2025.10.01
Qwen3-Omni(30B, 4bit量子化)をローカルで動かしてみた
TL;DR
- Qwen3-Omni(30B, 4bit量子化版)をローカル環境で実行してみた
- vLLM を利用して高速・効率的な推論環境を構築
- 音声+画像の同時入力が可能
- 4bitでも、音声や画像の特徴をある程度正確に説明できることを確認
- vLLMは現状音声出力に未対応だが、今後対応予定
はじめに
こんにちは、グループ研究開発本部・AI研究開発室のB.Dです。
直近、Qwen3-Omni はオープンソースで利用可能なマルチモーダルモデルとして注目されています。今回は、その Qwen3-Omni(4bit量子化版)をローカル環境で動かし、性能や使い勝手を試してみました。
本記事では、モデルの概要、特徴、アーキテクチャに加え、実際にローカル実装して得られた知見を紹介します。
Qwen3-Omniとは
Qwen3-Omni は、テキスト・画像・音声・動画を統合的に扱える30Bのオープンソース多言語オムニモーダル基盤モデルです。リアルタイムでテキストや自然な音声による応答を生成できる点が大きな特徴です。さらに、性能と効率を向上させるためのアーキテクチャ改善も導入されています。
- 単一モデルでのマルチモーダル性能:Qwen3-Omni は、テキスト、画像、音声、動画の全てのモダリティで単一モードモデルに劣らない最先端性能を維持します。
- ベンチマーク実績:36の音声・音声+映像ベンチマークのうち、オープンソースSOTAを32、全体SOTAを22達成。
- Thinker-Talker MoEアーキテクチャ:スムーズなテキスト生成と自然なリアルタイム音声応答を実現。
- マルチモーダル推論:Thinking モデル導入により任意のモダリティ入力に対する明示的推論が可能。
- 多言語対応:テキスト119言語、音声理解19言語、音声生成10言語。
- 公開ライセンス:Apache 2.0 ライセンスで公開。
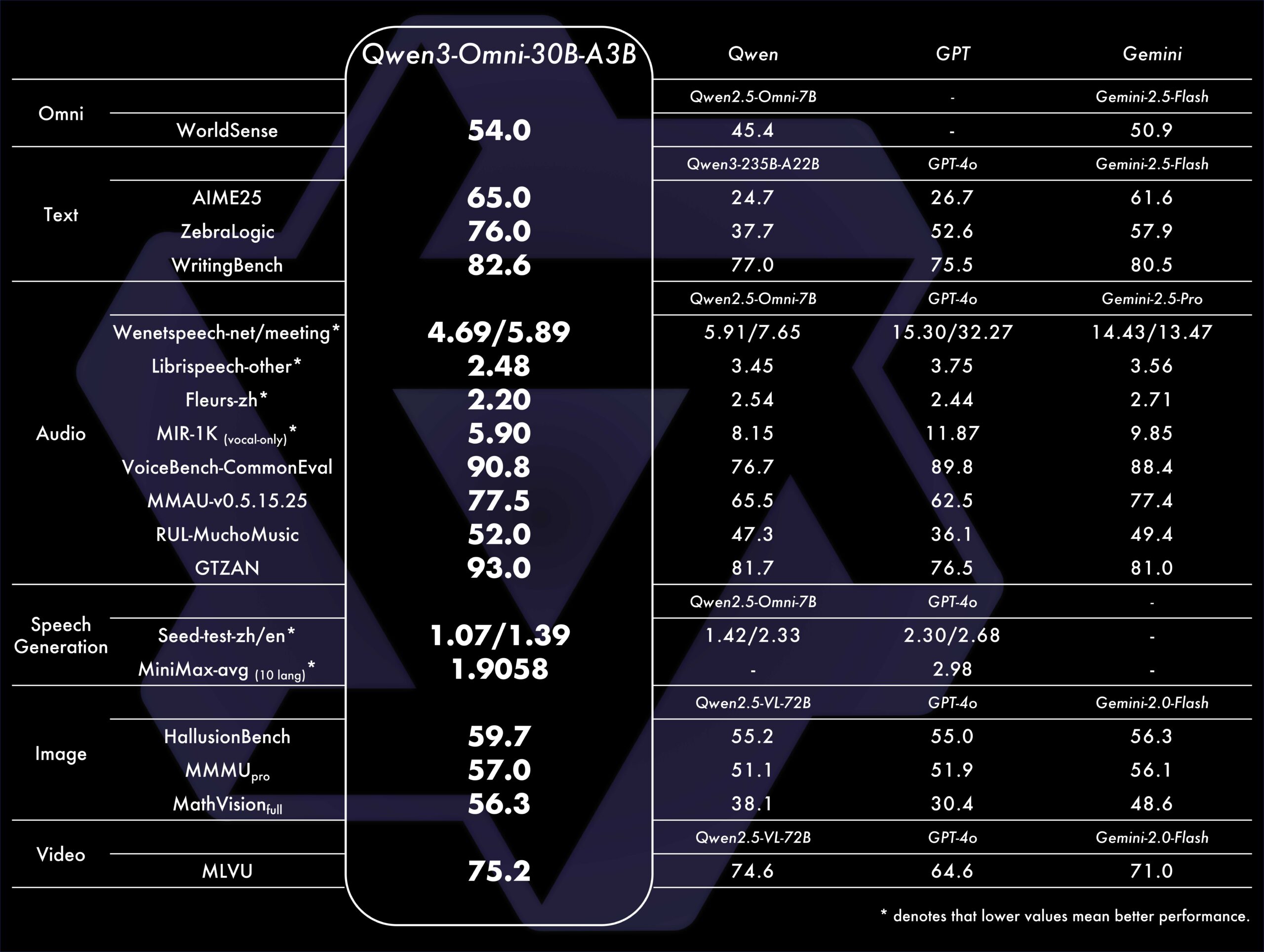
図1:Qwen3-Omniのベンチマーク結果[2]
モデルアーキテクチャ
Qwen3-Omniは、マルチモーダル入力を処理し、テキストと音声の両方で応答できる統合的なアーキテクチャを採用しています。
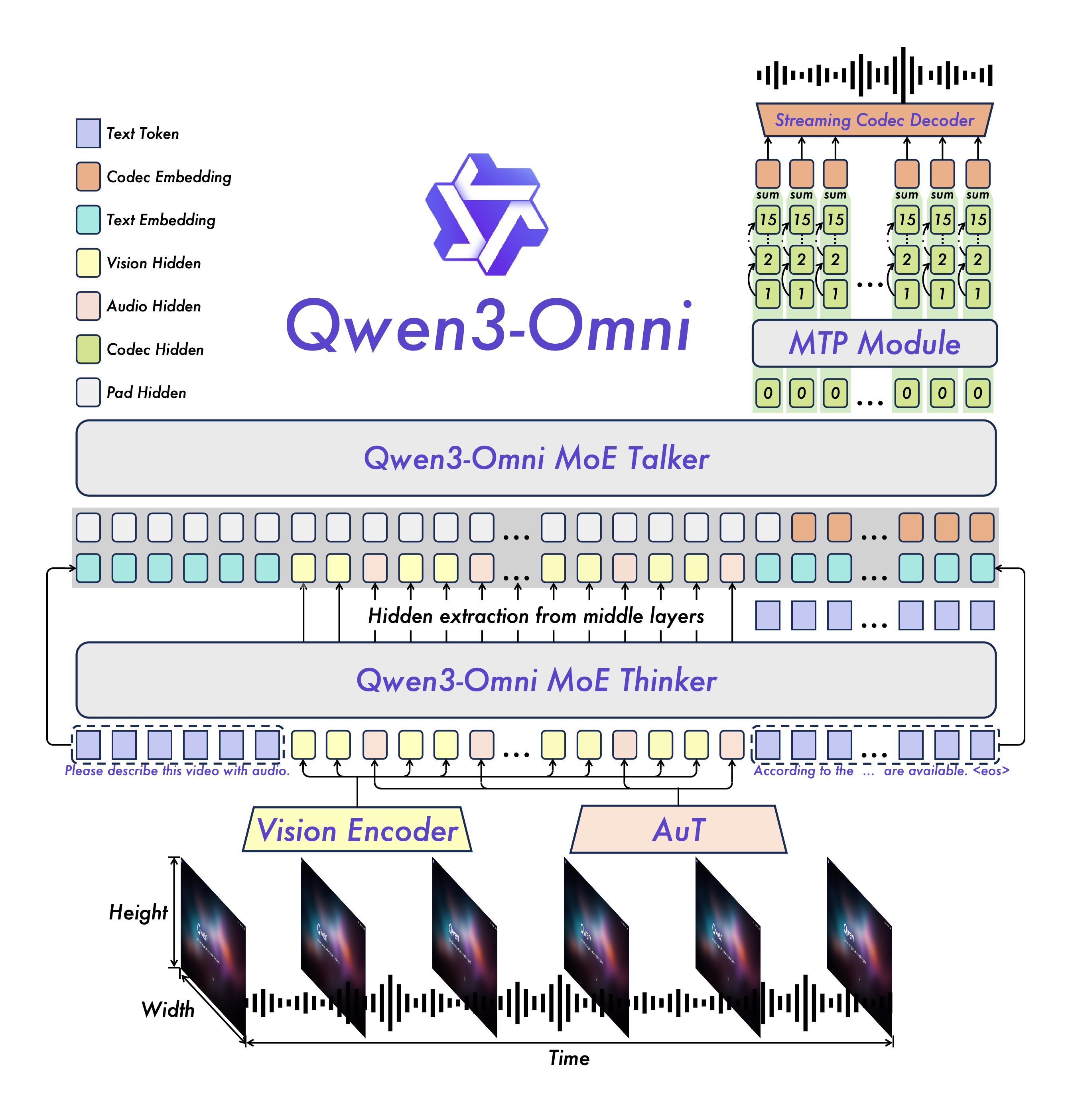
図2:Qwen3-Omniのアーキテクチャ概要[2]
モデル種類
- Qwen3-Omni-30B-A3B-Instruct:thinker と talker の両方を含み、音声・動画・テキスト入力に対応し、音声およびテキストで応答可能。
- Qwen3-Omni-30B-A3B-Thinking:thinker コンポーネントを含み、チェイン・オブ・ソート推論が可能。音声・動画・テキスト入力に対応し、テキストで応答。
- Qwen3-Omni-30B-A3B-Captioner:Qwen3-Omni-30B-A3B-Instruct からファインチューニングされた下流音声キャプションモデル。任意の音声入力に対して詳細かつ低誤出力のキャプションを生成可能。thinker を含み、音声入力とテキスト出力に対応。
ローカル実装
今回は Qwen3-Omni-30B-A3B-Instruct の4bit量子化モデル をローカル環境に導入し、vLLMを使って実行しました。環境構築の詳細や推論の実例も紹介します。
実装条件
OS:Windows11 WSL Ubuntu24.04
GPU:RTX4090(24GB) 外付けボックス
Hugging Face レポジトリ:cpatonn/Qwen3-Omni-30B-A3B-Instruct-AWQ-4bit
公式ドキュメントで以下のように強く推奨されていたため、今回はvLLMを利用して実装しました。
We strongly recommend using vLLM for inference and deployment of the Qwen3-Omni series models.
※現在コードがプルリクエスト段階にあり、Instructモデルの音声出力推論サポートは近日中にリリース予定とのことです。
Since our code is currently in the pull request stage, and audio output inference support for the Instruct model will be released in the near future
そのため、音声出力はまだ実装できていません。
vLLMとは
vLLM は、大規模言語モデル(LLM)の推論を高速かつ効率的に行うためのオープンソースライブラリです。PagedAttention という仕組みによりメモリを効率管理し、従来より 2〜4 倍のスループットを実現します。
主な特徴は以下の通りです:
- 高速推論:Continuous Batching により多数のリクエストを低レイテンシで処理可能
- モデル互換性:多くの Hugging Face モデルに対応、INT4/INT8/FP8 など量子化もサポート
- サービング機能:OpenAI 互換の API サーバを内蔵し、対話アプリケーションにも利用可能
- GPU サポート:CUDA, ROCm, Intel XPU など幅広い環境に対応
これにより、チャットボットや音声対話システムなど、リアルタイム性が重要な応用で特に有用です。
AWQとは
AWQ(Activation-aware Weight Quantization)は、大規模言語モデル(LLM)の重みを低ビット量子化(主に4bit)しつつ性能劣化を抑える手法です。
主な特徴は以下の通りです:
- モデル内部の活性化分布に基づき、重要なチャネルを重点的に保護
- スケーリングにより量子化誤差を抑えつつ、混合精度を使わずに高速化
- キャリブレーションセットだけでスケールを決定するため汎用性が高い
- 標準ベンチマークで従来手法を上回る性能を示す
- リソース制約下でも LLM の圧縮と高速化に有効
実装手順
事前準備
venvを作成して公式の手順に従ってvllmをインストール
python3.12 -m venv .venv
source .venv/bin/activate
git clone -b qwen3_omni https://github.com/wangxiongts/vllm.git
cd vllm
pip install -r requirements/build.txt
pip install -r requirements/cuda.txt
export VLLM_PRECOMPILED_WHEEL_LOCATION=https://wheels.vllm.ai/a5dd03c1ebc5e4f56f3c9d3dc0436e9c582c978f/vllm-0.9.2-cp38-abi3-manylinux1_x86_64.whl
VLLM_USE_PRECOMPILED=1 pip install -e . -v --no-build-isolation
# If you meet an "Undefined symbol" error while using VLLM_USE_PRECOMPILED=1, please use "pip install -e . -v" to build from source.
# Install the Transformers
pip install git+https://github.com/huggingface/transformers
pip install accelerate
pip install qwen-omni-utils -U
pip install -U flash-attn --no-build-isolationモデルダウンロード
hf download cpatonn/Qwen3-Omni-30B-A3B-Instruct-AWQ-4bit --local-dir ./Qwen3-Omni-30B-A3B-Instruct-AWQ-4bitvllm serveコマンドでモデルを起動
約1分くらいかかります
vllm serve ./Qwen3-Omni-30B-A3B-Instruct-AWQ-4bit \
--port 8901 \
--host 0.0.0.0 \
--dtype float16 \
--gpu-memory-utilization 0.90 \
--max-model-len 2048 \
--max-num-seqs 1 \
--allowed-local-media-path / \
-tp 1※–max-model-lenを大きく指定しちゃうと以下のエラーが出るので、メモリ許容最大限に近い値に変更しました
ValueError: To serve at least one request with the model's max seq len (32768),
(3.00 GiB KV cache is needed, which is larger than the available KV cache memory (0.20 GiB).
Based on the available memory, the estimated maximum model length is 2128.
Try increasing `gpu_memory_utilization` or decreasing `max_model_len` when initializing the engine.実行結果
(略)
INFO: Started server process [161852]
INFO: Waiting for application startup.
INFO: Application startup complete.↑最後にこの三行が出れば問題ないです。
curlコマンドで動作確認
数秒で応答が返ってきます。
Avg generation throughput: 約10~20 tokens/s
公式の例ではグラフ(四台の車)と音声(女性の咳の音)を同時に入れてたが、それだと以下のエラーが出るので、一旦画像を外して音声だけで試します。
"The decoder prompt (length 6115) is longer than the maximum model length of 2048. Make sure that `max_model_len` is no smaller than the number of text tokens plus multimodal tokens. For image inputs, the number of image tokens depends on the number of images, and possibly their aspect ratios as well."curl http://localhost:8901/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"messages": [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": [
{"type": "audio_url", "audio_url": {"url": "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen3-Omni/demo/cough.wav"}},
{"type": "text", "text": "What can you see and hear? Answer in one sentence."}
]}
]
}'実行結果
{"id":"chatcmpl-f3383c1c6ede4f5eb3fcc8563d703c9e","object":"chat.completion","created":1759249175,"model":"./Qwen3-Omni-30B-A3B-Instruct-AWQ-4bit","choices":[{"index":0,"message":{"role":"assistant","reasoning_content":null,"content":"A person can be heard repeatedly coughing, but nothing can be seen.","tool_calls":[]},"logprobs":null,"finish_reason":"stop","stop_reason":null}],"usage":{"prompt_tokens":71,"total_tokens":87,"completion_tokens":16,"prompt_tokens_details":null},"prompt_logprobs":null,"kv_transfer_params":null}“A person can be heard repeatedly coughing, but nothing can be seen.”なので、完全正解
次に、画像と音声を同時に入れてみます。今回、トークン削減のため、画像の左下の赤い車だけを切り取り、ローカルに保存します。今回はローカルから読み込みます。

図3:実験で使用した画像(左下の赤いフェラーリPortofinoを切り出し)[6]
curl http://localhost:8901/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"messages": [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": [
{"type": "audio_url", "audio_url": {"url": "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen3-Omni/demo/cough.wav"}},
{"type": "image_url", "image_url": {"url": "file:///{your_local_path}/car.jpg"}},
{"type": "text", "text": "What can you see and hear? Answer in one sentence."}
]}
]
}'実行結果
{"id":"chatcmpl-84f6bdbb28d443a8acf583dd84247cc2","object":"chat.completion","created":1759250698,"model":"./Qwen3-Omni-30B-A3B-Instruct-AWQ-4bit","choices":[{"index":0,"message":{"role":"assistant","reasoning_content":null,"content":"The audio features a person clearing their throat, followed by the distinct sound of a red Ferrari Portofino convertible sports car.","tool_calls":[]},"logprobs":null,"finish_reason":"stop","stop_reason":null}],"usage":{"prompt_tokens":1610,"total_tokens":1636,"completion_tokens":26,"prompt_tokens_details":null},"prompt_logprobs":null,"kv_transfer_params":null}“The audio features a person clearing their throat, followed by the distinct sound of a red Ferrari Portofino convertible sports car.”
よくみたら、車の札にPortofinoの文字と馬のマークが見えるので、素晴らしいですね。
最後に、日本語で回答してもらいます。
curl http://localhost:8901/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"messages": [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": [
{"type": "audio_url", "audio_url": {"url": "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen3-Omni/demo/cough.wav"}},
{"type": "image_url", "image_url": {"url": "file:///{your_local_path}/car.jpg"}},
{"type": "text", "text": "聞いた内容と、見た内容を日本語で説明してください。"}
]}
]
}'実行結果
{"id":"chatcmpl-e6ea758814b84eab8ea84f19ec9d36f1","object":"chat.completion","created":1759250274,"model":"./Qwen3-Omni-30B-A3B-Instruct-AWQ-4bit","choices":[{"index":0,"message":{"role":"assistant","reasoning_content":null,"content":"この画像は、赤いフェラーリ「ポルトフィーノM」の車両を展示ホールのような明るい室内で捉えています。車両はオープントップのコンバーチブルで、黒いソフトトップが折りたたまれており、全部屋とシートが見えます。内装には赤いスポーツシートと黒いデコラティブな装飾が施されています。フェラーリ特有の鮮やかなレッド塗装のボディ、車のフロントガルバリコラムには「Portofino M」と記されたプレートが付いており、辛抱強いヘッドライト、前面の大きなグリル、そしてキャビネットフォーミングされたフロントバンパーが目立っています。標準のフェラーリリムホイールを備えており、尺設計されています。サービスエリアはタイルパネルを敷いた床で、明るい照明に直面した洗練しているものです。この車両は完全にバージョンアップされており、コンバーチブルキャブリオレとミッドシップビークル両方の魅力を持ち、レッドマディックMパッケージを備えた高級スポーツカーモデルです。","tool_calls":[]},"logprobs":null,"finish_reason":"stop","stop_reason":null}],"usage":{"prompt_tokens":1573,"total_tokens":1860,"completion_tokens":287,"prompt_tokens_details":null},"prompt_logprobs":null,"kv_transfer_params":null}車種の認識(Portofino M)や基本的な外観の記述は正しかったものの、ハルシネーションによる意味不明な内容も含まれていました。また、音声に関する情報が抜け落ちてしまいました。やはり 4bit 量子化では、日本語での応答は難しい面があるようです。
まとめ
本記事では、Qwen3-Omni の概要と、vLLM を用いたローカル実装の手順・検証結果を紹介しました。
実際に試したところ、4bit量子化モデルでも音声と画像を同時に処理し、ある程度正確に応答できることを確認できました。特に、画像中の細かい特徴を捉える能力は印象的でした。
一方で、日本語出力では情報の抜けやハルシネーションも見られ、現時点では精度や安定性に課題も残ります。
それでも、このクラスの大規模マルチモーダルモデルを 一般的なGPU環境で動かせること自体が大きな前進 であり、研究や開発の基盤として十分なポテンシャルを感じました。
今後、音声出力対応や量子化技術の進展により、さらに実用性が高まり、身近な応用へと広がっていくことが期待されます。
最後に
グループ研究開発本部 AI研究開発室では、データサイエンティスト/機械学習エンジニアを募集しています。ビッグデータの解析業務などAI研究開発室にご興味を持って頂ける方がいらっしゃいましたら、ぜひ 募集職種一覧 からご応募をお願いします。皆さんのご応募をお待ちしています。
参考資料
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD