2022.01.12
Universal Sentence Encoderによる文章埋め込みの紹介と、転移学習への有用性の検証
こんにちは。次世代システム研究室のS.Y.です。なんだかお堅そうなタイトルですが、今回はNLPネタです。
NLPの分野ではコンピュータに言語を理解させ、人間のように高度な言語認識・処理を行わせることが大きな目標の一つです。
近年の機械学習モデルベースなNLP手法は世界中の文書コーパスを学習データとすることで、高度で複雑な言語表現空間の獲得に成功し、文書分類・質問応答・含意関係認識(NLI)など様々なタスクで成果を上げています。
一方で実社会の企業・機関にとっては、それぞれに固有なタスクのために巨大な規模のデータセットを用意することは容易ではありません。そこで近年、巨大なコーパスで事前学習したモデルを使った転移学習の需要が高まっています。
転移学習に有用な埋め込みベクトルを獲得する手法として、2018年にgoogleから発表されたUniversal Sentence Encoder[1](USE)があります。
この記事ではまずUSEの論文紹介を行います。そして、論文中では触れられていなかったUSEと他の文書埋め込み手法の比較を行い、USEで得られた埋め込みがどの程度転移学習に有用なのかを検証します。
論文紹介 | 文章埋め込み
従来の文章埋め込みの方法は、文章中の各単語の埋め込みベクトルの平均をとるというものでした。この方法には主に二つの問題点があります。
一つは、たとえ文章中で使われた時とは違う意味の単語であっても、単語ベクトルと文章全体のベクトルの類似度が高くなることがあるという問題です。例えば’It is cool’といった文章と’It’という単語の類似度を測った時、前者の形式主語としてのItと後者の代名詞としてのItだと意味が違いますが、実際に単語埋め込みから算出される類似度は高くなってしまいます。
もう一つは、語順を考慮できないという問題です。’It is cool’と’Is it cool’だと意味が明らかに違いますが、単語ベクトルの平均をとると同じになってしまいます。
TF-IDFやn-gramなどを適用することでも上記の問題にある程度マニュアル的に対応することができますが、USEでは文中の単語の意味や語順を考慮した文章ベクトルを、ニューラルネットワークによるend-to-endな学習で獲得します。
論文紹介 | 文章ベクトルの獲得と2種類のencoder
USEでは文章のベクトルを得るために、文脈を考慮した各単語のベクトルを足し込み、文章の長さで正規化します。
文脈を考慮した単語のベクトルを得る方法として、Transformer Encoderを用いる方法とDeep Averaging Network(DAN)を用いる方法の2種類を提案しています。これらの方法は、精度と計算速度のトレードオフの関係になります。
次節はそれぞれのencoderの簡単な説明ですが、これら自体にオリジナリティはありませんので、既に理解されている方は学習の章まで読み飛ばしてください。
Transformer Encoder
読んで字の如く、Transformerモデルのencoder部分を利用して単語の埋め込みベクトルを獲得します。
Transformerモデルは2017年に発表されたAttention Is All You Need[2]の論文で提案された翻訳モデルで、Attention機構によって文中の単語同士の関係を双方向に学習し、文脈を考慮した翻訳が可能です。
Attention機構自体はTransformerが初出ではなく、以前からCNNやRNNとAttentionを組み合わせたNLPモデルが提案されていますが、TransformerはAttentionのみを用いることで単語毎の処理の並列化を可能にし、尚且つ当時のSOTAを達成したことから、以降のNLPに絶大なインパクトを与えました。
Transformerのencoder部分のattentionはself-attentionと呼ばれ、文章中のそれぞれの単語について、その単語が文中の他のそれぞれの単語とどの程度関係があるかを元に、埋め込みベクトルを獲得します。
self-attentionではまず、入力された文章からQuery (Q), Key (K), Value (V)というマトリックスをそれぞれ作成します。それぞれのマトリックスのm行目は、文中のm番目の単語のqeuryベクトル、keyベクトル、valueベクトルです。queryとkeyは単語の関係度合いの計算に使用し、valueは埋め込みベクトルそのものです。
self-attentionは、得られたマトリックスで以下を計算して得られます。
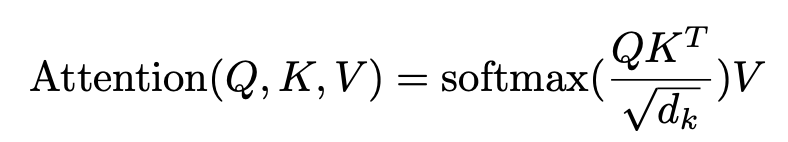
softmaxの結果得られるマトリックスのm行n列目の要素は、m番目の単語とn番目の単語がどの程度関係しているかを表しています。これを使って各単語は、文中の単語のvalueの重み付き和として表現されます。自身のベクトルに、関係が強い他の単語のベクトルを焼き付けるイメージですね。
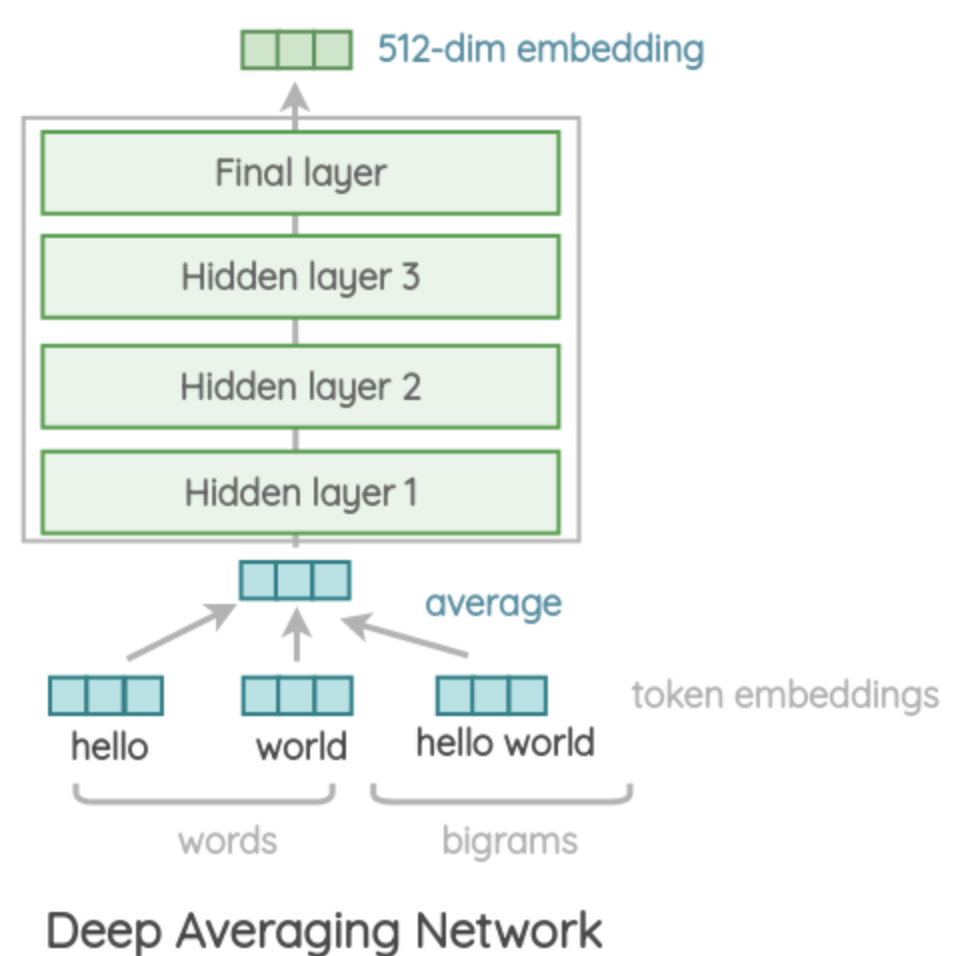
Deep Average Network Encoder
DANはある文章について、各単語とbi-gramの埋め込みベクトルを算出し、それらのaverageなベクトルをMLPを通して固定長のベクトルへと変換します。DANは各単語とbi-gramの埋め込みを学習します。
bi-gramの情報を含めることで、語順や単語同士の関係を考慮することができます。
論文紹介 | USEの学習
転移学習に有用な文章ベクトルを獲得するため、USEは3種類のNLPタスクをdown streamとしたmulti-task learningで学習します。
- Modified Skip-Thought: Unsupervised. 入力された文の、前後の文を予測する。
- Conversational Input-Response Prediction Permalink: Unsupervised. 質問文に対して適切な返答文を予測する。
- Natural Language Inference: Supervised. 前提文を与えられ、仮説文が矛盾しているかを予測する。
NLIの学習データにはStanford Natural Language Inferenceコーパスを使用し、Unsupervisedな学習データにはWikipedia, web news, web question-answer page, discussion forum等、幅広いwebソースを使用します。
論文紹介 | 評価
USEモデルについて、以下を評価します。
- 得られたベクトルについて、様々なNLPタスクの転移学習で高い精度を出せるか。
- 得られたベクトルについて、転移学習のサンプルデータが少ない場合でも高い精度を出せるか。
- Resource Usage
転移学習するNLPタスクはsentence classification(MR, CR, SUBJ, MPQA, TREC)とsentence similarity(SST, STS Bench)です。sentence classificationではUSEのencoderの出力はtask specificなDNNに渡されます。sentence similarityではencoderの出力から直接コサイン類似度を計算します。
転移学習の精度
各タスクについて、USEの精度と比較対象なモデルの精度を表にしています。
USE_T, USE_Dはそれぞれ、encoderにTransformerとDANを用いたUSEです。
DANとCNNはそれぞれtask specifiedなword embeddingモデルです。w2v w.e.とタグ付けされたものは事前学習されたWord2Vecのembeddingを使用します。一方でlrn w.e.とタグ付けされたものは単語のembeddingをランダムに初期化し、転移学習中でのみこれらのembeddingを学習します。
USE+DANなモデルは、USEとDANのそれぞれの埋め込みベクトルをconcatenateし、down-streamなタスクの入力とします。
比較の表から、Sentence Embeddingを使用した転移学習の方が、Word Embeddingのみを使用する手に学習よりも精度が良いことが分かります。また、Sentence Embeddingな転移学習の中でも、Word Embeddingを同時に使用する方が精度が良くなります。
少ないサンプルでの精度
上の表は、SSTタスクの転移学習時のサンプル数を変化させた時の、各モデルの精度です。SST 1kからSST 67.3k(full size)に向かうにつれてサンプル数が多くなります。USEの事前学習ベクトルを使用すると、サンプル数が少ない段階から高い精度を出していることがわかります。
Resource Usage
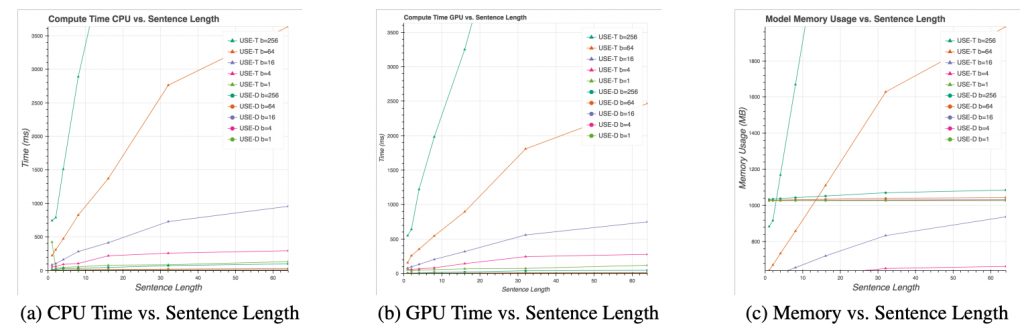
(a)と(b)は、文章の長さについてUSEの計算時間です。Transformer basedでは文章が長くなるほど計算時間が増える傾向にあり、batch sizeが大きくなるほど増え方の傾きが急になります。一方DAN basedの計算時間は文章の長さやbatch sizeにあまり左右されません。
(c)は文章の長さについてUSEのmemory使用量です。計算時間と同様に、Transformer basedは文章の長さとbatch sizeが増えるほど増大し、DAN basedはほぼ一定です。
ちなみに、理論上の計算時間・memory使用量は、Transformer basedがどちらもO(n2)でDAN basedがどちらもO(n)です。
実践 | 他の文章埋め込み手法との、転移学習への有用性の比較・検証
論文中では単語埋め込み手法に対する文章埋め込み手法(USE)の優位性は示されていましたが、USEと他の文章埋め込み手法との比較はされていませんでした。
USEの学習済みモデルはtensorflow hubで公開されています。
import tensorflow_hub as hub
embed = hub.load("https://tfhub.dev/google/universal-sentence-encoder/4")
embeddings = embed([
"The quick brown fox jumps over the lazy dog.",
"I am a sentence for which I would like to get its embedding"])
print(embeddings)
tf.Tensor( [[-0.03133017 -0.06338635 -0.016075 ... -0.03242778 -0.0457574 0.05370456] [ 0.05080863 -0.01652427 0.01573782 ... 0.00976659 0.0317012 0.01788119]], shape=(2, 512), dtype=float32)
この事前学習モデルを使って、カテゴリ分類のタスクを転移学習し、SBERTの事前学習モデルで転移学習した場合と比較してみます。
データはkaggleのnews-category-datasetを使って、descriptionの文章からニュースのcategoryを予測します。Binary ClassificationとMulti Classificationを試します。
Binary Classification
descriptionから、categoryがPoliticsか否かを判別します。
データ準備
各クラスをresamplingしたり、label encodingしたりといった前処理を行い、出来上がったトレーニングデータは32554件(各クラス16277件ずつ)です。
original_data = pd.read_json("News_Category_Dataset_v2.json", lines=True)
binary_dataset = original_data
from imblearn.under_sampling import RandomUnderSampler
sampler = RandomUnderSampler(random_state=42)
def encode_str(s):
return s.encode('utf-8')
s = original_data[original_data["short_description"]!='']
s['is_politics'] = np.where(s['category']== 'POLITICS', 1, 0)
s['short_description'] = s['short_description'].apply(encode_str)
X = s["short_description"]
y = s["is_politics"]
le = preprocessing.LabelEncoder()
y = le.fit_transform(y)
X_train, X_test, y_train, y_test = train_test_split(X, y,test_size = 0.2,random_state = 1)
train_examples = np.array(X_train)
train_labels = np.array(y_train)
test_examples = np.array(X_test)
test_labels = np.array(y_test)
original_partial_x_train = train_examples[:100000]
original_x_val = train_examples[100000:]
original_partial_y_train = train_labels[:100000]
original_y_val = train_labels[100000:]
resampled_x_train, resampled_y_train = sampler.fit_resample(original_partial_x_train.reshape(-1, 1), original_partial_y_train)
resampled_x_val, resampled_y_val = sampler.fit_resample(original_x_val.reshape(-1, 1), original_y_val)
resampled_x_test, resampled_y_test = sampler.fit_resample(test_examples.reshape(-1, 1), test_labels)
resampled_y_train = np_utils.to_categorical(resampled_y_train)
resampled_y_val = np_utils.to_categorical(resampled_y_val)
resampled_y_test = np_utils.to_categorical(resampled_y_test)
モデル定義・学習 (USE)
tensorflow hubからUSEのkerasレイヤーをdownloadし、そこにdown-streamとしてfull connectedを1層繋げたモデルで転移学習します。
import tensorflow_hub as hub
hub_layer = hub.KerasLayer("https://tfhub.dev/google/universal-sentence-encoder/4", input_shape=[], dtype=tf.string, trainable=False)
bin_model = tf.keras.Sequential()
bin_model.add(hub_layer)
bin_model.add(tf.keras.layers.Dense(64, activation='relu'))
#model.add(tf.keras.layers.Dense(1))
bin_model.add(tf.keras.layers.Dense(len(le.classes_)))
bin_model.summary()
bin_model.compile(optimizer='adam',
loss=tf.losses.CategoricalCrossentropy(from_logits=True),
metrics=[tf.metrics.CategoricalAccuracy(name='categorical_accuracy')])
history = bin_model.fit(resampled_x_train,
resampled_y_train,
epochs=100,
batch_size=512,
validation_data=(resampled_x_val, resampled_y_val),
verbose=1)
results = bin_model.evaluate(resampled_x_test, resampled_y_test)
モデルのsummaryとテストの結果は下記の通りです。
100回学習させると過学習しますが、最終的なtest accuracyは0.82まで上がりました。
_________________________________________________________________ Layer (type) Output Shape Param # ================================================================= keras_layer (KerasLayer) (None, 512) 256797824 _________________________________________________________________ dense_2 (Dense) (None, 64) 32832 _________________________________________________________________ dense_3 (Dense) (None, 2) 130 ================================================================= Total params: 256,830,786 Trainable params: 32,962 Non-trainable params: 256,797,824 _________________________________________________________________
[0.5384117960929871, 0.8210849165916443]
埋め込みベクトル獲得・モデル定義・学習 (SBERT)
前項のUSEと同程度のパラメータのfull-connectedモデルで、USEと同様の条件で学習させます。こちらはSBERTによるencodingとモデルによる予測が独立しているため、descriptionを予めSBERTでベクトルに変換します。
from sentence_transformers import SentenceTransformer
sbert_model = SentenceTransformer('paraphrase-MiniLM-L6-v2')
embed_resampled_x_train = sbert_model.encode(resampled_x_train.reshape(-1))
embed_resampled_x_val = sbert_model.encode(resampled_x_val.reshape(-1))
embed_resampled_x_test = sbert_model.encode(resampled_x_test.reshape(-1))
bin_model = tf.keras.Sequential()
bin_model.add(tf.keras.layers.Dense(64, activation='relu', input_shape=(384,)))
bin_model.add(tf.keras.layers.Dense(64, activation='relu'))
bin_model.add(tf.keras.layers.Dense(len(le.classes_)))
bin_model.summary()
bin_model.compile(optimizer='adam',
loss=tf.losses.CategoricalCrossentropy(from_logits=True),
metrics=[tf.metrics.CategoricalAccuracy(name='categorical_accuracy')])
history = bin_model.fit(embed_resampled_x_train,
resampled_y_train,
epochs=100,
batch_size=512,
validation_data=(embed_resampled_x_val, resampled_y_val),
verbose=1)
results = bin_model.evaluate(embed_resampled_x_test, resampled_y_test)
モデルのsummaryとテストの結果は下記の通りです。
最終的なtest accuracyは0.60で、USEの結果と比べるとだいぶ低いですね。
_________________________________________________________________ Layer (type) Output Shape Param # ================================================================= dense (Dense) (None, 64) 24640 _________________________________________________________________ dense_1 (Dense) (None, 128) 8320 _________________________________________________________________ dense_2 (Dense) (None, 2) 258 ================================================================= Total params: 33,218 Trainable params: 33,218 Non-trainable params: 0 _________________________________________________________________
[0.6628333926200867, 0.6050928831100464]
Multiclass Classification
同じデータセットからサンプル数が多い5種類のクラス(POLITICS, WELLNESS, ENTERTAINMENT, STYLE & BEAUTY, TRAVEL)を使って、multiclass classificationの精度も比較してみました。前処理やモデル定義のコードはbinary classificationと同様なので、model summaryとtest resultを載せます。
学習に使用したサンプルは各クラス6455ずつの、合計32275サンプルです。
結果のaccuracyはUSEが0.81、SBERTが0.60と、multiclass classificationでもUSEの転移学習は高い精度を示しました。
埋め込みベクトル獲得・モデル定義・学習 (SBERT)
_________________________________________________________________ Layer (type) Output Shape Param # ================================================================= keras_layer_1 (KerasLayer) (None, 512) 256797824 _________________________________________________________________ dense_2 (Dense) (None, 64) 32832 _________________________________________________________________ dense_3 (Dense) (None, 5) 325 ================================================================= Total params: 256,830,981 Trainable params: 33,157 Non-trainable params: 256,797,824 _________________________________________________________________
[0.5347756147384644, 0.817770779132843]
埋め込みベクトル獲得・モデル定義・学習 (USE)
_________________________________________________________________ Layer (type) Output Shape Param # ================================================================= dense (Dense) (None, 64) 24640 _________________________________________________________________ dense_1 (Dense) (None, 128) 8320 _________________________________________________________________ dense_2 (Dense) (None, 2) 258 ================================================================= Total params: 33,218 Trainable params: 33,218 Non-trainable params: 0 _________________________________________________________________
[0.6628333926200867, 0.6050928831100464]
fine tuningした場合の精度
Keras Layerとして提供されているUSEについては、USEのパラメータも含めてのfine tuningという形でmulticalss classificationのタスクを学習させた場合の精度も測りました。結果のaccuracyは0.80と転移学習とほぼ変わらないことから、USEは事前学習の時点で汎用的なembeddingを獲得していることが確認できました。
_________________________________________________________________ Layer (type) Output Shape Param # ================================================================= keras_layer (KerasLayer) (None, 512) 256797824 _________________________________________________________________ dense (Dense) (None, 64) 32832 _________________________________________________________________ dense_1 (Dense) (None, 5) 325 ================================================================= Total params: 256,830,981 Trainable params: 256,830,981 Non-trainable params: 0 _________________________________________________________________
[0.9939566850662231, 0.809779167175293]
まとめ
今回は文書埋め込み手法のUniversal Sentence Encoderの論文紹介と、USEのウリである転移学習の有用性を検証しました。
USEでは、文脈を考慮した単語の埋め込みを平均して固定長のベクトルを作り、それを様々なdown-streamタスクと繋いで学習させることで、汎用的な文章埋め込みベクトルを獲得します。単語の埋め込みを獲得するencoder部分は、精度重視のTransformer Encoderと速度重視のDAN Encoderの2種類あります。
後半に行った検証では、映画のdescriptionを特徴量としたテゴリ分類タスクへの転移学習を実践し、同じく文章埋め込み手法であるSBERTで転移学習した場合と比較して、USEがNLPタスクの転移学習に有用であることを確認しました。USEの事前学習モデルはtensorflow hubからKelas Layerとして読み込むことができ、転移学習やfine tuningも簡単にできるので、非常に使いやすいです。
最近だとUSEをteacherとしたknowledge distillation手法や、複数言語に対応したモデルも提案されていて、NLPの発展と社会実装により一層期待できそうですね。
最後に
出典
Universal Sentence Encoder [1]
Attention Is All You Need [2]
Universal Sentence Encoder Visually Explained [3]
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD