2018.07.04
多変量RNNでFXレートの予想精度は上がるか?【Google Colaboratory】
こんにちは。次世代システム研究室のK.N.です。
業務で金融データを触っているうちに、「この経験を生かせば自分でもお金儲けができるんじゃ…」なんて錯覚を起こしてしまうことがあったりなかったり。
そんな自分に現実を見せつつ、ちょっと勉強にもなりそうなテーマをやってみたいと思います。
キーワードはこちら
- Google Colaboratory
- Keras
- RNN
- 多変量
- FX(!!!)
というわけで、FXでディープラーニングしてみたいと思います。
FX+DNNだけだとやってる人たくさんいそうなので、複数のプライスを使ってみます。
さらに一度触ってみたかった、無料でGPUが使えるGoogle Colaboratory環境でやってみます。
概要
データについて
今回扱うのは、Kaggleの「Foreign Exchange (FX) Prediction – USD/JPY」データです。

これはカラムの説明がなかったのですが、4つの会社が出しているドル円の1分ごとのレートを並べたもの、と推測できますね。
レートを出す会社も、真のレートがわかるわけではないので、各社で「このくらいでしょう」みたいなものを考えて決めてるんだと思います。
trainは31,442サンプル、testは59サンプルありました。
RNNは変数が0~1の間を取っていないとうまく動かないので、あとで正規化をしてあげましょう。
目的
シンプルに、4社のレートを予測して、その精度を出してみたいと思います。
実際の売買戦略とか考えるなら、各社同一スプレッドを仮定してーとか売買モデルを考えてーとか損切りがーとかあると思うんですが、今回はそういった余分な要因は排除しましょう。
モデル
今回は深層学習のモデルを使います。
時系列データなので、LSTMとQRNNの比較もします。
これらの手法の中身は、先人たちがたくさん書いてくださってるのでそちらをご参照頂ければ。
環境
Google ColaboratoryのPython2ランタイムを使います。
やってみる
環境構築
ノートブック作成
といっても大してやることはなくて、
- Googleアカウント作成
- Googleドライブ内で「右クリック>その他>アプリを追加」からColaboratoryを追加?(ちょっと曖昧なのでググっていただければ)
- お好みのディレクトリで右クリック>その他>Colaboratory
以上でノートブック作成完了。
Googleアカウントさえ持ってれば一分で終わりますね。。
作成したノートブックを開きましょう。
ツールバーの「ランタイム>ランタイムのタイプを変更」で好きな環境を選べばOK。
Kaggleからデータ入手
KaggleのAPIを使うために、インストールや認証が必要になります。
こちらは丁寧に説明してくださっている記事を見つけたので、リンクを貼らせて頂きますね。
Google Colaboratory で始める Kaggler 生活(データ入手と提出編)
ここの「4. Google ドライブから Colaboratory 上に kaggle.json をダウンロード」までを行い、データ入手準備が整います。ありがとうございます。
ダウンロードは
!kaggle datasets download -d team-ai/foreign-exchange-fx-prediction-usdjpy
のように入力するとできます。
ダウンロード先が出力に書かれているので確認しましょう。
参考記事そのままでやっていると、
/content/.kaggle/datasets/team-ai/foreign-exchange-fx-prediction-usdjpy
にダウンロードされると思います。
ファイル名にスペースや括弧が入っていて扱いずらいので、名前を変えてあげます(お好みで)。
!mv /content/.kaggle/datasets/team-ai/foreign-exchange-fx-prediction-usdjpy/FX_USDJPY_201701till01312259_Train\ -\ USDJPY_201701till01312259\ \(1\).csv /content/.kaggle/datasets/team-ai/foreign-exchange-fx-prediction-usdjpy/FX_USDJPY_train.csv
!mv /content/.kaggle/datasets/team-ai/foreign-exchange-fx-prediction-usdjpy/FX_USDJPY_201701312300_Test\ -\ USDJPY_201701312300\ \(1\).csv /content/.kaggle/datasets/team-ai/foreign-exchange-fx-prediction-usdjpy/FX_USDJPY_test.csv
RNNの準備
今回はKerasを使います。
ColaboratoryはKerasがデフォルトで入っているので、インストールなどは必要ないのですが、QRNNはKerasに実装されていないので、GitHubに公開されているものを利用させてもらいます。ありがとうございます。
このQRNNを入れる際、theanoがインストールされていないと怒られる場合は、
!pip install theano
でインストールしてあげましょう。
(おまけ)Googleドライブとのファイル共有準備
Colaboratoryは一定時間でランタイムが閉じてしまい、それまでの変数やローカルファイルが消えてしまいます。
必須ではないですが、ドライブとのファイルのやり取りを行う関数を準備しておくとよいかもしれません。
# coding: utf-8
# Install the PyDrive wrapper & import libraries.
# This only needs to be done once per notebook.
!pip install -U -q PyDrive
from pydrive.auth import GoogleAuth
from pydrive.drive import GoogleDrive
from google.colab import auth
from oauth2client.client import GoogleCredentials
# Authenticate and create the PyDrive client.
# This only needs to be done once per notebook.
auth.authenticate_user()
gauth = GoogleAuth()
gauth.credentials = GoogleCredentials.get_application_default()
drive = GoogleDrive(gauth)
def upload_file(fname, data):
uploaded = drive.CreateFile({'title': fname})
uploaded.SetContentString('\n'.join([','.join(x.astype(str)) for x in data.values]))
uploaded.Upload()
print('Uploaded file with ID {}'.format(uploaded.get('id')))
def download_file(id, fname):
downloaded = drive.CreateFile({'id': id})
downloaded.GetContentFile(fname)
download_fileのid引数は、ドライブのダウンロードしたいファイルを右クリックして、「リンクの共有」を選択したときに出てくるURLの、id=の後の部分です。
これで環境準備は完了です!
インポート・データ読み込み・整形
必要なライブラリのインポートなどをまとめてやってしまいます。
# coding: utf-8 from keras.layers import Input, Dense, LSTM from keras.models import Model import pandas as pd import numpy as np import os from keras.models import Sequential from keras.layers.core import Dense, Activation from keras.layers.recurrent import LSTM from keras.optimizers import Adam from keras.callbacks import EarlyStopping dir_name = '/content/.kaggle/datasets/team-ai/foreign-exchange-fx-prediction-usdjpy/' import matplotlib.pyplot as plt %matplotlib inline
データの読み込みはpandasで。
# coding: utf-8 train_df = pd.read_csv(os.path.join(dir_name,'FX_USDJPY_train.csv'), names=['date', 'time', 'price_0', 'price_1', 'price_2', 'price_3']) test_df = pd.read_csv(os.path.join(dir_name,'FX_USDJPY_test.csv'), names=['date', 'time', 'price_0', 'price_1', 'price_2', 'price_3'])
次に正規化です。
Scikit-learnのMinMaxScalerを使いましょう。
testデータも正規化しないといけないので忘れずに。
# coding: utf-8 from sklearn.preprocessing import MinMaxScaler mms = MinMaxScaler() mms.fit(pd.concat([train_df, test_df], axis=0).drop(['date', 'time'], axis=1)) train = mms.transform(train_df.drop(['date', 'time'], axis=1)) test = mms.transform(test_df.drop(['date', 'time'], axis=1))
こんな感じになりました。
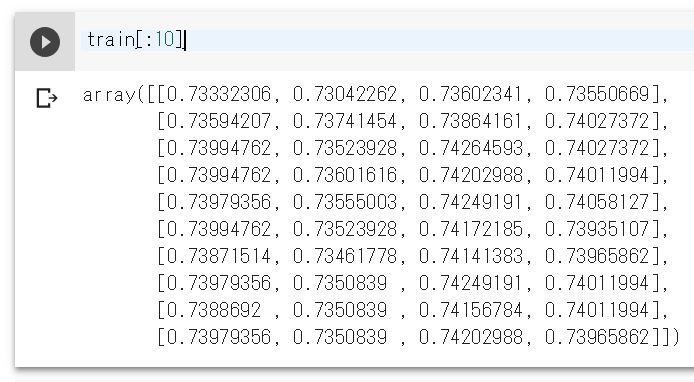
これをさらにRNN用の入出力に整形しましょう。
n分間×4プライスを説明変数とし、次の時刻の4プライスを目的変数とします。
(実際の取引などに使う場合は、数分後とか数時間後とかの方が適切ですね。)
今回は直前2時間を使いたいと思います。
また、あとで評価に使うため、trainとtestをまとめたデータも作っておきます。
# coding: utf-8
def make_data(price_data, window):
inp, out = [], []
for i in range(len(price) - window):
inp.append(price[i:i + window])
out.append(price[i + window])
X = np.array(inp).reshape(len(inp), window, price.shape[1])
y = np.array(out).reshape(len(out), price.shape[1])
return X, y
X, y = make_data(train, window=120)
X_all, y_all = make_data(np.concatenate([train, test]), window=120)

31,442サンプルから120分幅を取ったので、問題なさそうですね。
学習
いよいよRNNを使って学習していきます。
今回はLSTMとQRNNについて、1変量の場合と4変量の場合でそれぞれ学習・予測を行います。
それぞれのモデル作成部分は、【Python】QRNNでカオス時系列データ予測【Keras】を参考に一部改変して使わさせていただいています。ありがとうございます。
# coding: utf-8
rnn_1 = create_rnn_model(X.shape[1], 1)
early_stopping = EarlyStopping(monitor='val_loss', mode='auto', patience=20)
rnn_1.fit(X[:,:,:1], y[:,:1],
batch_size=300,
epochs=100,
validation_split=0.1,
callbacks=[early_stopping]
)
pred_rnn_1 = rnn_1.predict(X_all[:,:,:1])
rnn_4 = create_rnn_model(X.shape[1], 4)
early_stopping = EarlyStopping(monitor='val_loss', mode='auto', patience=20)
rnn_4.fit(X, y,
batch_size=300,
epochs=100,
validation_split=0.1,
callbacks=[early_stopping]
)
pred_rnn_4 = rnn_4.predict(X_all)
qrnn_1 = create_qrnn_model(X.shape[1], 1)
early_stopping = EarlyStopping(monitor='val_loss', mode='auto', patience=20)
qrnn_1.fit(X[:,:,:1], y[:,:1],
batch_size=300,
epochs=100,
validation_split=0.1,
callbacks=[early_stopping]
)
pred_qrnn_1 = qrnn_1.predict(X_all[:,:,:1])
qrnn_4 = create_qrnn_model(X.shape[1], 4)
early_stopping = EarlyStopping(monitor='val_loss', mode='auto', patience=20)
qrnn_4.fit(X, y,
batch_size=300,
epochs=100,
validation_split=0.1,
callbacks=[early_stopping]
)
pred_qrnn_4 = qrnn_4.predict(X_all)
一変量の場合は最初の列のプライスを学習しています。
多変量の場合は全て使って学習し、評価の時に最初の列のプライスのみを見ます。
予測の際は、直前2時間を使うことにしました。testの予測も直前2時間を使っているので、説明変数は学習に使ったものが含まれていることに注意してください。
また、今回はtrainデータで学習・testデータで予測という2段階になっていますが、使っているモデルは追加学習が可能です。
実用の際には、新たなデータが来たらそれに合わせてモデル更新することもできますね。
ちなみにこのコード、GPUを使っても結構時間がかかります。QRNNだけやりたい方は、RNN部分はやらない方が良さそうです。
評価
さて、いよいよ評価していきます。今回はRMSEを使いましょう。
学習誤差と予測誤差をそれぞれ出します。
# coding: utf-8 n_test = len(test) y_train = y_all[:-n_test,:1] y_test = y_all[-n_test:,:1] pred_list_train = np.array([pred_rnn_1[:-n_test,0], pred_rnn_4[:-n_test,0], pred_qrnn_1[:-n_test,0], pred_qrnn_4[:-n_test,0]]) pred_list_test = np.array([pred_rnn_1[-n_test:,0], pred_rnn_4[-n_test:,0], pred_qrnn_1[-n_test:,0], pred_qrnn_4[-n_test:,0]]) from sklearn.metrics import mean_squared_error rmse_train = [np.sqrt(mean_squared_error(y_train, _y)) for _y in pred_list_train] rmse_test = [np.sqrt(mean_squared_error(y_test, _y)) for _y in pred_list_test]

これはちょっと疑いたくなるくらい良い結果ですね。。。
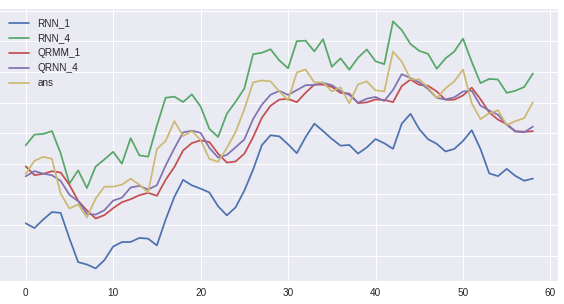
testのプロット結果はこの通り。収束判定が甘かったかもしれません。
とはいえRNN同士、QRNN同士では利用した変量の数以外は同条件でやっています。
今回のタイトルである、
【多変量RNNでFXレートの予想精度は上がるか?】
の答えはひとまずYesと言って良いのではないでしょうか!
【おまけ】Google Colaboratoryの感想
今回触ってみたいが為に使ったGoogle Colaboratory。
良い点不満点をまとめてみました。
【良い点】
- インストール不要
- アカウントとブラウザがあればどんな環境でも使えるのは強い。
- 無料でGPUが使える
- 面倒な設定もいらず、ただ切り替えるだけでGPUが使えるのはちょっと触ってみたいという人には最適かと。
- 使える機能の幅が広い
- 基本的なライブラリは入っているし、pipコマンドも使える。
【不満点】
- ショートカットが利用しにくい
- Jupyterのショートカットが使いたいときは、Ctrl+Mのあとに入力しないといけない。セルを消したあとに次のセルの編集状態になるのもかなり面倒
- キーの挙動が違う
- セル内でのキーの挙動が若干Jupyterと違うのがストレスになる…
- Googleドライブとの連携がやりにくい
- ローカルに保存すると消えてしまうのに、Googleドライブへの保存や読み込みが面倒。マウントすることもできるみたいだが、マウントの手続きも面倒。
ちなみにこの記事を書いている途中で全ての結果が消えました。
- ローカルに保存すると消えてしまうのに、Googleドライブへの保存や読み込みが面倒。マウントすることもできるみたいだが、マウントの手続きも面倒。
Jupyterと似せているのにちょっと違うところが、Jupyterに慣れている人間からするとストレスになるなという感じ。
基本的には「ちょっとPythonを触ってみたい」「ちょっとDNN on GPUを体験してみたい」という人が触るにはいいのかなーと感じました。
あと、Jupyterで作ったipynbファイルが使えるということで、コーディングはJupyterでやってGPUでの実行はColaboratoryに持ってくる、という変則的な使い方も可能かと思います。
最後に
次世代システム研究室では、ビッグデータ解析プラットホームの設計・開発を行うアーキテクトとデータサイエンティストを募集しています。興味を持って頂ける方がいらっしゃいましたら、ぜひ 募集職種一覧からご応募をお願いします。
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD