。
顧客一人一人を見て分析するとその顧客が特異な存在であった場合に全く顧客全体に対して効果的ではない施策を打ち出してしまったり、逆に顧客全体で一括りにして分析すると重要な情報も平滑化されてしまいインサイトを得ることが難しくなってしまうという特徴がある上で、ある程度の粒度にグループ化することによって特徴を掴むことができるようになり良い分析ができるようになるため、顧客分析における中心的な解析手法になると考えています。
マーケティング系統の顧客分析では、セグメンテーション分析の他に様々なフレームワークが存在します。しかしながら、それらのフレームワークの核になる分析はいづれも「顧客をセグメント/クラスタに分類し、その顧客群における評価指標を見る」ということであり、どう分けるか+分けた後に何を見るかが異なるというものになるので、極論で言うと、〇〇分析は全てセグメンテーション分析に含めてしまっていいくらいの感覚で問題ないと思っています。以下はその例です。
- ABC 分析 / デシル分析
主に連続値の指標(顧客別の売り上げなど)を ABC の三段階(or 10 段階)にセグメント分け - RFM 分析 /RFE 分析
Recency(最新購入日時)、Frequency(直近の購入頻度)、及び Monetary(購入金額) または Engagement(エンゲージメント)の 3 つで顧客層をセグメント分け - 行動トレンド分析 / コホート分析
同じ時期に行動をしている人でセグメント分け(行動トレンド分析は顧客の購入金額が上がるタイミングを起点として分析、コホート分析は同じタイミングであるキャンペーンなどのイベントを体験したことを起点として分析) - CTB 分析
Category(商品のカテゴリ)、Taste(色やデザイン)、Brand(ブランド)の 3 つのセグメントに分割
顧客離脱防止のための生存時間分析
サービスを利用している顧客を 1 ヶ月の粒度で考えたとき、「新しくサービスを利用し始めた顧客」と「前月は利用していなかったが、サービス利用に復帰した顧客」、そして「前月から引き続き利用している顧客」の 3 種類に分けることができます。その月におけるアクティブなユーザーを増やす方法としての方法として新規の顧客をどのように獲得するか、離脱した顧客をどのように復帰してもらうかといった視点は考えられますが、顧客にサービスを継続的に利用して貰えるようにするために、新規の顧客はどの程度増えたか、既存顧客がどの程度サービスを利用しなくなったかなど、現状どの程度サービスに出入りしているのかは重要になります。離脱率の観点では、このサービスに出ていく顧客に着目します。サービスによっては、利用しなくなる際に退会やアカウント停止をする顧客がごく一部になる場合もあり、アカウントは有効ではあるが利用はされていない、いわゆる「休眠状態」にいる顧客がいるということがあります。ここで課題になるのが、顧客がいつ離脱したかを決める閾値です。1 年間サービスを利用しなかったら離脱したとみなすのか、1 日サービスを利用しないだけで離脱したとみなすのか、といった閾値をあまりに的外れな値を閾値にしてしまうと正しく離脱したユーザーをカウントすることができなくなってしまいます。そこで、行動に対してイベントがどのくらいの期間で起こっているのかを分析するために、生存時間分析を行います。
生存時間分析は時系列データを用いてあるイベントが発生するまでの期間を予想する分析で、名前の通り、対象が生物であれば死亡、機械であれば故障といった重大なイベントに対して使用されます。マーケティングではサービスを使わなくなったタイミング、すなわち離脱のタイミングをイベント発生とみなして、離脱が発生するタイミングを予測します。
まず生存時間分析では、イベントが発生するまでの時間\(T\)を用いて、ある時刻\(t\)時点でイベントが発生していないことを表す生存関数は以下のように表されます。
$$ S(t) = Pr(T \geq t) $$
その上で、時刻\(t\)以前にイベントが発生していない場合に、時刻\(t\)にイベントが発生する可能性を示すものであるハザード関数\(h(t)\)を以下のように表します。
$$ h(t) = \lim_x \frac{Pr(t \leq T < t + \Delta t | T \geq t)}{\Delta t} $$
ここで、時刻 t をイベントが発生するを表す関数を\(F(t)\)、その確率密度関数を\(f(t)\)とした時、上の式は以下のように変換できます。
$$ h(t) = \lim_x \frac{F(t + \Delta t) – F(t)}{\Delta t \cdot S(t)} = \frac{f(t)}{S(t)} $$
よって、\(f(t) = -\frac{d}{dt}S(t)\)から、生存関数\(S(t)\)とハザード関数\(h(t)\)の間には以下のような関係があると言えます。
$$ S(t) = exp \biggl( – \int^t_0h(u)du \biggr) $$
このように、ある時刻\(t\)時点でイベントが発生していないことを表す生存関数と、微小時間でイベントが発生する可能性を示すハザード関数との関係が得られます。
このハザード関数に対してどのような仮定を置くかが生存時間分析の手法の違いとなります。ハザード関数が特定の確率分布に従うと仮定した場合をパラメトリックモデル、分布を仮定しないものの、特定の説明変数を用意する場合はセミパラメトリックモデル、分布を仮定せず、説明変数も使用しない場合はパラメトリックモデルとなります。
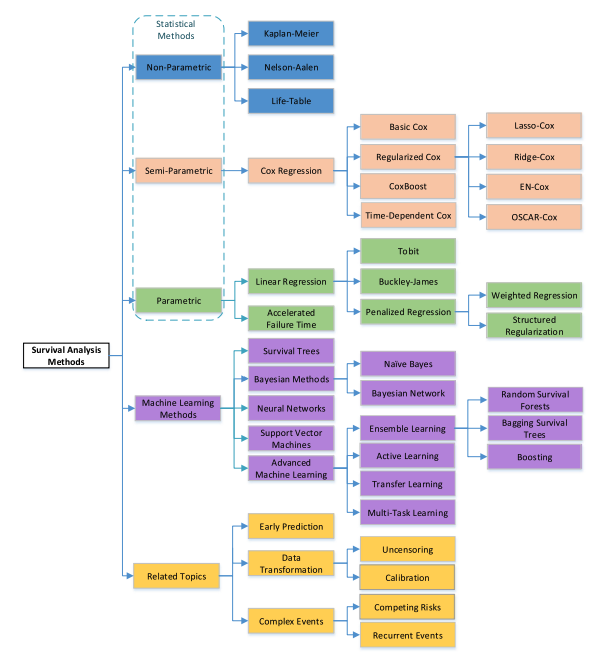
ユースケースによってどの手法をとるかは様々ですが、顧客分析においては、確率分布に依存する形は扱いづらいので、顧客の属性データから「どのような顧客が生存しやすいか」などを考えたい場合はセミパラメトリックモデル、そうでない場合はパラメトリックモデルを利用すると良さそうです。
また、生存時間分析には「打ち切り期間」という概念が存在します。解析する際にどこからどこまでのデータを観測の対象にするのかということを決めなくてはいけません。一般的な用語として、右側打切りが観測終了までにイベントが発生しなかった場合、左側打ち切りが観測開始までにイベントが発生していた場合を指します。この打ち切り期間を「得られるデータの最終日から 3 ヶ月前」などで決め打ちすることによって離脱の閾値が妥当かどうか検討しても良いですし、得られるデータの最後までを対象とした生存関数を plot した後に妥当な打ち切り期間を決めても良いと思います。
顧客理解のための感情分析
ここまでの分析に関しては、回帰分析等を使わないことを前提とすれば実績により数値化された特徴量で記述できていました。しかしながら顧客をより理解するためには、顧客が抱いているものの、顕在化していないサービスに対するイメージや印象を定量化することで、さらに顧客を理解することが期待できます。昔は SNS をはじめとしたインターネット上にあるデータを利用することはデータが大きいかつ単純な集計では人間ですら判断が難しい感情を定量化することは厳しいと考えられていましたが、ビッグデータ解析基盤の進化や自然言語処理技術と機械学習の進歩によって一つの研究分野として確立されてきました。
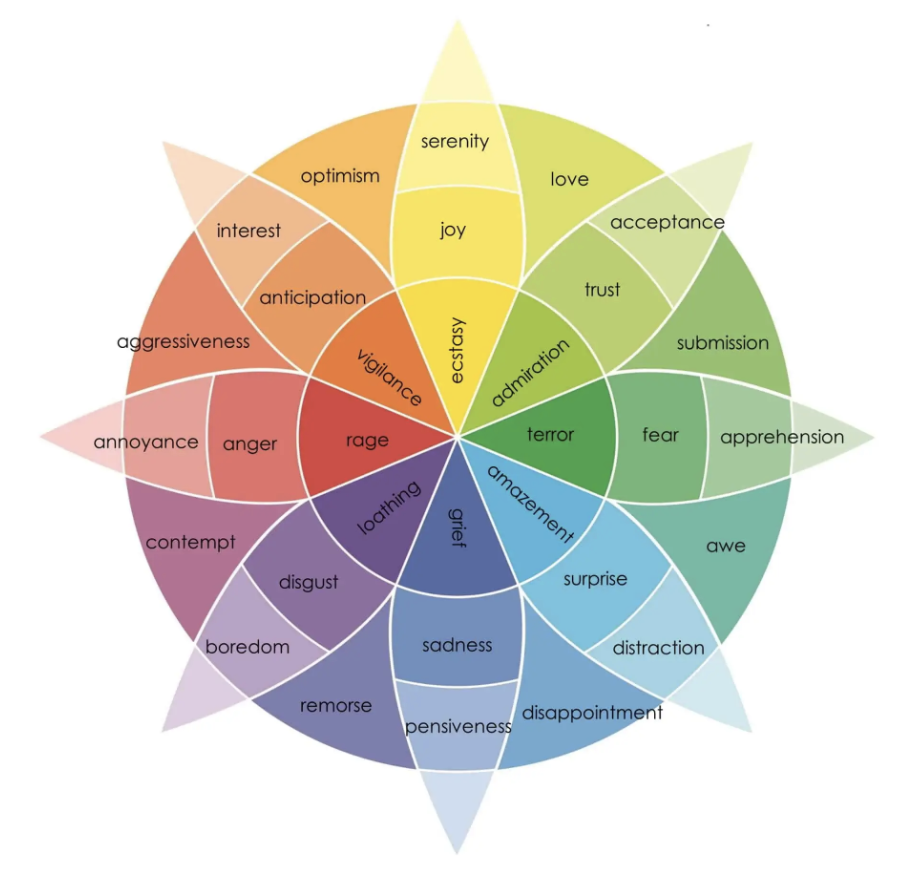
初めは文章などのコンテキストをポジティブなものか、ネガティブなものか、どちらでもないニュートラルなものかといった極性を判定するような分析を中心に研究が進められてきましたが、Plutchik の感情の輪といった心理学分野の研究を元にして「怒り」や「悲しみ」といった対象の感情自体を推定するという方向にも研究されています。
また、昨今何かと話題の GPT-4 などを中心とした大規模言語モデル(Large Language Model, LLM)の進歩から、テキストデータを中心により精度の高い自然言語処理ができるようになることで、この研究分野はさらなる発展をしていくと予想されます。
その他の分析手法
他にも顧客分析と調べたら様々なフレームワークがヒットするかと思います。例えばサービスを利用するユーザーを仮想的に作成してサービスに必要な体験を考えるペルソナ分析や、顧客の行動と感情を結びつけながら、ユーザーがサービスを利用するシナリオを作成することでサービスの体験の良し悪しを評価するカスタマージャーニー分析などがあります。これらも顧客の分析手法としてよく挙げられるものですが、定性的な判断も多く、データサイエンティストが全て行うものではないと考えています。UX デザイナーやマーケターのような職務の人が中心となり、前述のセグメンテーション/クラスタリングや感情分析の結果を持ってペルソナやカスタマージャーニーに対してデータドリブンな要素を加えることでより仮説を強固にする、といった関わり方がベストではないかなと考えています。(前述しましたが、もちろん全てできるデータサイエンティストの需要は凄まじいと思います。そこに行き着くまでどれだけ大変かは想像に難くありませんが…)顧客分析の手法の具体例
本セクションでは、前セクションで述べた顧客分析の手法とその目的との関係性を踏まえた上で、実際にどのように設計・実装していくのかを考えていきます。今回は購買データとして、Online Retail Data Setを使わせていただきます。軽く以下のような前処理をしてスタートです。def preprocess(df_retail: pd.DataFrame) -> pd.DataFrame :
df = df_retail.copy()
df["InvoiceDate"] = pd.to_datetime(df["InvoiceDate"])
df["CustomerID"] = df["CustomerID"].fillna(0).astype(int)
df["TotalPrice"] = df["Quantity"] * df["UnitPrice"]
df["FirstInvoiceChar"] = df["InvoiceNo"].str[0]
df = df.query("FirstInvoiceChar != 'A'") # adjustは除く
df = df.assign(IsCancelInvoice=df["FirstInvoiceChar"] == "C")
df["InvoiceNo"] = np.where(df["IsCancelInvoice"] == True, df["InvoiceNo"].str[1:], df["InvoiceNo"]).astype(int)
return df
df_retail = preprocess(df_retail_)
df_retail.head()
指標設計の例
指標設計とは書いていますが、今回のブログでは本当に基礎的な部分であるアクティブユーザーと売上について確認していきます。それぞれ日レベルと月レベルの統計量を作成していきます。df_daily_summary = (
df_retail.assign(InvoiceDay=lambda x: x["InvoiceDate"].dt.date)
.groupby("InvoiceDay")
.agg(
DailyActiveUser=("CustomerID", "nunique"),
GrossSales=("TotalPrice", "sum"),
)
.reset_index()
)
df_monthly_summary = (
df_retail.assign(InvoiceMonth=lambda x: x["InvoiceDate"].dt.to_period("M"))
.groupby("InvoiceMonth")
.agg(
MonthlyActiveUser=("CustomerID", "nunique"),
GrossSales=("TotalPrice", "sum"),
)
.reset_index()
.query("InvoiceMonth < '2011-12'")
)
これらをそれぞれプロットしていきます。fig, axes = plt.subplots(1, 2, figsize=(10, 4))
ax1 = axes[0].twinx()
sns.lineplot(df_daily_summary, x="InvoiceDay", y="GrossSales", ax=axes[0], color="blue", alpha=0.5)
sns.lineplot(df_daily_summary, x="InvoiceDay", y="DailyActiveUser", ax=ax1, color="red", alpha=0.5)
axes[0].set_xticklabels(axes[0].get_xticklabels(), rotation=45)
axes[0].set_ylabel("Daily Gross Sales", color="blue")
ax1.set_ylabel("Daily Active User", color="red")
ax2 = axes[1].twinx()
sns.barplot(data=df_monthly_summary, x="InvoiceMonth", y="GrossSales", ax=axes[1], color="blue", alpha=0.5)
ax2.plot(axes[1].get_xticks(), df_monthly_summary["MonthlyActiveUser"], color="red", alpha=0.5)
axes[1].set_xticklabels(axes[1].get_xticklabels(), rotation=45)
axes[1].set_ylabel("Monthly Gross Sales", color="blue")
ax2.set_ylabel("Monthly Active User", color="red")
plt.tight_layout()
plt.show()
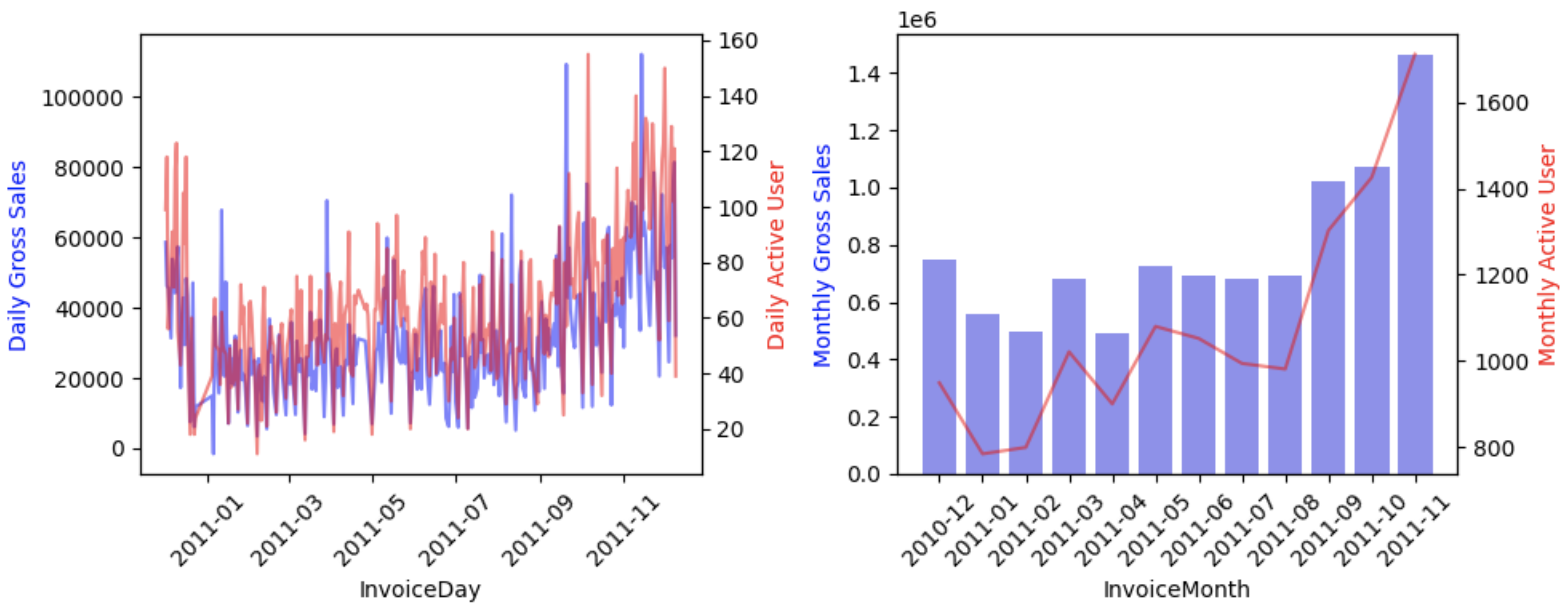
見たところ、日次の総売上は日によっては50,000ポンド程度のばらつきが見られます。そのため、目標として日次の総売上を掲げることは好ましくありません。DAUと日次総売上はいわばアラートのように異常な値が続かないかを監視するために追いかけつつ、MAUと月次総売上を施策によってどう伸ばすかを考えていく方針になります。
また、基礎的な数値しか出していませんが、2011年の9月からMAUと総売上の両方が増加していることがわかります。このタイミングで何が起きたのかをコホート分析などによって深掘りしていくというのは一つの顧客分析のアプローチだと考えられます。
顧客セグメンテーションの例
次に顧客のセグメンテーションの例です。今回はRFMの観点から顧客をセグメンテーションしてみます。まず、顧客ごとの属性データを行動データから作成していきます。(このデータフレームは次の生存時間分析の項でも利用します)# 行動データから特徴量を作る
df_users = (
df_retail.query("CustomerID != 0")
.assign(InvoiceDay=lambda x: pd.to_datetime(x["InvoiceDate"].dt.date))
.groupby("CustomerID")
.agg(
TotalInvoiceCount=("InvoiceNo", "nunique"),
CancelInvoiceCount=("IsCancelInvoice", "sum"),
SumTotalPrice=("TotalPrice", "sum"),
FirstInvoiceDay=("InvoiceDay", "min"),
LastInvoiceDay=("InvoiceDay", "max"),
TotalInvoiceDayCount=("InvoiceDay", "nunique"),
)
.assign(
DiffFirstAndLastDay=lambda x: (x["LastInvoiceDay"] - x["FirstInvoiceDay"]).dt.days,
DiffEndDay=lambda x: (df_retail["InvoiceDate"].max() - x["LastInvoiceDay"]).dt.days,
)
.reset_index()
)
このデータフレームに対して、RFMそれぞれの観点で3つのビンに区切り、ビンに対して数値が小さくなれば優良顧客とみなせるようなラベルを振っていきます。そしてそれぞれのセグメントに属する顧客の平均総購入金額と平均総注文回数をヒートマップでプロットします。# RFMの観点でセグメンテーション
df_rfm = (
df_users.assign(
RecencyRank=lambda x: pd.qcut(x["DiffEndDay"], 3, labels=[1, 2, 3]).astype(int),
FrequencyRank=lambda x: pd.qcut((x["TotalInvoiceCount"] - x["CancelInvoiceCount"]), 3, labels=[3, 2, 1]).astype(int),
MonetoryRank=lambda x: pd.qcut(x["SumTotalPrice"], 3, labels=[3, 2, 1]).astype(int),
)
.groupby(["RecencyRank", "FrequencyRank", "MonetoryRank"])
.agg(
AvgAllInvoicePrice=("SumTotalPrice", "mean"),
AvgAllInvoiceCount=("TotalInvoiceCount", "mean"),
)
.reset_index()
.sort_values(["RecencyRank", "FrequencyRank", "MonetoryRank"])
)
fig, axes = plt.subplots(1,2,figsize=(8,4))
sns.heatmap(df_rfm.pivot_table(index=["RecencyRank", "FrequencyRank"], columns="MonetoryRank", values="AvgAllInvoicePrice"), ax=axes[0], annot=True, fmt=".0f", cmap="Blues")
sns.heatmap(df_rfm.pivot_table(index=["RecencyRank", "FrequencyRank"], columns="MonetoryRank", values="AvgAllInvoiceCount"), ax=axes[1], annot=True, fmt=".0f", cmap="Blues")
axes[0].set_title("AvgAllInvoicePrice")
axes[1].set_title("AvgAllInvoiceCount")
plt.tight_layout()
plt.show()
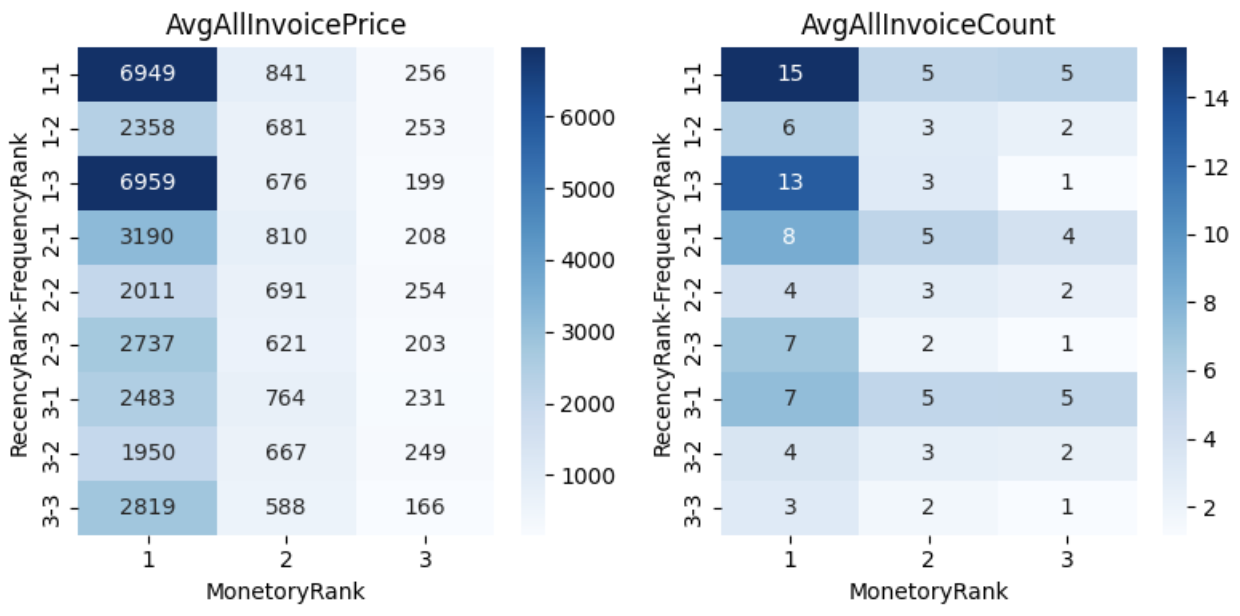
こう見るとRecencyのランクが高い(=直近購入している顧客)かつFreqencyに関しては回数が中程度の顧客と比べて多いor少ない方が優良顧客と言えそうということがわかります。2011年9月から総売上が大きく上がっていることからRecencyに関してはわからなくないですが、Frequencyに関しては関心が湧きます。Recency=1, Frequency=2, Monetory=1の顧客は他と比べてなぜ低めの結果となったのかを属性データと一緒に深ぼっていくことになると思います。
生存時間分析の例
次は生存時間分析の例です。先ほどのデータフレームにおける「最初の取引と最後の取引の間の日数」のデータを使って、2011年の12月に取引をしていない顧客は離脱した(イベントが発生した)として生存時間分析を行なっていきます。# 生存時間分析
# 2011年12月に取引をしていない場合は離脱したとみなして分析
from lifelines import KaplanMeierFitter
df_users = df_users.assign(IsLeaved= lambda x: x["LastInvoiceDay"] < "2011-12-01")
kmf = KaplanMeierFitter()
kmf.fit(df_users["DiffFirstAndLastDay"], event_observed=df_users["IsLeaved"])
fig, ax = plt.subplots(figsize=(8,4))
kmf.plot_survival_function(ax=ax)
ax.set_xlabel("day")
ax.set_ylabel("survive ratio")
ax.set_title("median_survival_times: {}".format(kmf.median_survival_time_))
ax.set(ylim=(0,1))
plt.show()
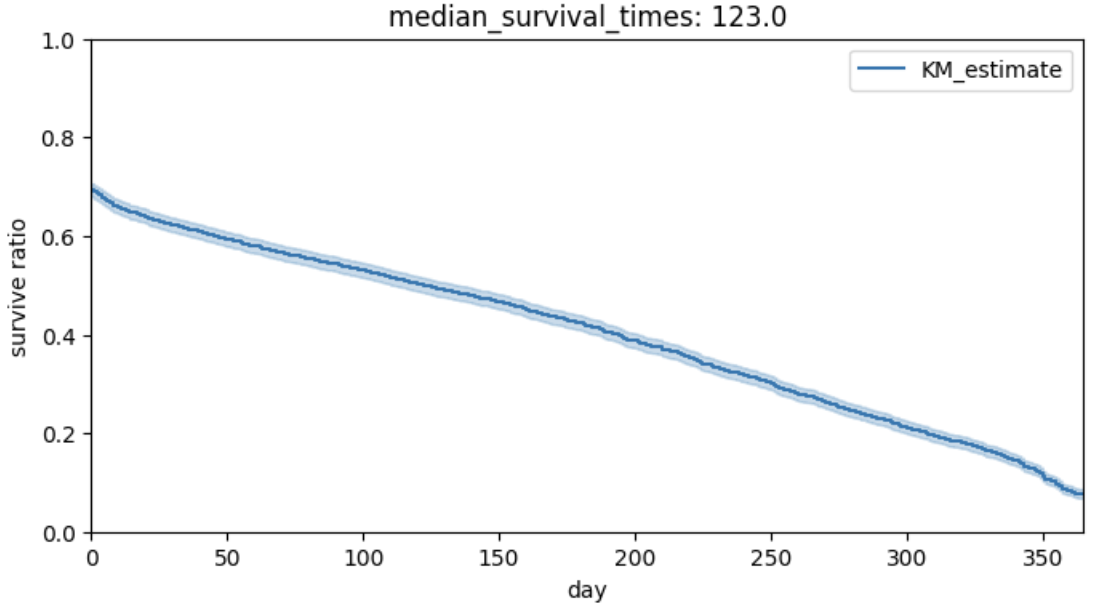
結果として、30%の顧客が最初と最後の購入日が同じ=1日しかアクティブになっていないということがわかります。ここの30%の顧客をもう1日、さらにもう1日と購入を重ねてもらう方が良いのか、はたまたそこは重視せずにRFMで見つけたセグメントに対して手厚くサポートするべきなのか、といった仮説が生まれます。また、中央値で言うと離脱までの期間は123日、およそ4ヶ月間となります。これを基準に直近4ヶ月購入していない顧客に対してはまだ復帰する可能性ありとしてアプローチをとっていくのも手である、と言えるかもしれません。
感情分析の例
このセクションで今まで利用してきたデータですが、行動データしかないためこのデータから感情分析を行うには難しいです。実務においては、アンケートをとったり SNS の情報を取得するなどにより顧客の感情が発現しやすいデータを取得できるような環境を構築することが第一にすべきことになるかと思います。今回は、感情分析では別のデータを使います。ただ、実際の EC サイトのレビューデータやツイートなどを使うとなると色々と気を遣うので、chatGPTでデータを作成しました。
次のような条件を全て遵守して、感情分析用のデモデータを作成して表示してください ・架空のあるサービスに対する印象を表現したデータ ・ツイッターのような極めて砕けた文体で短い文章を出力する ・ポジティブな発言とネガティブな発言が同じ割合になるように出力する ・過激なネガティブ発言は除外する ・ポジティブな例:「このサービス、機能が多くていい!」「普通に使えるな」 ・ネガティブな例:「値段高いのがちょっとなぁ…」「UIがイケてない」
上記の入力で生成された 300 件のデータを使用して感情分析をしていきましょう。日本語に対応した感情分析モデルに関してはこちらを使わせていただきました。 理論は複雑であれど、使う分にはそこまで難しくないのはとてもいい時代ですね。
from transformers import pipeline
name = "jarvisx17/japanese-sentiment-analysis"
nlp = pipeline("sentiment-analysis", model=name, tokenizer=name)
res = nlp(df_review["text"].to_list())
df_review = pd.concat([df_review, pd.DataFrame(res)], axis=1)
分類結果を10件サンプルしてみたところ、以下のように若干怪しいところもありますが、概ね正しくポジティブ/ネガティブを判定できています。今現在の顧客によるポジティブな意見に関してはセールスポイントとして利用し、ネガティブな意見に関しては改善点として捉えることでより良いサービスを目指すことができるかと思います。label text score 0 negative 使い方が分からない機能があって、イライラしたわ。 0.999938 1 negative 使い方が難しくてイライラした... 0.999944 2 negative 値段が高すぎて、コストパフォーマンスが悪い... 0.999944 3 negative このサービス、価格が高すぎて手が出せない... 0.999696 4 negative 値段が高くて、使う回数が減ってしまった... 0.999942 5 positive 使ってみた感じ、まあまあ良かったと思う。 0.999953 6 positive このサービスは、特に何も問題はなかったわ。 0.999953 7 positive このサービスを使うと、業務の効率化ができて快適! 0.999957 8 positive 機能が充実していて、どんな仕事でもこなせる 0.999956 9 positive セキュリティがしっかりとしていて、情報漏洩の心配がない 0.999951また、今回データの生成もChatGPTでやってしまいましたが、ChatGPTでもよく「出鱈目を返してくる」と言われることがあるように、あくまで尤もらしい値を出しているだけのLLMでは絶対に間違えてはいけない分野への応用は現状かなり気を遣います。ただし、こと顧客分析においてはその不確実性に関しても顧客という不確実な対象を再現できる可能性があるのではないかと考えています。頭を使わずにペルソナを勝手に出力してくれるような形でLLMを利用できたら顧客分析に関してもブレイクスルーが生まれるのではないかと考えています。
まとめ
本ブログでは、データサイエンティストとして顧客分析をどのように捉えればよいかということについて検討してみました。結論としてはいかに数値に落とし込み、統計・機械学習の引き出しを使いながら、マーケターを中心としたビジネスサイドやUXデザイナーと協力して顧客を捉えて意思決定をサポートする、というところが落とし所かなと思っています。今回整理した中でも特に指標の設計が非常に高いレベルが必要だと感じました。設計次第で意思決定が意図していない方向に向かってしまうリスクもあるということもあり、かなりの能力・知識・そして経験が必要とされるイメージでした。
また、今回はほんの少しだけ触れましたが、LLMと顧客分析の親和性は個人的には高いと思っています。今後Deep Learning界隈がどのような方向に進んでいくのかはわかりませんが、是非ブレイクスルーが起きて欲しいものです。
最後になりますが、当然ながら顧客分析に関する定義や方法は一枚岩ではなく、今回私が考えたものも一部でしかないと思っています。あくまで一例として捉えていただけると幸いです。最後までご覧いただきありがとうございました。
最後に
グループ研究開発本部 AI 研究開発室では、データサイエンティスト/機械学習エンジニアを募集しています。ビッグデータの解析業務など AI 研究開発室にご興味を持って頂ける方がいらっしゃいましたら、ぜひ募集職種一覧からご応募をお願いします。皆さんのご応募をお待ちしています。参考
- データマイニング手法【3 訂版】〈探索的知識発見編〉―営業、マーケティング、CRM のための顧客分析―
- データマイニング手法【3 訂版】〈予測・スコアリング編〉―営業、マーケティング、CRM のための顧客分析―
- データ・ドリブン・マーケティング 最低限知っておくべき 15 の指標
- KPI 大全 重要経営指標100の読み方&使い方
- 評価指標入門 データサイエンスとビジネスをつなぐ架け橋
- Daqing Chen, Sai Liang Sain, and Kun Guo, Data mining for the online retail industry: A case study of RFM model-based customer segmentation using data mining, Journal of Database Marketing and Customer Strategy Management, 2012
- マーケティング用語集
- 生存時間解析について – 概要編