2018.07.04
深層学習・最新論文紹介:ブースティングを用いてGANの性能を改善する「Ada GAN」の紹介
イントロダクション
皆様、こんにちは(or こんばんは)。
次世代システム研究室のT.Yです。
今年の夏は、今までにないスピードでやってきましたね。
原稿を整理している時点では、日中最高気温が30度前後と季節感全開の日が続いていますが、皆様はいかがお過ごしでしょうか?
さて今回は、引き続き深層学習のテクノロジーの紹介をしたいと思います。
現時点では最新となるNIPS2017より「Ada GAN」を取り上げたいと思います。
Ada GANのArxivの論文ページはこちらです。
https://arxiv.org/pdf/1701.02386.pdf
[補足1] Nipsについて
Nipsは、Neural Information Processing Systems の略称です。
1986年にカリフォルニア工科大学とベル研究所が設立し、30年もの歴史を持つ国際学会です。
もともとはニューラルネットワークの学会でしたが、現在では機械学習全般をテーマとして扱っています。
参加人数は2016年に5,000人、2017年には8,000人と、指数関数的な勢いで増えており、人工知能分野では世界最大の学会となっています。
https://nips.cc/[補足2] GANについて
GANは、Generator(生成器)とDiscriminator(鑑識器)が互いに競い合いながら学習を進めるというメカニズムを持ち、
写真やイラスト、音声を自動合成することができます。そのインパクトは大変強く、多くの研究者がさまざまな改良に取り組んでいます。GANがどのようなものかを具体的に知りたい際には、私が以前発表した以下のスライドをご覧ください。
Ada GAN 概要
以前紹介した「Bayesian-GAN」をはじめ、GAN(Generative Adversarial Networks:生成的対立的ネットワーク)は、
人間の目でもってもニセモノと見破ることができないような画像を生成できるという鮮烈なデビューを飾ったテクノロジーです。
入力されたデータに対して、判定結果を出すという従来の伝統的なAI(=機械学習モデル)とは比べて、データそのものを生成するという点が大きな特徴でした。
そのGANも課題を抱えており、それらの中の一つに最頻値崩壊(“mode collapse”)という、特定パターンに極度に偏ったデータ生成しかできなくなる問題があります。
modeとは最頻値のことであり、文字通り最も頻繁に出現するパターンしか生成できない学習に陥ってしまいます。
具体的に言うと、どのようなインプットを与えても、出てくる画像や音声はほぼワンパターンに収束してしまうのです。
GANではDiscriminatorの学習がGeneratorよりも早く進む場合があり、GeneratorはDiscriminatorを欺くことが出来るわずかなパターンを選択的に生成するようになります。
よって、本物そっくりの画像や音声を合成できるものの、ワンパターンしか出力できないモデルが出来上がります。
こうした背景があるため、従来のGANにおいては、成功するモデルが出来るかどうか運試しの要素が多分にあり、何度もモデル構築を試す羽目になることは珍しいことではありませんでした。
このGAN特有の課題を、従来の機械学習手法の一つ・アンサンブルモデルを取り入れ、ハイブリッドな解決方法を鮮やかに提示したのが「Ada GAN」なのです。
Ada GAN のすごいところ
従来の機械学習手法の中には、アンサンブルモデルというものがあります。
複数のモデルを組み合わせて、より良い性能を追及するというものです。
その中から、「Ada Boosting」という著名な方法を選び、そのメカニズムを取り入れてGANの課題に対して解決策をもたらした点がAda GANの素晴らしいところです。
何しろ、納得感・説得力に満ち溢れているわけです。
「ああ、あのAda Boostingね? なるほど、それなら分かる!」と関係者がスムーズに口走るぐらい、論理構造のスムーズな理解ができるのが大変特徴的であると思います。
そもそもAda BoostingをはじめとするBoostingアルゴリズムにお世話になる専門家は非常に多く、Kaggleのような世界的コンペではBoostingをはじめとするアンサンブル手法を使うのがもはや当たり前となりつつあります。
その背景ゆえに、Ada Boostingのメカニズムを取り入れていることは、強い説得力を持つのです。
では、そのAda Boostingがどういったアルゴリズムなのか、簡潔にご説明したいと思います。
Ada Boostingとは
Ada Boostingの考え方は、弱い学習モデル(=精度はランダム以上であること、重要)を組み合わせて、より高い精度の合成モデルを構築するというものです。
Ada Boosting は、様々な学習アルゴリズムに対応しています。
各種アルゴリズムで実装された学習モデルは、いわば部品のようなものです。
用いる学習アルゴリズムを問わない柔軟性も Ada Boostingの優れた点です。
それでは、Ada Boostingの処理の流れを見ていきましょう。
まず重要な特徴は、「予測に失敗したサンプルを重点的に学習しなおす」というものです。
最初のサイクルで、一つ目の学習モデルを構築します。
一つ目の学習モデルが予測を外したサンプルをかき集め、それらを元に二つ目の学習モデルを構築します。
この流れを指定回数繰り返します。当然、繰り返しが多いほど性能は良くなります。
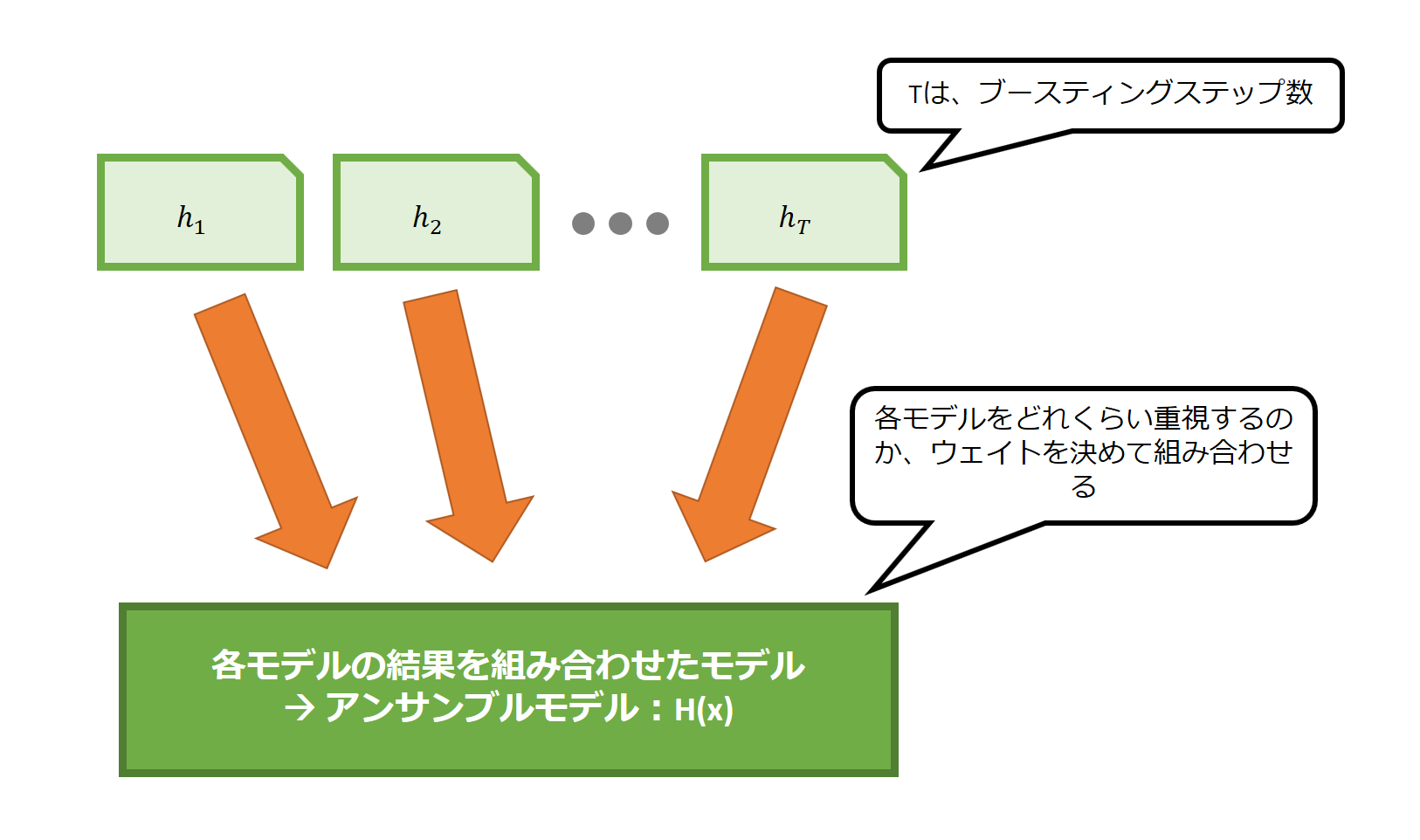
Ada Boosting の繰り返し学習の仕組み

こうして複数の学習モデルを用意したら、次は各学習モデルの重みを計算します。
ここで言う重みとは、投票権の大きさのようなものです。
信頼がおける学習モデルほど、大きな投票権を与えようというわけです。
各学習モデルの信頼度は、学習データ全体を入力した際の予測精度を元に計算します。
各サイクルごとに、構築した学習モデルの信頼性を計算して、重みを求めるわけです。
各学習モデルを重みをつけて結びつける
各学習モデルの重み=信頼度の大きさの求め方

こうして求めた学習モデルと重みから、単一モデルよりも精度の高いアンサンブルモデル=合成モデルを構築するのです。
GANにAda Boostingを取り入れる
それでは、Ada Boostingの仕組みを使って、GANのアンサンブルモデルを構築するアルゴリズムを見ていきましょう。
これがAda GANのアルゴリズムになります。
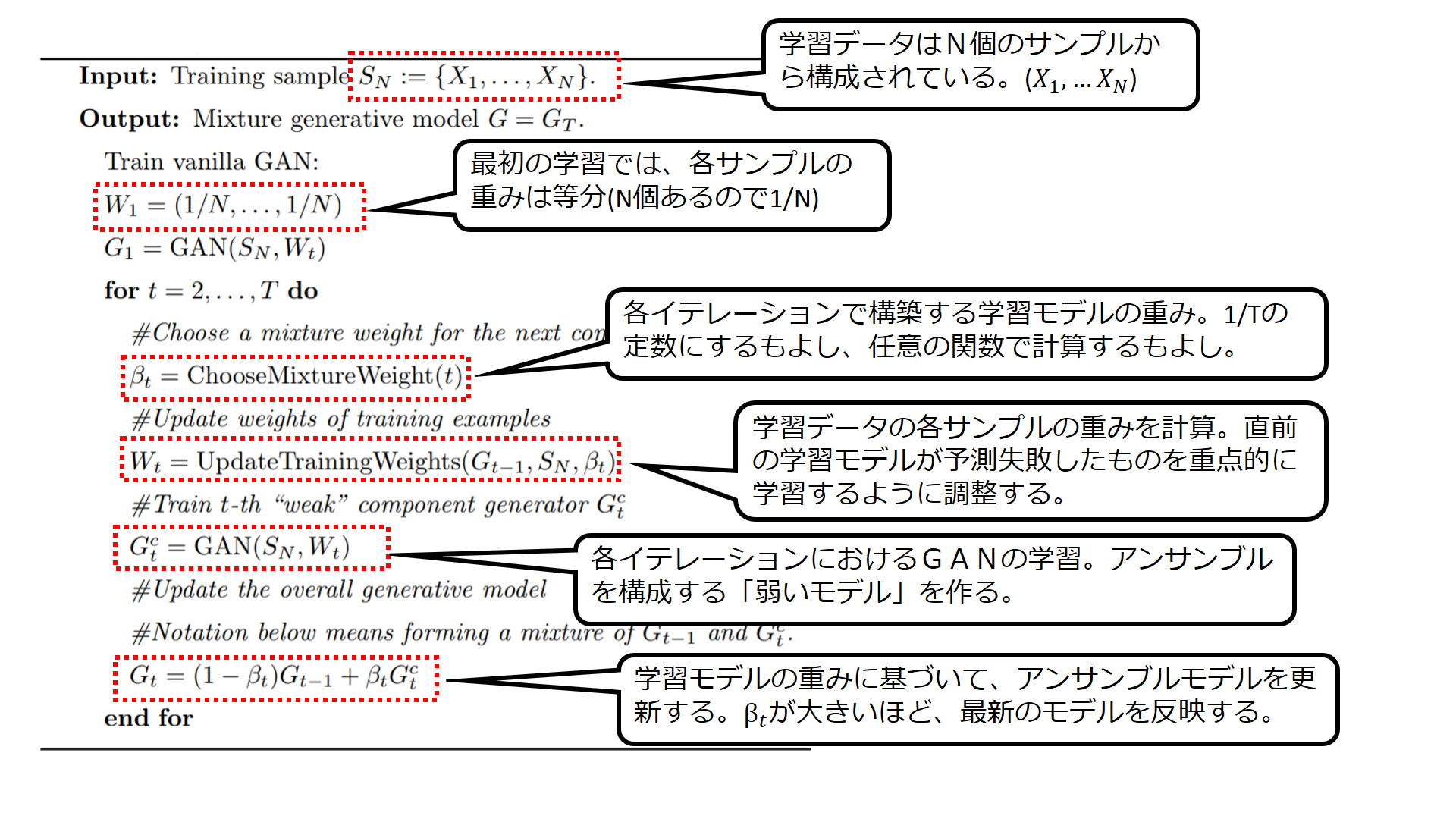
N個の学習データのサンプルを使います。
T個の学習モデル(GAN)を組み合わせたものをアンサンブルモデル=最終成果物とします。
繰り返しの学習ループを始める前に、最初の学習モデルを作っておきます。
最初の学習では、N個の学習データの各サンプルを等しい重みで学習します。
各学習モデルの重みの付け方には、いくつかのアプローチがありますが、等分にする(=各モデルの重みは 1/T)という方法が分かりやすいですね。
学習データの各サンプルをどれくらいの重みで学習するのか調節してゆくのが、Ada Boostingの基本的な発想です。
ここでは、一つ前のプロセスで構築した学習モデルを学習データ全体にぶつけて、学習の重みを求めます。
Ada Boostingの考え方に沿って、学習モデルが予測に失敗したサンプルを重点的に学習するように重みを付けていきます。
学習データの各サンプルの重みが決まったら、いよいよ最新の学習モデルを構築します。
直前の学習モデル(t-1回目のモデル)で、予測に失敗したサンプルほど重点的に学習します。
こうして求めた最新の学習モデル(t回目)と直前の学習モデルを混合比率βで結合して、
t回目時点のアンサンブルモデルとします。
このようにして、トータルでT回のイテレーションを実施し、最後に得られたアンサンブルモデルがお目当ての最終成果物となります。
実験
それでは Ada GANの特性について、実験を紹介したいと思います。
サンプルコードは以下のGitHubから入手することができます。
https://github.com/tolstikhin/adagan
実験1:対応するmodeの増加と、学習対象の選別
以下のチャートをご覧ください。
これは実験用に生成されたデータに対して、1回だけAda GANの学習プロセスを実行した場合のものです。

左側のチャートは画像の特徴を次元圧縮をしてプロットしたものですが、赤い点は学習データのサンプルを、青い点がAda GANで生成したモデルの Generatorが生成した画像を表しています。
赤い点の集合が4つあることが分かります。modeが4つあることに対応します。
1回目の学習の時点では、4つあるmodeのうち1つしかカバーできていないことが分かります。
また右側のチャートは、次に学習する際の学習の重みを表しています。
青い点は、学習の重みがゼロに近いサンプルで、赤い点は学習の重みが高いサンプルです。
1回目の学習モデルでは生成できなかった mode のサンプルが軒並み赤い点になっていることがわかります。
つまり、生成できなかった mode のサンプルを重点的に学習使用としていることが分かります。
次に2回目の学習プロセスの後のチャートを見て見ましょう。

左側のチャートを見ると、青いプロットの集合が二つできている、すなわち二つの mode に対応していることが分かります。
そして右側のチャートを見ると、赤い点の集合は二つに減り、モデルがまだ生成できていない残る二つの mode に重みが置かれていることが分かります。
これはまさしく Ada Boosting の振る舞いといえます。
MNISTのデータを使って他のアルゴリズムと比較する
続いて、機械学習分野ではお馴染みのMNISTのデータを使った実験を紹介します。
この実験では、MLP GANとDCGANを組み合わせて構築したAda GANモデルと、プレーンなGAN、そして別々に学習したGANを同じ割合で混合した単純なアンサンブルGANを比較します。
5つのmodeを持つ手書き数字画像を使って、モデルの学習と性能評価を行います。
次のチャートをご覧ください。
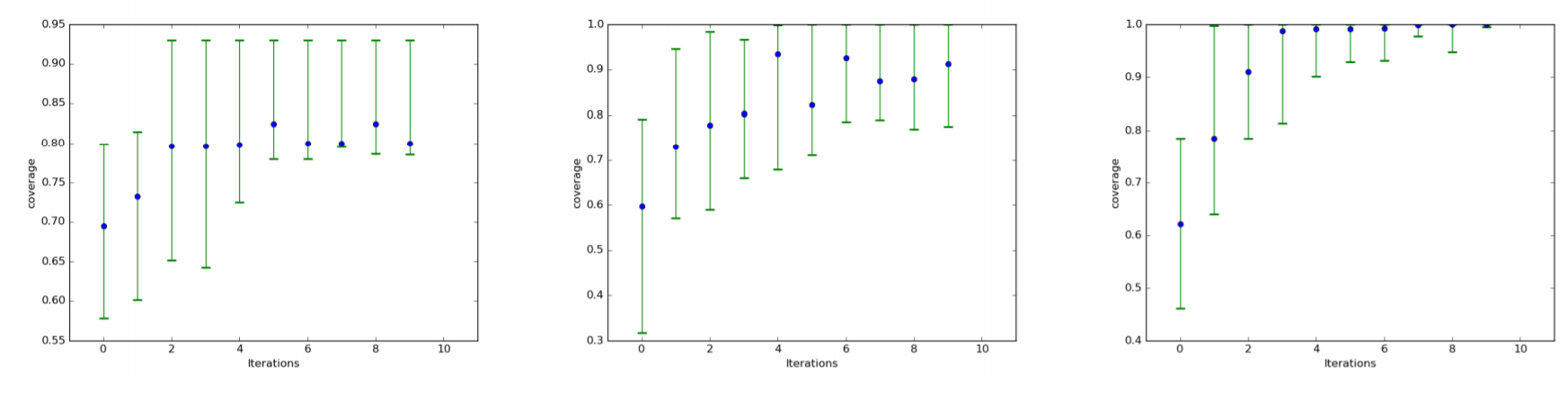
3つのチャートは左から、プレーンなGAN、別々に学習したGANを混合して作ったアンサンブルGAN、そしてAda GANとなります。
各チャートの横軸は、学習プロセスの反復回数です。
各青いプロットは35回の測定の中央値で、緑の線は5%と95%の範囲を示しています。
縦軸は、生成できた画像のカバレッジです。つまり、どれくらい mode に対応できているか、生成できる画像の種類が豊富かを示しています。
アンサンブルGANとAda GANは共にプレーンなGANを明らかに上回るカバレッジを示しています。
さらに比較すると、アンサンブルGANは試行回数を繰り返してもカバレッジの中央値が90%付近で振動しているのに対して、Ada GANは100%に向かって収束しています。
カバレッジのばらつきも少なく、確実に100%に近づいており、Ada GANの側に明らかに軍配が上がることが分かります。
MNISTのデータで mode の数を変えて実験
それでは、同じMNISTのデータを使い、mode の数を変えて実験をします。
mode の数が増えるほど、手書き数字の多様性は強くなり、再現する難易度は上がります。
以下のテーブルをご覧ください(論文より抜粋)。
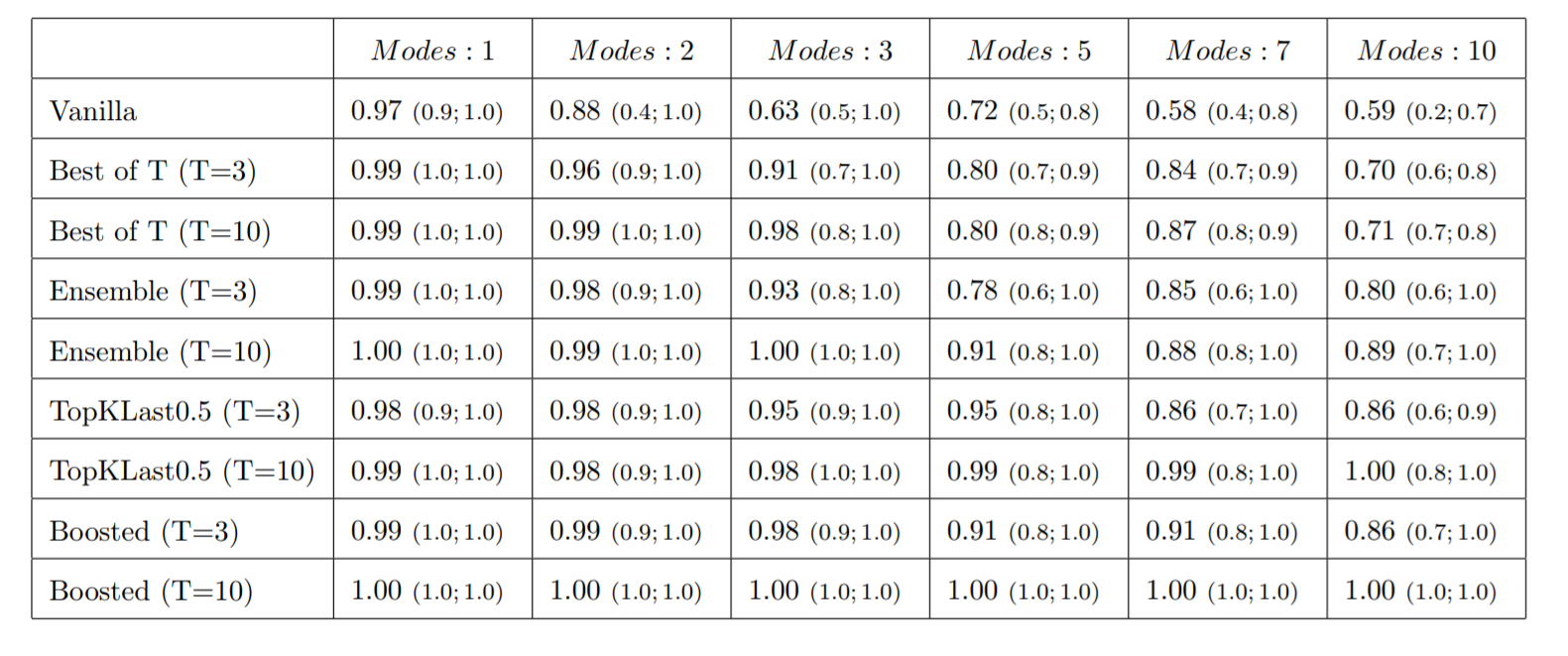
テーブルの列方向には、modeの数が1から10のケースまで記されています。
行方向には、そのままのGAN(=VanillaなGAN)、ベストなモデルを選択する手法(Best of T)、アンサンブルモデル、論文中で他論文から引用したカスケード型GAN(表記はTopKLast0.5と TopKLast0.3)、そしてAda GANの項目(=表記は Boosted)が記されています。
各セルには、先ほどの実験と同じく35回の測定の中央値が記録されています。
括弧内には、カバレッジの測定分布の5%の値と95%の値が記されています。
テーブルを見るとmodeの数が大きくなるほど、カバレッジの値が下がる傾向が確認できます。
そのままのGANでは mode が10個だと6割にも達しません。
mode 3までならば、ベスト選択の手法、アンサンブルも100%に近いカバレッジを出しています。
しかし、modeが5以上になると、明らかにカバレッジが下がりトップ競争から脱落してしまいます。
デッドヒートを繰り広げるのは、カスケード型GANとAda GANです。
共に100%近いカバレッジで競い合いますが、3~5%の僅差でAda GANが優れていることが分かります。
まとめ
従来の機械学習における代表的なアンサンブル手法の一つで Boosting のアプローチをGANに取り入れることで、カバレッジが大きく改善し、多数の mode に対応できることが示されました。
直前までのプロセスで予測できなかったサンプルを重点的に再学習し、新しい Generatorを組み込むことで、確実にカバレッジが改善することが示されました。
やはり複数のモデルを組み合わせるアンサンブルアプローチは強力ですね。
【重要】最後に
次世代システム研究室では、機械学習や統計処理に関心を持つ開発者、アーキテクト、データサイエンティストを求めています。
自由闊達にのびのびと働きながら学べる環境があります。
コーヒー片手にアカデミックとビジネスの融合したディスカッションをしながら、知的好奇心を満たすことができる環境があなたを待っています。
次世代システム研究室にご興味を持たれたらすぐに 募集職種一覧 からご応募してください。
皆さんのご応募をお待ちしています。
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD