2022.01.11
Cloud SQLサーバーレスエクスポートからのBigQueryデータ登録
こんにちは。次世代システム研究室のM.Mです。
現在、担当しているプロジェクトでCloud SQLを利用する機会があり、Cloud SQLのエクスポートについて調べている際に、サーバーレスエクスポートという機能を見つけました。
今回は、そのサーバーレスエクスポートを使って、手軽にBigQueryにデータ登録できるか試してみました。
1. Cloud SQLのサーバーレスエクスポートとは
Cloud SQLのDBインスタンスにパフォーマンス影響を与えることなく、データをエクスポートできる機能です。
特に膨大なデータを保持している本番稼働データベースからデータをエクスポートする場合、データベースへの負荷を考慮して、負荷が最も低い時間帯にエクスポートを実施しているかと思います。
サーバーレスエクスポートを使うことで、そのような本番稼働データベースへの負荷影響を考慮しなくてもよくなります。
サーバーレスエクスポートは、内部的に稼働しているDBインスタンスとは別の一時的なDBインスタンスを新たに作成し、その一時的なDBインスタンスを利用してデータのエクスポートを行うことで、稼働しているDBインスタンスへの影響を回避しています。
エクスポートが完了するとその一時的なDBインスタンスは自動的に削除されます。
本番環境のデータベースに影響を与えず、本番環境のデータを抽出して調査・分析ができるので、非常にありがたい機能ですが欠点もあります。
一時的なDBインスタンスの作成に時間がかかるため、標準エクスポートよりも時間がかかります。
さらに、一時的なDBインスタンスの利用分の追加料金も発生します。
メリット
- エクスポート処理でDBインスタンスに影響を与えない
- その結果、DBインスタンスを利用しているサービスに影響を与えることなく、大量データのある本番環境でも、高負荷になるようなSQLでのデータ抽出でも気にせず実行可能
デメリット
- 通常エクスポートより時間がかかる
- 一時的なDBインスタンスの利用分の追加料金が発生する
2. サーバーレスエクスポートとBigQueryへのデータ登録
では、Cloud SQLサーバーレスエクスポートを使って、データをエクスポートし、そのエクスポートされたデータを利用してBigQueryへ登録していきます。
GCP WEB管理コンソールを使って、Cloud SQLのサーバーレスエクスポートの実行
まず、GCP WEB管理コンソールのCloud SQLから、エクスポート対象のDBインスタンスを選択します。
すると、以下の図のように、エクスポートボタンがあるので、クリックします。
クリックすると、エクスポートの形式やエクスポート対象のデータベース、エクスポート先などを設定する画面が表示されます。
エクスポートの形式については、以下の図のように、pg_dumpの出力などのSQLファイルかCSVファイルかを選択できます。

今回は、CSVを選択して、必要なデータを取得するSQL文を記載してデータのエクスポートを行うことにします。
以下の図のように、エクスポート対象のデータベース、SQLクエリ、出力先となるCloud Storageロケーションを選択します。
また、赤線で囲った部分で、サーバーレスエクスポートを利用するか選択できるようになっています。
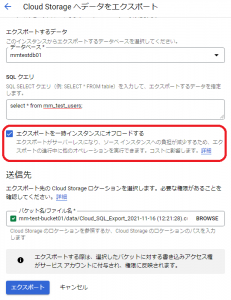
今回は、「エクスポートを一時インスタンスにオフロードする」にチェックを入れて、エクスポートボタンを押して実行します。
以下の図のようにエクスポートが実行され、指定したCloud Storageのロケーションにエクスポートデータが作成されます。

サーバーレスエクスポート自体は、「エクスポートを一時インスタンスにオフロードする」にチェックを入れればよいだけで、簡単に利用できることが分かりました。
続いて、Cloud Storageにエクスポートされたデータを利用してBigQueryのテーブルを作ります。
BigQueryへのデータ登録
この作業も、GCP WEB管理コンソールを使って実施します。
GCP WEB管理コンソールのBigQueryを選択して、以下の図のように、テーブルを作成したいデータセットから「テーブルを作成」を選択します。
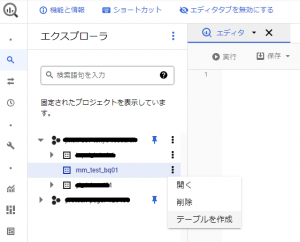
「テーブルを作成」をクリックすると、以下の図のように取り込むデータを選択したり、作成するテーブル名などを設定する画面が表示されます。
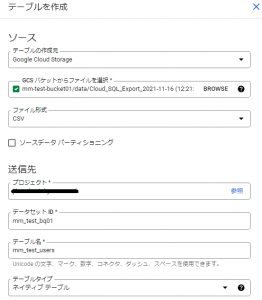
ここで、サーバーレスエクスポートでCloud Storageに作成されたCSVファイルを選択すればOKです。
また、作成するテーブルのフィールド名なども、以下の図のように画面上で設定してテーブル作成を行うことができます。
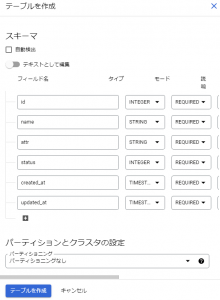
「テーブルを作成」ボタンをクリックするとBigQueryにテーブルが作成されます。
これでBigQueryへのデータ登録もできました。
サーバーを用意する必要もなく、プログラムを書く必要もありません。利用するのはGCPのWEB管理コンソールのみです。
分析用途やバックアップなど定期的にエクスポートしたいのではなく、一時的な調査で利用したい場合はそれで十分だと思います。
3. サーバーレスエクスポートとBigQueryへの定期的なデータ登録
先ほどはGCPのWEB管理コンソールですべて対応しました。
では一時的ではなく、定期的にBigQueryへデータ登録させたい場合も、GCPのWEB管理コンソールのみで実現できるでしょうか?
結論、Cloud SQLサーバーレスエクスポートを定期的に実行してCloud Storageへエクスポートさせるには、多少プログラムを書かないとできませんでした。
GCPのWEB管理コンソールのみで完結させたかったので残念ではありましたが、定期的なエクスポートについてドキュメントが用意されていました。
「Cloud Scheduler で Cloud SQL データベースのエクスポートをスケジューリングする」
そのドキュメントによると、以下のクラウドコンポーネントを利用して実現するようです。
- Cloud Scheduler
- Cloud Pub/Sub
- Cloud Functions

クラウドコンポーネントを利用するためのサービスアカウントの作成などは必要になりますが、基本的にやることは2つです。
- Pub/SubトピックをトリガーとするCloud Functionsを作成する
- Pub/Subトピックにエクスポート対象のデータベースやCloud Storageのロケーション情報を定期的に送信するCloud Schedulerを作成する
※このCloud Functionsに、サーバーレスエクスポートを実行するプログラムを書きます。
流れ的には、
1.Cloud Schedulerから定期的に、Pub/Subトピックにエクスポートのための情報が送られてくる
2.そのPub/SubトピックをトリガーにCloud Functionsが実行され、サーバーレスエクスポートが実行される
となります。
サービスアカウントの作成や、各種クラウドコンポーネントの作成は上記ドキュメントに記載の通り実施すればできました。
Cloud Functionsの実装は以下のようにしました。
import base64
import logging
import json
from datetime import datetime
from httplib2 import Http
from googleapiclient import discovery
from googleapiclient.errors import HttpError
from oauth2client.client import GoogleCredentials
def main(event, context):
pubsub_message = json.loads(base64.b64decode(event['data']).decode('utf-8'))
credentials = GoogleCredentials.get_application_default()
service = discovery.build('sqladmin', 'v1beta4', http=credentials.authorize(Http()), cache_discovery=False)
uri = "{0}/data/mm-test-users.csv".format(pubsub_message['gs'])
instances_export_request_body = {
"exportContext": {
"uri": uri,
"databases": [
pubsub_message['db']
],
"kind": "sql#exportContext",
"csvExportOptions": {
"selectQuery": "select * from mm_test_users;"
},
"fileType": "CSV",
"offload": True
}
}
try:
request = service.instances().export(
project=pubsub_message['project'],
instance=pubsub_message['instance'],
body=instances_export_request_body
)
response = request.execute()
except HttpError as err:
logging.error("Could NOT run backup. Reason: {}".format(err))
else:
logging.info("Backup task status: {}".format(response))
データベースやCloud Storageの情報はCloud SchedulerからPub/Subトピックに送るように、ドキュメントに記載されている内容と全く同じにしていますが、GCP Web管理コンソールで行った内容と同じになるように、以下の部分のみ変更しています。
28行目:データ取得のSQL文を記述する
30行目:エクスポート形式をCSVにする
31行目:offloadにTrueを設定してサーバーレスエクスポートとする
これでCloud Schedulerに設定した日時にて、定期的にサーバーレスエクスポートが実行され、Cloud StorageにCSVファイルが作成されるようになりました。
では、Cloud StorageにあるCSVファイルを定期的に、BigQueryに登録するにはどうすればよいでしょうか?
こちらに関しては、Data Transfer Serviceを使えば、特にプログラミングをしなくても、GCPのWEB管理コンソールのみで実現できました。
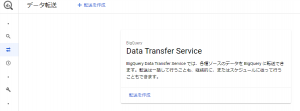
まず、GCPのWEB管理コンソールのBigQueryからデータ転送を選択します。
以下の図のような画面が表示されるので、「転送を作成」をクリックします。
「転送を作成」をクリックすると、取り込みデータの情報や転送先の情報、定期的に実行させる日時などを設定する画面が表示されます。
以下では、Google Cloud Storageから毎日、13:00に実行されるように設定しています。
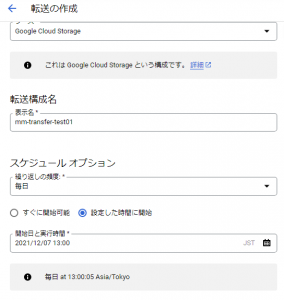
また、取り込みデータの情報や転送先の情報も以下の図のように設定することができます。
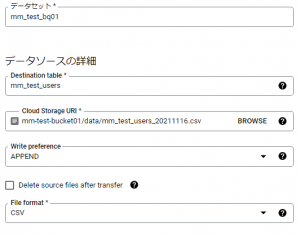
設定が完了して、指定した時間になると、BigQueryへの取り込みが行われます。
また、以下の図のように実行履歴を確認することができます。
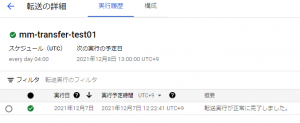
これで、Cloud SQLからの定期的なサーバーレスエクスポート、Data Transfer Serviceにて定期的なBigQueryへデータ登録ができました。
ただこの状態だと、Cloud Schedulerに設定したエクスポートの開始時間とData Transfer Serviceに設定したBigQueryへのデータ登録の開始時間が連携しておらず、BigQueryへのデータ登録開始時間にエクスポートが間に合わなければ失敗してしまいます。
Cloud StorageをトリガーとするCloud Functionsを作って、Data Transfer Service APIをうまく使えば、エクスポートと連動してBigQueryへの登録もさせることができるかもと思いましたが、結局、Cloud Funstionsでそれなりにコーディングが必要になるのであれば、あえてData Transfer Service使わなくても、そのままBigQueryに登録するソースコード書けばいいのではと思えてきました。
極力コーディングなしでクラウドのサービスを利用するだけで実現させたかったのでここで諦めました。
まとめ
サーバーレスエクスポートは素晴らしい。
データベース負荷を気にしなくてもよいので、エクスポート中の負荷は大丈夫なのか、サービス影響がでてしまうかも、などの不安がなくなるのは本当にうれしい。
エクスポートに利用するSQLがフルスキャンになるとか気にしなくていいですしね。
定期的にデータを取り込みたいとかは、しっかりコーディングして対応したほうがよい気はしますが、一時的な調査での利用であれば、GCPのWEB管理コンソールだけで十分。エンジニアじゃなくてもできるのでは。
最後に、次世代システム研究室では、グループ全体のインテグレーションを支援してくれるアーキテクトを募集しています。アプリケーション開発の方、次世代システム研究室にご興味を持って頂ける方がいらっしゃいましたら、ぜひ募集職種一覧からご応募をお願いします。
皆さんのご応募をお待ちしています。
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD