2025.06.10
BAGEL: ByteDanceの画像生成・編集も可能なマルチモーダル統合オープン生成AI
TL;DR
- ByteDanceが2025年5月20日に発表したマルチモーダル統合モデル「BAGEL」は、GPT-4oやGeminiと同等にテキストから画像生成、入力画像の理解と画像編集が可能です。BAGELは140億パラメータ(アクティブなものは70億)のオープンソースで公開されており、ローカル環境で実行可能です。
- BAGELは、意味理解と画像生成専門のTransformerを組み合わせたMixture-of-Transformer(MoT)アーキテクチャーを採用し、2つのTransformerはAttentionを共有することで、概念理解と画像生成能力を統合しています。学習では「interleaved data」という動画などから拡張生成された画像とテキストデータも利用し、現実世界での画像と意味の結びつきの理解を強化しています。
はじめに
こんにちは。グループ研究開発本部 AI研究開発室のT.I.です。昨今、OpenAIのChatGPT 4oやGoogleのGeminiなど、文章生成だけではなく、画像生成や編集も可能なマルチモーダルモデルが登場しています。今回は、ByteDanceが開発したマルチモーダルなオープンAI「BAGEL」について紹介します(BAGEL: The Open-Source Unified Multimodal Model)。BAGELは、画像生成・画像編集・画像理解を統合的に行うことができるモデルであり、オープンソースとして2025年5月20日に公開されています( Bagel [GitHub])。なお、BAGELの名の由来は、「scalaBle generAtive coGnitive modEL(デモ動画では、scalaBle perceptuAl Generative modEL)」の略です(そんな無茶な)。BAGELがどのようなことができるか、以下に引用する公式サイトのデモ動画がわかりやすいでので、まずはご覧ください。
動画はBAGEL: The Open-Source Unified Multimodal Model より
画像を入力し、深く考えながら新しい画像を生成したり、画像の一部を編集して新しい画像を生成したりと、OpenAI ChatGPT 4oやGoogle Geminiと匹敵するようなパフォーマンスを持っていることがわかります。
BAGELを動かしてみる
BAGELを試すには、デモサイト(BAGEL Demo)を利用するのが最も手軽ですが、今回はGitHubのリポジトリからローカル環境にインストールして動かしてみます。BAGELは全体では、140億パラメータのモデルですが、実際にアクティブとなるのは70億パラメータのみです。では、GitHubの指示に従って、BAGELをローカル環境にインストールしてみます。
$ git clone https://github.com/bytedance-seed/BAGEL.git $ cd BAGEL $ uv venv --python 3.10 $ source .venv/bin/activate $ uv pip install -r requirements.txt $ uv pip install flash_attn --no-build-isolation
GitHubの手順では、flash_attnのバージョンを指定がありますが、うまくビルドできなかったため、バージョン指定せずにインストールすることで成功しました(以下、flash-attn 2.7.4.post1での実行検証)。次に、必要なモデルデータをダウンロードします。GitHubの指示通り、以下のPythonスクリプトを実行します。
from huggingface_hub import snapshot_download
save_dir = "models/BAGEL-7B-MoT"
repo_id = "ByteDance-Seed/BAGEL-7B-MoT"
cache_dir = save_dir + "/cache"
snapshot_download(cache_dir=cache_dir,
local_dir=save_dir,
repo_id=repo_id,
local_dir_use_symlinks=False,
resume_download=True,
allow_patterns=["*.json", "*.safetensors", "*.bin", "*.py", "*.md", "*.txt"],
)
ダウンロードに時間がかかりますが、これでBAGELのモデルをローカル環境にインストールできました。さて、GradioのWebUIを立ち上げてみます。
$ python app.py
注意点として、BAGELの量子化なしでの実行には32GB以上のVRAMが必要です(例 GeForce RTX 5090相当)。一般的なGPU(12GB以上)で動作させるためには、以下のようにモードの切り陰が必要です。
$ python app.py --mode 2
もう少し、GPUのスペックに余裕がある(VRAM 22GB以上)場合は、以下のモードでも実行可能です。GeForce RTX 4090 (24 GB)では、このモードでも無事に実行できました。
$ python app.py --mode 3
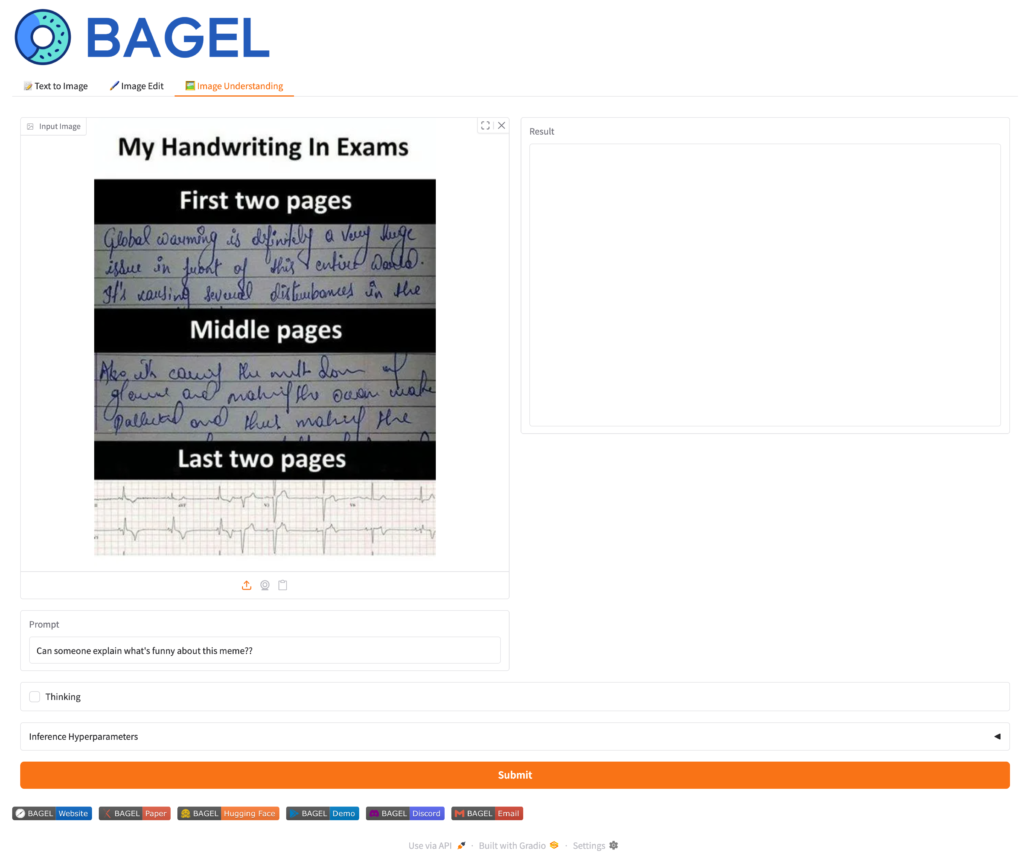
GradioのWebUIが立ち上がりますので、ブラウザでアクセスしてみます。BAGELには、以下の図の様なText to Image、Image Edit、Image Understandingの3つのモードがあります。(表示されているプロンプトや画像はデフォルトのものです。)
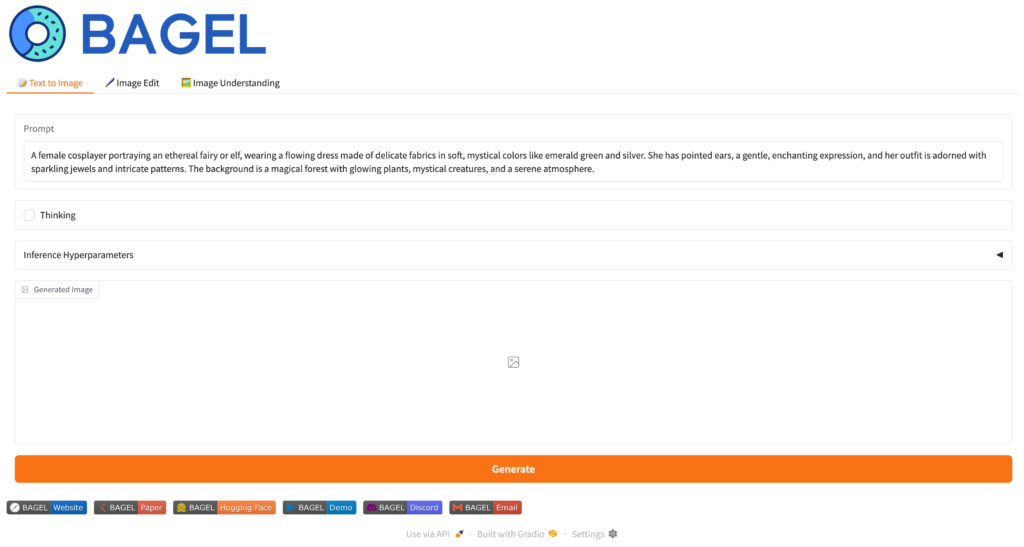
BAGEL: Text to Image
では、まずはText to Imageのモードを試してみます。画像生成のモードでは、テキストプロンプトを入力し、画像を生成できます。また、Image EditとImage Understandingも同様ですが、Thinkingモードを有効にすると、画像生成の前に思考プロセスを追加することで、より高品質な結果がえられます。画像の生成にかかる時間は、RTX 4090で約1分半程度でした。

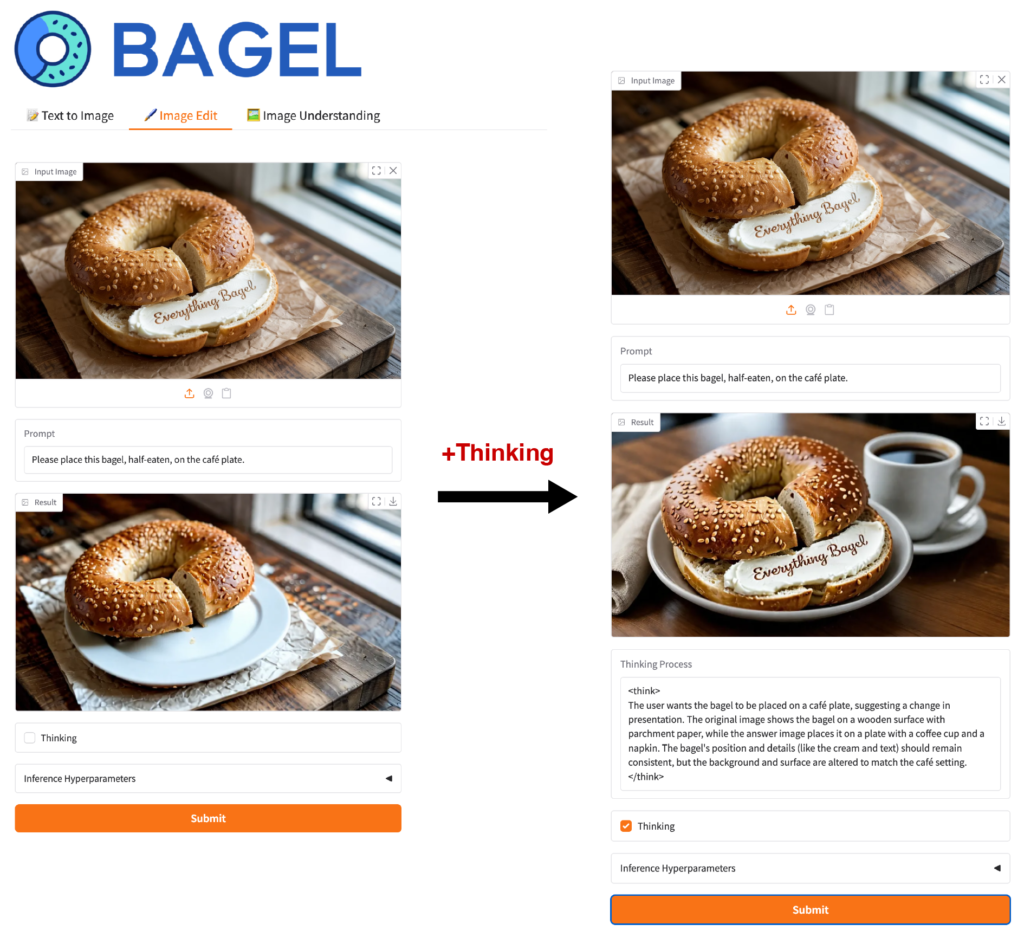
BAGEL: Image Edit
つぎは、Image Editのモードです。これは画像を入力してプロンプトの指示で編集する機能です。こちらもThinkingモードで思考プロセスを追加しより高品質な結果がえられます。
BAGEL: Image Understanding
最後に、Image Understandingのモードです。これは画像を入力してプロンプトの指示で理解する機能です。こちらもThinkingモードで思考プロセスを追加しより高品質な結果がえられます。

BAGELの中身について
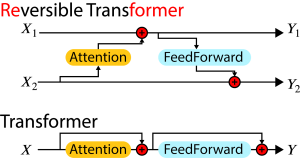
さて、一旦動かして遊んでみましたが、BAGELの理論的背景についても少し触れておきましょう。BAGELはマルチモーダルなオープンAIであり、モデルだけではなく、技術使用についても詳細に公開されています(Emerging Properties in Unified Multimodal Pretraining [arXiv:2505.145683])。BAGELの技術的な特徴としては「Mixture-of-Transformers(MoT)」と呼ばれるアーキテクチャを採用しています。これは、意味を理解するためのTransformerブロック(Und. Expert)と画像生成専門のTransformerブロック(Gen. Expert)を組み合わせたものです。それぞれは異なる専門性を持ちますが、途中のAttention機構は共有されています。文章の生成は、通常のLLMと同様にNext Token Predictionによる生成を行います。画像に関しては、Diffusion Modelではなく、Stable Diffusion 3でも採用しているRectified Flow を利用した Velocity Predictionを元にした画像生成を行います(Stable Diffusion 3: Research Paper)。Rectified Flowは、Stable Diffusion 3のアーキテクチャーについて解説した以前のBlog(Stable Diffusion 3: Stability AIの最新生成AIの技術解説 Multimodal Diffusion Transformer & Rectified Flow)で解説していますので、そちらも参考にしてください。
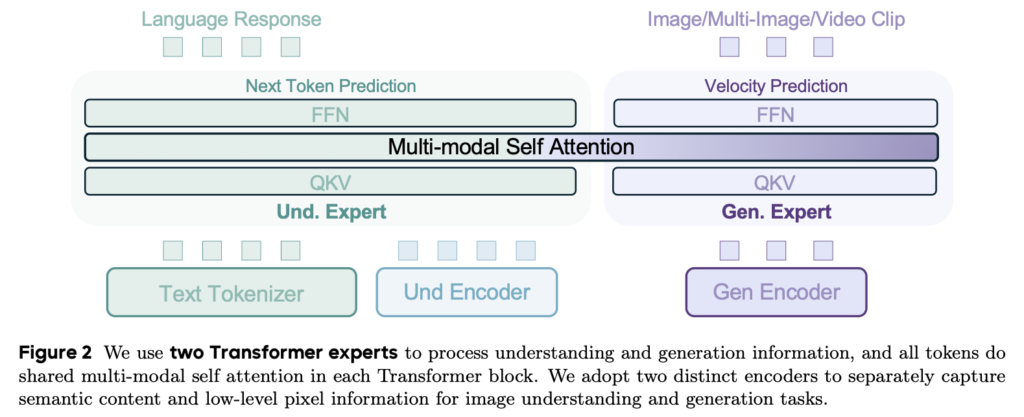
具体的なBAGELのアーキテクチャーは、Qwen2.5(Hugging Face Qwen2.5)を元にしており、画像理解のためのViTエンコーダーはSigLIP2-so400m/14(SigLIP 2: A better multilingual vision language encoder)、画像生成に関してはFLUX(GitHub – black-forest-labs/flux)のVAEを採用して組み合わせています。
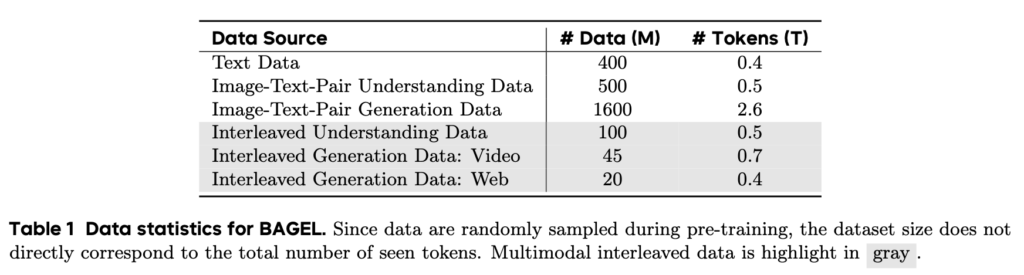
BAGELの学習では、テキストデータ、そしてテキストと画像のペアデータを利用して学習を行っています。文章生成のテキストデータでは、0.4Tトークン、画像とテキストペアのデータに関しては、意味理解のためのデータと画像生成様のデータをそれぞれ0.5Tトークン、2.6Tトークンを利用しています。更にBAGELが、現実世界の情報をより正確に理解するために、interleaved data(綴じ込まれた)という拡張学習データも利用しています。推論能力を高めるためのデータが0.5Tトークン、動画、Webを元に拡張したデータが、それぞれ0.7Tトークン、0.4Tトークンを利用しています。これらの学習データをまとめたものが以下の表です。
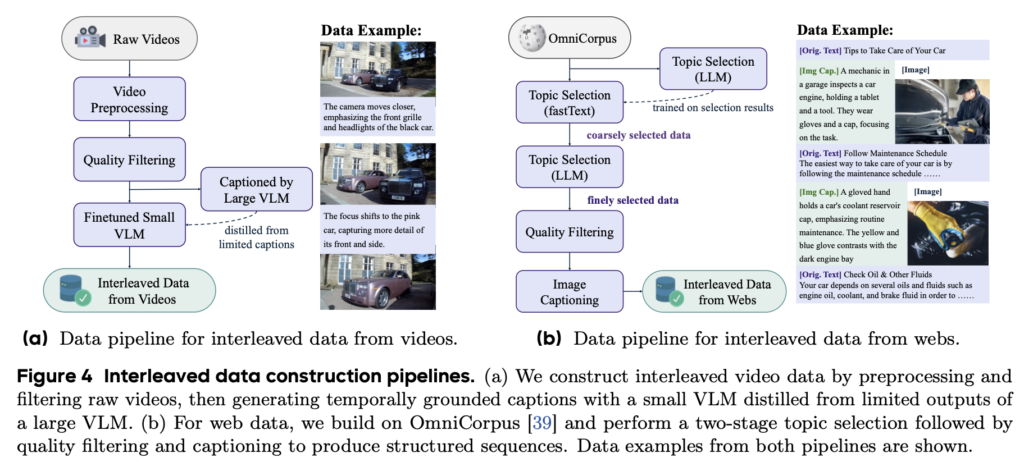
この、「interleaved data」について補足します。画像とテキストという異なるモダリティを結びつけるために、通常のVLMの学習では画像とテキストのペアデータを利用しますが、現実世界の情報はもっと深いコンテキストで結びついており、単純なペアデータだけでは不十分です。そこで、BAGELではマルチモーダルな理解力を高めるために、動画やWebの情報を元にした学習データ生成を行っています。動画からは、フレームを抽出して、VLMを使ったキャプションを生成を順次生成して交互に並べることで、現実の物体の空間情報や時間の流れを意識した学習データを生成しています。また、Webデータ(OmniCorpusを利用)からは、チュートリアルのような順序が意味があるデータを抽出し、その画像のキャプションをVLMから生成して拡張することで、より堅牢なマルチモーダルな理解力を学習させます。更に、O1やDeepSeek-R1の学習においてChain-of-Thought形式のデータを利用しているように、BAGELでもReasoning-Augmented Dataと呼ばれる500kのデータを利用して学習を行っています。
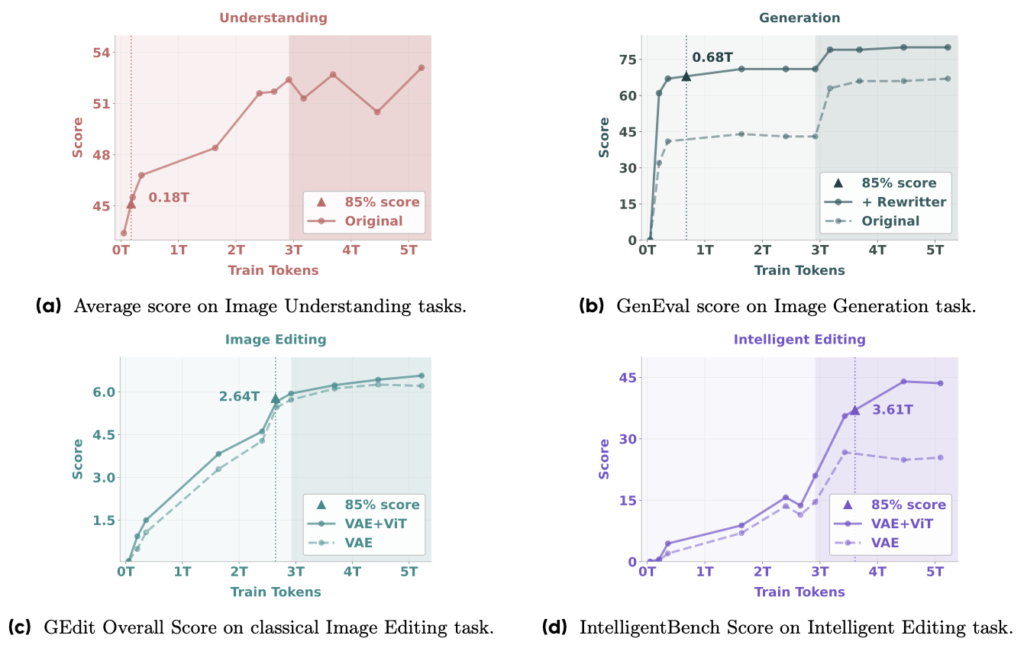
以上の学習データを元に、BAGELはアライメント、事前学習、追加学習と教師ありファインチューニングという4段階に分けて学習を行っています。学習データの量と性能に関して、BAGELでは、「Emerging(創発)」という興味深い現象を報告しています。創発とは、学習の初期段階では表れていない能力が、ある時を境に急激に向上する現象を指します。BAGELでは、学習データの量が増加するにつれて、特定のタスクにおいて急激な性能向上が見られることを示しています。以下の図は、4種類のタスクの性能を学習データの量に応じてプロットしたものです。ピーク性能の85%を達成するために必要な学習データの量は、画像理解では約0.18Tトークン、画像生成では約0.68Tトークン、画像編集では約2.64Tトークン、そしてより高度な画像編集では約3.61Tトークンとなっています。BAGELの性能は学習データと共に向上し、特に課題の複雑さに応じて必要となる学習データの量が増えていくことがわかります。
まとめ
今回のBlogでは、ByteDanceが開発したマルチモーダルなオープンAI「BAGEL」について紹介しました。BAGELは、画像生成・画像編集・画像理解を統合的に行うことができるモデルであり、オープンソースとして公開されています。OpenAIのChatGPT 4oやGoogleのGeminiなども同様の機能を持っていますが、オープンソースとして同等の高い性能を持つモデルが公開されたことは大きなインパクトのある成果と言えます。オープンモデルの利点としては、クローズドモデルと違いローカルでセキュアに利用可能ですし、またBAGELを元にさらに追加学習しユーザーの好みのモデルに改良するなどの利用方法が考えられます。
最後に
グループ研究開発本部 AI研究開発室では、データサイエンティスト/機械学習エンジニアを募集しています。ビッグデータの解析業務などAI研究開発室にご興味を持って頂ける方がいらっしゃいましたら、ぜひ募集職種一覧からご応募をお願いします。皆さんのご応募をお待ちしています。

参考資料
- BAGEL: The Open-Source Unified Multimodal Model
- Bagel [GitHub]
- Bagel Demo
- Emerging Properties in Unified Multimodal Pretraining arXiv:2505.145683
- Stable Diffusion 3: Research Paper
- Stable Diffusion 3: Stability AIの最新生成AIの技術解説 Multimodal Diffusion Transformer & Rectified Flow
- Hugging Face Qwen2.5
- SigLIP 2: A better multilingual vision language encoder
- GitHub – black-forest-labs/flux
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD