2022.01.11
GCPの次はAWS Lake FormationとGoverned tableを試してみた(Glue Studio&Athenaも)
こんにちは。次世代システム研究室のデータベース と Hadoop を担当している M.K. です。
前回のブログではGoogleのGCPのDataproc on GKE(β版)を使って、クラウドネイティブなHadoopクラスタを検証しました。コンピュートノードをストレージノードと分離して、処理したいときだけコンピュートノードを使うような形です。ある程度はやりたいことができましたが、Dataprocメタストアと連携できるようにしたり(β版だからかうまくいかず・・)、GKEクラスタの設計・管理をしないといけなかったりと、統合的にはできませんでした。
もっと簡単にできないものかと探してみると、なんと、AmazonのAWSにLake Formationという、やりたい構成が統合的に用意されたサービスがありました!
GoogleのGCP一辺倒もつまらないなと思っていたので、今回は、AWS Lake Formationを検証することにしてみました。
AWS Lake Formation
AWS Lake Formationはどんなもの?
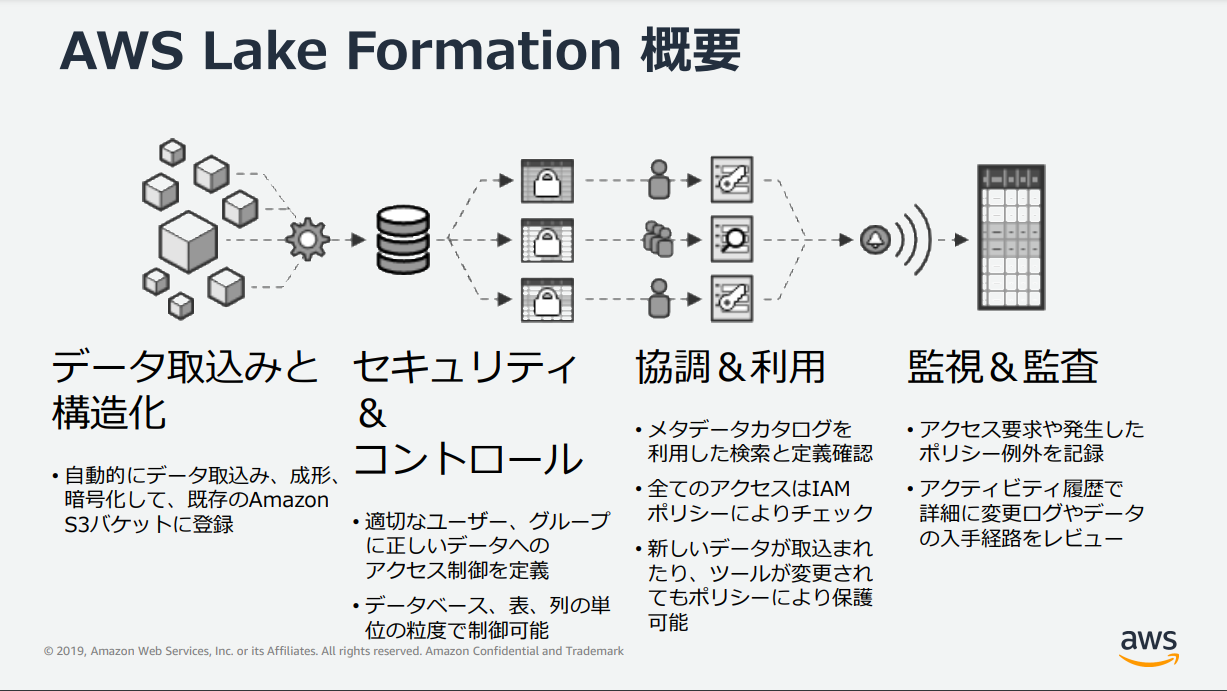
様々なデータ(構造化/非構造化)を一つに集めて分析を行うデータレイクを、AWSがすばやく構築&統合的に管理できるように目指したもの、だと思います。
詳しい説明がAWSの資料として公開されていますので、お読みください。
「20191001 AWS Black Belt Online Seminar AWS Lake Formation」資料より抜粋:
それと、以下の記事も参考にさせていただきました。
期待のGoverned table
そして、最近GAリリースされたのが、Lake FormationのGoverned tableです。コンピュートノードとストレージノードを分離して分散処理を行うとき、ストレージノードはAWS s3やGCSなどオブジェクトストレージのサービスを使うことが基本になると思いますが、オブジェクトストレージやその上に作成するテーブルはACIDトランザクション対応でないことはほとんどでした。
Sparkで有名なDatabrick社が出しているDelta Lake(以前からずっと検証していた技術:過去のDelta Lakeを検証したブログ)はACIDトランザクション対応を謳っていますが、今まではこれしかぱっと思いつくものがなかったので、AWSが出してきてとても関心を持ちました。コンピュートノードとストレージノードの分離に加えて、ACIDトランザクション対応できたら言うことなしなので個人的に期待してます。
AWS GlueとAthena
Lake FormationのコアになっているAWS Glue
Lake Formaionについて調べたり、色々触っていく中でわかったのは、Lake Formationのコア技術はAWS Glueということです。Glueは様々なデータソースのメタデータ管理とデータ移動を行うサーバーレスなデータ統合(主にETL)サービスです。
GlueについてはこちらのAWS公開資料が詳しいです。
Glue Studioが便利
GlueにはVisualでETLジョブが簡単に作れるGlue Studioができてとても便利になりました。今回の検証でもメインで使っています。使ってみた感想としては、Governed table対応などまだこれからのところもありますが、とても見やすくて使いやすいと思いました。
Glue Studioについても最近のAWS公開資料が出ているので参考にしてみてください。
AWS Athenaとの連携
Lake Formation(Glue)でデータを統合的に管理できるようになっても、すぐにデータ分析できないと残念な感じになるわけですが、そのときにAWS Athenaを利用します。
Athenaはs3上のデータをテーブル管理してSQLで操作できるようにするサービスです。
AthenaもAWSの公開資料があるので詳細が知りたい方は読んでみてください。
使ってみてわかったのは、Athenaは実はPrestoがベースだったということで(私が全然知らなかっただけですけど)、Athenaからのクエリは基本的にPrestoのSQLに準拠します。ただ、DDLはHiveQL、参照はPrestoのSQLみたいになるのと、GlueのジョブでSQLを書くときはSparkSQLになるため、時々混乱するので要注意です。
あと、後述していますが、Lake Formationと連携するには「AmazonAthenaLakeFormation」という名前のワークグループを作成しないといけません。
Lake Formationを試す
それではいよいよLake Formationを試していきます。
Lake Formationの権限管理
AWSで何かを新たに試すには、兎にも角にも、まず権限管理ですね。AWSのドキュメントに従ってLake Formation用のユーザーを作って権限を付与します。最初よくわからないので、Lake Formation用のユーザーを一つ作って、そこに必要な権限や新たに作成したポリシーを付与しました。
まず「LakeFormationWorkflowRole」をAWSのドキュメント通りに作成してから、以下をそのユーザーに付与します。
- 既存のAWS管理ポリシー
- AmazonAthenaFullAccess
- AdministratorAccess
- CloudWatchLogsReadOnlyAccess
- AWSGlueConsoleFullAccess
- AWSLakeFormationCrossAccountManager
- AWSLakeFormationDataAdmin
- AWSのドキュメントに従って新たに作成したインラインポリシー
- LakeFormationSLR
- PutDataLakeSettingOnly
- RAMAccess
- UserPassRole
検証を進めるうちに、Glueのジョブではロールを指定する必要があり、選択肢が「LakeFormationWorkflowRole」になるため、このロールに足りない以下の権限を後で追加しました。
- AWSGlueServiceRole
- AmazonS3FullAccess
このあたり、IAM設計がちょっとおかしくなっていると思うので、いつかもっとちゃんと理解しようと思います(たぶん)。
IAM設計が終わったら、Lake Formationの権限管理も行います。
AWS Lake Formationのコンソール画面にいき、サイドメニューから「Data lake locations」で今回使うs3のパスを登録します。ここで登録していないところはLake Formationで管理対象になりません。今回は検証用のデータを置いたs3バケットとLake Formationで作成するデータベース用のs3バケットの二つを登録しました(Lake Formationで登録する前に先にs3でバケットを作成しておきます)。
続いて、サイドメニューから「Data locations」でLake Formationで作成するデータベース用のs3バケットのパスに対する許可を「LakeFormationWorkflowRole」に付与します。
ここまでできたら、Lake Formationでデータベースを作成します。サイドメニューから「Databases」でデータベースを作成します。「datalake」という名前で先ほどのs3バケットのパスを指定して作成しました。
要注意
データベース作成時に注意点があって、データベース名に「-(ハイフン)」を入れてはいけません。最初何も知らずに「lakeformation-db」という名前で作ったんですが、データベース名に「-」が入っていると、クエリがこけるときがあって(Lake Formationの「Tables」から「Action」で「View Data」したときに発行されるクエリなど)、理由がわからずハマりました。。
なんじゃそりゃという感じなんですが、なんともできないので、データベース名には注意しましょう。
Glue Studioからジョブ(Visual with a source and target)でデータロード
今回の検証では、毎度おなじみのアイオワ州のお酒販売のサンプルデータを使います。Lake Formationでテーブルを作成し、Glue StudioからVisualでETLのジョブを作成してみます。
Lake Formationのサイドメニューから「Tables」を選んでPARQUETフォーマットのパーティショニングされたテーブルを作成します。画面で作れるんですが、カラム定義(スキーマ)の記入がいけてなくて1カラムずつ登録するか、JSON形式で一括して登録するかしかできません。JSONで一括登録する場合にパーティションキーをどうするのかがわからず、テーブルプロパティを全部JSON形式で書いてみたり試行錯誤して、ようやく以下の正解に辿り着きました。
[
{
"Name": "invoice_item_number",
"Type": "string"
},
{
"Name": "store_number",
"Type": "int"
},
{
"Name": "store_name",
"Type": "string"
},
{
"Name": "address",
"Type": "string"
},
{
"Name": "city",
"Type": "string"
},
{
"Name": "zip_code",
"Type": "int"
},
{
"Name": "store_location",
"Type": "string"
},
{
"Name": "county_number",
"Type": "int"
},
{
"Name": "county",
"Type": "string"
},
{
"Name": "category",
"Type": "string"
},
{
"Name": "category_name",
"Type": "string"
},
{
"Name": "vendor_number",
"Type": "int"
},
{
"Name": "vendor_name",
"Type": "string"
},
{
"Name": "item_number",
"Type": "int"
},
{
"Name": "item_description",
"Type": "string"
},
{
"Name": "pack",
"Type": "int"
},
{
"Name": "bottle_volume",
"Type": "int"
},
{
"Name": "state_bottle_cost",
"Type": "string"
},
{
"Name": "state_bottle_retail",
"Type": "string"
},
{
"Name": "bottles_sold",
"Type": "int"
},
{
"Name": "sale",
"Type": "string"
},
{
"Name": "volume_sold_liters",
"Type": "float"
},
{
"Name": "volume_sold_gallons",
"Type": "float"
}
]
上記のカラム定義を登録した後で、コンソール画面上でパーティションキーのカラム(sale_date:date型)を追加で登録します(つまり一括登録する際は除外しておく)。ここもわかりにくいところ。
同じカラム定義で、データロードの元のソースとなるテーブルと、ターゲットとなるGoverned tableの二つを作成します。
前者は、以前のブログでお酒販売サンプルデータをPARQUETフォーマットに作り直したもの(未パーティショニング)があるので、予めs3の指定のバケットに配置、そこをLake Formationのテーブルとして作成します。後者はコンソール画面から作成するときに「Enable goberned data access and management」をチェックして作成します。
先にテーブルを作成したら、Lake Formationのサイドメニューで「Jobs」を開きます。これはAWS Glueへのリンクになっていて、Glueのコンソール画面に移ったらサイドメニューから「AWS Glue Studio」を選びます。
Glue Studioのコンソール画面のサイドメニューで、「Jobs」を選んでジョブを作成します。Create jobのセクションにある「Visual with a source and target」にチェックが入った状態で、すぐ下にあるSource→Targetのプルダウンでそれぞれ「AWS Glue Data Catalog」を選び、「Create」ボタンを押します。
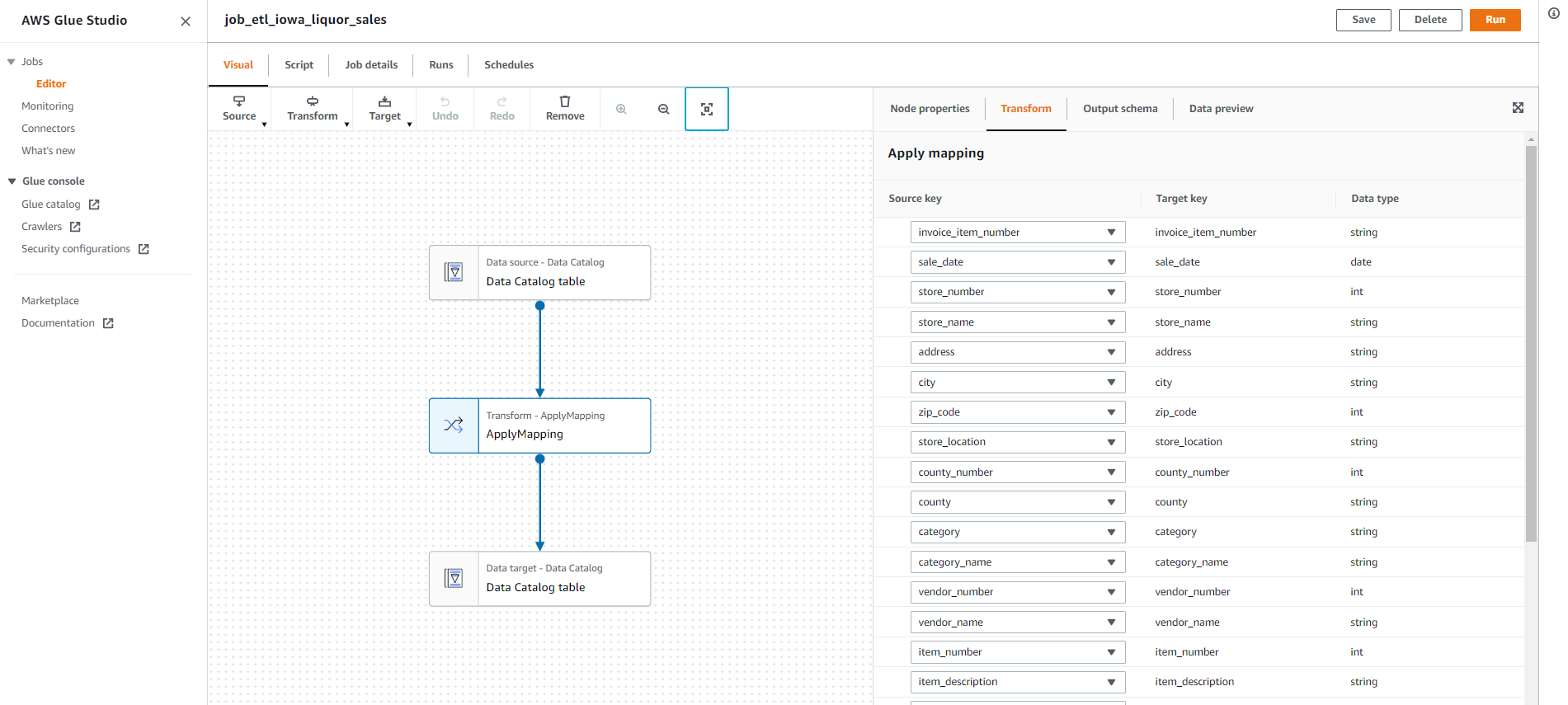
このような画面が出てくるので、Data sourceのアイコンとData targetのアイコンを一つずつ選択してそれぞれデータベースとテーブルを選択すれば、TransformのApplyMappingは自動で入ります。Data targetの方は「Parition keys – optional」と出てくるので、ここにパーティションキーのsale_dateカラムを選択しておきます。
これでもうETLのジョブが作れてしまったので、あとは「Run」ボタンを押して実行するだけです。Glue Studioはとても楽ちんで良いですね。
と思っていたら、そんなに最初からうまくいかないもので、実行してみたところ、ジョブは成功してデータはできているもののData targetのテーブルは想定通りにパーティショニングされませんでした。そのテーブルのs3のロケーションにsale_dateごとのディレクトリができていて欲しかったのですが、されていません。
どうもこのやり方で自動的にETL処理してくれる内容ではパーティショニングに対応してくれないようです。
AthenaからSQLでデータロード
パーティショニング対応どうするのかと、そもそもSQLでできないものかと思って調べたところ、AthenaからGoverned tableを作成できることがわかりました。
ここでも落とし穴があって、AthenaでGoverned tableと連携するためには、まずAthenaで「AmazonAthenaLakeFormation」という名前のワークグループを手動で作成しておく必要があります(ドキュメント読み込まないと気が付かないです・・)。
パーティショニングがうまくいかなかったので、Data sourceのテーブルも最初からパーティショニングしておかないといけないのかと思い、Governed tableでない通常のテーブルとしてパーティショニングされたテーブルを新たに作ることにしました。
CREATE TABLE iowa_liquor_sales_original_partitioned WITH ( format = 'PARQUET', write_compression = 'SNAPPY', partitioned_by = ARRAY['sale_date'] ) AS SELECT invoice_item_number ,store_number ,store_name ,address ,city ,zip_code ,store_location ,county_number ,county ,category ,category_name ,vendor_number ,vendor_name ,item_number ,item_description ,pack ,bottle_volume ,state_bottle_cost ,state_bottle_retail ,bottles_sold ,sale ,volume_sold_liters ,volume_sold_gallons ,sale_date FROM iowa_liquor_sales_original ;
AthenaからCTAS(CREATE TABLE AS SELECT)文を実行したら、100個以上のパーティションはダメと怒られてしまいました・・。
HIVE_TOO_MANY_OPEN_PARTITIONS: Exceeded limit of 100 open writers for partitions/buckets.
そこで、sale_dateカラムをそのままパーティションキーにするのはやめて、月単位に切り出したsale_monthというカラムを新たに作ってやってみることにします。先ほどつけ忘れたんですが、s3上の場所を指定するプロパティも入れておきます。
CREATE TABLE iowa_liquor_sales_original_partitioned
WITH (
format = 'PARQUET',
write_compression = 'SNAPPY',
partitioned_by = ARRAY['sale_month'],
external_location = 's3://lakeformation-tokyo/datalake/iowa_liquor_sales_original_partitioned/'
)
AS SELECT
invoice_item_number
,sale_date
,store_number
,store_name
,address
,city
,zip_code
,store_location
,county_number
,county
,category
,category_name
,vendor_number
,vendor_name
,item_number
,item_description
,pack
,bottle_volume
,state_bottle_cost
,state_bottle_retail
,bottles_sold
,sale
,volume_sold_liters
,volume_sold_gallons
,date_trunc('month', sale_date) sale_month
FROM iowa_liquor_sales_original
;
このSQLは成功しました!
Data targetとなるGoverned tableも以下のSQLで作成できました。
CREATE TABLE iowa_liquor_sales( invoice_item_number STRING, sale_date DATE, store_number INTEGER, store_name STRING, address STRING, city STRING, zip_code INTEGER, store_location STRING, county_number INTEGER, county STRING, category STRING, category_name STRING, vendor_number INTEGER, vendor_name STRING, item_number INTEGER, item_description STRING, pack INTEGER, bottle_volume INTEGER, state_bottle_cost STRING, state_bottle_retail STRING, bottles_sold INTEGER, sale STRING, volume_sold_liters FLOAT, volume_sold_gallons FLOAT ) PARTITIONED BY (sale_month DATE) STORED AS PARQUET LOCATION 's3://xxxxx/datalake/iowa_liquor_sales/' TBLPROPERTIES ( 'table_type'='LAKEFORMATION_GOVERNED', 'classification'='parquet' );
テーブルプロパティが独自の書き方ですが、SQLで書けるのは管理しやすくて良いですね。
Data sourceとData targetのテーブルを再度作り直したところで、Athenaからデータロードを試みたんですが、結論、できませんでした。。Governed tableでなければ大丈夫なんですが、Governed tableだと色々と制限に引っかかってダメでした。Athenaではテーブル作成と、参照クエリが基本になりそうです。
Glue Studioでジョブ(Spark script editor)でデータロード
ここでまたGlueから何とかしようと考えて、Visualでやるのは諦めて、自分でスクリプトを書くことにしました。
Glue Studioのコンソール画面のサイドメニューで「Jobs」を選び、Create jobのセクションにある「Spark script editor」にチェックを入れて「Create」ボタンを押します。
スクリプトの編集画面になるので、あとはここにコードを書くだけです。
Spark script editorと言っておきながらSparkでなくてGlueを理解する必要がありました。。最初わからなくて(Glue初心者のため)、PySparkのコードでSparkSQLをメインに書いたんですがうまくいかず、試行錯誤してGlueのDynamicframeを使った書き方を検証しました。GlueのDynamicframeとSparkのDataframeは恐らく似ているんでしょうが違うもので、DynamicframeではSparkSQLをそのまま使えません。
また、Governed tableの目的であるACIDトランザクション対応のために、トランザクション処理を入れる必要があり、これがすぐにわからずハマりました。このトランザクション処理が必要なために、今のところAthenaでGoverned tableへの書き込みができないんだと思います(つまり、Governed tableへの書き込みは毎回コードを書かないといけない)。
色々書き方を試したんですが、ジョブが成功してもなかなかデータロード後にData targetのGoverned tableがパーティショニングされた状態にならず、ようやく辿り着いたのが以下の書き方です。
import sys
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from pyspark.sql import functions
from pyspark.sql.functions import *
from pyspark.sql.types import *
from awsglue.context import GlueContext
from awsglue.job import Job
from awsglue.dynamicframe import DynamicFrame
## from awsglue import DynamicFrame
## @params: [JOB_NAME]
args = getResolvedOptions(sys.argv, ['JOB_NAME'])
sc = SparkContext()
glueContext = GlueContext(sc)
spark = glueContext.spark_session
job = Job(glueContext)
job.init(args['JOB_NAME'], args)
dyf = glueContext.create_dynamic_frame.from_catalog(
database="datalake",
table_name="iowa_liquor_sales_original_partitioned",
additional_options={"partitionKeys":["sale_month"]}
)
txid = glueContext.start_transaction(read_only=False)
sink = glueContext.getSink(
connection_type="s3",
path="s3://xxxxx/datalake/iowa_liquor_sales/",
enableUpdateCatalog=True,
partitionKeys=["sale_month"],
updateBehavior="LOG",
transactionId=txid
)
sink.setFormat("glueparquet")
sink.setCatalogInfo(catalogDatabase="datalake", catalogTableName="iowa_liquor_sales")
try:
sink.writeFrame(dyf)
glueContext.commit_transaction(txid)
except:
glueContext.cancel_transaction(txid)
raise
job.commit()
Data targetのGoverned tableへの書き込みは、glueContext.getSinkにしてフォーマットを「glueparquet」にしないと、うまくパーティショニングされて、且つAthenaからのクエリで上手く参照できませんでした。glueContext.write_dynamic_frame.from_catalogでも書き込めてパーティショニングされましたが、テンポラリー的なディレクトリが作成されてしまい、そのためにAthenaからはうまく参照できていないようでした。
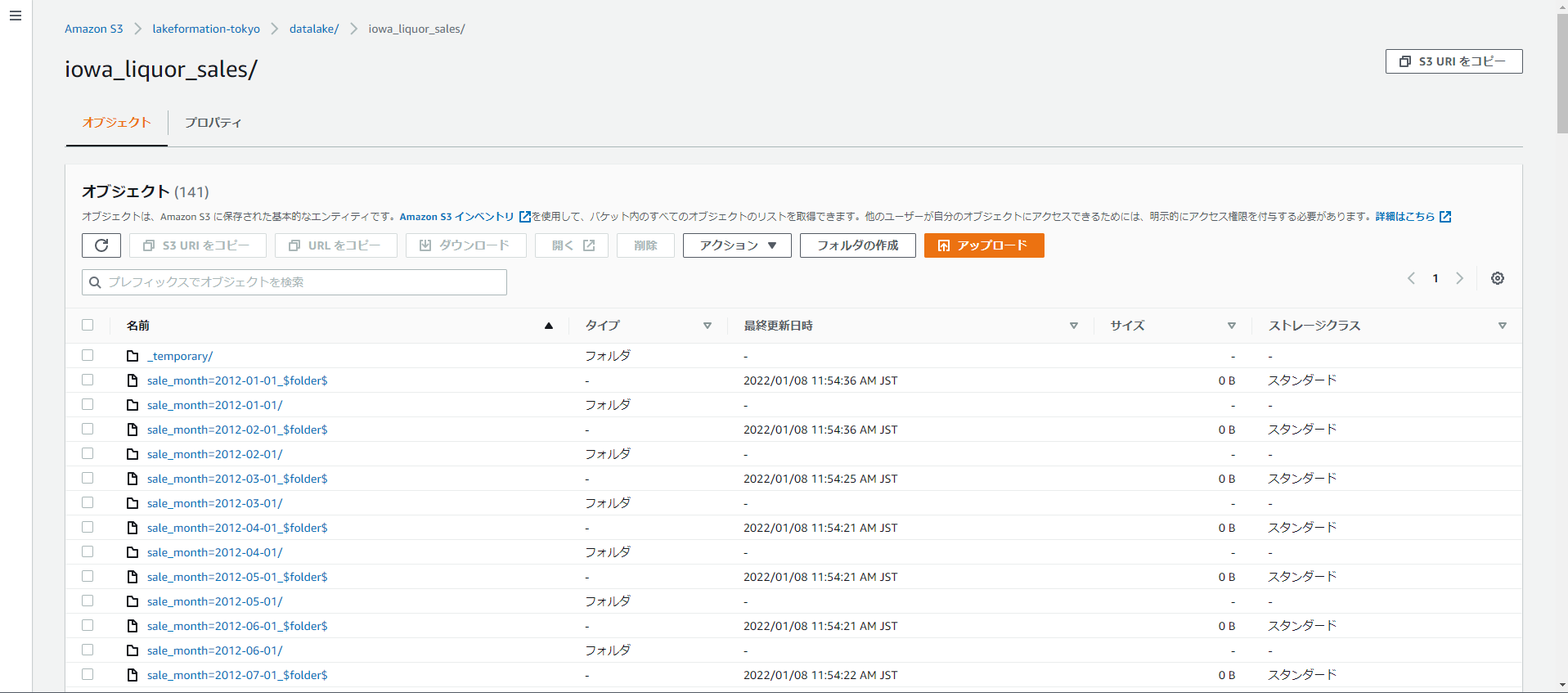
参考までに、glueContext.write_dynamic_frame.from_catalogで書くときのコードは以下です。
try:
glueContext.write_dynamic_frame.from_catalog(
frame=dyf,
database="datalake",
table_name="iowa_liquor_sales",
additional_options={"partitionKeys":["sale_month"], "transactionId":txid}
)
glueContext.commit_transaction(txid)
毎度のことながら初めての技術で色々ハマりましたが、AWS Lake Formationを使った分散処理の検証ができました!
コンピュートノードとストレージノードを分離した分散処理をGCPとAWSで比較
これまでの技術ブログの検証を通して、コンピュートノードとストレージノードを分離した分散処理(Spark/PySpark)について、GCPとAWSで比較してみました。あくまで主観なのでご参考程度に。
構成:
| GCP | AWS |
|---|---|
| Dataproc on GKE(β版)、Dataprocメタストア、GCS、 BigQuery | AWS Lake Formation (Glue、s3)、Athena |
権限管理:
| GCP | AWS |
|---|---|
| IAM、およびGCSのバケット単位の認可。評価×。 | IAM、およびLake Formationによる認可。Lake Formationではs3上のデータベース、テーブル単位で認可を一元管理できる。評価△×。 |
メタデータ連携:
| GCP | AWS |
|---|---|
| Dataprocメタストアと上手く連携できなかったのもあり、評価×。 | Glueカタログが統合されているので楽ちん。評価〇。 |
料金:
| GCP | AWS |
|---|---|
| Dataprocメタストアが高い。BigQueryもストレージコストの方が高くつきがち。あとはそうでもない。評価△。 | Glueによる処理を使いすぎると高くつくかもしれないが、他はそうでもない。評価〇。 |
処理の書きやすさ:
| GCP | AWS |
|---|---|
| PySpark(+SparkSQL)のみで書けるのは良い。ただVisualでやれるものがない。評価△×。 | Glue Studioを使えば、VisualでETL処理が書ける。パーティショニングされたGoverned tableはVisualではうまくいかなかった。SparkスクリプトはGlueの理解と作法を知らないと(DataframeとDynamicframeの違いなど)動かない。評価△×。 |
実行のしやすさ:
| GCP | AWS |
|---|---|
| 毎回Cloud ShellからPySparkプログラムをspark-submit(gcloud dataproc jobs submit pyspark)を行う必要がある。評価△。 | Glue Studioで簡単にジョブがVisualで作れて実行できる。スクリプトを書くジョブも管理しやすい。評価〇。 |
データアクセス:
| GCP | AWS |
|---|---|
| GCS上のデータに対して、BigQueryの外部テーブルを作成すれば、スムーズに連携できる。評価△(処理速度は◎)。 | Glueカタログを使っていれば外部テーブル作成不要でAthenaと自動で連携できる。ただ、Governed tableはできないことが多くわかりにくい。AthenaはHiveQLとPrestoのSQLが混ざるので慣れるまで混乱する。評価△×。 |
ACIDトランザクション対応:
| GCP | AWS |
|---|---|
| 対応していない。Cloud Storage Connectorの協調的ロック(cooperative locking)を活用すれば部分的にできるかも(未検証)。評価×。普通のDataprocならDelta Lakeを使えばできる(以前のブログ参照)。 | Governed tableを使えばACIDトランザクションに対応できる。ただ、使いづらいところが多い。評価△。 |
ログの見やすさ:
| GCP | AWS |
|---|---|
| ログエクスプローラーから自分で探す必要があり、ちょっとわかりずらい。評価△(好みと慣れの問題かも)。 | Glue Studioからジョブ実行時に、簡単にCloudWatchに飛んで関連ログが見やすいので、評価〇。 |
その他イケてる点:
| GCP | AWS |
|---|---|
| なんといってもBigQuery。ビッグデータに対してSQL的に書く処理なら圧倒的(圧倒的なために処理をなんでもBigQueryに寄せようとするのには否定的です)。 | Glue StudioのVisualでできるところや、料金も設計しやすく、全体的にやりやすいと思う。 |
その他イケてない点:
| GCP | AWS |
|---|---|
| テーブル定義などのメタデータについて、GCPのData CatalogはGlueカタログほど統合されてない/便利でない/安くない印象。AWS Lake Formationのようにコンピュートノードとストレージノードを分離する分散処理を統合する製品がない。 | Glue独自の実装を習得しないといけないのと、Governed tableの操作をAthenaであまりできない点。Athenaによる操作をLake Formationにもっと統合してくれたら便利。AthenaはBigQueryほどの応答速度はなく、Prestoの独自拡張?などで頑張ってくれると嬉しい。 |
おまけ:
| GCP | AWS |
|---|---|
| AWS Lake Formationと比較するならCloud Dataflow (+Data Catalog)の方が適切だったかも。ただ、Cloud DataflowはApach Beamの実装でPySparkみたいにSQL的に書けない。 | - |
まとめ
今回の検証をまとめると、
- Spark/PySparkをベースにしたビッグデータの分散処理を考えるなら、AWS Lake Formation(+Glue Studio)は結構いいじゃん!
- あとは、
- Governed tableのACIDトランザクション対応はとても良いので、もっと扱いやすくして
- Athenaの応答速度をもうちょっと頑張って
といったところでしょうか。個人的にはAWSもGCPもどちらもIAM管理の最初のわかりにくさを何とかしてほしいものです。
今回の検証ではできなかったですが、
今後の課題:
- AWS Lake FormationのGoverned tableのACIDトランザクションを、より本番を想定したワークロードで検証
- 本番を想定したワークロードでLake Formationを使ったときの料金計算の見積もり
- GCPのCloud Dataflow(Apache Beamの実装)を検証
- 本番を想定したIAMとLake Formationの権限管理を考える
などをいつかやってみたいと思います。
最後に
次世代システム研究室では、データサイエンティスト/機械学習エンジニアを募集しています。ビッグデータの解析業務など次世代システム研究室にご興味を持って頂ける方がいらっしゃいましたら、ぜひ 募集職種一覧 からご応募をお願いします。皆さんのご応募をお待ちしています。
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD