2020.04.08
Graph Neural Network+Attention(Graph Attention Neural Network)モデルの紹介
こんにちは、次世代システム研究室のA.Zです。
昨年からグラフのニューラルネットワークに興味をもち、この分野の研究のトレンドや応用は日々ワッチしています。この分野の研究は近年、人気になり、様々な分野の応用事例も増えています。昨年のNeurIPS(Neural Information Processing Systems) 2019で、こちらの分野はかなり注目浴びて、今年もまだまだ話題になっていると思います。
特に現在のコロナウイルスの状況で、ウィルスの構造(DNA/RNA)の解析や感染予測のモデルとかにはグラフ構造の分析は結構役に立つと思います。
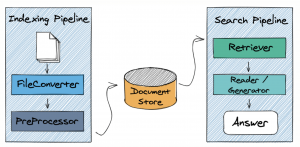
前回、ニューラルネットワークや他の機械学習タスクで、グラフのフィーチャー化は紹介いたしました。そこで、グラフはどうやって表現するかについて紹介いたしました。今回のブログでは、グラフをフィーチャー化するではなく、グラフそのものを利用し、機械学習のタスク行い手法紹介したいと思います。その中で、NLP分野でも、グラフを利用した研究が増加し、ベースになるAttentionを利用したグラフニューラルネットワーク(Graph Attention Neural Network)について紹介したいと思います。
はじめに
画像処理や画像認識の分野で、畳み込みニューラルネットワーク(Convolutional Neural Network(CNN))の成功のきっかけで、様々な分野(例:NLP、音声認識など)のマシンラーニングに、似たような手法を使えないかという研究も進んでいます。その中に、グラフ関連の機械学習の分野も一つになっています。
しかし、画像と違って、グラフに畳み込みの手法を応用するには困難なチャレンジがあります。画像では、2次元のeuclidanの空間に表現することができるため、以下のように畳み込みの処理を特定方向に動かすと、特徴量の抽出はできます。
グラフは、構造的に複雑で、方向性(上、下、右、左)はあまり意味がなく、グラフの特有の情報(近所情報、次数など)の方が重要です。その結果、CNNと違って、別のアプローチは必要です。
Graph Attention Networks
Graph AttentionネットワークというのはAttentionのメカニズムを利用したグラフ畳込みネットワーク(Graph Convolution)です。Attentionメカニズムというのは簡単に言うと、学習時、重要な情報の部分にフォクスできるようにの方法です。
グラフ畳み込み層はあるnノードを持つグラフとそのそれぞれのおグラフのfeature(h1,h2,…hn)とグラフ近所マトリックスAに対して、別のfeature(h’1,h’2,…h’n)に変換するためのオペレーターです。
Graph Attention層(以下:GAT層に省略)は基本的な役割はグラフ畳み込みそうと同じです。具体的に、GAT層で、行う処理はかんたんに説明いたします
1. 入力フィーチャを高次元のフィーチャに変換する。
2. Attentionの重みを計算する。
各ノードに対して、重みを以下の方法で計算します。
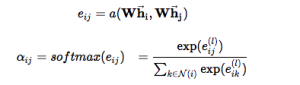
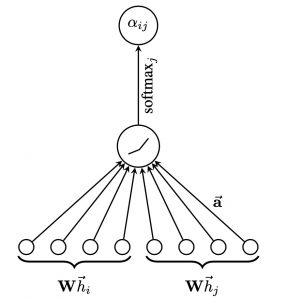
上記のa はattention メカニズム(
最後に、全てのノードiの近所ノードに対して、softmaxで、値をnormalizedします。
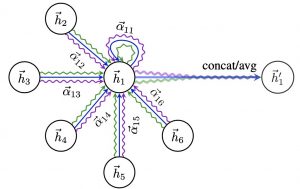
具体的なイメージは以下の図になります。
3. 最後のステップではすべて近所情報は結合します。
統合するのは以下の数式を利用します。
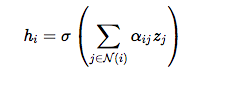
σは活性化関数(sigmoidなど)です。
GATはmulti head attentionを利用し、attentionの数は Kだとしたら、GAT層の位置(分類層の手前かどうか)によって、結合方法は以下になります。
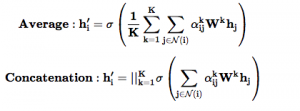
分類層(最後の層)の手前だったら、averageを利用し、中間層だったら、concatenationを利用する。具体的なイメージは以下の図になります。
実験
データセットについて
今回使っているデータセットは元の論文で利用したcoraデータセットです。
https://relational.fit.cvut.cz/dataset/CORA
データセット概要
The Cora dataset consists of 2708 scientific publications classified into one of seven classes. The citation network consists of 5429 links. Each publication in the dataset is described by a 0/1-valued word vector indicating the absence/presence of the corresponding word from the dictionary. The dictionary consists of 1433 unique words.
こちらのデータセットは単純にグラフだけではなく、ほかのフィーチャー(Bag of words)も含まれ、 グラフの情報+他のフィーチャはEnd-to-Endのモデルでトレーニングするのは今回のアルゴリズムの特徴です。
ソースコード
今回はSpektralというTensorflow 2のライブラリーを利用しました。
ネットワークの構造
今回の実験は基本的に、元の論文で行ったセットアップと同じセットアップを行いました。 具体的に、上記のデータのレーブル予測するときに、以下のネットワーク構造を利用しました。
Input Layer -> Dropout Layer -> GAT Layer1 -> Dropout Layer -> GAT Layer2 -> Output Layer
モデルサマリー:
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
input_1 (InputLayer) [(None, 1433)] 0
__________________________________________________________________________________________________
dropout (Dropout) (None, 1433) 0 input_1[0][0]
__________________________________________________________________________________________________
input_2 (InputLayer) [(None, None)] 0
__________________________________________________________________________________________________
graph_attention (GraphAttention (None, 64) 91904 dropout[0][0]
input_2[0][0]
__________________________________________________________________________________________________
dropout_1 (Dropout) (None, 64) 0 graph_attention[0][0]
__________________________________________________________________________________________________
graph_attention_1 (GraphAttenti (None, 7) 469 dropout_1[0][0]
input_2[0][0]
==================================================================================================
Total params: 92,373
Trainable params: 92,373
Non-trainable params: 0
__________________________________________________________________________________________________
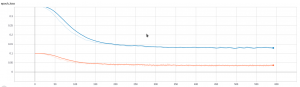
結果
トレーニングのloss

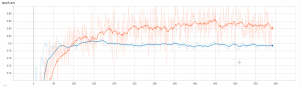
トレーニングのaccuracy
テストデータの精度
Test loss: 0.22264422476291656 Test accuracy: 0.824999988079071
上記の結果見ると、結構高い精度達成できました。
まとめ
- 今回はGraph Attention Network(GAT)についてを紹介いたしました。グラフと他のfeatureはEnd-to-End学習できるため、実サービスに応用するには便利だと思います。
- 最近注目されているGraph NLPの分野で、今回紹介した手法は結構ベースになるため、今後のトレンドにキャッチアップするには役に立つだと思います。
- 今後、Graph NLPの分野にも取り込んでみて、またそれについて紹介したいと思います
次世代システム研究室では、ビッグデータ解析プラットホームの設計・開発を行うアーキテクトとデータサイエンティストを募集しています。次世代システム研究室にご興味を持って頂ける方がいらっしゃいましたら、ぜひ 募集職種一覧 からご応募をお願いします。
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD